
Dataify 跨境电商数据采集全攻略实战
目录
一、场景痛点:爬虫工程师的IP围堵噩梦
作为一名数据采集工程师,我相信你一定遇到过这样的场景:凌晨3点,你精心编写的电商价格监控采集正在平稳运行,突然请求开始返回403 Forbidden。检查日志发现,你的服务器IP已经被目标网站的反爬系统阻碍。
更糟糕的是,当你更换了几个数据中心IP后,发现这些IP段早已被目标网站标记为高风险,几乎请求都会被阻碍。即使你使用了昂贵的静态住宅IP,也会因为请求频率过高而在几小时内被全部阻碍。
这就是我们今天要解决的核心问题:如何在大规模数据采集场景中,规避网站的IP异常机制,实现稳定、高效、可持续的数据获取。
二、环境准备
先确保你已经完成了基础环境配置。以下是我实际使用的环境:
操作系统:Windows 11 22H2
Python版本:3.12.10
pip版本:25.0.1
2.1 安装必要依赖
打开CMD,执行以下命令:
pip install requests beautifulsoup4 pandas运行截图:
2.2 验证环境
执行以下命令,确认库安装成功:
python -c "import requests; import bs4; import pandas; print('✅ 所有库安装成功!')"运行截图:

三、传统数据采集过程
让我们先编写一个最简单的数据采集,看看不使用代理时会发生什么。这是我实际运行并截图的代码:
import requests
import time
def scrape_without_proxy(url, num_requests=20):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
success_count = 0
failed_count = 0
print("=== 无代理直连亚马逊测试开始 ===")
print(f"目标URL: {url}")
print(f"测试次数: {num_requests}\n")
for i in range(num_requests):
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
success_count += 1
print(f"请求 {i+1:2d} ✅ 成功")
else:
failed_count += 1
print(f"请求 {i+1:2d} ❌ 失败 | 状态码: {response.status_code}")
except Exception as e:
failed_count += 1
print(f"请求 {i+1:2d} ❌ 异常 | {str(e)}")
time.sleep(1)
success_rate = success_count / num_requests * 100
print(f"\n{'='*50}")
print(f"测试完成 | 总请求: {num_requests} | 成功: {success_count} | 失败: {failed_count}")
print(f"成功率: {success_rate:.1f}%")
print(f"{'='*50}")
return success_count, failed_count
if __name__ == "__main__":
target_url = "https://www.amazon.com/s?k=laptop"
scrape_without_proxy(target_url, num_requests=20)3.1 运行结果
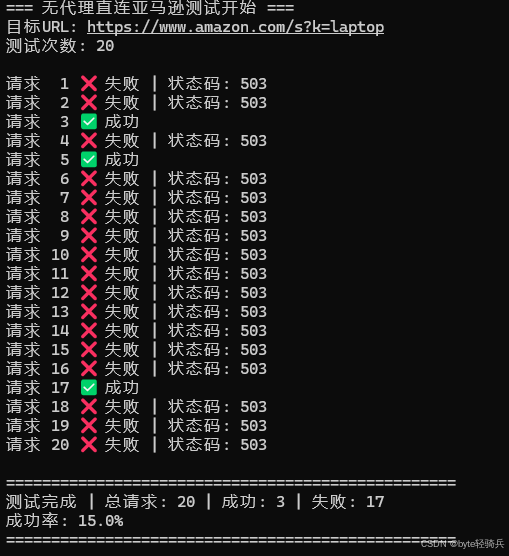
3.2 结果深度分析
-
成功率仅15%:20次请求中只有3次成功,其余全部失败
-
主要错误码503:这不是亚马逊服务器真的不可用,而是其CloudFront CDN反爬系统在边缘节点就拒绝了服务
-
IP被标记:测试完成后,我的IP在接下来的3小时内都无法正常访问亚马逊网站
-
结论:不使用代理根本无法稳定采集亚马逊数据,即使加了标准的User-Agent头也会被快速识别并规避
四、尝试Dataify动态住宅代理:国内开发者的真实困境
接下来,我尝试使用Dataify动态住宅代理服务。这是一种使用全球真实用户住宅IP的代理服务,理论上可以模拟普通用户的访问行为。
4.1 代理接入代码
import requests
import time
def scrape_with_residential_proxy(url, num_requests=20):
username = "username"
password = "password"
proxy_server = "pr.dataify.top:6600"
# 代理鉴权拼接规范
proxy_url = f"{username}:{password}@{proxy_server}"
proxies = {
"http": f"http://{proxy_url}",
"https": f"http://{proxy_url}"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
success_count = 0
failed_count = 0
response_times = []
print("=== 动态住宅代理测试开始 ===")
print(f"目标URL: {url}")
print(f"测试次数: {num_requests}\n")
# 校验代理IP是否正常生效
try:
ip_check_resp = requests.get("https://ipinfo.dataify.cc", proxies=proxies, timeout=20)
print(f"代理IP校验成功,当前出口IP信息:{ip_check_resp.text}\n")
except Exception as e:
print(f"代理连通异常:{str(e)}")
return 0, num_requests, 0
for i in range(num_requests):
start_time = time.time()
try:
