
AI 图片翻译是怎么实现的?从 OCR、背景修复到译文重排的完整链路
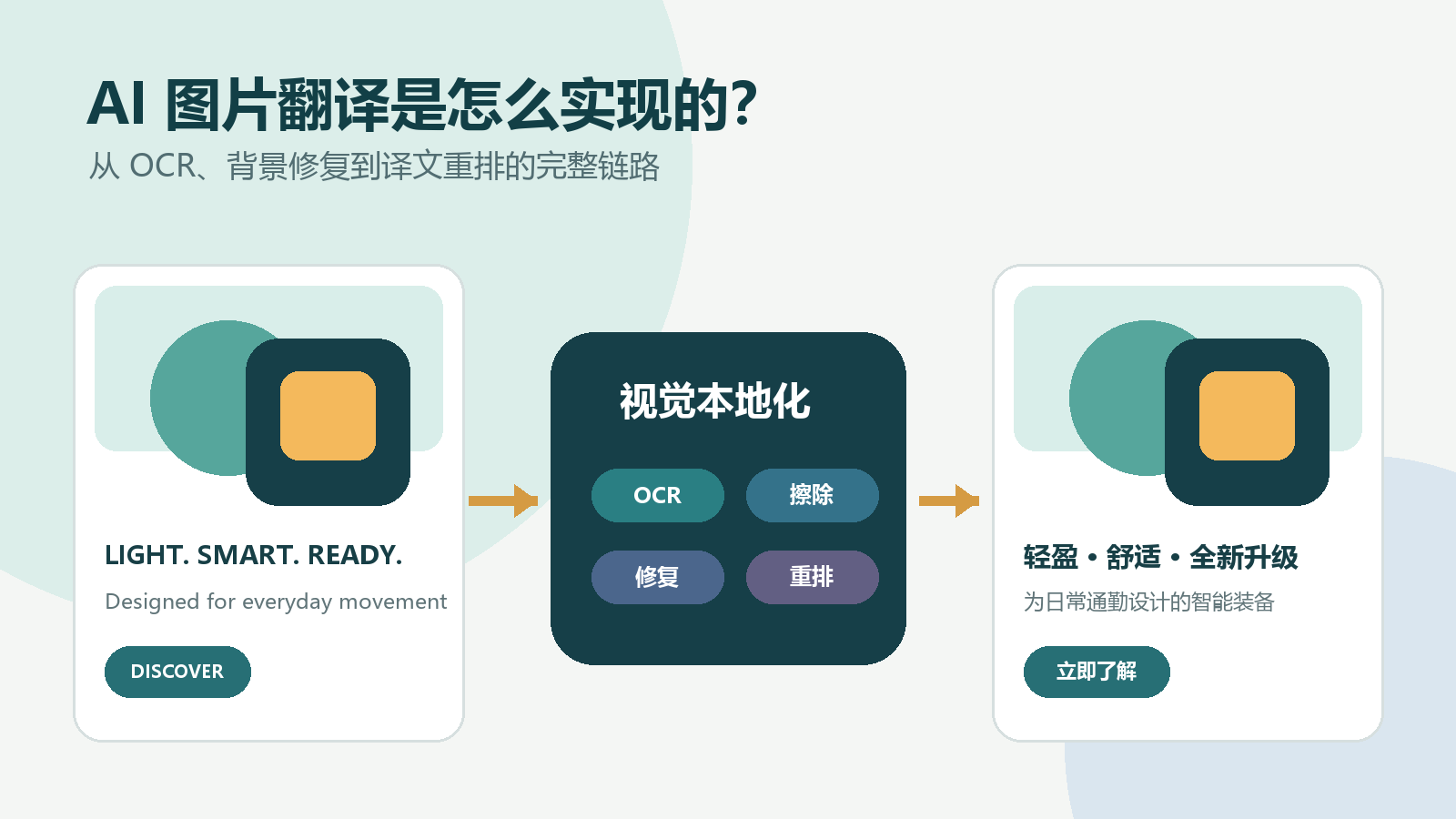
把一段英文翻译成中文,只需要将文字发送给翻译模型。但如果文字出现在商品主图、宣传海报、信息图或漫画中,事情就不再是调用一次翻译接口那么简单。
图片里的文字并不是独立存在的。它有位置、字体、颜色、描边和阴影,也可能压在渐变、纹理或商品照片之上。系统不仅要知道原文写了什么,还要在删除原文之后补回背景,再将译文按照原来的视觉层级重新排版。
如果其中任何一步处理得不够好,结果都会非常明显:文字识别错误、背景留下残影、中文挤出按钮、英文被擦掉后出现一块突兀的色斑,或者译文虽然准确,却完全破坏了原图的设计感。
因此,图片翻译本质上不是单一的自然语言处理任务,而是一条由计算机视觉、机器翻译和图形排版共同组成的视觉本地化流水线。
本文从工程实现的角度拆解一套 AI 图片翻译系统,看看一张图片如何依次经过文字检测、OCR、语义翻译、原文擦除、背景修复和译文重排,最终成为可以直接发布的多语言素材。
普通 OCR 为什么还不够
OCR,也就是光学字符识别,解决的主要问题是“图片中写了什么”。
对于扫描文件或快递单,只要把文字正确提取出来,任务可能已经完成大半。但在图片翻译中,提取文字只是起点。系统还必须保留每段文字在原图中的位置和形状。
例如,一张商品海报可能包含主标题、折扣数字、产品卖点、价格和按钮文案。把它们全部识别成一段纯文本之后,虽然能够翻译,却已经失去了页面结构:
SUMMER SALE
50% OFF
Lightweight Running Shoes
Shop Now
一套可用于图片翻译的识别结果,需要更接近下面的数据结构:
{
"text": "SUMMER SALE",
"language": "en",
"polygon": [[86, 52], [412, 52], [412, 128], [86, 128]],
"rotation": 0,
"fontColor": "#FFFFFF",
"strokeColor": "#203040",
"alignment": "center"
}
这里的 polygon 记录文字区域的四边形坐标,rotation 表示文字方向,颜色和对齐信息则为后面的视觉重建提供参考。
换句话说,图片翻译需要的不是“识别结果”,而是“可还原的视觉文本对象”。
第一阶段:找到真正需要翻译的文字
一张图片中并不是所有类似字符的形状都应该被翻译。
商品包装上可能有品牌标志,背景中可能出现路牌,衣服上可能有装饰性字母,图表中还可能包含数字、单位和代码。文字检测模型首先需要判断哪些区域属于有效文本,再输出对应的位置。
常见的检测结果是矩形框或多边形。矩形框实现简单,但面对倾斜文字、弧形文字和透视变形时容易包含过多背景;多边形能够更紧密地贴合文字轮廓,更适合后续生成擦除区域。
检测阶段还需要处理文字大小差异。海报标题可能占据半张图片,免责声明却只有十几个像素高。如果模型只针对大字优化,小字就会被漏掉;如果过度追求小字召回率,又可能把纹理和装饰误判成字符。
工程上通常会设置多个缩放尺度,并结合置信度、面积和长宽比过滤结果。对于批量任务,还应保留低置信度区域,交给后续 OCR 或人工编辑确认,而不是直接删除。
第二阶段:OCR 不只是认字,还要理解方向
文字区域确定之后,OCR 模型开始恢复字符内容。
