
电商数据实战:京东商品采集与分析平台 数据分析 大数据 spark Hadoop 数据仓库(selenium爬虫+Django 可视化分析 源码)
电商数据实战:京东商品采集与分析平台 数据分析 大数据 spark Hadoop 数据仓库(selenium爬虫+Django 可视化分析 源码)✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Django框架(后端业务逻辑)、Selenium爬虫框架(京东商品数据采集)、谷歌Chromedriver(浏览器自动化)、Echarts可视化(数据图表展示)、MySQL数据库(数据存储)
- 核心功能:京东商品数据自动化采集(名称、价格、销量、评价等)、数据清洗与结构化处理、多维度分析(销量/价格/购买人数趋势)、可视化展示(折线图/柱状图/词云)、商品查询与收藏、店铺销量深度分析
- 研究背景:电商行业竞争加剧,京东平台商品数据成为商家决策核心,但传统依赖人工采集与分析的方式存在效率低、数据滞后、缺乏直观洞察等问题,导致商家难以及时把握市场趋势,亟需“采集-分析-可视化”一体化工具。
- 研究意义:技术层面,整合Django、Selenium与可视化技术,构建完整数据处理链路;应用层面,为商家提供实时市场动态与竞品分析,辅助精准决策;学习层面,适合作为爬虫+Web开发方向毕业设计,覆盖实战核心技能。
2、项目界面
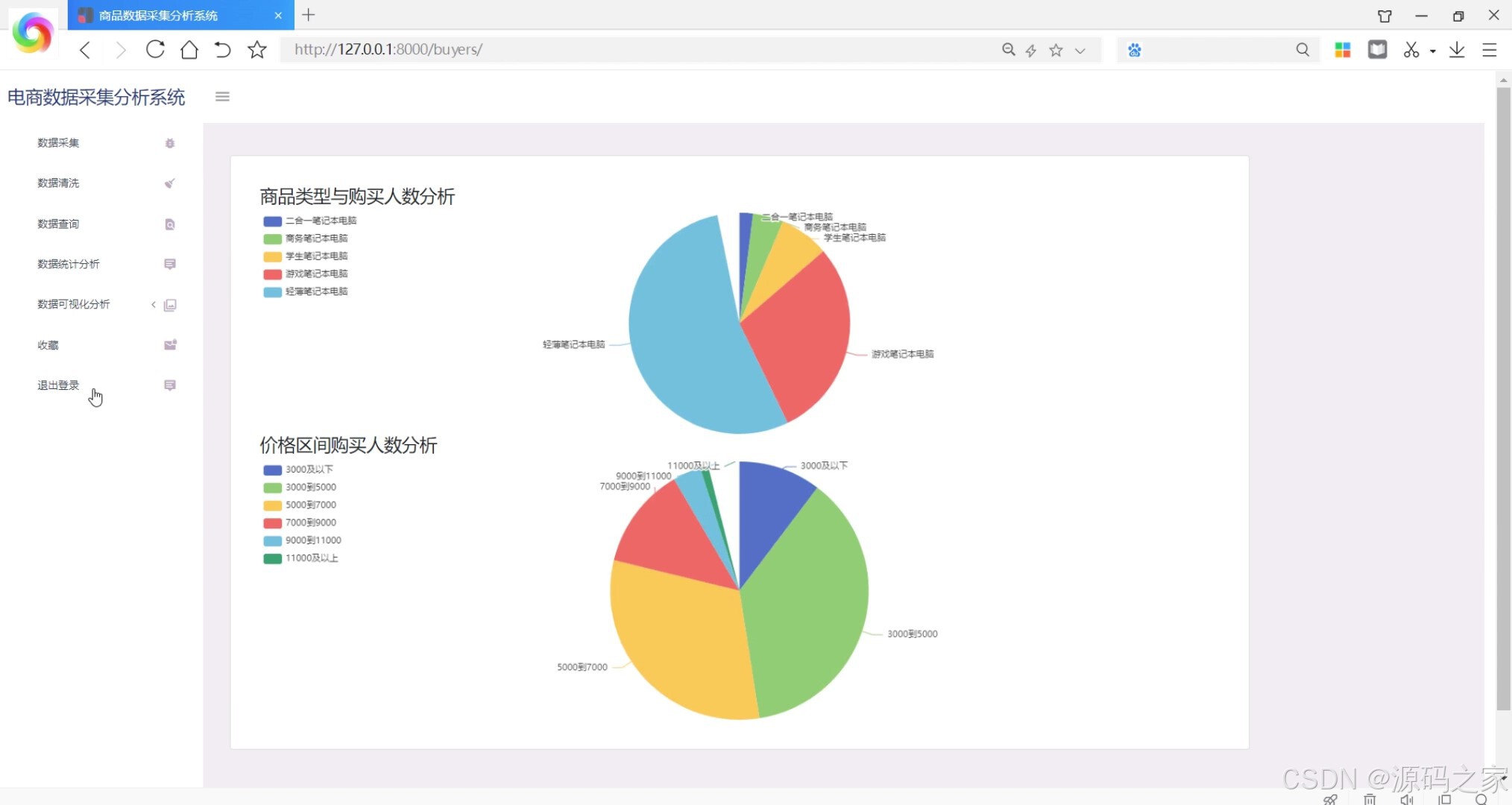
- 商品类型与购买人数分析(不同类型商品的购买人数对比图表)
