
影刀RPA新手教程:跨境电商选品完全指南——AliExpress热卖商品分析与竞品调研自动化
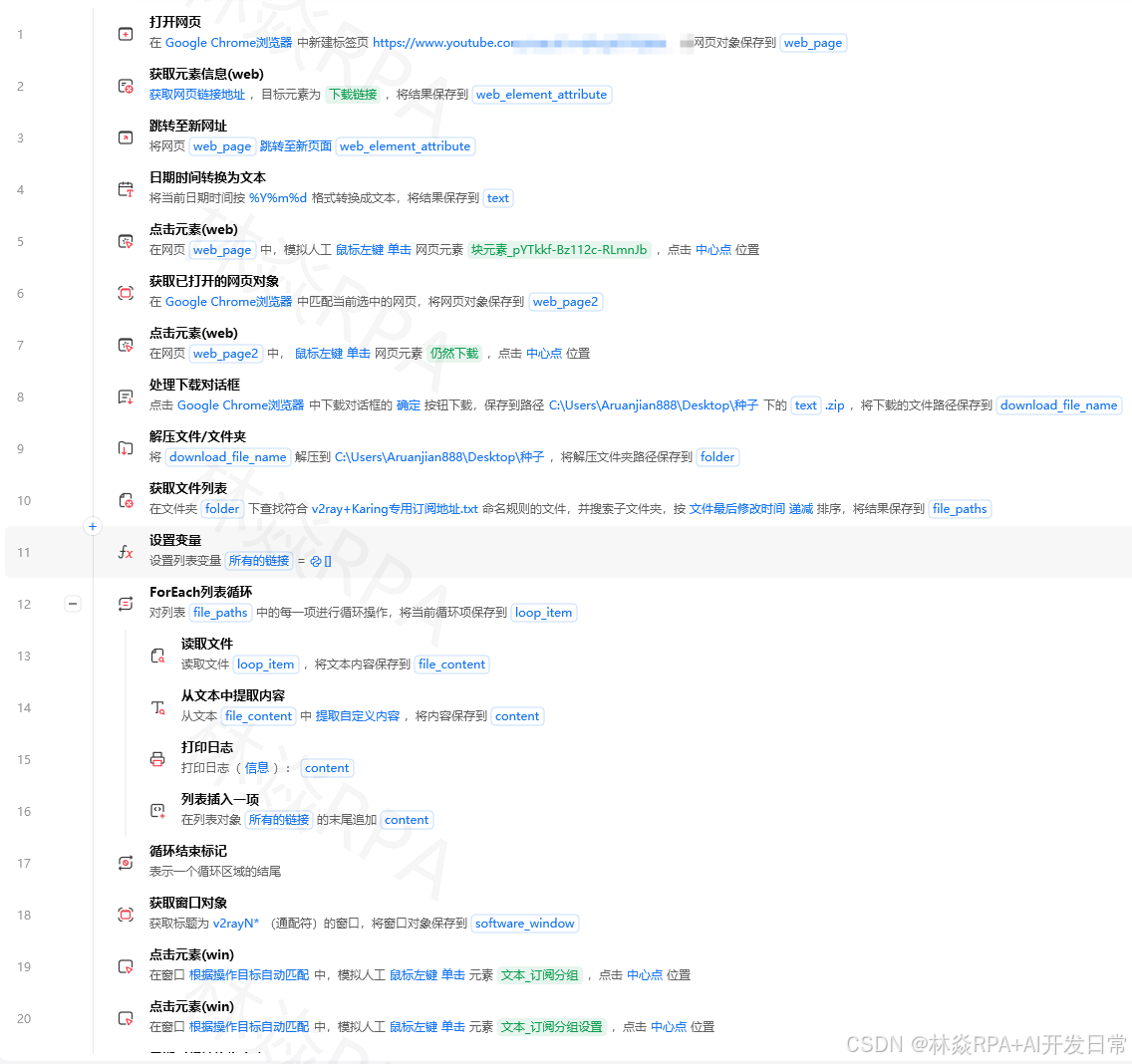
影刀RPA新手教程:跨境电商选品完全指南——AliExpress热卖商品分析与竞品调研自动化
作者:林焱 | 实战向 | 全文约2500字
前言
做跨境电商,选品决定生死。但选品最痛苦的是数据收集——AliExpress上一个个点开商品,记录价格、销量、评分、评论数,一个品类看下来眼睛都花了,还容易抄错数据。
我用影刀RPA做过一个AliExpress选品数据采集方案,每天自动采集指定品类的前200个热卖商品数据,存到Excel里,再用Python做简单分析,十分钟就能判断一个品类值不值得做。
本篇把这套方案完整讲一遍,从AliExpress页面结构特点到反爬策略,都是实战踩坑之后的经验。
店群矩阵自动化突破运营极限!