标准印刷体通常不难识别,真正麻烦的是艺术字体、低对比度文字、弯曲排版、描边阴影以及与背景颜色接近的文案。跨境素材中还经常混合英文、数字、货币符号和产品型号。
系统需要先判断语言和文字方向,再选择合适的识别策略。拉丁文字通常横向排列,日文可能同时出现横排和竖排,阿拉伯文则从右向左书写。方向判断一旦错误,识别和后续重排都会受到影响。
OCR 输出还应该进行规范化。例如统一全角与半角字符、修复断开的单词、保留价格中的小数点,并避免把型号中的字母 O 误识别为数字 0。
对于商品图片,数字和单位往往比普通描述更加敏感。容量 500 ml、折扣 20% 和价格 $19.99 一旦识别错误,即使整段译文读起来很流畅,素材也不能直接使用。
因此,成熟系统通常会将普通文本、数字、货币、URL 和型号分别标记。翻译阶段只修改应该翻译的部分,其余内容通过占位符保护。
第三阶段:从逐句翻译转向视觉语境翻译
同一个单词出现在不同图片中,含义可能完全不同。
例如,light 在灯具广告里可能是“灯光”,在食品包装上可能是“低脂”,在运动鞋海报中则更可能表达“轻盈”。如果系统只把每个文本框独立送入翻译模型,就会失去商品类型和周围文案提供的上下文。
更合理的方式是先整理同一图片中的全部文本,再连同内容类型、目标市场和文字层级一起提交。主标题、卖点和按钮文案的语气也应有所区别:标题需要简洁有力,产品描述强调准确,按钮则要符合目标语言的常用交互表达。
可以将请求组织成类似下面的结构:
{
"contentType": "ecommerce_banner",
"targetLanguage": "zh-CN",
"blocks": [
{"id": 1, "role": "headline", "text": "LIGHT. SMART. READY."},
{"id": 2, "role": "description", "text": "Designed for everyday movement"},
{"id": 3, "role": "cta", "text": "DISCOVER"}
]
}
模型返回译文时保留原始 id,系统就能将每一段内容与对应的视觉区域重新关联。
这一步体现了大语言模型在图片翻译中的价值:它不仅完成字面转换,还能结合标题层级、商品语境和目标语言习惯,生成更适合页面的表达。
第四阶段:删除原文之前,先生成准确的 Mask
译文已经准备好,但原图中的文字仍然存在。系统必须先把原文清理掉。
最直接的方法是根据文字检测框生成一张黑白 Mask:白色区域表示需要删除,黑色区域表示保留。随后,图像修复算法只处理 Mask 覆盖的位置。
但直接使用检测框通常不够。文字可能带有描边、阴影或发光效果,如果 Mask 只覆盖字形主体,处理完成后会留下模糊的轮廓。
因此,实际生成 Mask 时通常需要进行适度膨胀:
kernel = np.ones((5, 5), np.uint8)
expanded_mask = cv2.dilate(text_mask, kernel, iterations=1)
膨胀范围不能无限增大。范围太小会留下残影,范围太大则会误删按钮边框、装饰图案甚至商品本身。
对于多个相邻文本框,还需要判断它们是否属于同一个视觉区域。分别擦除可能产生接缝,合并成一个 Mask 往往能获得更连续的修复结果。
第五阶段:背景修复决定图片是否“像原图”