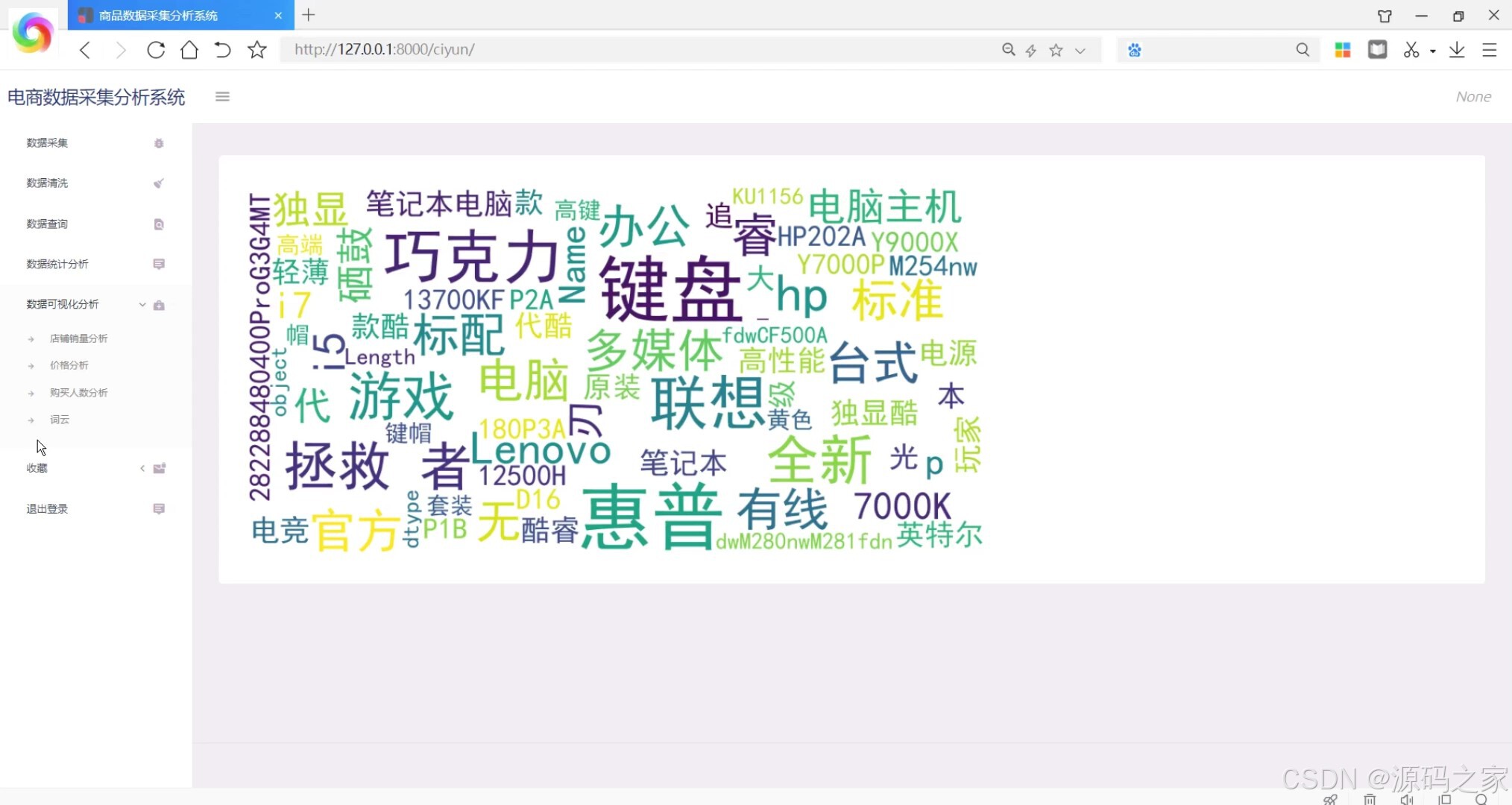
- 商品词云图(用户评价关键词词云展示)
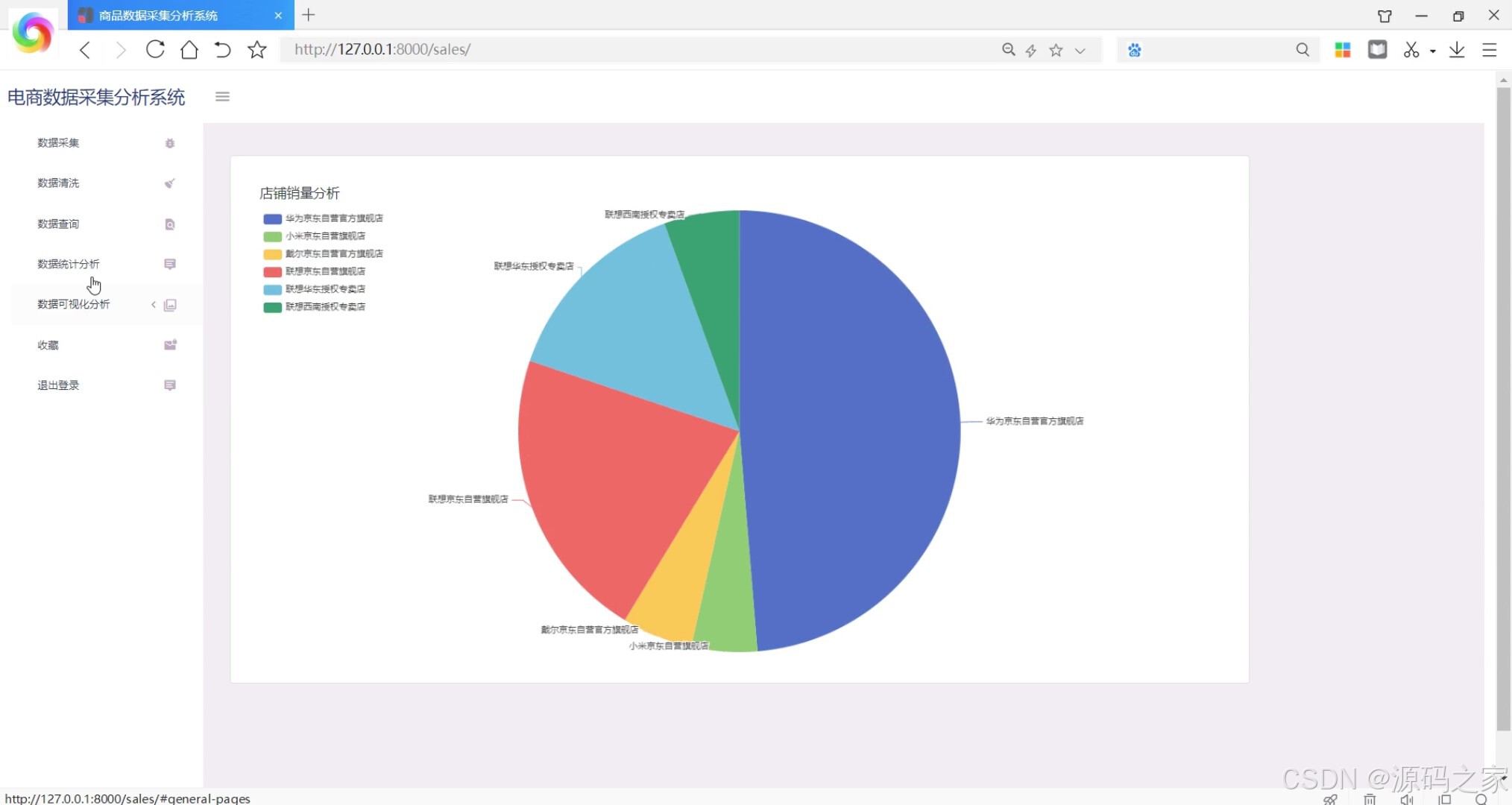
- 店铺销量分析(各店铺销量趋势与排名图表)
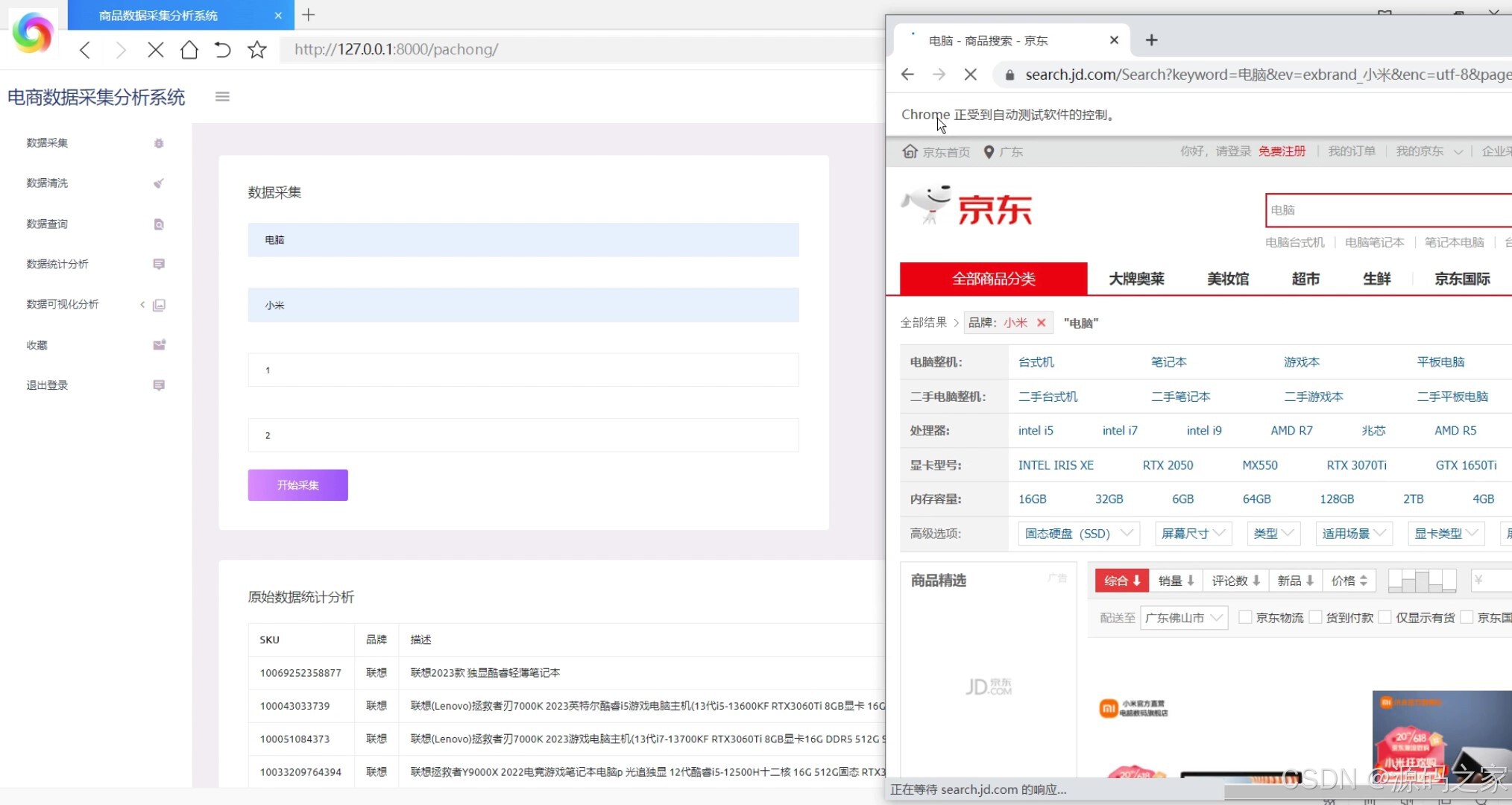
- 京东商品数据采集(爬虫任务配置与执行界面)
- 商品查询(商品信息检索与筛选界面)
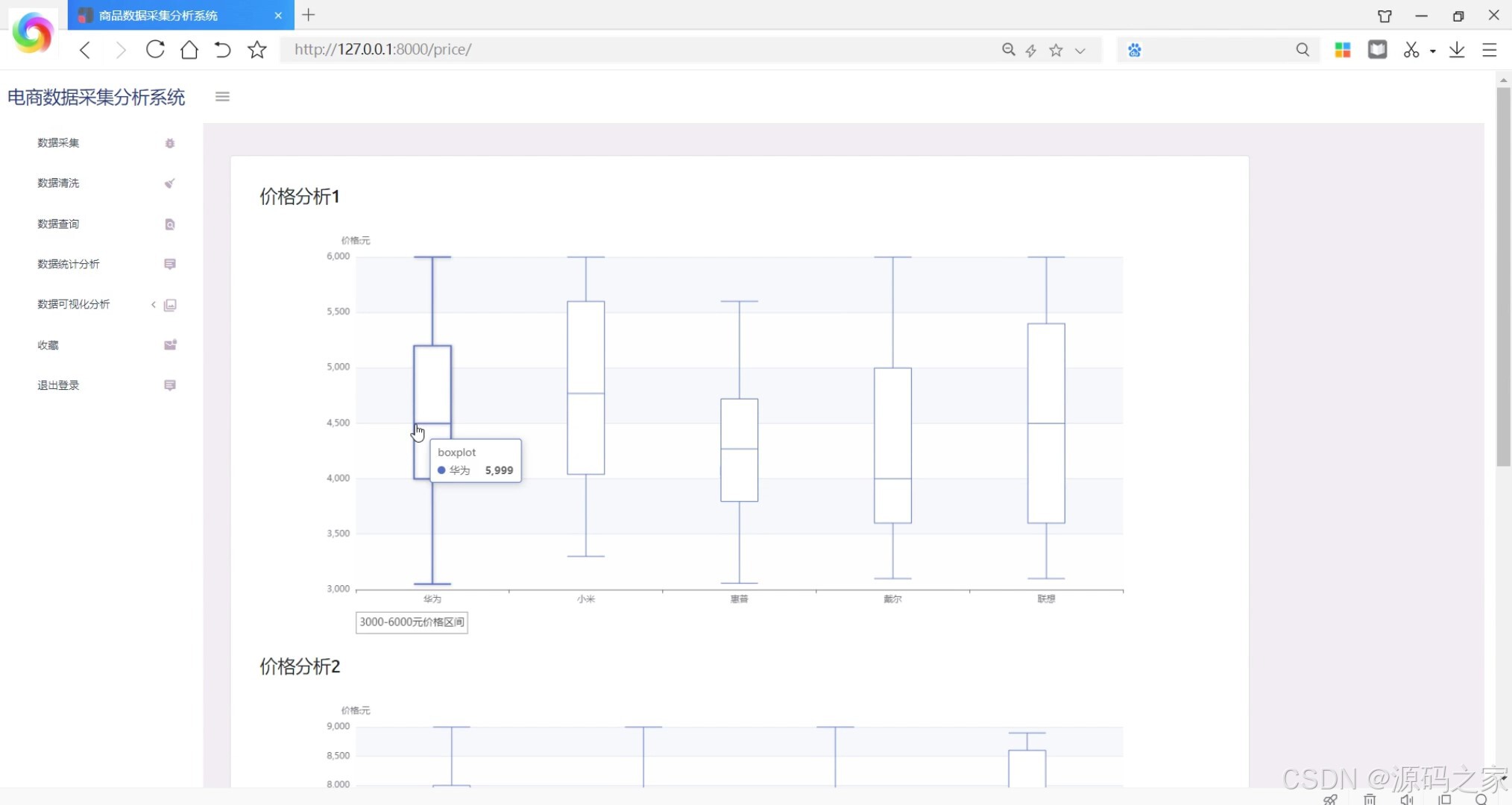
- 商品价格分析(商品价格区间与趋势图表)
7.注册登录
3、项目说明
在电子商务高速发展的当下,京东作为国内领先的电商平台,其商品数据蕴含着丰富的市场趋势与用户需求信息。然而,多数商家仍依赖人工方式采集和分析这些数据,不仅效率低下、易出错,还难以将复杂数据转化为直观的决策依据,导致在激烈的市场竞争中反应滞后。为此,本项目设计并实现了京东商品数据采集分析可视化系统,通过技术整合解决上述痛点。系统以Python为核心开发语言,后端采用Django框架搭建业务逻辑层,负责处理数据采集任务调度、数据清洗、用户请求响应等核心流程;数据采集环节借助Selenium爬虫框架结合谷歌Chromedriver,模拟浏览器操作突破京东反爬限制,精准抓取商品名称、价格、销量、用户评价、店铺信息等关键数据,经清洗(去除重复值、修正异常价格)后存入MySQL数据库,确保数据的准确性与完整性。