一、安装与初始化
AliExpress是跨境电商最重要的平台之一,但它的页面结构和国内淘宝完全不同,有几个特点需要注意。
第一,AliExpress有严格的访问频率限制,操作太快会直接封IP。
第二,商品页面有大量异步加载内容,需要等待元素出现。
第三,有些数据在移动端页面和PC端不一样,建议用移动端User-Agent采集,数据更干净。
影刀配置:
浏览器:Chrome
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 15_0 like Mac OS X) ...
代理设置:建议使用住宅代理,避免IP被封
页面加载等待:隐式等待10秒
我当时第一次做AliExpress采集,没设User-Agent,用的是默认PC端,结果页面结构和教程对不上,浪费了半天时间。
二、元素定位四合一
AliExpress的商品列表页和详情页元素定位,需要准备多套方案。
商品列表页——商品卡片:
AliExpress商品列表每个商品卡片的class是动态生成的,但有几个属性是稳定的。
//div[contains(@class,'product-card')]
//a[contains(@href,'/item/')]
//span[contains(@class,'price')]
//span[contains(@class,'orders')]
商品详情页——价格:
AliExpress的价格显示有几种形式:单价、区间价、折扣价。需要分别获取。
//span[@class='product-price-current']
//span[@class='product-price-original']
//div[@class='discount-badge']