删除文字后,原来的位置会留下空洞。背景修复的任务,是根据周围像素推测这块区域原本应该是什么样子。
纯色背景最容易处理,只需要采样附近颜色进行填充。线性渐变可以根据区域两侧的颜色变化进行插值。重复纹理则可以从周围寻找相似图案进行复制。
真正困难的是文字压在商品、人物、复杂纹理或光影边缘上的情况。传统的 OpenCV Inpainting 可以利用邻近像素扩散填补小区域,但面对大面积文字和结构复杂的背景时,容易出现模糊和重复纹理。
生成式 Inpainting 会结合更大范围的图像语义推断缺失内容。例如文字覆盖在木纹桌面上,模型不仅复制颜色,还需要延续木纹方向;文字覆盖在衣服褶皱上,则需要保持布料纹理和明暗关系。
一套实际系统往往不会对所有图片使用同一种算法。简单背景使用快速的传统修复,复杂区域再交给生成模型,可以在处理速度和视觉质量之间取得平衡。
背景修复是否自然,往往是用户判断图片翻译质量的第一印象。译文稍有措辞差异可能需要仔细阅读才能发现,而背景上的色块和文字残影几乎一眼就能看出来。
第六阶段:译文重排不是把文字画回去
背景处理完成后,系统需要把译文绘制到原来的区域。
这一步看似简单,实际涉及字体匹配、字号计算、自动换行、对齐方式和文字方向。原文长度与译文长度几乎不可能完全一致,同一个文本框需要根据目标语言重新适配。
一个常见策略是从原字号开始测量译文尺寸,如果超出文本框,就逐步缩小字号:
font_size = original_font_size
while font_size > min_font_size:
width, height = measure_text(translated_text, font_size)
if width <= box_width and height <= box_height:
break
font_size -= 1
但字号并不是唯一变量。系统还可以调整字间距、行距和换行位置。标题通常应优先保持大字号,可以适当扩大文本框;说明文字则可以通过多行排版容纳更多内容。
字体匹配也不只是寻找相同字体名称。原图使用的英文字体可能根本不包含中文字形,系统需要根据粗细、圆角、衬线和视觉重心寻找相近的中文字体。
阿拉伯文、希伯来文等从右向左书写的语言,还需要改变对齐方式和文本方向。如果仍按从左向右排版,文字即使翻译正确,也会显得非常不自然。

为什么图片翻译需要在线编辑器
自动化可以覆盖大量标准场景,但营销素材对文字的要求往往非常主观。
一句广告语可能存在多个正确译法,品牌团队关心的不只是语义,还包括语气、用词和视觉节奏。某些标题为了保持冲击力,需要主动缩短;某些按钮则必须采用当地用户熟悉的表达。
因此,完整的图片翻译产品通常会在自动处理之后保留可编辑层。用户可以修改译文、调整字号、改变颜色或移动文字位置,而不必重新打开 Photoshop 从头排版。
这也是图片翻译工具与普通 OCR 翻译之间的重要区别:前者交付的是可继续编辑、可以直接用于业务的视觉素材,而后者通常只返回一段识别文本。
批量图片翻译如何设计
一张图片可以同步等待,几十张甚至几百张图片则更适合使用异步任务。
上传完成后,系统可以按照“项目—文件—目标语言—处理任务”拆分数据。一张源图需要生成中文、日文和西班牙文版本时,实际上对应三个独立任务,但它们可以复用第一次文字检测和 OCR 的结果。
源图片
├── 通用检测与 OCR
├── 中文:翻译 → 修复 → 重排
