
电商常见面试场景题
以上方案需结合业务阶段选择。初创企业可采用Sharding-JDBC快速落地,中大型企业建议Proxy方案统一管理,云原生环境优先考虑Vitess。分页查询需在性能与功能间权衡,核心交易链路推荐游标分页+ES补充查询。
目录
-
-
- 1. 瞬时高并发
- 2. 库存一致性
- 3. 防重复下单
- 4. 系统稳定性
- 5. 库存预热
- 6. 请求削峰
- 7. 限流熔断
- 8. 静态化页面
- 9. 缓存一致性
- 10. 分布式锁方案
- 11. 分布式事务方案
- 12. 订单超时未支付
- 13. 库存扣减方案
- 14. 热点 Key 问题
- 15. 订单号生成
- 16. 数据库慢查询优化
- 17. 分布式 Session 管理
- 18. 恶意刷单检测
- 19. 数据库慢查询检测及优化
- 20. 推荐系统数据实时性(截至2025年04月28日)
- 21. 退款流程
- 22. 线程池参数设置与电商大促调优
- 23. 解决电商秒杀超卖问题
- 24. 微服务架构下商品服务拆分
- 25. 主从数据库读写分离的数据不一致解决方案
- 26. 如何保证支付系统的可靠性?
- 27. 购物车设计,遇到的问题及方案
- 28. 订单历史数据如何优化存储?
- 29. 谈谈你对CAP理论的理解
- 30. 分库分表的设计与分页查询
- 31. 分库分表的路由设计及查询
-
1. 瞬时高并发
核心挑战:在电商秒杀、大促等场景中,瞬时请求量可能达到数十万甚至百万级别,直接冲击数据库和服务器,导致系统崩溃。
解决方案:
- 异步解耦:通过消息队列(如RocketMQ)将同步下单转为异步处理。用户请求先写入队列,后端服务按处理能力消费消息,避免瞬时压力。
// 示例:使用RocketMQ发送秒杀请求
DefaultMQProducer producer = new DefaultMQProducer("seckill_producer");
producer.send(new Message("seckill_topic", "秒杀请求体".getBytes()));
- 限流与降级:
- 前端限流:按钮置灰(如2秒内禁止重复点击),减少无效请求。
- 后端限流:使用令牌桶(如Guava RateLimiter)或漏桶算法控制接口QPS。
- 缓存优化:
- OpenResty + Redis:在负载均衡层直接读取缓存,避免请求穿透到应用层。
- 库存分片:将大Key拆分为多个子Key(如stock_1, stock_2),分散Redis压力。
2. 库存一致性
核心挑战:高并发下库存扣减需保证数据一致性,避免超卖(库存扣成负数)或少卖(实际有库存但未扣减)。
解决方案:
- 数据库层:
- 行级锁 + 无符号字段:通过
SELECT ... FOR UPDATE锁定库存行,更新时检查库存 >= 扣减量。
- 行级锁 + 无符号字段:通过
UPDATE product SET stock = stock - #{num} WHERE id = #{id} AND stock >= #{num};
- 乐观锁:基于版本号或时间戳实现,冲突时重试。
- 缓存层:
- Redis原子操作:使用
DECRBY或Lua脚本保证原子性。
- Redis原子操作:使用
-- Lua脚本示例:扣减库存
if redis.call('GET', KEYS[1]) >= ARGV[1] then
return redis.call('DECRBY', KEYS[1], ARGV[1])
else
return -1
end
- 对账机制:异步比对缓存与数据库库存,发现不一致时触发补偿。
3. 防重复下单
核心挑战:用户重复点击或网络重试导致生成多个订单,引发库存错误和资金损失。
解决方案:
- 客户端防重:按钮置灰、禁用浏览器后退键,减少用户重复提交。
- 服务端幂等:
- 唯一请求号(requestId) :客户端生成唯一ID,服务端通过Redis或数据库唯一索引拦截重复请求。
// 示例:基于requestId的幂等校验
String requestId = UUID.randomUUID().toString();
boolean isLock = redis.setnx("order_lock:" + requestId, "1", 10); // 分布式锁
if (!isLock) throw new RepeatSubmitException();
- 订单表唯一索引:在订单表添加
user_id + product_id + request_id的唯一组合索引。
4. 系统稳定性
核心挑战:高并发下系统需保证可用性,避免雪崩、穿透等问题。
解决方案:
- 熔断与降级:通过Hystrix或Sentinel实现接口熔断,异常时返回兜底数据(如“活动太火爆”)。