CSS选择器备用方案:
div[class*="product"][class*="card"]
span[class*="price"]
span[data-testid="price"]
我当时遇到一个问题:AliExpress的DOM结构和国内淘宝不一样,它的价格是放在shadow DOM里的,用普通的XPath获取不到。解决方法是用"在网页元素上执行JavaScript"指令,通过shadow root获取。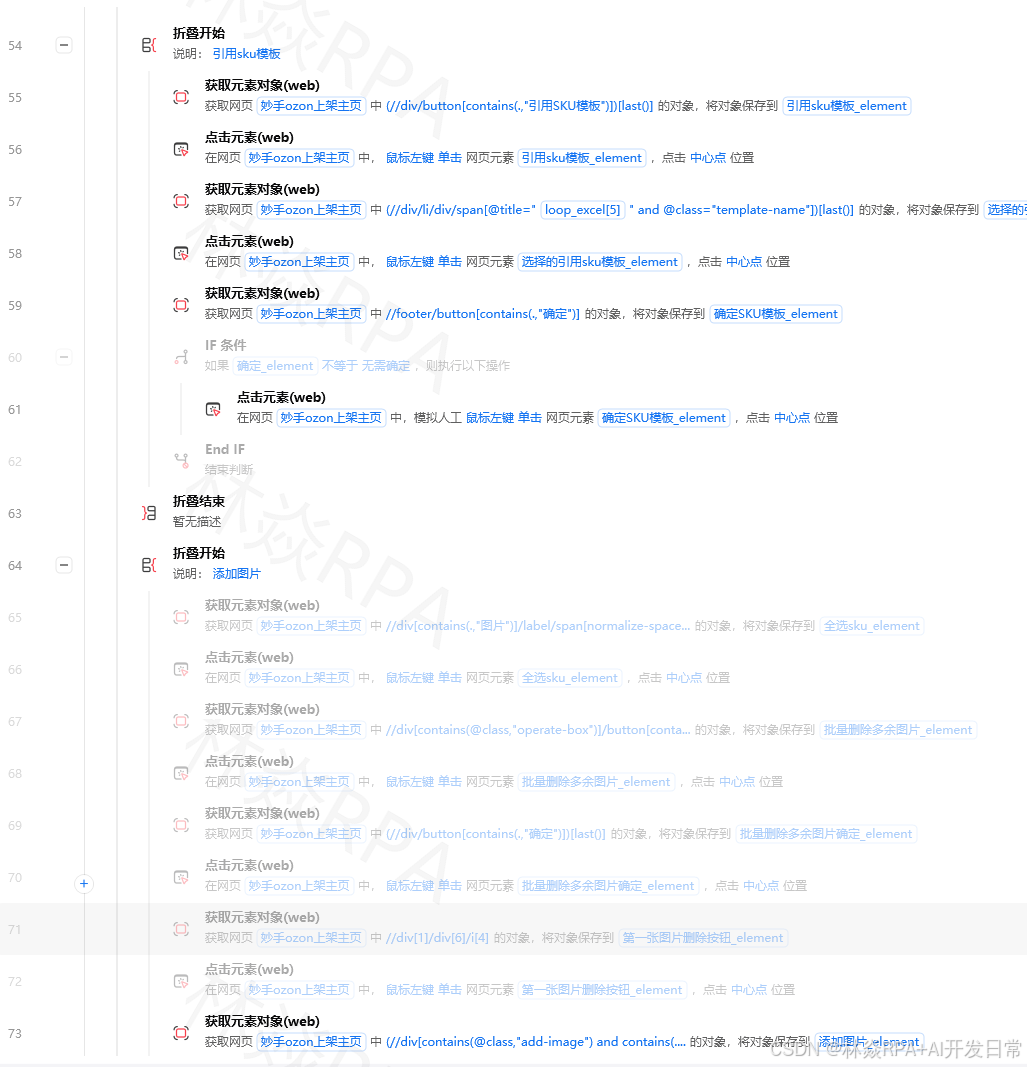
function(element, input) {
let shadowRoot = element.shadowRoot;
return shadowRoot.querySelector('.price-text').textContent;
}
三、变量与数据类型
选品数据采集的变量设计,核心是支持后续的数据分析。
单个商品数据结构:
product = {
"product_id": "1005005567890123",
"title": "Wireless Earbuds Bluetooth 5.3",
"price": 12.99,
"original_price": 25.99,
"currency": "USD",
"orders": 2345,
"rating": 4.7,
"review_count": 1834,
"seller": "Shop123456",
"seller_followers": 12340,
"shipping": "Free shipping",
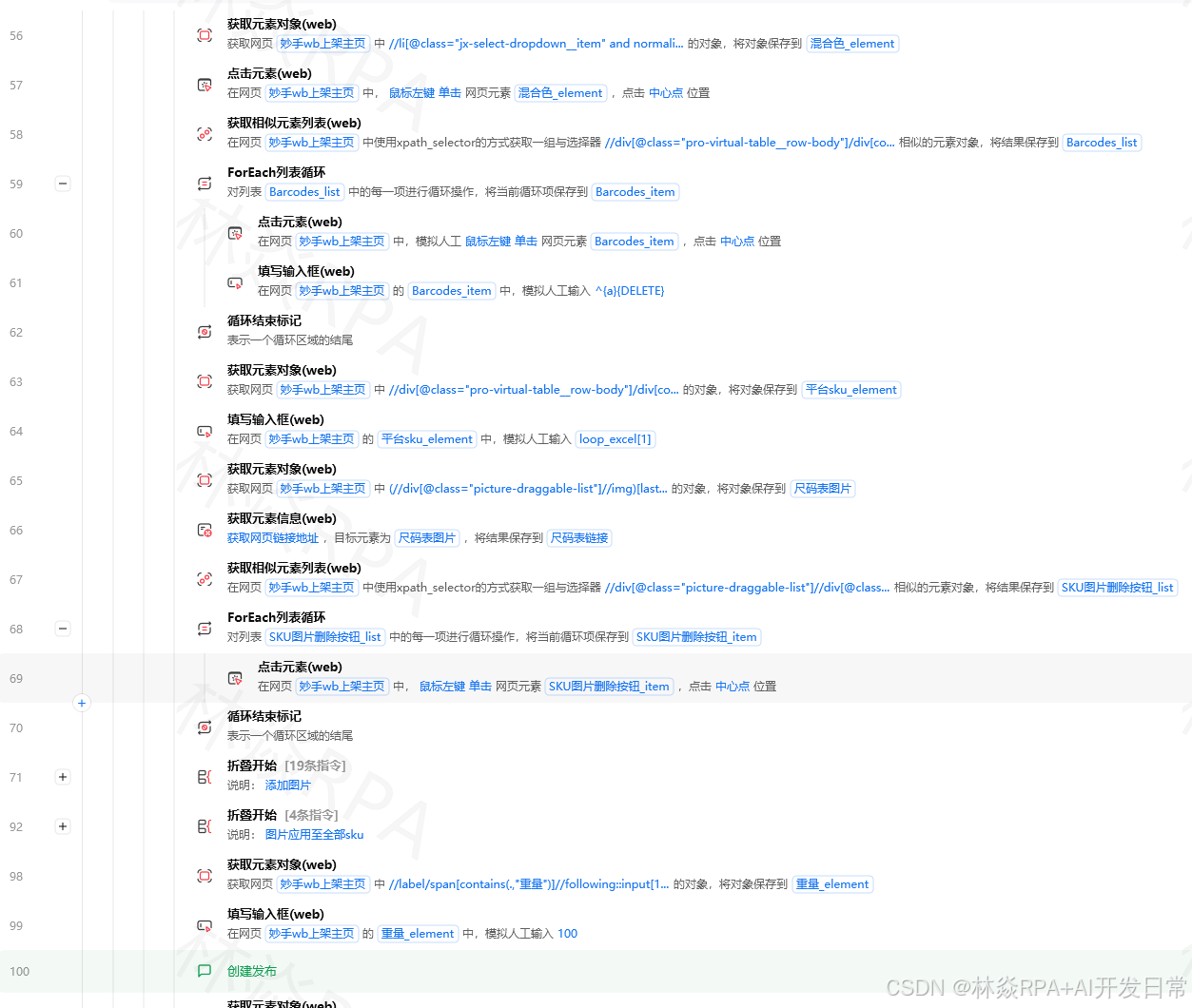