├── 日文:翻译 → 修复 → 重排
└── 西班牙文:翻译 → 修复 → 重排
任务队列负责控制并发,避免大量图像修复请求同时耗尽 GPU 资源。每个阶段都应记录状态,使失败任务可以从当前节点重试,而不是重新完成整条链路。
项目化管理同样重要。跨境电商团队往往需要同时管理不同 SKU、国家和活动批次。如果多语言素材只是散落在本地文件夹里,后续很难判断哪一张是最新版本。
将源图、语言版本、编辑记录和导出文件关联起来,图片翻译才真正从一个单次工具升级为可持续的内容本地化工作流。
如何把这套链路变成实际工作流
从产品形态来看,LingFlow 并没有把图片翻译限制在“上传一张图、下载一张图”的单次操作中,而是采用项目化流程组织素材。
用户可以创建项目,批量上传 JPG、JPEG、PNG、BMP 或 WEBP 文件,选择目标语言后启动翻译。自动处理完成后,还可以在编辑器中继续调整译文、字体大小和位置,再导出高分辨率图片。
这种方式比较适合商品主图、Amazon A+ 页面、广告横幅、信息图、菜单和漫画等需要保留视觉结构的内容。对于同一批素材的多语言版本,项目和文件库也比零散下载更容易管理。
平台公开页面还展示了 100 多种语言支持以及批量图片处理能力。对出海团队而言,实际价值并不只是“把英文换成中文”,而是减少设计师反复擦字、修背景和重新排版的重复工作。
更重要的是,自动结果之后仍然保留人工微调入口。AI 负责完成大部分机械工作,运营或本地化人员负责最后的品牌表达,这比完全依赖自动化更符合真实业务流程。
哪些场景最值得使用
图片翻译最典型的应用是跨境电商。产品图、尺寸说明、促销海报和详情页素材数量多、更新频繁,逐张交给设计师替换文字会形成明显瓶颈。
第二类场景是市场营销。相同的活动创意需要投放到不同国家时,视觉设计通常保持一致,只有标题、卖点和按钮需要本地化。保留原图布局可以减少重复设计,也有助于维持品牌统一。
信息图、报告截图和演示材料同样适用。这些内容中的文字与图形关系紧密,单独提取文本会失去阅读结构,而图片翻译可以让译文继续停留在相应的数据和图示附近。
漫画和表情包则是更特殊的场景。系统需要识别气泡区域、擦除原文并让译文重新适配气泡大小。它对文字检测和排版提出了更高要求,也很好地体现了视觉本地化与普通文本翻译的差异。
总结
AI 图片翻译并不是“OCR 加一个翻译接口”。
它需要先找到文字并恢复内容,再结合图片语境完成翻译;随后生成精确的文字 Mask,清除原文和视觉效果,通过图像修复补全背景,最后根据目标语言重新选择字体、字号、换行与对齐方式。
这条链路横跨计算机视觉、自然语言处理和图形排版。最终质量不只取决于译文是否准确,还取决于背景是否自然、文字是否适配,以及整张图片能否继续保持原来的视觉层级。
LingFlow 将这套复杂链路封装成了项目化的在线操作,并加入批量处理、文件管理和后期编辑。对于需要持续生产多语言图片的团队,这种“AI 自动处理 + 人工快速校正”的方式,比单纯输出 OCR 文本更接近真正可落地的本地化工作流。
从开发者角度看,图片翻译也是一个很典型的多模态 AI 工程案例:模型只是其中一个组件。只有将检测、识别、翻译、修复、排版和任务系统连接起来,才能从“识别出图片中的文字”走到“交付一张可以直接发布的多语言图片”。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)