- 集群与分库分表:
- 读写分离:订单库按买家ID分库,查询时路由到对应库。
- 冷热分离:历史订单归档到ES,减少主表压力。
- 压测与监控:全链路压测(如JMeter),监控QPS、RT等指标,提前扩容。
5. 库存预热
核心挑战:秒杀开始前将库存加载到缓存,避免瞬时查询压垮数据库。
解决方案:
- 缓存预加载:活动开始前将库存数据同步到Redis,扣减时优先操作缓存。
// 示例:预热库存到Redis
List<Product> products = productMapper.getSeckillList();
products.forEach(p -> redis.set("stock:" + p.getId(), p.getStock()));
- 缓存击穿处理:
- 互斥锁:缓存失效时,通过分布式锁(如Redisson)控制单线程重建缓存。
- 逻辑过期:缓存值包含过期时间,异步刷新避免集中失效。
6. 请求削峰
核心挑战:瞬时高并发请求直接冲击系统核心资源(如数据库),导致响应延迟或服务崩溃。
解决方案:
-
消息队列异步处理
- 将同步请求转为异步流程,通过消息队列(如RocketMQ、Kafka)缓冲请求,后端服务按处理能力消费消息。
- 优势:削平流量峰值,避免数据库瞬时过载。
// 示例:使用RocketMQ发送请求到队列 rocketMQTemplate.convertAndSend("order_topic", new OrderMessage(userId, productId)); -
等待队列与流量整形
- 在分布式锁前增加队列(如Redis List或Disruptor无锁队列),请求线程进入阻塞状态,按队列顺序处理。
- 优化:使用Disruptor框架替代LinkedBlockingQueue,实现无锁并发操作,提升吞吐量。
-
动态扩容与弹性伸缩
- 结合Kubernetes自动扩缩容,流量高峰时增加服务节点,低谷时缩减资源,降低成本。
7. 限流熔断
核心挑战:异常流量或下游服务故障导致系统雪崩。
解决方案:
- 限流策略
-
网关层限流:Nginx通过令牌桶算法限制IP或接口QPS,如设置单IP每秒50请求。
# Nginx配置示例 limit_req_zone $binary_remote_addr zone=api_read:20m rate=50r/s; limit_conn perserver_conn 1000; -
应用层限流:Sentinel或Guava RateLimiter实现细粒度控制,如接口级QPS限制。
-
- 熔断与降级
- 熔断器(Hystrix/Sentinel) :监控服务异常比例,触发熔断后直接返回兜底数据(如“服务繁忙”)。
- 降级策略:非核心功能降级(如关闭推荐服务),优先保障交易链路。
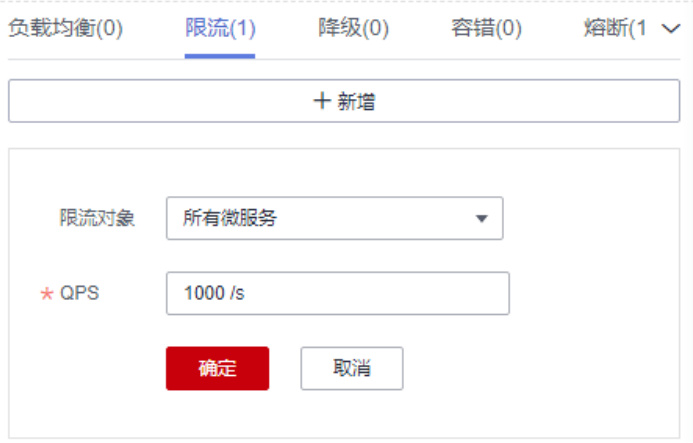
- 动态规则配置
- 华为云微服务引擎支持界面化配置限流规则(如QPS=1000),实时生效。
8. 静态化页面
核心挑战:动态页面渲染消耗服务器资源,导致响应延迟。
解决方案:
- 全静态化生成
- 商品详情页预先生成HTML,推送到CDN节点,用户就近访问。
- 技术栈:Thymeleaf或Velocity模板引擎生成静态文件。
- 动静分离与CDN加速
- 静态资源(JS/CSS/图片)分离存储,通过CDN分发,减少服务器带宽压力。
- 客户端时间同步
- 抢购倒计时由客户端JavaScript计算,避免集中请求服务器时间接口。
- 验证码与安全拦截
- 页面嵌入数学公式验证码,分散用户请求并防止脚本攻击。
9. 缓存一致性
核心挑战:缓存与数据库数据不一致,导致超卖或脏读。
解决方案:
- 缓存更新策略
- 双写模式:更新数据库后同步更新缓存,需加分布式锁避免并发写冲突。
- 失效机制:更新数据库后删除缓存,下次查询时回填(可能短期不一致)。
- 异步对账补偿
- 定时任务比对Redis与数据库库存差异,触发补偿操作(如回滚超扣库存)。
- 逻辑过期设计
- 缓存值包含逻辑过期时间,异步线程主动刷新,避免集中失效。
// 示例:缓存值结构 public class CacheItem { private Object data; private LocalDateTime expireTime; // 逻辑过期时间 }
10. 分布式锁方案
核心挑战:集群环境下保证资源操作的原子性,避免重复扣减。
解决方案:
-
Redis分布式锁
-
Redisson实现:基于Lua脚本和Watchdog机制,支持可重入锁和自动续期。
RLock lock = redisson.getLock("seckill:product:" + productId); lock.lock(); try { // 扣减库存逻辑 } finally { lock.unlock(); } -