前端通过Echarts实现多维度可视化展示,包括商品类型与购买人数的关联分析(柱状图直观呈现不同类型商品的受众规模)、店铺销量趋势(折线图追踪销量波动)、价格区间分布(饼图展示各价位商品占比)以及用户评价词云图(提炼“性价比高”“物流快”等高频关键词),让数据趋势一目了然。此外,系统支持商品模糊查询、收藏重点商品、导出分析结果等功能,满足商家个性化需求。管理员可通过界面配置爬虫参数(如采集类别、页数),普通用户则能快速获取目标商品的市场动态。整体而言,该系统实现了从数据采集到可视化分析的闭环,为商家提供及时、全面的市场洞察,助力精准决策,同时其完整的技术链路(爬虫+Web开发+可视化)使其成为电商数据处理领域的实用工具,也适合作为毕业设计展示爬虫与Web开发的综合应用能力。
4、核心代码
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from urllib import parse
import time
import pymysql
import os
class pachong_class:
def __init__(self, B, O, word, pinpai):
self.begin=B
self.end =O
self.word=word
self.pinpai=pinpai
# 实例化一个启动对象
self.chrome_options = webdriver.ChromeOptions()
# 设置浏览器以无界面方式运行
# chrome_options.add_argument('--headless')
self.browser = webdriver.Chrome(executable_path=os.path.join(os.getcwd(), 'app_jd') + '/chromedriver.exe',
