
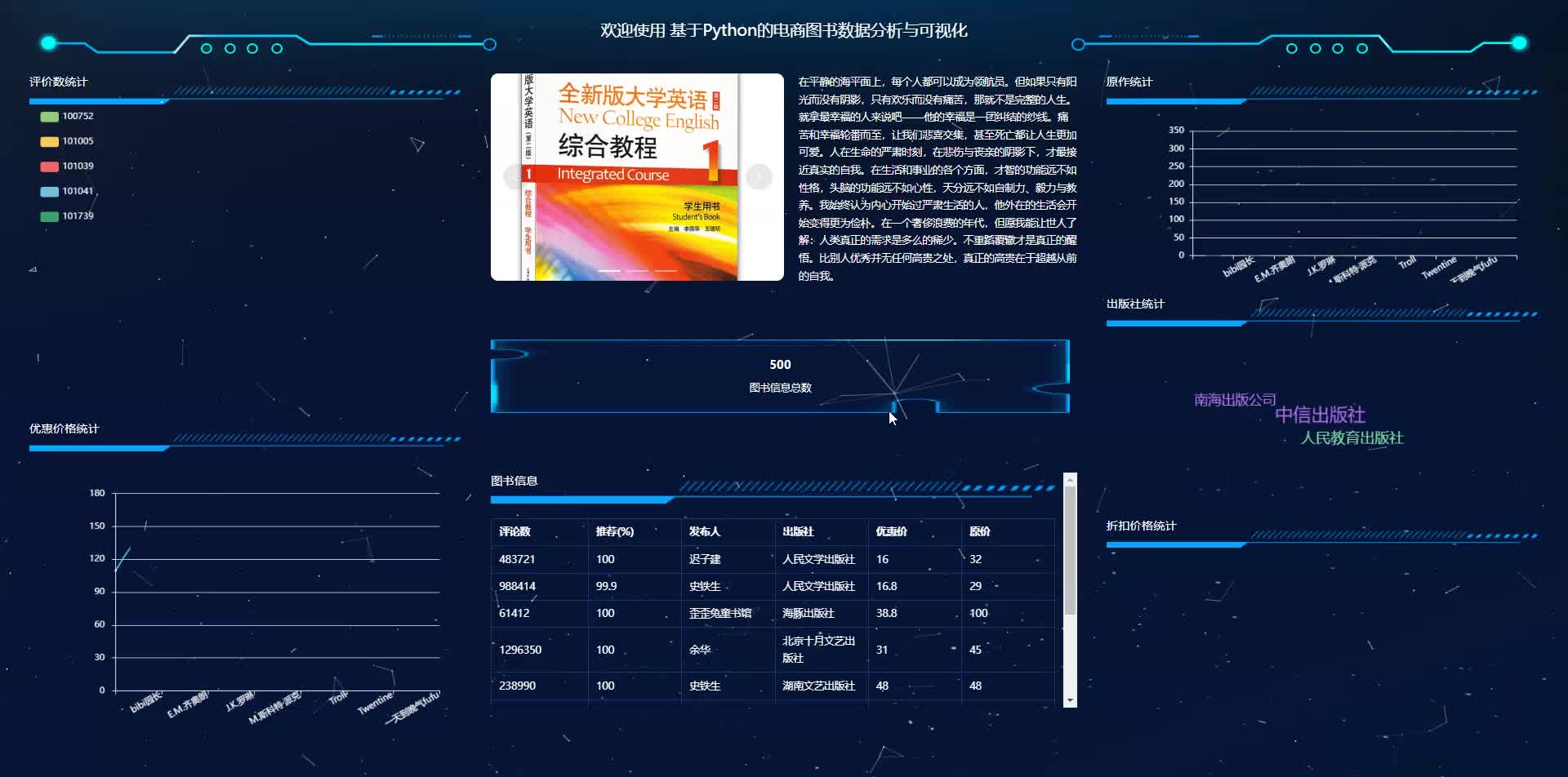
基于python+django的电商图书数据分析与可视化大数据分析系统
采用Python+Django框架搭建后端服务,结合MySQL/PostgreSQL数据库存储数据,使用Pandas、NumPy进行数据处理,Matplotlib、Seaborn、Plotly或ECharts实现可视化展示。通过爬虫或API接口获取图书销售数据(如京东、当当等平台),使用Pandas清洗无效数据、处理缺失值、去重及标准化格式。该系统需根据实际业务需求调整分析维度和可视化形式,建议初
系统架构设计
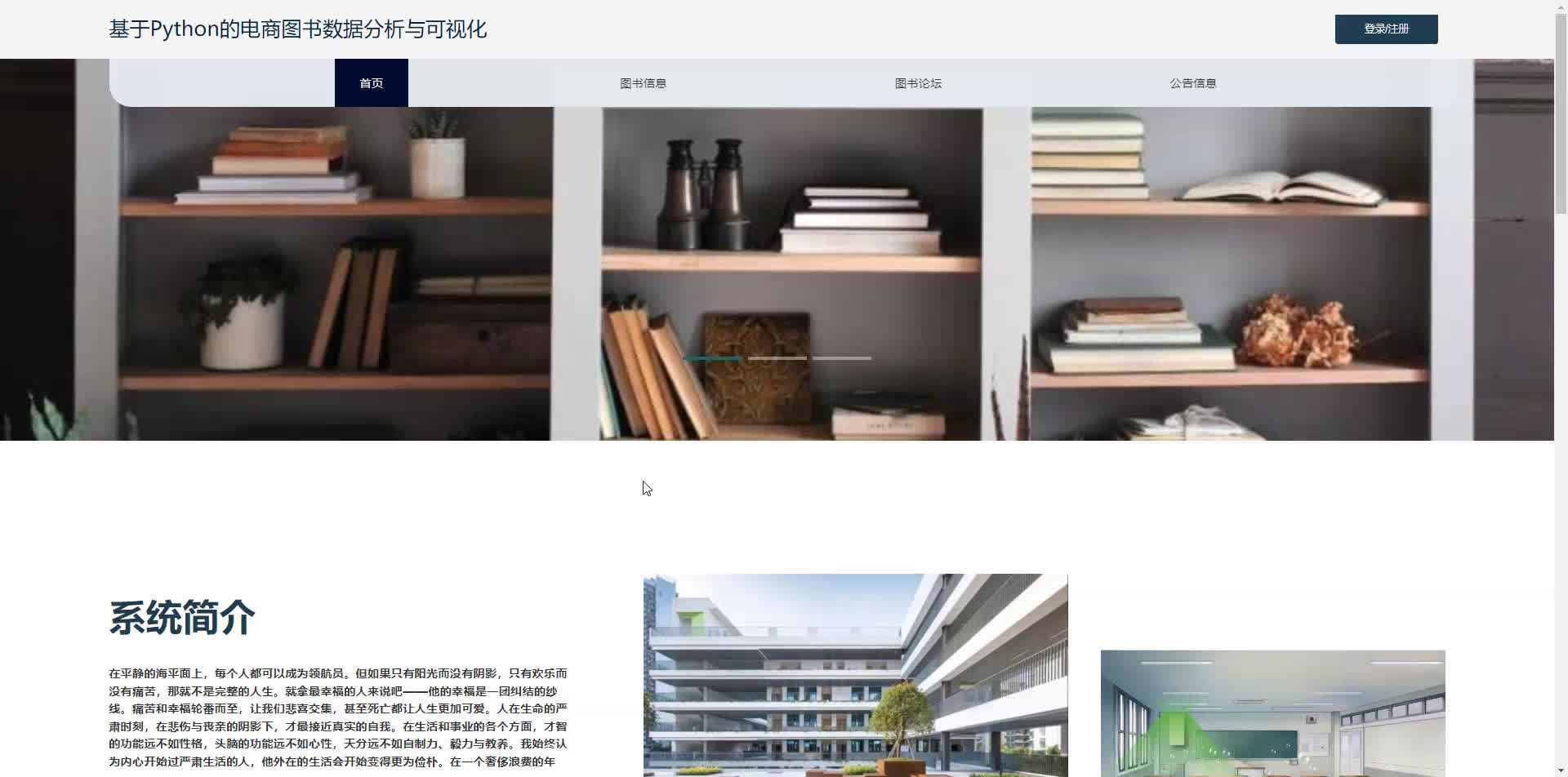
采用Python+Django框架搭建后端服务,结合MySQL/PostgreSQL数据库存储数据,使用Pandas、NumPy进行数据处理,Matplotlib、Seaborn、Plotly或ECharts实现可视化展示。前端可选择Django模板渲染或前后端分离架构(如Vue.js/React)。