优化点:使用Netty实现非阻塞I/O,提升高并发下锁操作性能。
-
-
ZooKeeper临时节点锁
- 通过临时顺序节点实现公平锁,会话断开自动释放,但性能低于Redis。
-
数据库悲观锁
SELECT ... FOR UPDATE锁定库存行,适用于低并发场景。
-
对比选型
方案 性能 可靠性 适用场景 Redis锁 高 较高 高并发秒杀 ZooKeeper锁 中 高 强一致性需求(如支付) 数据库锁 低 高 低频交易
11. 分布式事务方案
核心挑战:在电商系统中,订单创建、库存扣减、积分变更等操作涉及多个服务,需保证跨服务事务的原子性和一致性。
解决方案:
- 2PC(两阶段提交)
- 流程:
- 准备阶段:事务协调器询问所有参与者(如订单、库存服务)是否可提交事务。
- 提交阶段:若所有参与者同意,协调器通知提交;否则回滚。
- 缺点:
- 同步阻塞:资源长时间锁定,影响性能()。
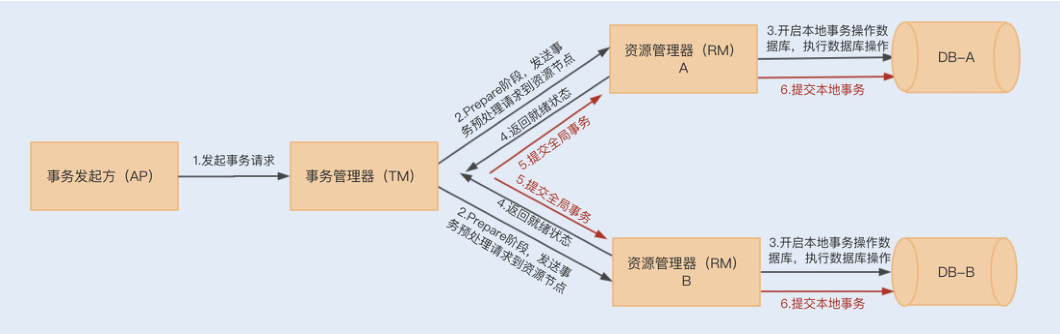
- 数据不一致风险:第二阶段部分节点可能因网络故障未收到提交指令。
- TCC(Try-Confirm-Cancel)
- 流程:
- Try:预留资源(如冻结库存、预扣积分)。
- Confirm:确认操作(正式扣减库存)。
- Cancel:回滚资源(释放冻结库存)。
- 优点:最终一致性,性能较高()。
- 适用场景:电商库存扣减,需业务代码实现补偿逻辑。
- 示例:
// Try阶段:冻结库存 boolean tryResult = inventoryService.freezeStock(productId, num); // Confirm阶段:实际扣减 if (tryResult) inventoryService.confirmStock(productId, num); // Cancel阶段:释放冻结 else inventoryService.cancelStock(productId, num);
- 事务消息(MQ)
- 流程:
- 订单服务本地事务提交后发送事务消息到MQ(如RocketMQ)。
- MQ确保消息投递成功,库存服务消费消息执行库存扣减()。
- 优点:异步解耦,适合对实时性要求不高的场景。
- 缺点:需处理消息重复消费(通过幂等性解决)。
- Saga模式
- 流程:通过一系列本地事务和补偿事务串联实现全局事务。
- 示例:订单创建成功→扣减库存→若后续积分增加失败,触发库存回滚补偿。
选型对比:
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 2PC | 强 | 低 | 高 | 传统数据库事务 |
| TCC | 最终 | 高 | 高 | 高并发交易(如秒杀) |
| 事务消息 | 最终 | 中 | 中 | 异步处理(如库存扣减) |
| Saga | 最终 | 中 | 中 | 长事务流程(如支付) |
12. 订单超时未支付
核心挑战:订单超时后需释放库存并取消订单,避免资源占用和超卖。
解决方案:
-
延时消息(MQ)
- RabbitMQ:通过TTL+死信队列实现,支持海量消息但配置复杂。
- RocketMQ:内置定时消息功能(精度秒级),但最大延时24小时()。
-
定时任务批处理
- 实现:分布式任务框架(如阿里SchedulerX)扫描超时订单,批量处理。
- 优化:
- 分片处理:按订单ID哈希分片,避免单节点压力。
- 增量扫描:仅查询状态为“待支付”且超时的订单()。
-
Redis过期监听
- 流程:订单创建时写入Redis并设置超时时间,通过
KEYSPACE:EXPIRE事件触发回调。 - 缺点:Redis过期事件可能丢失,需结合数据库兜底。
- 流程:订单创建时写入Redis并设置超时时间,通过
-
本地延迟队列
- 实现:JDK的
DelayQueue或时间轮算法(如Netty的HashedWheelTimer)。 - 缺点:单机内存限制,无法分布式扩展()。
- 实现:JDK的
最佳实践:
- 组合方案:RocketMQ定时消息+定时任务兜底()。
- 补偿逻辑:
# 示例:超时后回滚库存 def cancel_order(order_id): if check_order_duplicate(order_id): update_order_status(order_id, '已取消') if check_payment_status(order_id) == '未支付': rollback_stock(order_id) # 回滚库存
13. 库存扣减方案
核心挑战:高并发下精准扣减库存,避免超卖(负库存)或数据不一致。
解决方案:
-
数据库行级锁
- 实现:使用