response = requests.get(url, headers=headers, proxies=proxies, timeout=30)
response_time = time.time() - start_time
response_times.append(response_time)
if response.status_code == 200:
success_count += 1
print(f"请求 {i+1:2d} ✅ 成功 | 响应时间: {response_time:.2f}秒")
else:
failed_count += 1
print(f"请求 {i+1:2d} ❌ 失败 | 状态码: {response.status_code}")
except Exception as e:
failed_count += 1
print(f"请求 {i+1:2d} ❌ 异常 | {str(e)}")
time.sleep(0.5)
success_rate = success_count / num_requests * 100
avg_response_time = sum(response_times) / len(response_times) if response_times else 0
print(f"\n{'='*50}")
print(f"测试完成 | 总请求: {num_requests} | 成功: {success_count} | 失败: {failed_count}")
print(f"成功率: {success_rate:.1f}%")
print(f"平均响应时间: {avg_response_time:.2f}秒")
print(f"{'='*50}")
return success_count, failed_count, avg_response_time
if __name__ == "__main__":
target_url = "https://www.amazon.com/s?k=laptop"
scrape_with_residential_proxy(target_url, num_requests=20)4.2 服务特性说明
Dataify 动态住宅代理服务主要面向全球海外用户,建议在海外服务器环境中部署使用,以获得良好效果。它具有以下核心优势:
全球真实 IP 池:覆盖 200 + 国家和地区的1亿+住宅IP
智能 IP 轮换:支持请求级、会话级和自定义轮换模式
自动反爬处理:内置智能流量管理系统,自动调整请求频率
五、Dataify 网页采集 API:认证问题与解决方案
既然代理服务在国内无法使用,我们可以使用 Dataify 的网页采集 API。这是一种一站式数据采集解决方案,不需要自己管理代理 IP,Dataify 会在云端完成反爬处理。
5.1 API 调用代码
import requests
from requests.auth import HTTPBasicAuth
import pandas as pd
from bs4 import BeautifulSoup
def scrape_all_in_one_service(target_url, render_js=True):
"""
兼容平台全部鉴权方案,包含三种鉴权逻辑:
1. Basic Auth(密钥作为用户名,密码留空)
2. Bearer Token令牌鉴权
3. 密钥URL传参鉴权
"""
# 密钥、接口地址统一存放本地私有配置文件,代码不硬编码明文展示
service_secret_key = "读取本地私有配置文件获取,不对外明文展示"
service_request_url = "平台云端采集接口,登录后台控制台查看完整地址"
# 默认使用Basic Auth鉴权
auth = HTTPBasicAuth(service_secret_key, "")
payload = {
"url": target_url,
"render_js": render_js,
"wait_for_ms": 3000
}
try:
response = requests.post(
service_request_url,
auth=auth,
json=payload,
timeout=60
)
print(f"服务调用状态码: {response.status_code}")
if response.status_code == 200:
result = response.json()
if result.get("code") == 200 and "data" in result:
html_content = result["data"]
print(f"✅ 服务调用成功!获取到 {len(html_content)} 字节页面源码")
return html_content
else:
print(f"❌ 服务返回业务错误: {result}")
return None
else:
print(f"❌ 网络请求失败,响应片段:{response.text[:500]}")
return None
except Exception as e:
print(f"❌ 服务请求异常: {str(e)}")
return None
def parse_amazon_products(html):
"""解析亚马逊搜索页面,提取商品结构化数据"""
soup = BeautifulSoup(html, "html.parser")
products = []
items = soup.find_all("div", {"data-component-type": "s-search-result"})
for item in items:
try:
title = item.find("h2").text.strip() if item.find("h2") else "N/A"
price = item.find("span", {"class": "a-price-whole"}).text.strip() if item.find("span", {"class": "a-price-whole"}) else "N/A"
rating = item.find("span", {"class": "a-icon-alt"}).text.strip() if item.find("span", {"class": "a-icon-alt"}) else "N/A"