核心功能模块
数据采集与清洗 通过爬虫或API接口获取图书销售数据(如京东、当当等平台),使用Pandas清洗无效数据、处理缺失值、去重及标准化格式。示例代码:
import pandas as pd
def clean_data(df):
df.drop_duplicates(inplace=True)
df['price'] = df['price'].fillna(df['price'].median())
return df
数据分析模型 构建销量预测、用户行为分析等模型。使用Scikit-learn实现线性回归或时间序列分析:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
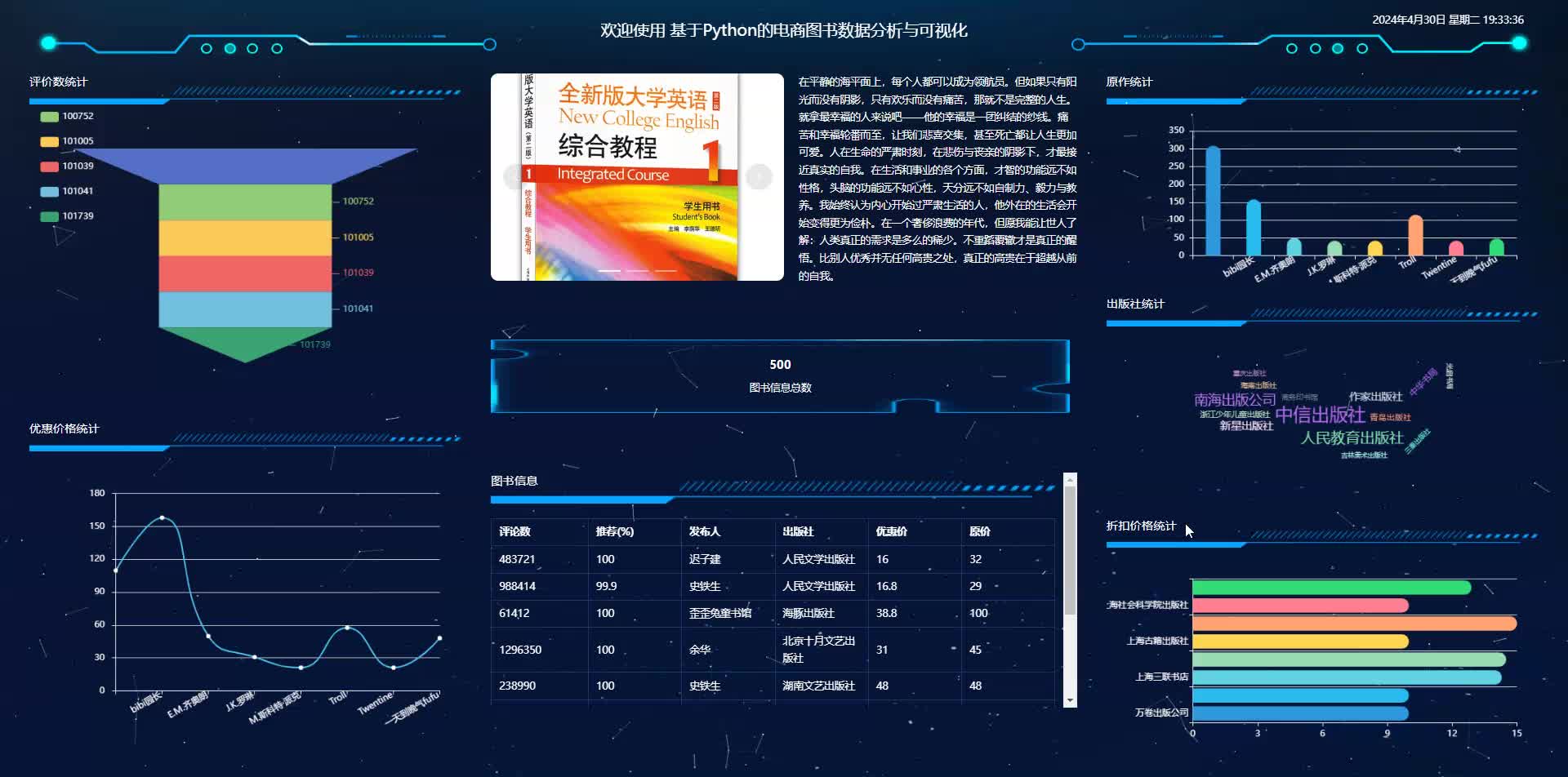
可视化展示 通过Django集成可视化库,动态生成图表。Plotly示例:
import plotly.express as px