SELECT ... FOR UPDATE锁定库存行,更新时校验库存余量。 - 缺点:并发性能低,不适合秒杀场景()。
- 实现:使用
-
Redis原子操作
-
Lua脚本:保证查询和扣减的原子性。
-- 示例:Lua扣减库存 local stock = tonumber(redis.call('GET', KEYS[1])) if stock >= tonumber(ARGV[1]) then return redis.call('DECRBY', KEYS[1], ARGV[1]) else return -1 end -
优化:库存分片(如将库存拆分为
stock_1、stock_2),分散热点。
-
-
预扣库存与最终扣减
- 流程:
- 下单时预扣Redis库存,生成订单。
- 支付成功后扣减数据库库存,异步同步到Redis()。
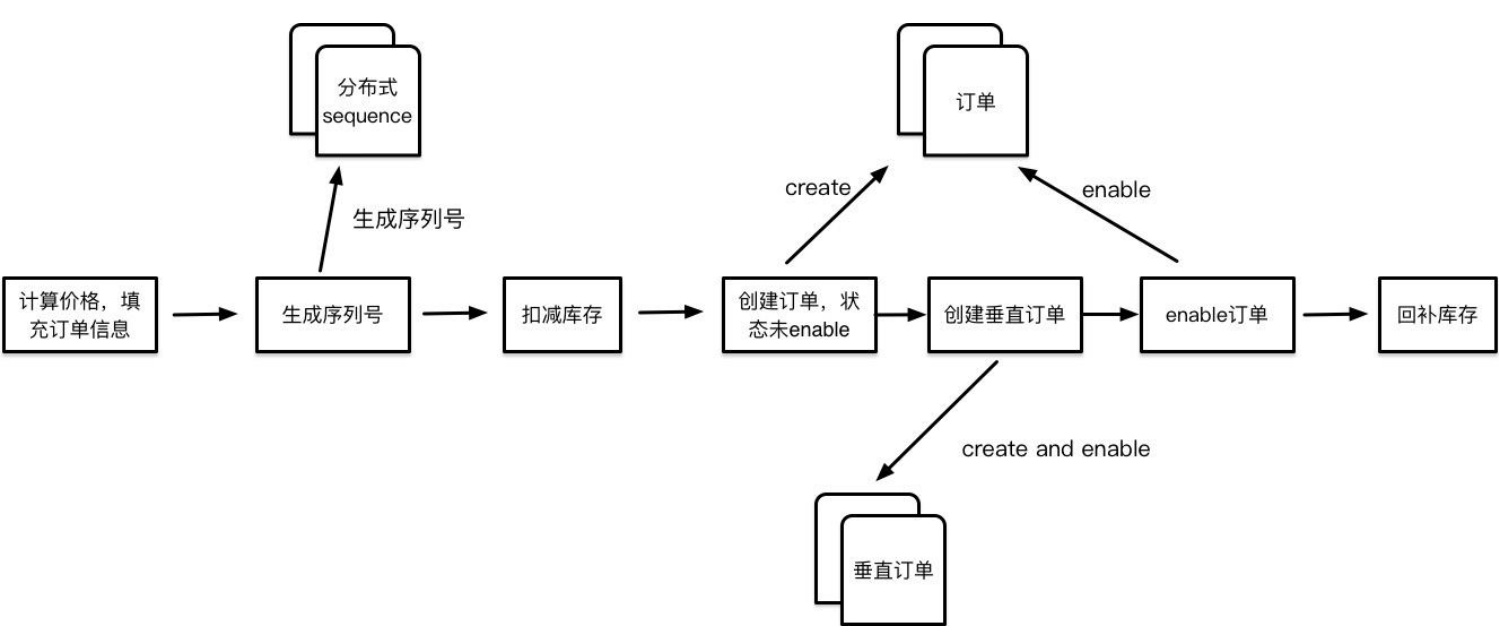
- 异步对账补偿
- 实现:定时任务比对Redis与数据库库存差异,触发补偿(如超扣时回滚)。
选型建议:
- 秒杀场景:Redis原子操作+库存分片。
- 普通交易:数据库行级锁+异步对账。
14. 热点 Key 问题
核心挑战:某商品库存Key(如stock:1001)在秒杀期间被高频访问,导致Redis或数据库性能瓶颈。
解决方案:
-
本地缓存+随机过期
- 实现:应用层缓存热点Key,设置随机过期时间(如10ms±2ms),减少Redis访问。
-
库存分片
- 示例:将库存1000拆分为10个分片(
stock_1~stock_10),请求随机路由到分片。
- 示例:将库存1000拆分为10个分片(
-
请求合并
- 实现:将多个扣减请求合并为批量操作(如累计扣减10件),减少IO次数。
-
限流与熔断
- 工具:Sentinel或Redis+Lua实现令牌桶限流。
极端场景处理:
- 动态扩容:秒杀前对热点Key所在Redis节点临时扩容。
- 兜底策略:降级为数据库扣减并加锁。
15. 订单号生成
核心要求:全局唯一、趋势递增、高并发、可读性。
解决方案:
-
雪花算法(Snowflake)
- 结构:时间戳(41bit)+机器ID(10bit)+序列号(12bit)。
- 优点:高性能、无需中心化协调。
- 缺点:时钟回拨可能导致重复。
-
数据库序列
- 实现:使用MySQL自增ID或
REPLACE INTO生成唯一ID。 - 优化:分库分表时设置不同初始值和步长(如步长=分片数)。
- 实现:使用MySQL自增ID或
-
Redis原子计数器
- 实现:
INCR命令生成序列号,结合业务前缀(如日期)拼接。// 示例:生成日期+Redis自增ID String date = new SimpleDateFormat("yyyyMMdd").format(new Date()); Long seq = redis.incr("order_id:" + date); String orderId = "ORD" + date + String.format("%06d", seq);
- 实现:
-
UUID
- 缺点:无序导致数据库索引效率低,通常不推荐。
选型建议:
- 分布式系统:雪花算法(需解决时钟回拨)。
- 分库分表:数据库序列+步长设置。
- 高并发:Redis计数器+本地缓存预生成。
16. 数据库慢查询优化
核心挑战:慢查询导致数据库性能下降,影响用户体验和系统稳定性。需从定位、分析到优化形成闭环。
系统化解决方案:
-
定位问题根源
-
启用慢查询日志:设置
long_query_time阈值(如2秒),记录所有超时查询。MySQL示例:SET GLOBAL slow_query_log = 1; SET GLOBAL long_query_time = 2; -- 单位:秒 -
分析执行计划:使用
EXPLAIN或EXPLAIN ANALYZE查看查询执行路径,关注type(扫描类型)、rows(扫描行数)、key(使用索引)等字段。EXPLAIN SELECT * FROM orders WHERE user_id = 1001; -
监控工具:NineData慢查询分析工具可自动采集日志并生成诊断报告,快速定位高频慢SQL。
-
-
SQL与索引优化
- 索引优化:
- 缺失索引:对高频过滤字段(如
user_id、order_time)添加组合索引。 - 冗余索引:定期清理未使用的索引(如通过
sys.schema_unused_indexes表)。 - 索引失效场景:避免在WHERE子句中使用函数或类型转换(如
WHERE DATE(create_time) = '2025-04-28')。- 重写复杂查询:
- 分页优化:避免
