
从 0 到 1 构建电商千人千面——基于 Easysearch 的个性化搜索与推荐系统实战
你有没有遇到过这种情况——搜“蓝牙耳机”,出来的全是你不喜欢的半入耳式,而你明明是个运动达人,想要挂耳式的?或者一打开电商首页,推荐的商品跟自己毫无关系,仿佛系统根本不认识你?
今天我们就聊聊,怎么从零搭一个能“认人”的电商搜索系统,让不同的人搜同一个词、看同一张首页,得到的结果都不一样。咱们用的底座是 Easysearch(跟 Elasticsearch 兼容),用 Python Flask 写后端,前端是干净的 HTML+JS,全程跑得通。

我会用大白话把事情讲清楚,但该给的 DSL、该说的实现细节一个都不会少。看完你就能上手,给自家系统加上“千人千面”的推荐能力。
一、先搞清楚:为什么需要“认人”?
一个电商系统,SKU 多了,搜索必须快,这个是基本要求。但快还不够,还要“懂你”。
举个例子,系统里有一堆耳机:
-
A 是一个学生党,预算 200 左右,常看“性价比”“低延迟”。
-
B 是一个健身教练,爱买“运动”“防水”“挂耳”。
-
C 是个商务人士,喜欢“降噪”“高端”“长续航”。
如果三个人都搜“耳机”,给他们返回同样的排序,那就太蠢了。搜索结果应该根据每个人的口味重新排队。
Easysearch 在官网说它支撑“个性化推荐”,但它毕竟是个搜索引擎,怎么个性化是你自己要去设计的。
我们这套 SearchPersona 系统,就是把这个设计完整落地了一遍:先采集行为,再算出画像,最后在搜索那一刻注入个性化因子。
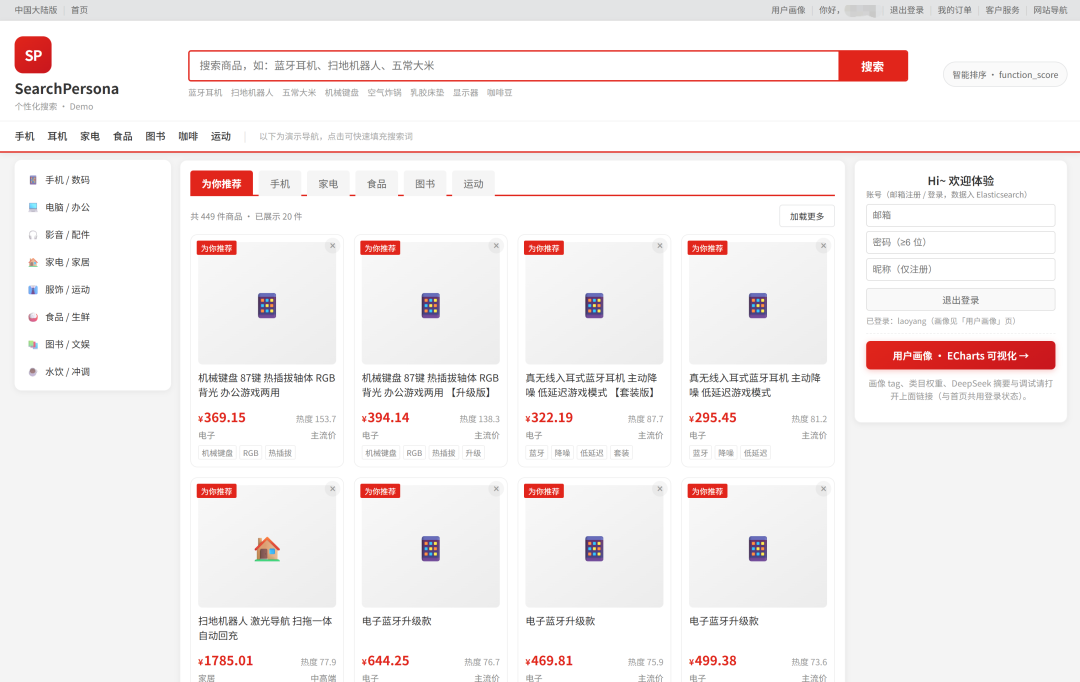
二、系统是怎么跑起来的?一张图看懂
整个链路长这样:
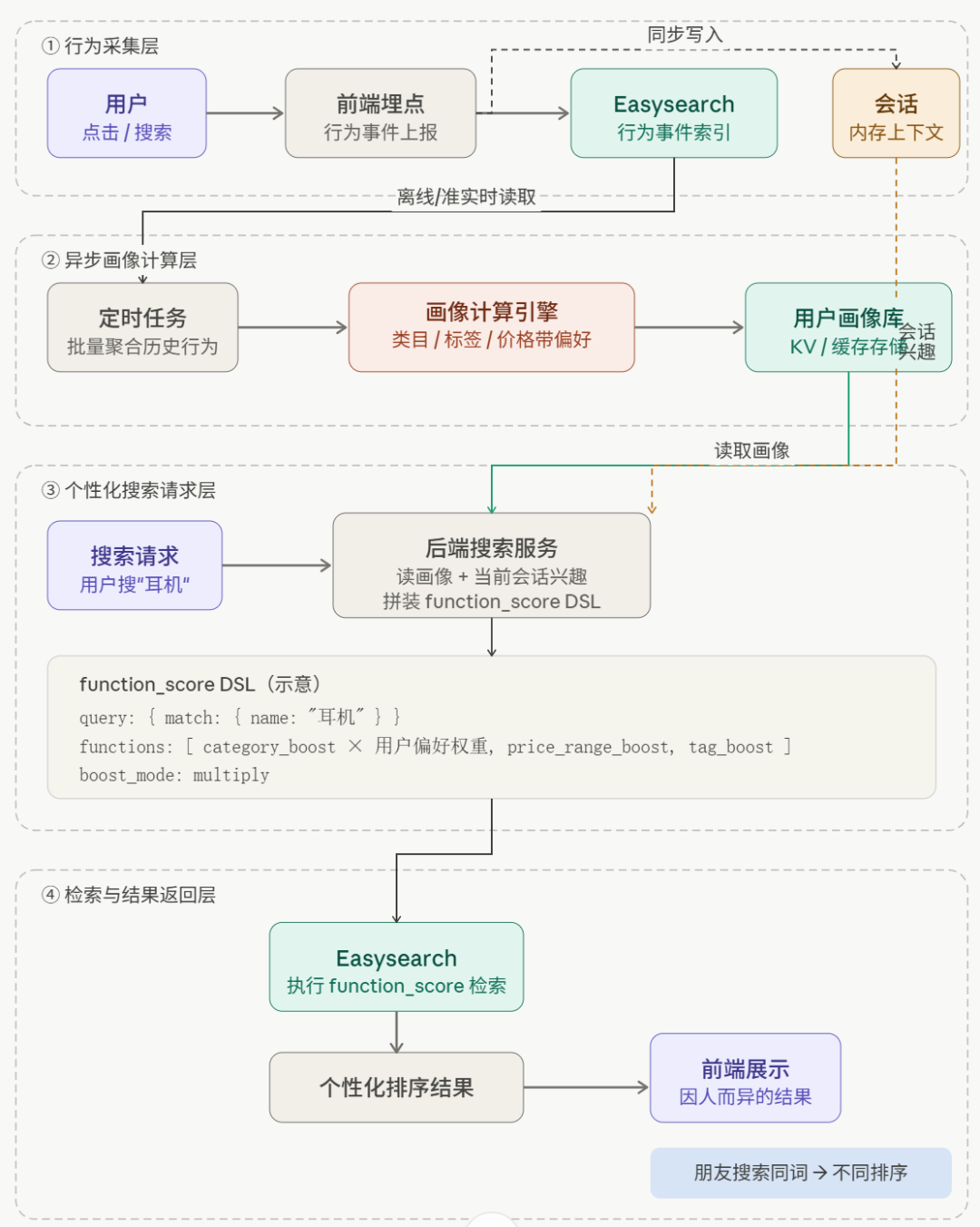
这里面最核心的其实是 build 那个搜索 DSL 的函数,等下我会重点讲。
三、商品数据:怎么存,才能让机器“认得”商品?