"category": "Consumer Electronics",
"collect_time": "2024-11-01 10:30:00"
}
品类数据采集列表:
category_products = []
# 采集完一个商品就append
category_products.append(product)
竞品对比数据:
选品需要对比竞品,用字典存储对比结果。
competitor_analysis = {
"my_product_price": 12.99,
"avg_competitor_price": 15.50,
"min_competitor_price": 9.99,
"price_rank": 3, # 在竞品中价格排第3低
[video(video-nOcS1kBR-1783008316114)(type-csdn)(url-https://live.csdn.net/v/embed/525010)(image-https://i-blog.csdnimg.cn/img_convert/66b1f116a1b0abf9e5b0dab07e07c311.jpeg)(title-店群矩阵自动化突破运营极限!)]
"review_rank": 2, # 评论数排第2多
}
四、流程控制
选品数据采集是一个"列表页→详情页→返回→下一个"的循环结构。
主流程:
开始
↓
配置采集参数(品类关键词、采集数量)
↓
打开AliExpress搜索页
↓
循环:翻页采集商品列表
↓
获取当前页所有商品卡片元素
↓
循环:逐个点击商品进入详情页
↓
采集商品详情数据
写入内存列表
↓
判断:已采集数量是否达到目标?
↓是→退出循环
↓否→返回列表页,继续下一个
↓
判断:是否有下一页?