LIMIT 100000,10,改用基于游标的分页(如WHERE id > 100000 LIMIT 10)。 - 拆分JOIN:将多表关联拆分为多次查询,利用应用层缓存中间结果。
- 架构与配置优化
- 读写分离:将报表类查询路由到只读副本,减轻主库压力。
- 分库分表:当单表数据量超500万时,按时间或用户ID哈希拆分。
- 参数调优:
innodb_buffer_pool_size设置为物理内存的70%~80%。- 调整
max_connections避免连接耗尽。
- 高级工具与AI赋能
- 自动化推荐:美团基于AI的索引推荐系统,通过历史查询模式预测最优索引。
- 实时监控:华为云GeminiDB提供慢查询日志参数(如
lock_time、docs_scanned),支持精细化分析。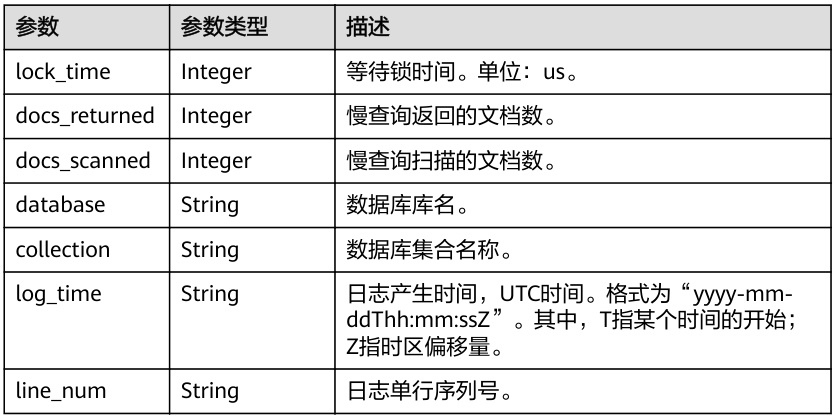
17. 分布式 Session 管理
核心挑战:集群环境下用户Session共享与一致性保障,需解决跨节点同步与高可用问题。
解决方案:
-
集中存储方案
-
Redis集群:将会话数据存储到Redis,利用其高并发和持久化能力。
// Spring Session配置示例 @EnableRedisHttpSession(maxInactiveIntervalInSeconds = 1800) public class SessionConfig {} -
序列化优化:使用Protostuff替代JDK序列化,减少存储空间和网络开销。
-
-
无状态方案
- JWT Token:将用户信息加密到Token中,客户端每次请求携带,服务端无需存储Session。
- 结构:Header(算法).Payload(数据).Signature(签名)
- 优点:天然支持跨域,适合微服务架构。
-
一致性保障
- 多级缓存:本地缓存(Caffeine)+ Redis,减少网络调用。
- 会话复制:Tomcat DeltaManager跨节点同步Session,但网络开销较大,仅适合小集群。
-
安全与容灾
- 加密存储:敏感信息(如用户ID)加密后存储,防止篡改。
- 降级策略:Redis宕机时,降级为本地Session,牺牲一致性保可用性。
18. 恶意刷单检测
核心挑战:识别并拦截异常下单行为(如黄牛脚本、薅羊毛),保障公平性和系统安全。
多维度风控策略:
- 规则引擎拦截
- 基础规则:
- 同一IP/设备ID 10分钟内下单超过5次。
- 同一用户账号秒杀成功率异常(如99%)。
- 关联分析:订单时间分布、收货地址相似度等。
- 机器学习模型
- 特征工程:
- 用户画像:历史订单频率、支付方式分布。
- 行为序列:点击流分析(如页面停留时间、下单路径)。
- 实时推理:Flink流处理 + 预训练模型(如XGBoost)实时打分,拦截高风险订单。
-
交互式验证
- 验证码升级:从图形验证码到行为验证(如滑块拼图、无感设备指纹)。
- 异步人工审核:对高风险订单人工复核,延迟发货。
-
数据溯源
- 日志埋点:全链路记录用户操作(IP、设备指纹、浏览器指纹)。
- 图谱分析:基于Neo4j构建用户-设备-IP关联网络,识别团伙行为。
19. 数据库慢查询检测及优化
全生命周期管理:
-
检测手段
- 慢查询日志:华为云GeminiDB日志参数包括
lock_time(锁等待时间)、docs_scanned(扫描文档数),帮助定位低效查询。 - 实时监控:NineData仪表盘展示慢查询QPS趋势、TOP SQL排行。
- 慢查询日志:华为云GeminiDB日志参数包括
-
自动化优化
- 索引推荐:NineData根据执行计划自动生成索引建议(如
ADD INDEX idx_user_status (user_id, status))。 - SQL审核:内置规则库拦截全表扫描、隐式类型转换等高风险操作。
- 索引推荐:NineData根据执行计划自动生成索引建议(如
-
持续调优
- A/B测试:对比优化前后执行时间(如使用
pt-query-digest工具)。 - 定期回滚:对无效索引(如3个月未命中)自动下线。
- A/B测试:对比优化前后执行时间(如使用
20. 推荐系统数据实时性(截至2025年04月28日)
核心技术栈与架构:
- 流批一体架构
- 数据管道:
- 实时流:Apache Flink处理用户点击/下单事件,窗口计算CTR(点击率)。
- 离线批:Spark构建用户长期兴趣画像。
- 特征存储:RedisVector(支持向量近似检索) + Apache Cassandra(宽表存储)。
-
在线学习
- 增量模型:TensorFlow Serving + FTRL(Follow-the-Regularized-Leader)算法,实时更新排序权重。
- 反馈闭环:用户隐式反馈(如停留时长)实时回流至特征工程。
-
高性能检索