options=self.chrome_options)
self.wait = WebDriverWait(self.browser, 10)
self.db = pymysql.connect(host="127.0.0.1", user="root", password="123456", db="jd_goods")
self.cursor = self.db.cursor() # 使用cursor()方法获取操作游标
self.count = 0
def get_url(self,n, word,pinpai):
print('正在爬取第' + str(n) + '页')
time.sleep(8)
# 确定要搜索的商品
keyword = {'keyword':word}
# 页面n与参数page的关系
page = '&page=%s' % (2 * n - 1)
pinpai='&ev=exbrand_%s'%(pinpai)
url = 'https://search.jd.com/Search?' +parse.urlencode(keyword) +pinpai+'&enc=utf-8' + page
print(url)
return url
def parse_page(self,url, pinpai):
print('正在爬取信息并保存......')
self.browser.get(url)
# 滑轮下拉至底部,触发ajax
for y in range(100):
js = 'window.scrollBy(0,100)'
self.browser.execute_script(js)
time.sleep(0.1)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_goodsList .gl-item')))
html = self.browser.page_source
soup = BeautifulSoup(html, 'lxml')
# 找到所有商品标签
goods = soup.find_all('li', class_="gl-item")
# 遍历每个商品,得到每个商品的信息
for good in goods:
num = good['data-sku']
tag = good.find('div', class_="p-price").strong.em.string
money = good.find('div', class_="p-price").strong.i.string
# 因为有些商品没有店铺名,检索store时找不到对应的节点导致报错,故将其设置为“没有找到店铺名”
store = good.find('div', class_="p-shop").span
pingjia = good.find('div', class_="p-commit").strong.a.string
name = good.find('div', class_="p-name p-name-type-2").a.em
