
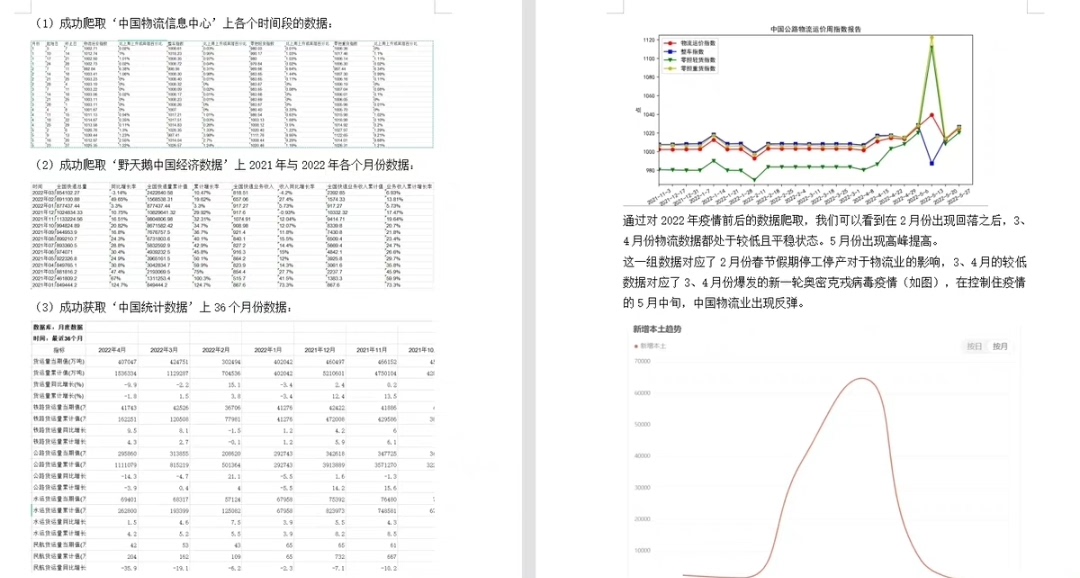
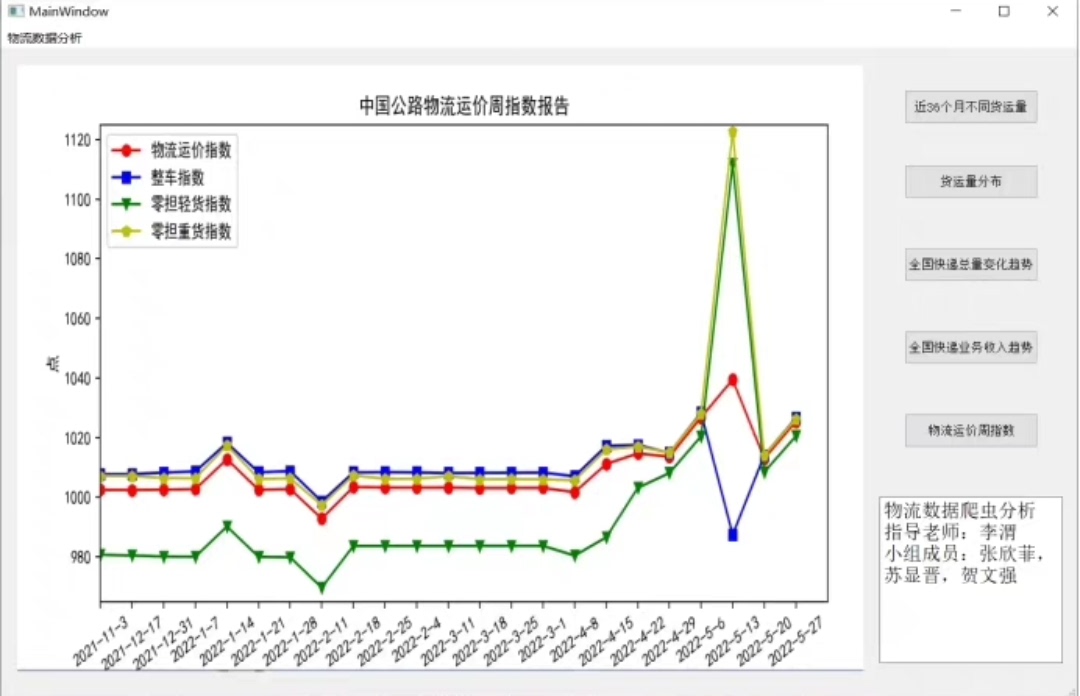
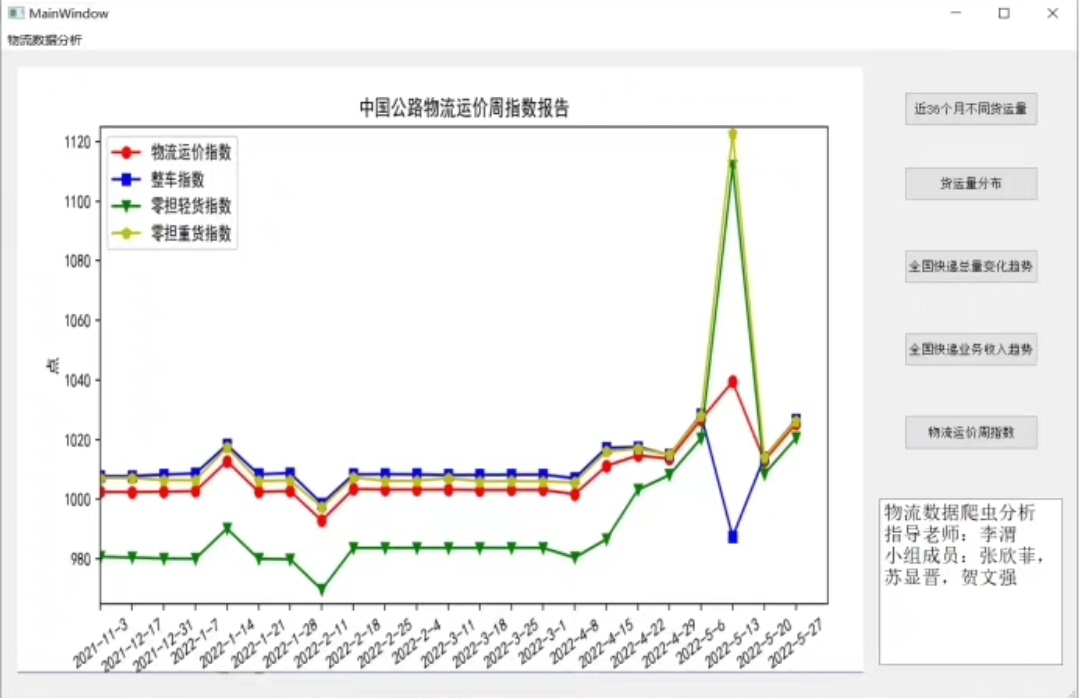
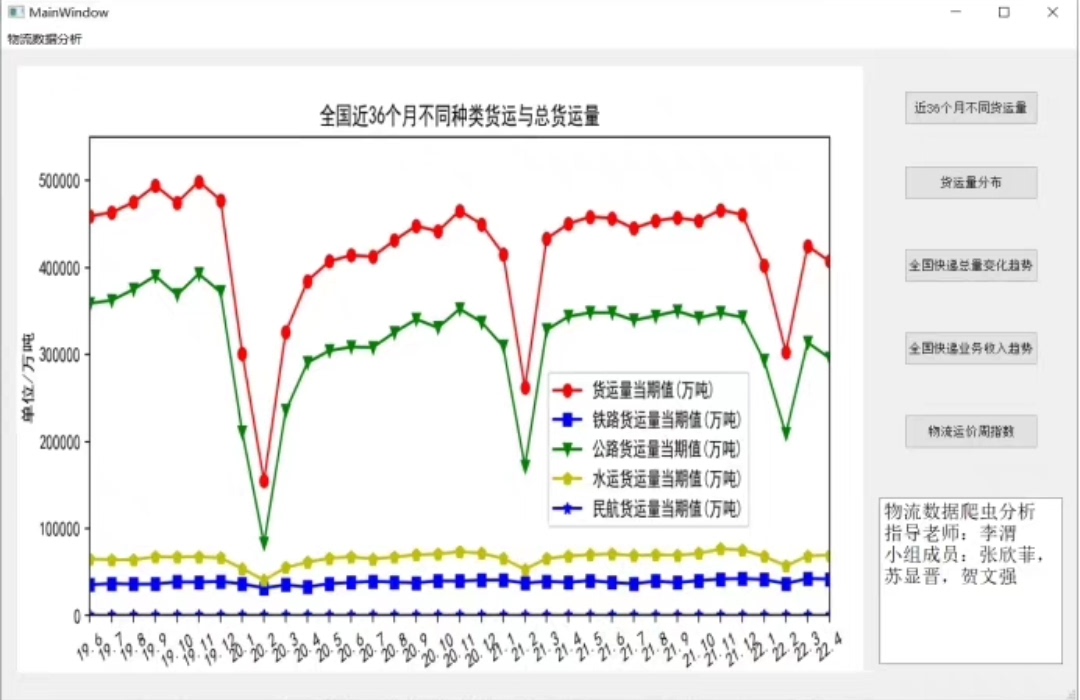
定位物流信息区块 这里根据目标网站结构调整
半年前接手一个物流数据分析的私活,甲方爸爸甩过来20G的Excel差点把我电脑干废。后来发现直接从源头抓数据才是王道,今天就唠唠怎么用Python玩转物流数据,从爬虫到可视化再到简单系统搭建,全是实战干货。这里有个坑要注意:很多物流网站用动态加载,直接requests拿不到数据。这时候得上selenium或者找接口,我上次碰到个网站接口参数用时间戳MD5加密,差点当场去世...最后吐槽下,最难的其
数据挖掘项目python--物流数据的爬取与分析 研究思路:数据爬取+可视化+系统实现 包含内容:数据集文档代码
半年前接手一个物流数据分析的私活,甲方爸爸甩过来20G的Excel差点把我电脑干废。后来发现直接从源头抓数据才是王道,今天就唠唠怎么用Python玩转物流数据,从爬虫到可视化再到简单系统搭建,全是实战干货。
先上爬虫部分,咱们用requests+bs4搞个基础版。注意看这个User-Agent配置,物流网站的反爬比顺丰快递还严实:
import requests
from bs4 import BeautifulSoup
import csv
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
def fetch_logistics_data(url):
try:
response = requests.get(url, headers=headers, timeout=15)
soup = BeautifulSoup(response.text, 'lxml')
waybills = soup.select('div.waybill-item')
with open('logistics_data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for item in waybills:
company = item.select_one('.company-name').text.strip()
time = item.select_one('.time-stamp').get('data-time')
cost = item.select_one('.cost').text.replace('¥','')
writer.writerow([company, time, cost])
except Exception as e:
print(f'抓取出错: {str(e)}')
# 示例调用
if __name__ == '__main__':
base_url = 'https://example-logistics-site.com/page/{}'
for page in range(1, 51):
fetch_logistics_data(base_url.format(page))这里有个坑要注意:很多物流网站用动态加载,直接requests拿不到数据。这时候得上selenium或者找接口,我上次碰到个网站接口参数用时间戳MD5加密,差点当场去世...