↓是→点击下一页,继续
↓否→退出翻页循环
↓
数据清洗与去重
↓
写入Excel,生成分析报告
↓
结束
翻页处理:
AliExpress的翻页按钮有时候是"下一页"箭头,有时候是数字页码。用"获取相似元素列表"获取所有页码按钮,找到当前页的下一个页码点击。
//a[contains(@class,'pagination') and not(contains(@class,'active'))]
异常处理:
详情页可能加载失败,或者商品已下架。用"尝试捕获"指令包住详情页采集逻辑,失败就跳过,记录日志,继续下一个。
五、网页自动化实战
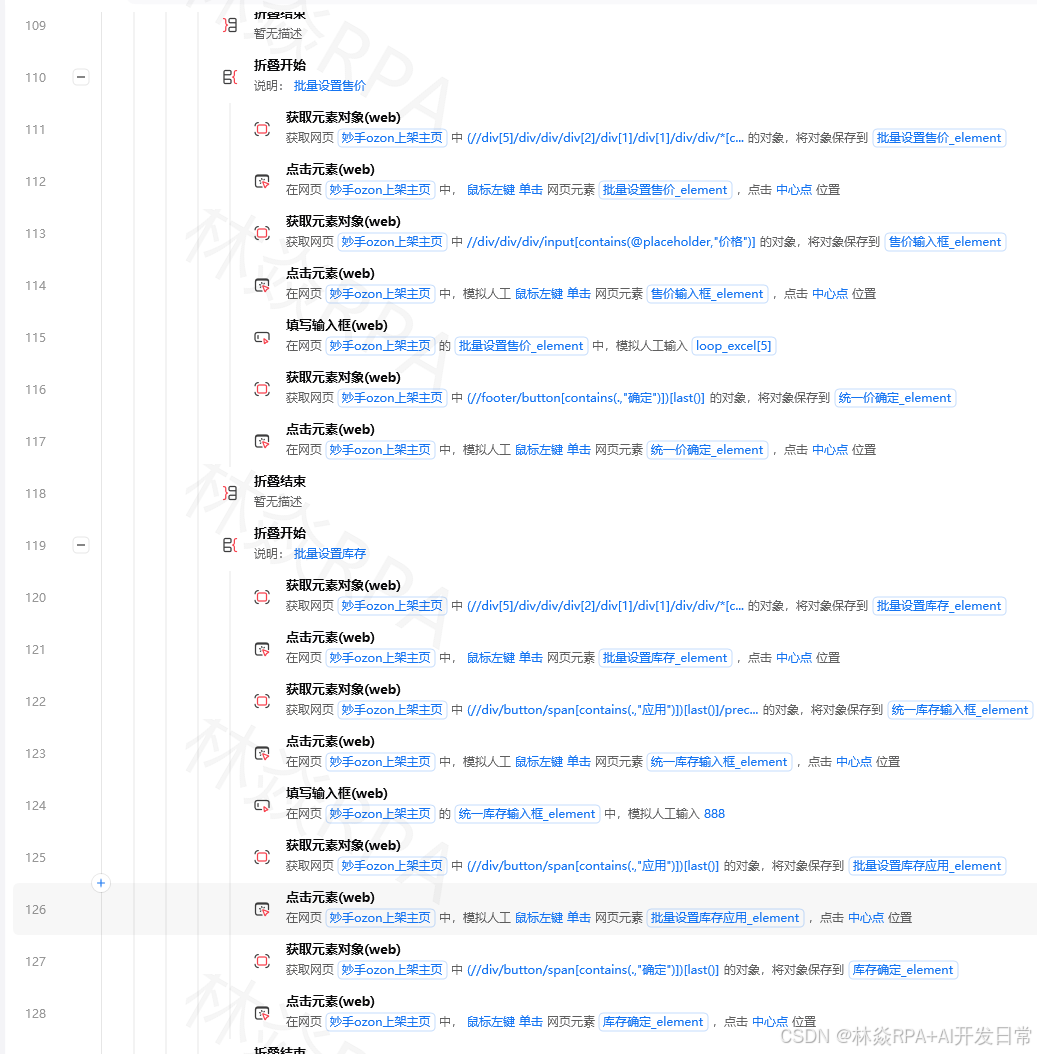
搜索目标品类:
用"在输入框中输入"指令,在AliExpress搜索框输入品类关键词,点搜索。
搜索框XPath:
//input[@id='search-key']
设置筛选条件:
AliExpress的筛选条件(价格区间、评分、订单量)在左侧边栏。用"点击元素"指令展开筛选条件,再设置。
按订单量排序:
//a[contains(@href,'SortType=totalOrderedQty')]
按评分排序:
//a[contains(@href,'SortType=rating')]
采集商品列表基础信息:
不需要每个商品都点进去,列表页已经有价格、订单量、评分等基础信息,先批量获取。
用"获取相似元素列表"指令,获取所有商品卡片,再循环提取每个卡片的信息。
# 批量获取商品价格
price_list = get_similar_elements_attribute("//span[contains(@class,'price')]", "textContent")
# 批量获取商品订单量
orders_list = get_similar_elements_attribute("//span[contains(@class,'orders')]", "textContent")
进入详情页采集深度数据:
列表页没有的数据(商品描述、详细参数、评论内容),需要进入详情页采集。
详情页数据采集要点:
- 商品图片URL:用"获取元素属性"获取img标签的src属性
- 商品描述:有些在iframe里,需要先切换iframe
- 评论内容:AliExpress的评论是动态加载的,需要模拟滚动触发加载
六、数据处理
采集到的原始数据需要做大量清洗工作。
价格处理:

AliExpress的价格文本格式是"US $12.99",需要提取数字部分。
import re
def extract_price(price_text):
# 匹配数字(支持小数点)
match = re.search(r'(\d+\.?\d*)', price_text)
if match:
return float(match.group(1))
return 0.0
# 示例
price = extract_price("US $12.99") # 返回 12.99
订单量处理:
AliExpress的订单量显示有"sold"、"orders"等后缀,还有"K"表示千。
def extract_orders(orders_text):
orders_text = orders_text.lower().replace("sold", "").replace("orders", "").strip()
if 'k' in orders_text:
return int(float(orders_text.replace('k', '')) * 1000)