- 向量索引:使用FAISS或HNSW算法,支持亿级向量毫秒级检索。
- 多路召回:协同过滤 + 语义向量 + 图网络,融合召回结果。
-
实时评估与监控
- A/B实验平台:分桶对比模型效果(如曝光点击率、转化率)。
- 数据漂移检测:监控特征分布偏移(如KS检验),触发模型重训练。
21. 退款流程
核心流程(以支付宝退款为例):
-
用户发起退款:用户在前端提交退款申请,携带订单号、退款原因。
-
风控校验:
- 业务规则:订单状态是否可退款(如已支付未发货)。
- 反欺诈检查:短时间高频退款触发风控(如1小时内退款3次)。
-
调用支付系统:
// 示例:调用支付宝退款接口 AlipayTradeRefundRequest request = new AlipayTradeRefundRequest(); request.setBizContent("{" + "\"out_trade_no\":\"202405010001\"," + // 商户订单号 "\"refund_amount\":100.00" + // 退款金额 "}"); AlipayTradeRefundResponse response = alipayClient.execute(request); -
状态同步与库存恢复:
- 支付系统回调通知退款成功,更新订单状态为“已退款”。
- 库存回滚:若商品已出库,需异步恢复库存(注意幂等性)。
-
资金原路退回:资金按支付渠道(银行卡/余额)原路返回,通常1-3个工作日到账。
关键问题:
- 部分退款:需拆分订单项粒度(如仅退某一SKU)。
- 逆向流水:财务系统需记录退款流水,与支付流水对账。
22. 线程池参数设置与电商大促调优
参数设置原则:
- 核心参数:
- corePoolSize:CPU密集型任务设为CPU核数+1(如8核设9),IO密集型可设2*CPU核数。
- maxPoolSize:根据系统负载和任务特性设定,通常为核心线程数的2~3倍。
- workQueue:
- 有界队列:
ArrayBlockingQueue(避免OOM),容量根据任务吞吐量设定。 - 优先级队列:
PriorityBlockingQueue(如VIP用户请求优先处理)。- 拒绝策略:
- CallerRunsPolicy:让提交任务的线程执行任务(避免请求丢失)。
- 大促调优策略:
-
动态调整:通过JMX或Spring Actuator实时修改参数。
ThreadPoolExecutor executor = (ThreadPoolExecutor) context.getBean("orderThreadPool"); executor.setCorePoolSize(20); // 动态扩容核心线程数 -
监控指标:
-
- 活跃线程数:
executor.getActiveCount() - 队列堆积:
executor.getQueue().size() - 拒绝次数:自定义
RejectedExecutionHandler统计。- 降级与熔断:队列满时触发降级(如返回“系统繁忙”提示)。
23. 解决电商秒杀超卖问题
全链路方案:
-
预扣库存:
- Redis原子操作:扣减库存时使用Lua脚本保证原子性。
-- KEYS[1]:库存Key, ARGV[1]:扣减数量 if tonumber(redis.call('GET', KEYS[1])) >= tonumber(ARGV[1]) then return redis.call('DECRBY', KEYS[1], ARGV[1]) else return -1 end
- Redis原子操作:扣减库存时使用Lua脚本保证原子性。
-
异步落库:
- 预扣成功后,将订单信息写入MQ,由消费者异步更新数据库库存。
-
库存分片:
- 将库存拆分为多个Key(如
stock_1、stock_2),分散Redis压力。
- 将库存拆分为多个Key(如
-
兜底校验:
- 数据库最终扣减时二次检查:
UPDATE product SET stock = stock - #{num} WHERE id = #{id} AND stock >= #{num};
- 数据库最终扣减时二次检查:
-
对账补偿:
- 定时任务比对Redis与数据库库存,发现超扣时触发补偿(如退款或补货)。
24. 微服务架构下商品服务拆分
拆分原则与方案:
- 领域驱动设计(DDD):
- 核心子域:
- 商品信息服务:管理SPU/SKU、价格、类目(独立服务)。
- 库存服务:库存扣减、预占、预警(高并发独立部署)。
- 评价服务:评价、评分、晒单(可读多写少,用缓存优化)。
-
通信设计:
- 同步调用:商品详情页聚合评价信息(Feign调用)。
- 异步事件:商品价格变更时发MQ通知促销服务更新活动价。
-
数据库拆分:
