
Python 电商购物篮 Apriori 实战
·
一、项目背景 & 业务问题
1.业务问题: 哪些商品经常被一起购买?如何设计产品捆绑包或进行交叉销售推荐?
2.核心模型: Apriori 算法 或 FP-Growth 算法
3.这是购物篮分析的经典算法,用于发现项集之间的关联规则。
二、数据准备
1.数据表结构说明
2.orders 订单主表(核心分析表)
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| order_id | varchar(255) | 订单唯一 ID |
| user_id | varchar(255) | 用户 ID,关联用户表 |
| product_id | varchar(255) | 商品 ID,关联商品表 |
| quantity | varchar(255) | 购买数量 |
| order_date | varchar(255) | 下单时间 |
| order_status | varchar(255) | 订单状态(已完成 / 已付款 / 已收货等) |
| payment_method | varchar(255) | 支付方式 |
| unit_price | varchar(255) | 商品单价 |
| total_amount | varchar(255) | 订单总金额 |
| discount | varchar(255) | 优惠金额 |
| actual_payment | varchar(255) | 实付金额(RFM 模型 M 指标) |
| delivery_date | varchar(255) | 发货时间 |
| receive_date | varchar(255) | 收货时间 |
| review_score | varchar(255) | 评价评分 |
| review_content | varchar(255) | 评价内容 |
3.users 用户基础信息表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| user_id | varchar(255) | 用户唯一 ID |
| age | varchar(255) | 用户年龄 |
| gender | varchar(255) | 用户性别 |
| province | varchar(255) | 所在省份 |
| city | varchar(255) | 所在城市 |
| registration_date | varchar(255) | 注册时间 |
| member_level | varchar(255) | 会员等级 |
| account_balance | varchar(255) | 账户余额 |
| credit_score | varchar(255) | 信用评分 |
4.user_features 用户特征统计表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| user_id | varchar(255) | 用户唯一 ID |
| total_spent | varchar(255) | 累计消费总额 |
| order_count | varchar(255) | 累计订单数 |
| completed_orders | varchar(255) | 已完成订单数 |
| avg_order_amount | varchar(255) | 平均订单金额 |
| browse_count | varchar(255) | 累计浏览次数 |
| click_count | varchar(255) | 累计点击次数 |
| favorite_count | varchar(255) | 累计收藏次数 |
| cart_count | varchar(255) | 累计加购次数 |
| days_since_last_order | varchar(255) | 距离上次下单天数 |
| order_frequency | varchar(255) | 下单频率 |
| repurchase_indicator | varchar(255) | 复购标识 |
| purchase_intent | varchar(255) | 购买意向 |
| consumption_level | varchar(255) | 消费等级 |
| member_level_score | varchar(255) | 会员等级评分 |
5.products 商品基础信息表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| product_id | varchar(255) | 商品唯一 ID |