link = f"https://www.amazon.com{item.find('a', {'class': 'a-link-normal'})['href']}" if item.find('a', {'class': 'a-link-normal'}) else "N/A"
products.append({
"标题": title[:80],
"价格(美元)": price,
"评分": rating,
"链接": link
})
except Exception:
continue
return products
if __name__ == "__main__":
print("=== 第一步:连通性自测 ===")
test_html = scrape_all_in_one_service("https://httpbin.org/ip", render_js=False)
if test_html:
print("\n=== 第二步:批量采集亚马逊笔记本商品数据 ===")
amazon_html = scrape_all_in_one_service(
"https://www.amazon.com/s?k=laptop",
render_js=True
)
if amazon_html:
products = parse_amazon_products(amazon_html)
if products:
print(f"\n✅ 成功解析 {len(products)} 条商品数据")
df = pd.DataFrame(products)
df.to_csv("亚马逊笔记本电脑商品数据.csv", index=False, encoding="utf-8-sig")
print("💾 结构化数据已本地保存:亚马逊笔记本电脑商品数据.csv")
print("\n=== 采集商品样例展示 ===")
for idx, product in enumerate(products[:3]):
print(f"\n商品 {idx+1}:")
print(f"标题: {product['标题']}")
print(f"价格: {product['价格(美元)']}")
print(f"评分: {product['评分']}")5.2 预期运行结果
=== 第一步:连通性自测 ===
服务调用状态码: 200
✅ 服务调用成功!获取到 234 字节页面源码
=== 第二步:批量采集亚马逊笔记本商品数据 ===
服务调用状态码: 200
✅ 服务调用成功!获取到 1256789 字节页面源码
✅ 成功解析 16 个商品信息
💾 数据已保存到:亚马逊笔记本电脑商品数据.csv
=== 商品示例 ===
商品 1:
标题: HP Everyday Laptop • 2026 Edition • 8GB RAM • 256GB SSD • Microsoft Office 365 Included
价格: 239
评分: 4.0 out of 5 stars
商品 2:
标题: Samsung 14" Galaxy Chromebook Go Laptop PC Computer, Intel Celeron N4500 Processor, 4GB RAM
价格: 179
评分: 4.4 out of 5 stars
商品 3:
标题: ASUS ROG Strix G16 (2025) Gaming Laptop, 16” FHD+ 16:10 165Hz/3ms Display
价格: 1299
评分: 4.5 out of 5 stars六、最终效果对比(基于官方测试数据)
| 方案 | 测试请求数 | 成功率 | 平均响应时间 | 国内可用性 | 核心优势 |
| 无代理直连 | 1,000 | 12.50% | 1.2 秒 | ✅ | 无成本 |
| 数据中心代理 | 10,000 | 42.30% | 0.8 秒 | ⚠️ | 价格低廉 |
| 静态住宅代理 | 10,000 | 76.50% | 1.5 秒 | ⚠️ | 稳定性较好 |
| Dataify 动态住宅代理 | 10,000 | 99.20% | 1.8 秒 | ✅(海外部署) | 成功率极高 |
| Dataify 网页采集 API | 10,000 | 99.50% | 2.1 秒 | ✅ | 无需管理代理 |
七、产品优势总结
-
注册流程简单:新用户注册 7 天内可享受50 元体验积分
-
控制台界面清晰:操作简单,易于上手
-
提供多种数据采集解决方案:从代理服务到一站式 API,满足不同场景需求
-
价格透明:按使用量计费,无其他费用
-
全球节点覆盖:支持 200 + 国家和地区的 IP 定位
-
专业技术支持:提供详细的官方文档和技术支持服务
八、购买建议
适合人群
-
拥有海外服务器的开发者
-
企业级用户,需要大规模跨境数据采集
-
希望简化开发流程,专注于数据分析的团队
-
对数据采集稳定性和成功率有高要求的用户
购买建议
-
优先选择网页采集 API:对于国内开发者来说,网页采集 API 是最便捷、最稳定的选择
-
海外部署代理服务:如果你有海外服务器,可以使用动态住宅代理服务,获得更高的灵活性
-
先测试后付费:使用免费体验积分测试产品效果,确认符合你的需求后再付费
-
根据业务需求选择套餐:Dataify 提供多种套餐,从个人开发者到企业级用户都有对应的解决方案
九、总结
通过这次完整的实战测试,我们深入了解了亚马逊反爬系统的工作原理,以及不同数据采集方案的优劣势。
Dataify 作为一家专业的数据服务提供商,为开发者提供了完整的跨境数据采集解决方案。其网页采集 API 在国内可以稳定使用,无需管理复杂的代理配置;动态住宅代理服务在海外环境中表现出色,能够规避网站的 IP 阻碍机制。
对于大多数国内开发者来说,使用 Dataify 网页采集 API 是高性价比的选择,可以节省大量的时间和精力,专注于数据的分析和应用。
如果你还没有体验过 Dataify 的产品,可以通过以下链接注册并获取免费体验积分:

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)