- 商品库:MySQL分库(按类目ID哈希)。
- 评价库:ES存储全文搜索,MongoDB存储非结构化数据。
-
API设计:
- 读多写少:商品查询接口添加多级缓存(Redis + 本地缓存)。
- 写操作:库存扣减接口单独部署,与读服务隔离。
示例架构图:
用户请求 → API网关 → [商品服务 | 库存服务 | 评价服务]
↓ ↓ ↓
MySQL Redis Elasticsearch
25. 主从数据库读写分离的数据不一致解决方案
问题根源:主从同步延迟导致“写后读”不一致(如用户支付后查询不到订单)。
解决方案:
-
强制读主库:
- 业务标记:对需要实时性的查询(如支付结果页)强制走主库。
// Sharding-JDBC 强制路由主库 HintManager.getInstance().setMasterRouteOnly();
- 业务标记:对需要实时性的查询(如支付结果页)强制走主库。
-
半同步复制:
- MySQL半同步:主库等待至少一个从库ACK后才返回成功。
- 代价:增加写操作延迟(通常可接受)。
-
延迟检测与等待:
- 工具:Percona Toolkit的
pt-heartbeat监控主从延迟。 - 应用逻辑:若延迟超过阈值(如200ms),查询时短暂重试或提示用户刷新。
- 工具:Percona Toolkit的
-
缓存中间层:
- 写缓存:主库写入后,更新Redis缓存并设置短暂过期时间(如1秒)。
- 读缓存:优先读缓存,缓存未命中时查从库。
-
最终一致性补偿:
- 监听Binlog:通过Canal监听主库变更,异步刷新从库或缓存。
方案对比:
| 方案 | 实时性 | 复杂度 | 适用场景 |
|---|---|---|---|
| 强制读主 | 强 | 低 | 关键业务(支付结果页) |
| 半同步复制 | 较强 | 中 | 金融级一致性要求 |
| 缓存+延迟检测 | 最终 | 高 | 高并发读场景 |
26. 如何保证支付系统的可靠性?
核心挑战:支付链路涉及资金安全,需同时应对高并发、数据一致性、容灾能力等要求。
解决方案:
-
多级冗余架构:
- 多机房部署:支付系统跨地域部署(如北京、上海双活),通过GSLB实现流量调度。
- 主从热备:数据库采用半同步复制(Semi-Sync Replication),确保主库宕机时从库数据完整。
-
事务与幂等性保障:
- TCC事务模型:在扣款、记账、通知等环节实现Try-Confirm-Cancel,支持跨服务事务补偿。
- 幂等设计:支付流水号全局唯一(如雪花算法),通过Redis分布式锁拦截重复请求。
-
异步对账与容灾:
- 对账机制:日终比对银行通道、支付系统、商户系统三方流水,自动触发差错处理(如补单/退款)。
- 灾备演练:定期模拟机房级故障,验证秒级切换能力(如通过Chaos Engineering工具)。
-
安全与合规:
- PCI DSS合规:敏感数据(如卡号)加密存储,密钥轮换周期≤90天,网络隔离DMZ区。
- 风控拦截:实时检测异常行为(如单IP高频支付),结合规则引擎+机器学习模型拦截。
典型架构示例:
用户 → 支付网关 → [风控服务] → [账户服务] → [渠道服务] → 银行
↓ ↓ ↓
Redis集群 MySQL分库分表 MQ异步通知
27. 购物车设计,遇到的问题及方案
核心挑战:高并发下购物车数据一致性、合并逻辑(多端登录)、过期商品清理。
解决方案:
-
数据结构设计:
- Redis Hash结构:Key=用户ID,Field=商品SKU,Value=数量/选中状态/过期时间。
HSET cart:1001 "sku_123" "{'num':2, 'selected':1, 'expire':1735689600}"
- Redis Hash结构:Key=用户ID,Field=商品SKU,Value=数量/选中状态/过期时间。
-
分布式会话管理:
- 未登录态合并:设备指纹(如浏览器Cookie+IP)临时存储,登录后与账号数据合并。
- 冲突解决:基于版本号(Vector Clock)或最后写入优先(LWW)策略。
-
性能与容错:
- 本地缓存:Guava Cache缓存热点用户购物车,降低Redis读压力(TTL=5秒)。
- 异步持久化:购物车变更写入Kafka,由消费者批量落库(MySQL)。
-
业务逻辑难点:
- 库存预占:加入购物车时预占Redis库存(需设置TTL防止死锁)。
- 价格同步:商品价格变更时,通过Binlog监听触发购物车价格刷新。
典型问题与优化:
- 问题1:用户AB同时修改同一SKU数量导致覆盖。
方案:Redis WATCH命令实现乐观锁,冲突时重试。 - 问题2:促销商品过期后购物车清理。
方案:ZSet存储商品过期时间,定时任务扫描并通知用户。
28. 订单历史数据如何优化存储?