if 'm' in orders_text:
return int(float(orders_text.replace('m', '')) * 1000000)
return int(orders_text)
去重处理:
同一个商品可能有多个SKU链接,用product_id去重。
seen_ids = set()
unique_products = []
for p in all_products:
if p["product_id"] not in seen_ids:
seen_ids.add(p["product_id"])
unique_products.append(p)
七、鼠标键盘与图像
滚动加载更多:
AliExpress有些页面需要滚动才能加载更多内容,用"模拟滚动"指令。
指令:模拟滚动
目标:当前页面
方向:向下
滚动次数:3
每次滚动后等待:2秒(等待内容加载)
截图保存商品图片:
选品需要看商品图片,判断产品质量和卖点。用"下载文件"指令,根据图片URL批量下载商品主图。
import requests
def download_image(img_url, save_path):
headers = {"User-Agent": "Mozilla/5.0 ..."}
resp = requests.get(img_url, headers=headers, timeout=10)
with open(save_path, "wb") as f:
f.write(resp.content)
处理Cookie弹窗:
AliExpress会根据地区显示不同的Cookie同意弹窗,用"尝试点击元素"指令,检测到弹窗就关闭。
八、竞品调研进阶
选品不只是采集数据,还要做竞品分析。
自动打开竞品链接:
把采集到的竞品商品ID整理成链接列表,用影刀批量打开,采集竞品的详细数据做对比。
竞品链接格式:https://www.aliexpress.com/item/{product_id}.html
评论内容分析:
评论里有很多有价值的信息:客户喜欢什么、抱怨什么、希望有什么功能。用影刀采集评论内容,再做关键词分析。
评论内容的XPath(详情页):
//div[contains(@class,'feedback')]//div[@class='feedback-content']

店铺数据分析:
不只看单个商品,还要看店铺整体数据。用影刀进入店铺首页,采集店铺的粉丝数、好评率、加入年限等数据,判断店铺实力。
九、平台实战整合
把选品数据采集做成一个可配置的应用。
配置化运行:
把以下参数放在Excel配置表里,每次运行前修改配置表,不用改流程。
| 参数 | 示例值 |
|---|---|
| 搜索关键词 | Wireless Earbuds |
| 目标采集数量 | 200 |
| 排序方式 | 按订单量 |
| 最低评分 | 4.5 |
| 最低订单量 | 500 |
| 价格上限 | 50 USD |
定时自动采集:
用影刀的"定时任务"功能,每天凌晨2点自动运行采集流程(此时AliExpress访问量最低,不容易被封)。
生成选品报告:
采集完数据后,自动生成选品报告,包括:
- 品类平均价格
- 价格分布直方图
- TOP20商品列表
- 竞品价格对比表
- 推荐选品清单(综合评分最高的前10个商品)
十、系统联动
选品数据不应该只存在本地,还需要和其他系统联动。
推送到飞书多维表格:
把选品数据推送到飞书多维表格,团队多人可以同时查看和标注。