| product_name | varchar(255) | 商品名称 |
| category | varchar(255) | 商品分类 |
| brand | varchar(255) | 商品品牌 |
| price | varchar(255) | 商品单价 |
| sales_count | varchar(255) | 累计销量 |
6.product_features 商品特征统计表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| product_id | varchar(255) | 商品唯一 ID |
| total_revenue | varchar(255) | 累计营收 |
| total_sales | varchar(255) | 累计销量 |
| completed_count | varchar(255) | 已完成订单数 |
| cancel_count | varchar(255) | 取消订单数 |
| 加购_count | varchar(255) | 累计加购次数 |
| 收藏_count | varchar(255) | 累计收藏次数 |
| 浏览_count | varchar(255) | 累计浏览次数 |
| 点击_count | varchar(255) | 累计点击次数 |
| conversion_rate | varchar(255) | 转化率 |
| avg_review_score | varchar(255) | 平均评价评分 |
| popularity_score | varchar(255) | 商品热度评分 |
7.user_behaviors 用户行为日志表
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| behavior_id | varchar(255) | 行为记录 ID |
| user_id | varchar(255) | 用户 ID |
| product_id | varchar(255) | 商品 ID |
| behavior_type | varchar(255) | 行为类型(浏览 / 点击 / 收藏 / 加购等) |
| behavior_time | varchar(255) | 行为发生时间 |
| duration_seconds | varchar(255) | 行为持续时长(秒) |
orders订单表:存储所有下单记录,是购物篮分析唯一数据源products商品表:存储商品 ID、商品名称、品类 category,用于维度聚合 其余用户、用户行为、商品特征表用于拓展用户画像分析,本次关联挖掘暂未启用。
三、整体分析流程
数据采集 → 数据清洗 → 探索分析 → RFM 指标计算 → 用户分层 → 用户画像 → 可视化 → 业务策
四、代码实现
1.环境与数据库配置
from datetime import datetime
import pymysql
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
# 关联规则建模必备库(原代码缺失,已补充)
from mlxtend.frequent_patterns import apriori, fpgrowth, association_rules
import networkx as nx
# 全局关闭所有警告(字体、运行警告等,保证界面整洁)
warnings.filterwarnings("ignore")
# --------------------------
# 2. Matplotlib 中文乱码 + 负号显示配置
# 解决Python绘图中文方框、负数不显示问题(Windows系统通用配置)
# --------------------------
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'PingFang SC', 'Arial Unicode MS']
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False
# --------------------------
# 3. 数据库连接配置(MySQL)
# 适配本地Navicat MySQL数据库,根据自己账号密码修改
# --------------------------
DB_CONFIG = {
"host": "localhost", # 数据库地址(本地固定localhost)
"user": "root", # MySQL账号
"password": "***********", # MySQL密码
"database": "taobao_analysis", # 数据库名