分层存储策略:
-
在线库(热数据):
- 分库分表:按用户ID哈希分库,订单时间范围分表(如每月一张表)。
- 索引优化:对
user_id+status建立联合索引,避免全表扫描。
-
近线库(温数据):
- ES冷热分离:3个月前的订单迁移到ES,利用
_routing按用户ID分片。 - 列式存储:Parquet格式存储HDFS,供BI分析使用(如用户购买频次分析)。
- ES冷热分离:3个月前的订单迁移到ES,利用
-
离线归档(冷数据):
- 对象存储:1年以上的订单压缩后存入S3/OSS,保留法律要求的访问接口。
关键技术:
- 动态数据迁移:通过Canal监听MySQL Binlog,实时同步到ES/S3。
- 查询统一入口:使用Apache Calcite实现联邦查询,屏蔽底层存储差异。
成本对比:
| 存储层 | 成本(元/GB/月) | 查询延迟 | 适用场景 |
|---|---|---|---|
| MySQL | 10 | <10ms | 实时交易 |
| ES | 5 | 100ms | 近半年订单查询 |
| S3 | 0.3 | 1s | 历史订单归档下载 |
29. 谈谈你对CAP理论的理解
核心观点:在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得,需根据场景权衡。
典型场景应用:
-
CP系统(支付系统):
- 选择:强一致性优先,牺牲部分可用性。
- 案例:支付时主库故障,宁可返回失败也不允许金额不一致。
-
AP系统(购物车):
- 选择:高可用优先,接受最终一致性。
- 案例:多端添加商品时允许短暂差异,通过异步合并解决。
-
CA系统(单机数据库):
- 限制:无分区容错,仅适合单点部署(如小型ERP系统)。
辩证理解:
- CAP是动态权衡:网络分区发生时需临时决策(如支付系统降级为AP,事后对账补偿)。
- 细化模型:PACELC理论扩展了CAP,强调延迟(Latency)与一致性(Consistency)的权衡。
设计启示:
- 支付系统采用TCC(CP) + 异步补偿(最终一致)。
- 电商库存采用Redis分片(AP) + 数据库兜底(CP)。
30. 分库分表的设计与分页查询
分库分表策略:
-
垂直拆分:
- 分库:订单库与用户库分离,减少JOIN操作。
- 分表:将宽表拆分为订单主表(id, user_id, amount)和扩展表(优惠券、物流信息)。
-
水平拆分:
- 哈希分片:按
user_id % 64将数据散列到64个库,每个库16张表。 - 时间分片:近3个月订单存在热库,历史数据按月归档到冷库。
- 哈希分片:按
分页查询难题与方案:
-
二次查询法(Elasticsearch同步):
- 步骤:
-
查询ES获取满足条件的订单ID列表(带排序)。
-
根据ID从分库中获取完整数据。
- 缺点:ES数据延迟(通常控制在1s内)。
-
全局视野法(中间件实现):
- 逻辑:
- 每个分库返回按时间倒序的前N条数据。
- 中间件对所有结果归并排序,取全局前M条。
- 限制:页码越大性能越差(如查询第100页需扫描100*N条数据)。
- 业务妥协方案:
- 禁止跳页:仅支持“下一页”操作,基于最后一条记录的排序字段值查询。
- 游标分页:将
last_id和last_time作为查询条件,避免OFFSET。
性能对比:
| 方案 | 适用场景 | 复杂度 | 页码限制 |
|---|---|---|---|
| ES同步 | 复杂条件查询 | 高 | 无 |
| 二次查询 | 简单分页 | 中 | 页码≤100 |
| 游标分页 | 无限滚动 | 低 | 仅顺序翻页 |
31. 分库分表的路由设计及查询
路由策略:
-
静态路由:
- 哈希取模:
user_id % 1024直接映射到具体表,扩容需迁移数据。 - 范围分片:按时间范围(如每月一张表),适合冷热分离。
- 哈希取模:
-
动态路由:
- 一致性哈希:虚拟节点环减少数据迁移量,扩容时仅影响相邻节点。
- 配置中心:ZooKeeper存储分片规则,支持在线调整。
查询优化:
-
精准查询:
- 直接路由:已知分片键(如
order_id)时,解析ID中的分库分表信息。 - 案例:订单ID= timestamp + user_id_hash + seq,解析user_id_hash定位库表。
- 直接路由:已知分片键(如
-
模糊查询:
- 广播查询:无分片键时全库并发查询,性能差但兼容性强。
- 基因法:将关联字段(如
product_id)冗余到订单表,支持按商品维度查询。
-
JOIN查询:
- ER分片:将关联表(订单、订单项)按相同分片规则分布,本地JOIN。
- 全局表:小表(如商品类目)全量复制到所有分库。
典型路由中间件对比:
| 类型 | 代表产品 | 优点 | 缺点 |
|---|---|---|---|
| SDK嵌入 | Sharding-JDBC | 高性能,无代理单点 | 语言绑定(仅Java) |
| Proxy | MyCat | 多语言支持 | 性能损耗(20%~30%) |
| Sidecar | Vitess | 云原生友好 | 运维复杂度高 |
总结:以上方案需结合业务阶段选择。初创企业可采用Sharding-JDBC快速落地,中大型企业建议Proxy方案统一管理,云原生环境优先考虑Vitess。分页查询需在性能与功能间权衡,核心交易链路推荐游标分页+ES补充查询。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)