fig = px.bar(df, x='category', y='sales', title='图书品类销售分布')
fig.show()
技术实现步骤
数据库设计 创建图书、用户、订单等核心表。Django模型示例:
class Book(models.Model):
title = models.CharField(max_length=200)
price = models.DecimalField(max_digits=10, decimal_places=2)
sales = models.IntegerField(default=0)
API接口开发 使用Django REST framework构建数据分析接口:
from rest_framework.views import APIView
class SalesAnalysisAPI(APIView):
def get(self, request):
data = calculate_sales_trend()
return Response(data)
定时任务调度 通过Celery定期更新数据和分析结果:
@app.task
def update_daily_sales():
df = fetch_new_data()
analyze_sales(df)
部署与优化
性能优化
- 使用Redis缓存高频访问数据
- 对大数据表添加索引
- 采用分页加载可视化数据
安全措施
- 实现JWT身份验证
- 对敏感数据脱敏处理
- 防止SQL注入和XSS攻击
扩展功能
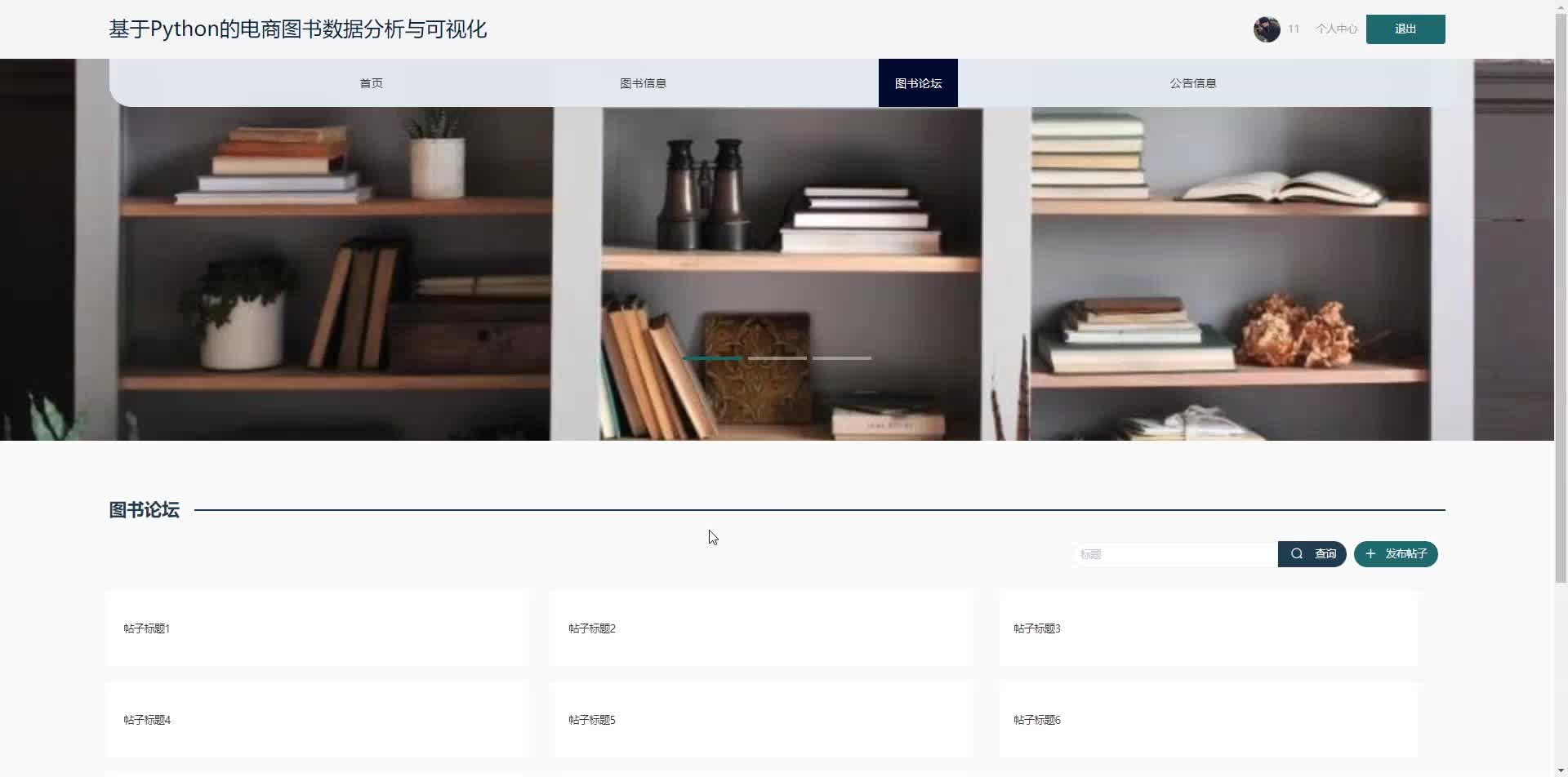
用户画像分析 通过聚类算法划分用户群体,生成购买偏好标签
智能推荐系统 基于协同过滤算法实现个性化图书推荐
移动端适配 通过响应式设计或开发配套小程序扩大覆盖范围
该系统需根据实际业务需求调整分析维度和可视化形式,建议初期聚焦核心指标如销售额、用户转化率、热销品类等,逐步扩展复杂分析功能。


电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)