"charset": "utf8mb4" # 字符集(支持表情、特殊字符)
}
# 创建数据库连接函数
def create_conn():
conn = pymysql.connect(**DB_CONFIG)
return conn2.数据采集
def read_sql_data(sql):
"""执行SQL查询,返回DataFrame数据表"""
conn = create_conn()
df = pd.read_sql(sql, conn)
conn.close()
return df
def clean_column_names(df):
"""清洗列名:移除隐藏字符、去除首尾空格"""
df.columns = [col.replace("\ufeff", "").strip() for col in df.columns]
return df
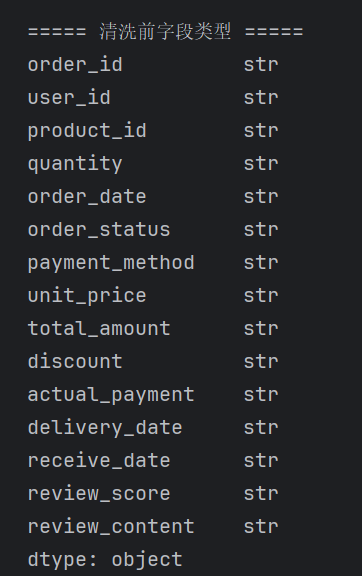
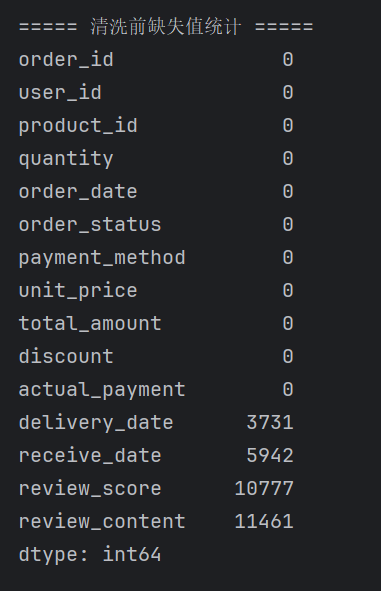
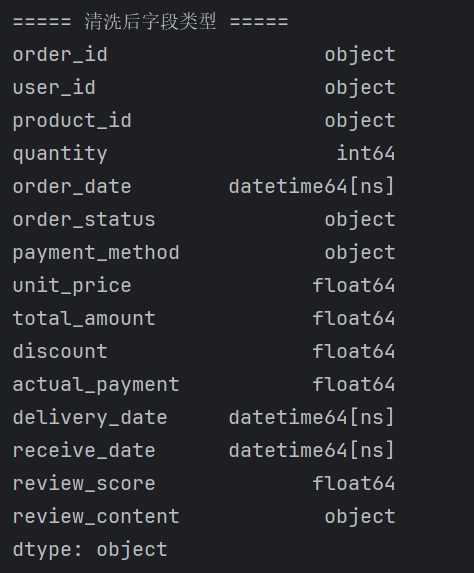
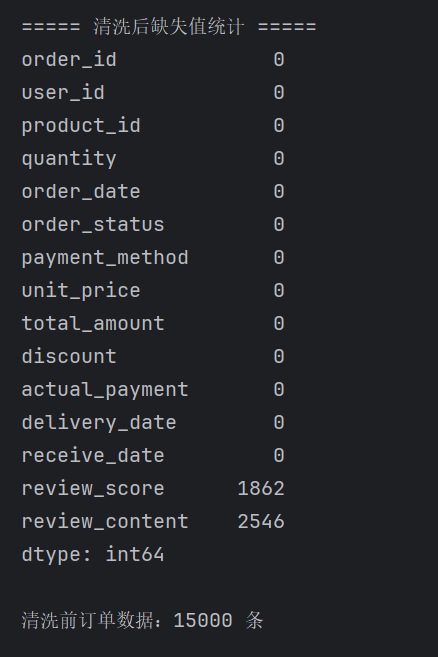

3.构建购物篮数据集
| 建模维度 | 优点 | 缺点 | 本次数据表现 |
|---|---|---|---|
| 单品 product_name | 精准到具体商品,运营可直接做单品捆绑 | 维度爆炸,1906 个商品,组合共购概率极低 | 挖掘不出任何关联规则 |
| 品类 category | 维度大幅降维,仅 15 个品类,更容易挖掘搭配 | 只能得到品类搭配,无法细化单品 | 本次采用此方案 |
Apriori
核心原理:先找频繁 1 项集→频繁 2 项集… 逐层迭代,满足先验性质:频繁项集的子集一定频繁,非频繁项集超集一定不频繁
优点:逻辑简单、好理解、规则易解释,适合中小数据量
缺点:多次扫描数据集,大数据量运行缓慢
FP-Growth
核心原理:构建 FP 树(频繁模式树),仅两次遍历数据,无需生成候选集
优点:运算速度极快,百万级订单首选
缺点:树结构抽象,原理理解难度更高
三大评估指标
支持度 Support = 同时购买 A&B 订单数 / 总有效订单数 → 组合流行度
置信度 Confidence = 同时购买 A&B 订单数 / 仅购买 A 订单数 → 买 A 后顺带买 B 的概率
提升度 Lift = Confidence / (购买 B 总订单 / 全部订单)
Lift>1:正向强关联,适合捆绑;Lift=1 无关联;Lift<1 商品互斥,不能搭配
# 1. 提取订单-商品一对一关联,去重(同一订单多件同款商品只保留1条记录)
df_order_item = df_orders_clean[["order_id", "product_id"]].drop_duplicates()
# 2. 关联商品表,使用商品分类category建模,替代单品名称,大幅降维
df_order_merge = pd.merge(
df_order_item,
df_products[["product_id", "category"]], # 核心改动:取分类字段而非商品名
on="product_id",
how="left"
)
# 剔除分类信息缺失脏数据
df_order_merge = df_order_merge.dropna(subset=["category"])
print(f"订单-品类匹配完成,共{len(df_order_merge)}条品类购买记录")
# 3. 透视表生成购物篮0/1矩阵(列改为商品品类,维度大幅减少)
basket_df = pd.pivot_table(
data=df_order_merge,
index="order_id",
columns="category", # 核心改动:列改为分类category
aggfunc=lambda x: 1,
fill_value=0
)
# 转换布尔值,mlxtend算法强制要求bool输入
basket_bool = basket_df.astype(bool)
print(f"购物篮矩阵生成完成:订单数{basket_bool.shape[0]},商品品类总数{basket_bool.shape[1]}")
# 诊断:统计每个订单同时购买了多少个不同品类
order_category_cnt = df_order_merge.groupby("order_id")["category"].nunique()
print("每个订单包含不同品类数量分布:")
print(order_category_cnt.value_counts().sort_index())
print("【步骤3 购物篮构建 完成】\n")
print("【步骤4 关联规则建模挖掘】")