用影刀的"HTTP请求"指令调用飞书OpenAPI的"写入记录"接口。
与ERP系统联动:
选品确定之后,自动在ERP系统里创建新品档案,包括商品名称、采购价、建议售价等字段。
价格监控联动:
选品入库之后,用另一个影刀流程定期监控竞品价格变化,发现竞品降价就发送提醒。
十一、工程化规范
选品数据采集是长期运行的流程,规范非常重要。
IP轮换策略:
AliExpress对单一IP的访问频率有限制。如果公司有代理池,在流程里配置IP轮换。
用"设置代理"指令,每次翻页之前切换一次代理IP。
代理格式:http://用户名:密码@代理IP:端口
切换频率:每10个商品切换一次
断点续采:
选品采集可能需要采集几百个商品,中间中断了要从头开始很浪费时间。实现断点续采。
每次采集完一个商品,把product_id追加写入进度文件。重新启动时,先读取进度文件,跳过已采集的商品。
# 保存进度
with open("C:\\aliexpress_progress.txt", "a") as f:
f.write(product_id + "\n")
# 读取进度
with open("C:\\aliexpress_progress.txt", "r") as f:
collected_ids = set(line.strip() for line in f.readlines())
十二、速查表与反爬应对
AliExpress有成熟的反爬体系,以下是我踩坑之后的应对方法。
常见反爬措施一:访问频率过高被封IP。
应对:每个操作之间加随机等待2-5秒,使用住宅代理IP,不要用数据中心IP。
常见反爬措施二:出现验证码。
应对:AliExpress的验证码主要是滑块验证。用影刀的"图像识别"指令,检测到验证码弹窗就报警,转人工处理。完全自动化的验证码破解不推荐,容易违反平台规则。
常见反爬措施三:页面结构变化导致元素定位失效。
应对:准备至少两套定位方案(XPath + CSS),都失败时用图像识别作为第三套方案。
速查表:
| 数据项 | 所在位置 | 采集方式 | 注意事项 |
|---|---|---|---|
| 价格 | 列表页+详情页 | 获取元素文本 | 注意折扣价和原价 |
| 订单量 | 列表页 | 获取元素文本 | 注意"K"单位 |
| 评分 | 列表页 | 获取元素属性 | 可能是图片,需OCR |
| 评论内容 | 详情页 | 循环相似元素 | 需滚动加载 |
| 商品图片 | 详情页 | 获取img的src | 注意主图和细节图 |
总结
AliExpress选品数据采集的核心价值在于规模化。人工一天最多能看50个商品,用影刀RPA可以采集500个商品,而且数据准确率更高。
我帮一个跨境卖家搭了这套方案之后,他们的选品周期从原来的一周缩短到一天,选品成功率(上架后30天内出单)从大概40%提升到了65%。数据化选品和拍脑袋选品,差距就在这里。
最后提醒一点:AliExpress的平台规则经常变化,采集频率一定要控制好,不要贪多求快,账号被封得不偿失。
更多跨境电商自动化实战内容,欢迎交流。我的个人网站 home.linyan.cloud 也会持续更新相关教程。
#影刀RPA #RPA教程 #跨境电商 #AliExpress #选品自动化
作者:林焱

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐



 7
7 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)