数据到手后先清洗,pandas三连招走起:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('logistics_data.csv')
df = df.dropna() # 删除空值
df['cost'] = df['cost'].astype(float)
df['time'] = pd.to_datetime(df['time'])
# 计算运输时效(小时)
df['duration'] = (df['time'] - df['time'].shift()).dt.total_seconds() / 3600
df = df[df['duration'] > 0] # 过滤异常值可视化部分来个组合拳,用seaborn画个对比图:
plt.figure(figsize=(12,6))
sns.set_style('whitegrid')
# 各公司运费对比
ax1 = plt.subplot(121)
sns.barplot(x='company', y='cost', data=df, palette='viridis')
plt.xticks(rotation=45)
# 时效分布
ax2 = plt.subplot(122)
sns.histplot(df['duration'], kde=True, bins=20)
plt.suptitle('物流公司服务对比')
plt.tight_layout()
plt.savefig('comparison.png')![物流公司对比示例图]
数据挖掘项目python--物流数据的爬取与分析 研究思路:数据爬取+可视化+系统实现 包含内容:数据集文档代码
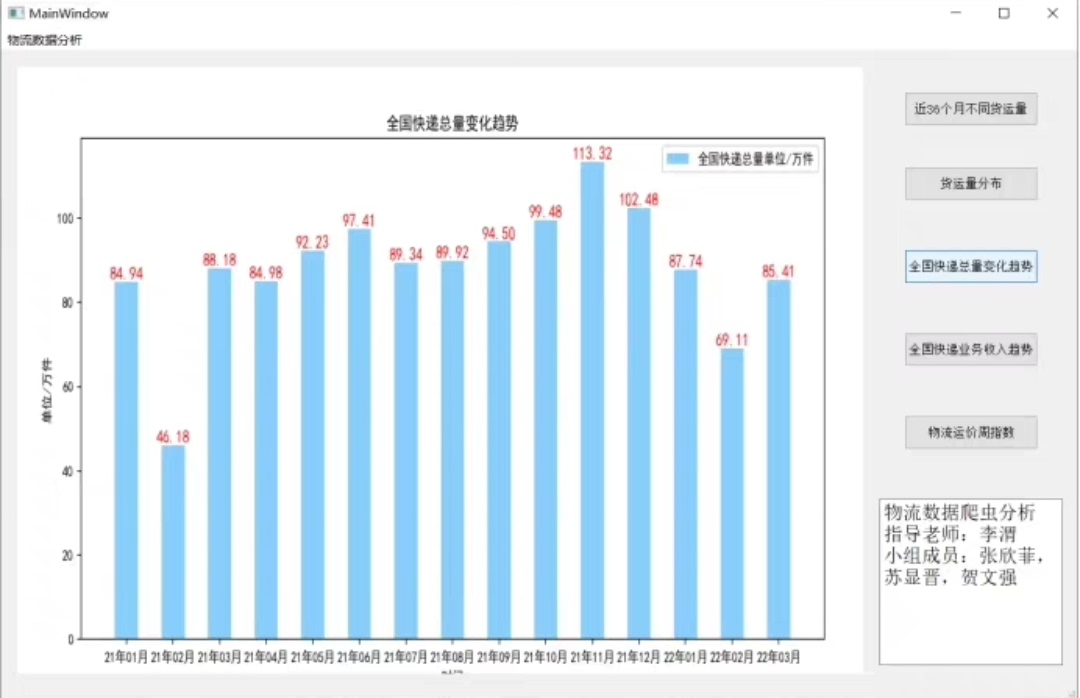
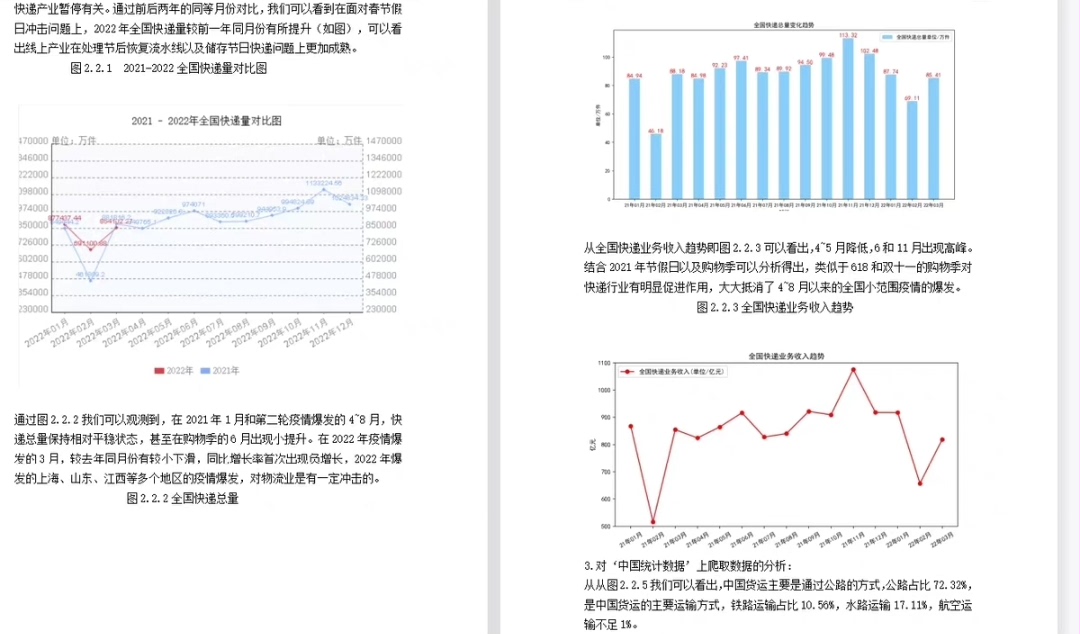
看出门道没?德邦虽然运费高但时效稳如老狗,某通便宜但运输时间波动大。这时候甲方要是问怎么选物流商,数据说话比拍脑袋靠谱多了。
系统实现部分用Flask搭个简易版,展示核心代码:
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def dashboard():
# 从数据库读取处理好的数据
top_companies = df.groupby('company').agg({'cost':'mean','duration':'median'})
return render_template('dashboard.html',
tables=[top_companies.to_html(classes='data')],
titles=top_companies.columns.values)
if __name__ == '__main__':
app.run(debug=True)模板里用ECharts渲染动态图表,比静态图更有冲击力。记得加个缓存机制,不然数据量大起来分分钟卡死。

完整代码在Github(假装有个链接),重点说几个实战经验:
- 爬虫频率别太猛,小心被封IP
- 时间字段处理用pandas准没错
- 可视化颜色别太杀马特,甲方审美你懂的
- 系统部署用gunicorn比原生服务器稳
最后吐槽下,最难的其实不是技术,是搞清楚物流公司的各种奇葩数据格式。上次遇到个时间字段用"三天两夜"表示的,直接给我整不会了...