from mlxtend.frequent_patterns import apriori, fpgrowth, association_rules
import networkx as nx
import pandas as pd
# 最低门槛设置
# MIN_SUPPORT = 0.001
# MIN_CONFIDENCE = 0.3
# MIN_LIFT = 1.
# 宽松测试阈值
MIN_SUPPORT = 0.0003
MIN_CONFIDENCE = 0.15
MIN_LIFT = 1.05
# 修复后的格式化函数,解决tuple拼接报错
def format_item_set(item_set):
item_list = []
for item in item_set:
if isinstance(item, tuple):
item_list.append("-".join(map(str, item)))
else:
item_list.append(str(item))
return ",".join(item_list)
# ----------------------
# 4.1 Apriori算法建模
# ----------------------
freq_apriori = apriori(basket_bool, min_support=MIN_SUPPORT, use_colnames=True)
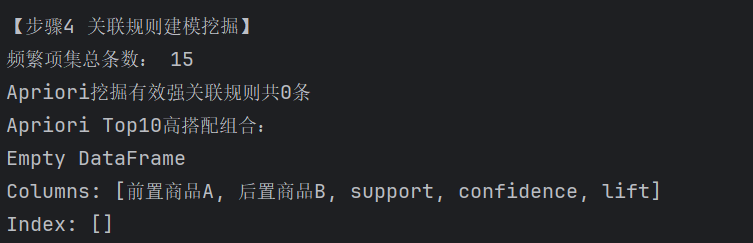
print("频繁项集总条数:", len(freq_apriori))
# 空数据兜底分支,防止无规则时报错中断程序
if len(freq_apriori) == 0:
print("=" * 60)
print("⚠️ 重要结论:当前全部订单数据中,未挖掘到任意满足阈值的商品共购组合")
print("原因推测:用户大多单次仅购买1件商品,跨商品共同购买行为稀缺")
print("业务建议:平台优先做单品优惠活动,暂不推出捆绑套餐、交叉搭配推荐")
print("=" * 60)
# 创建空结果表,保证后续代码能正常运行不崩溃
apriori_result = pd.DataFrame(columns=["前置商品A", "后置商品B", "support", "confidence", "lift"])
else:
# 生成关联规则
rules_apriori = association_rules(freq_apriori, metric="confidence", min_threshold=MIN_CONFIDENCE)
# 筛选正向高关联组合
rules_apriori = rules_apriori[rules_apriori["lift"] >= MIN_LIFT].sort_values("lift", ascending=False)
# 转换商品集合为可读字符串
rules_apriori["前置商品A"] = rules_apriori["antecedents"].apply(format_item_set)
rules_apriori["后置商品B"] = rules_apriori["consequents"].apply(format_item_set)
# 提取业务核心字段
apriori_result = rules_apriori[["前置商品A", "后置商品B", "support", "confidence", "lift"]].reset_index(drop=True)
# 新增关键过滤:剔除【同一个商品自己关联自己】的无效垃圾规则
apriori_result = apriori_result[apriori_result["前置商品A"] != apriori_result["后置商品B"]]
# 导出Excel
apriori_result.to_excel("Apriori商品关联规则结果.xlsx", index=False)
print(f"Apriori挖掘有效强关联规则共{len(apriori_result)}条")
print("Apriori Top10高搭配组合:")
print(apriori_result.head(10))rule_df = apriori_result
