
【Vid llm】E-VAds: An E-commerce Short Videos Understanding Benchmark
note
- 训练策略:
- SFT 仅完成浅层对齐,高阶推理强依赖 RL
- 多粒度奖励(MG-GRPO)有效克服奖励稀疏
- 增大答案权重的分配,可以防止出现推理正确但答案错误情况
一、E-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs
E-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs
链接:https://arxiv.org/abs/2602.08355
开源:https://github.com/TaobaoTmall-AlgorithmProducts/E-VAds_Benchmark
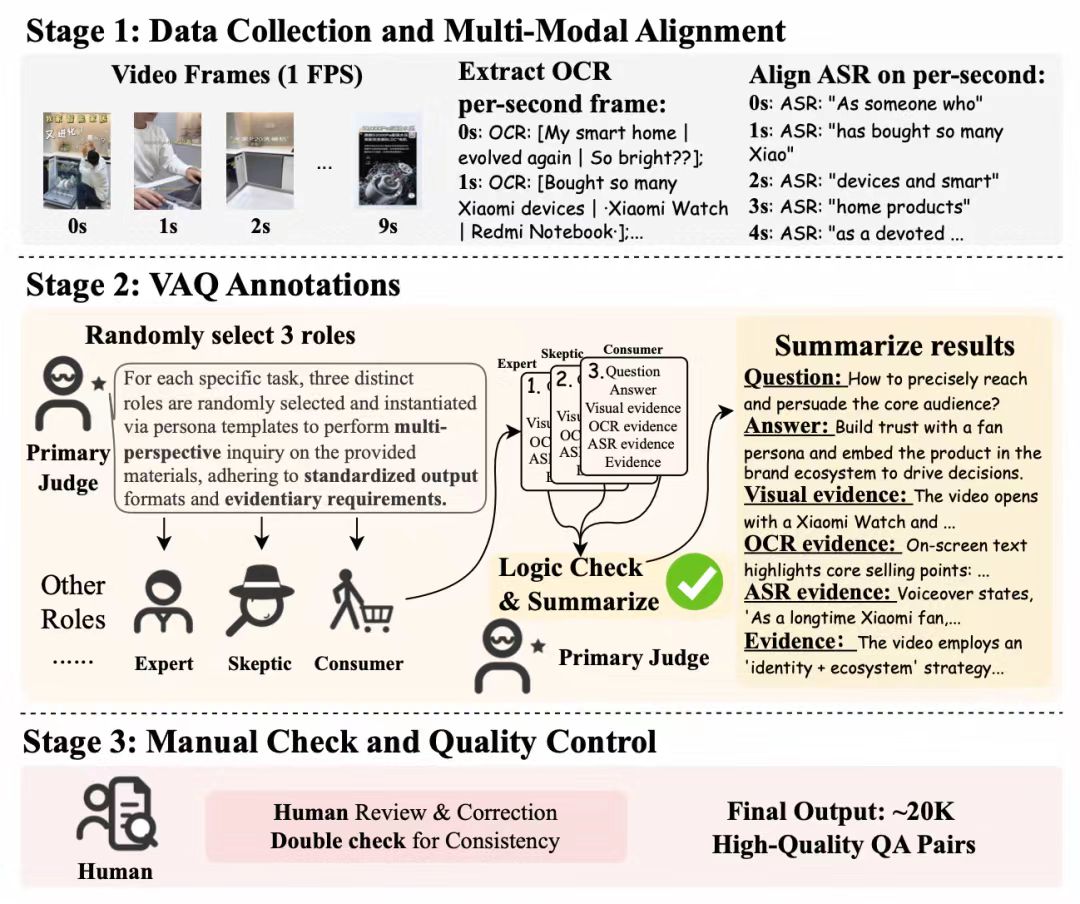
电商视频现有MLLM提出了三大现实挑战:
● 极高的多模态信息密度:模型必须在极短时间内追踪快速的视觉切换,并将密集的语音和字幕与视觉证据进行精准对齐。
● 评估基准的缺失:目前业内尚无专门针对大规模、转化导向型电商短视频的系统性评测标准。
● 开放式的商业推理:营销说服逻辑、消费者心理洞察等问题本质上是开放式且高度意图导向的。这种主观性使得监督信号难以定义,导致模型在学习时的奖励信号极其稀疏。
提出了业内首个电商短视频理解基准 E-VAds Benchmark,并同步开源了多模态信息密度评估框架、数据构建Pipeline以及 E-VAds-R1 推理模型
训练策略的消融实验,表明:
● SFT 仅完成浅层对齐,高阶推理强依赖 RL:对比不同的 SFT 策略(直接输出答案 vs 思维链后输出),表现差异微乎其微。这表明 SFT 阶段主要的作用是“格式对齐”和“基础领域知识注入”,而解决复杂电商逻辑推理的核心能力绝大部分是在 RL 阶段建立的。
● 多粒度奖励(MG-GRPO)有效克服奖励稀疏:单一的严格奖励(Strict)有严重稀疏的监督信号,阻碍模型探索;而单一的宽松奖励(Relaxed)虽能平滑引导,但无法让模型变得更精进。实验证明,MG-GRPO 将多粒度融合(G)后,能实现最佳的性能突破
● 答案权重的分配:在综合计算奖励时,赋予“最终答案(Answer)”更大的权重,能有效防止大模型产生“推理过程看似华丽,但核心结论站不住脚”的幻觉现象。
Reference
[1] E-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs
[2] ICML’26|淘天集团开源首个电商短视频理解基准E-VAds与RL增强推理模型

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)