picture = good.find('div', class_="p-img").a.img.get('src')
address = good.find('div', class_="p-img").find('a')['href']
if store is not None:
new_store = store.a.string
else:
new_store = '没有找到店铺名'
new_name = ''
for item in name.strings:
new_name = new_name + item
product = (num, pinpai, new_name, money, new_store, pingjia, picture, address)
self.save_to_mysql(product)
#print(product)
def save_to_mysql(self,result):
sql = "INSERT INTO app_jd_yuanshi(sku,pinpai,miaoshu,jiage,shangdian,pingjia,tupian_url,zhuye) \
VALUES ('%d','%s', '%s','%d', '%s','%s', '%s','%s')" % \
(int(result[0]),result[1],result[2],float(result[3]),result[4],result[5],result[6],result[7])
print("sql",sql)
try:
self.cursor.execute(sql) # 执行sql语句
self.db.commit() # 提交到数据库执行
print('保存成功!')
self.count+=1
except:
self.db.rollback() # 发生错误时回滚
print('保存失败!')
def get_data(self):
try:
print(self.begin,self.end,self.word,self.pinpai)
# 京东最大页面数为100
if 1 <= self.end <= 100:
page = self.end + 1
for n in range(self.begin, page):
url = self.get_url(n, self.word, self.pinpai)
self.parse_page(url, self.pinpai)
print('爬取完毕!')
self.db.close() # 关闭数据库连接
self.browser.close()
return (self.count)
else:
print('请重新输入!')
return ('请重新输入!')
except Exception as error:
print('出现异常!', error)
return ('出现异常!', error)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 46
46 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)