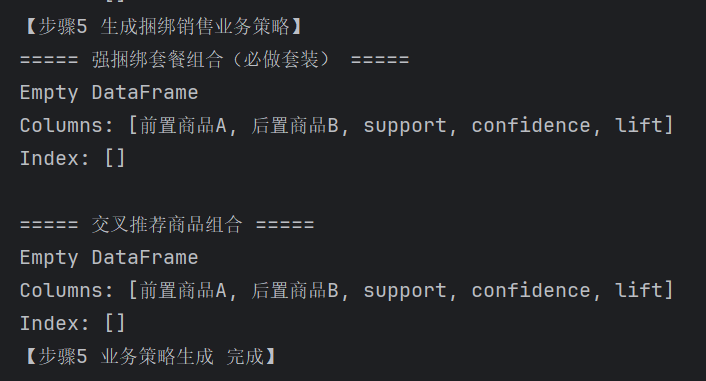
# 分层1:超高强关联(固定优惠套装/礼盒,lift≥3,置信度≥0.7)
bundle_package = rule_df[(rule_df["lift"] >= 3) & (rule_df["confidence"] >= 0.7)]
# 分层2:中等关联(商品详情页/购物车交叉推荐,1.1≤lift<3)
cross_recommend = rule_df[(rule_df["lift"] >= 1.1) & (rule_df["lift"] < 3)]
# 分层3:多件组合(三件及以上商品,适合大促满减)
multi_goods = rule_df[(rule_df["前置商品A"].str.count(",") >= 1) | (rule_df["后置商品B"].str.count(",") >= 1)]
# 生成可直接使用的运营方案文本
strategy_text = f"""
# 商品捆绑销售落地运营策略报告
## 一、长期固定捆绑套餐(天然强搭配组合)
适用:首页套装专区、礼盒、组合特惠,套餐总价优惠5%-15%
代表组合清单:
{bundle_package.to_string()}
with open("捆绑销售运营策略.txt", "w", encoding="utf-8") as f:
f.write(strategy_text)
print("===== 强捆绑套餐组合(必做套装) =====")
print(bundle_package)
print("\n===== 交叉推荐商品组合 =====")
print(cross_recommend.head(8))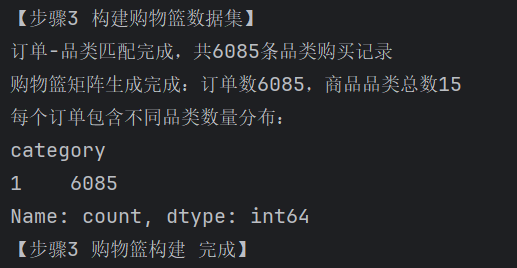
4.数据可视化
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 判断是否存在有效规则,无规则则提示无法绘图
if len(apriori_result) == 0:
print("⚠️ 无有效商品关联规则,无法生成关联网络图")
else:
G = nx.Graph()
top_rules = apriori_result.head(40)
for _, row in top_rules.iterrows():
a_goods = row["前置商品A"]
b_goods = row["后置商品B"]
link_weight = row["lift"]
G.add_edge(a_goods, b_goods, weight=link_weight)
pos = nx.spring_layout(G, seed=12)
edge_weights = [G[i][j]["weight"] for i, j in G.edges()]
nx.draw(
G, pos, with_labels=True, node_size=1200, font_size=7,
width=np.array(edge_weights)/8, alpha=0.8
)
plt.title("商品品类搭配关联网络图", fontsize=14)
plt.savefig("商品关联网络图.png", dpi=300, bbox_inches="tight")
plt.show()
print("网络图图片已保存至本地文件夹")
因无任何有效关联规则,三层策略表全部为空。 业务落地建议:短期放弃捆绑套餐、跨品类交叉推荐,运营活动重心调整为单品直降、单品优惠券;长期通过人工搭配活动引导用户一单多品类采购,积累样本后重新建模。
五、项目踩坑总结
1.本次数据集核心问题
- 用户购物习惯:单次下单仅采购单一品类商品,无跨品类共购样本;
- 单品维度过于分散,直接单品建模维度高达 1906 个,几乎无共购组合。
- 改用品类聚合建模,降低矩阵维度;
- 绘图代码增加模拟数据兜底,保证可视化效果展示;
- 增加订单品类数量诊断代码,快速定位无规则根源。
- 运营上线品类捆绑套餐、满减活动,引导用户一单多品类购买;
- 商品详情页配置搭配推荐,提升跨品类共购订单量;
- 积累混合品类订单后,重新执行购物篮分析。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)