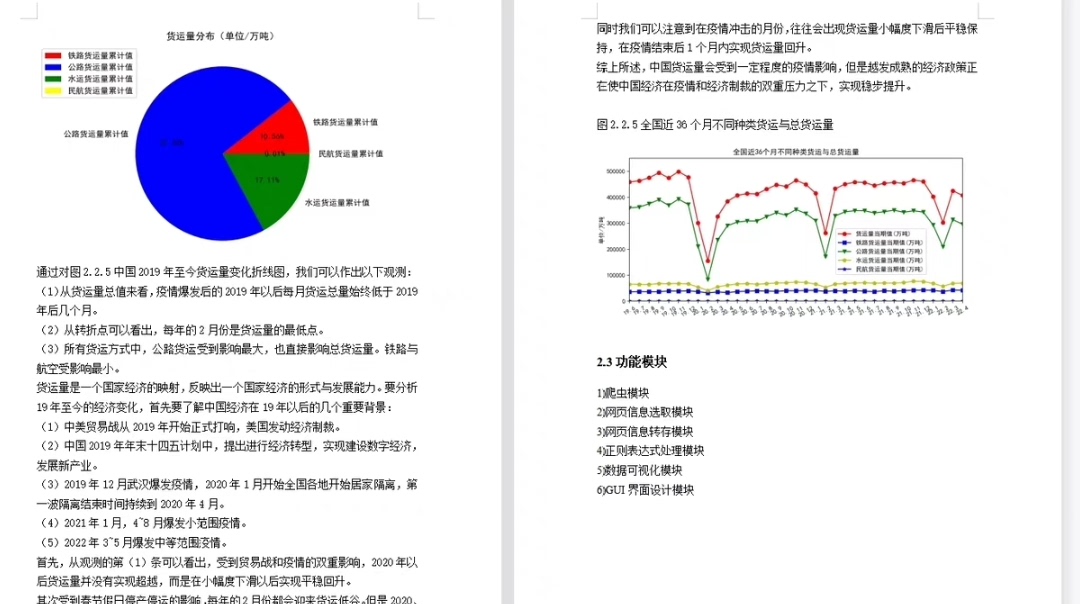
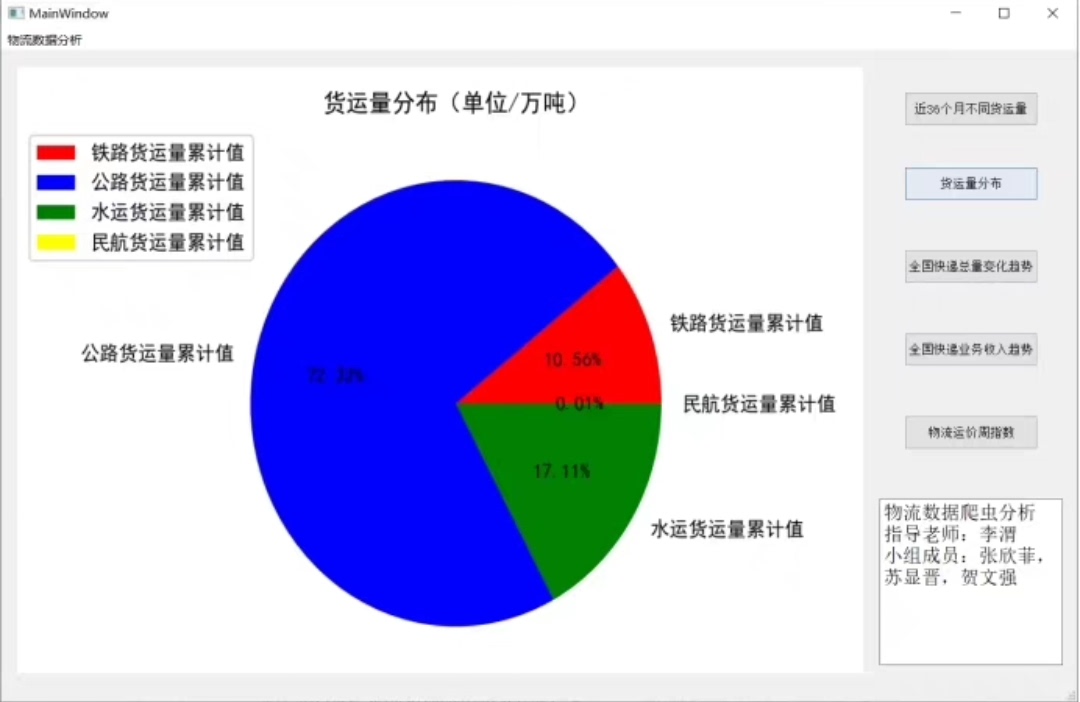

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)