我们要个性化,首先得让商品有一些能被“加权”的属性。不能光有一个标题,那只能做文本匹配。
在初始化索引的时候(scripts/init_indices.py),我把商品定成这个样子:
{
"id": "rc_001",
"title": "真无线入耳式蓝牙耳机 主动降噪 低延迟游戏模式",
"category": "电子",
"sub_category": "音频设备",
"tags": ["蓝牙", "降噪", "低延迟"],
"price": 289.0,
"price_tier": "mid",
"score_base": 0.78,
"created_at": "2025-01-15"
}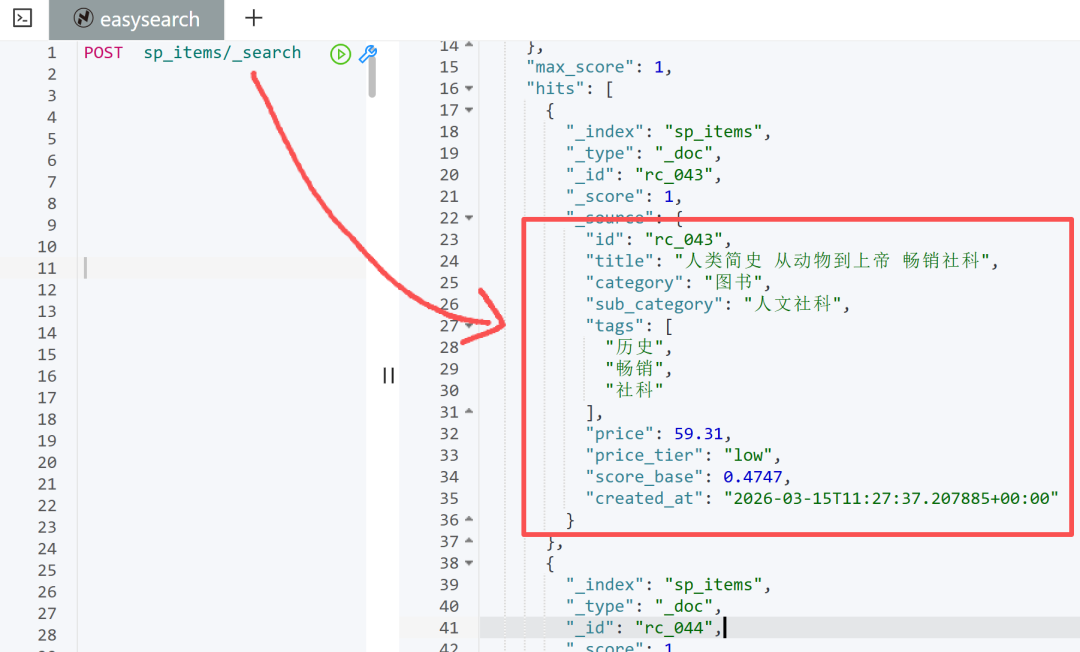
这里有几个设计要点:
-
category是 keyword 类型,以后画像里算出你喜欢“电子”,我就给“电子”的商品加权。 -
tags也是 keyword 数组,你喜欢“蓝牙”“降噪”,我就给打了这些标签的商品加分。 -
price_tier我分了五档:budget(入门)、value(平价)、mid(主流)、upper(中高端)、premium(旗舰)。这样我可以把价格偏好也切成若干个桶,而不是用连续的数字(连续数字做加权很麻烦,keyword 直接 term 匹配多爽)。 -
score_base是一个内容质量分,类似流行度,可以用field_value_factor做加权。
我们写了个小脚本 scripts/import_real_cases.py 导入了 100 条贴近真实的商品,覆盖电子、家居、服装、食品、图书,每个商品都有细致的标签,这样个性化才能看出效果。

四、行为采集:你怎么让系统知道你喜欢什么?
你要“告诉”系统你喜欢啥,就得让它盯着你的操作。每当你点击商品、浏览商品详情,前端就悄悄发一个请求:
POST /api/event
{
"event_type": "click",
"item_id": "rc_001",
"item_category": "电子",
"item_price_tier": "mid",
"item_tags": ["蓝牙", "降噪"],
"session_id": "sess_abc",
"user_id": "user_123"
}后端干两件事:
-
**把这条行为写入 Easysearch 的行为索引
sp_behavior_events**,供之后画像聚合使用。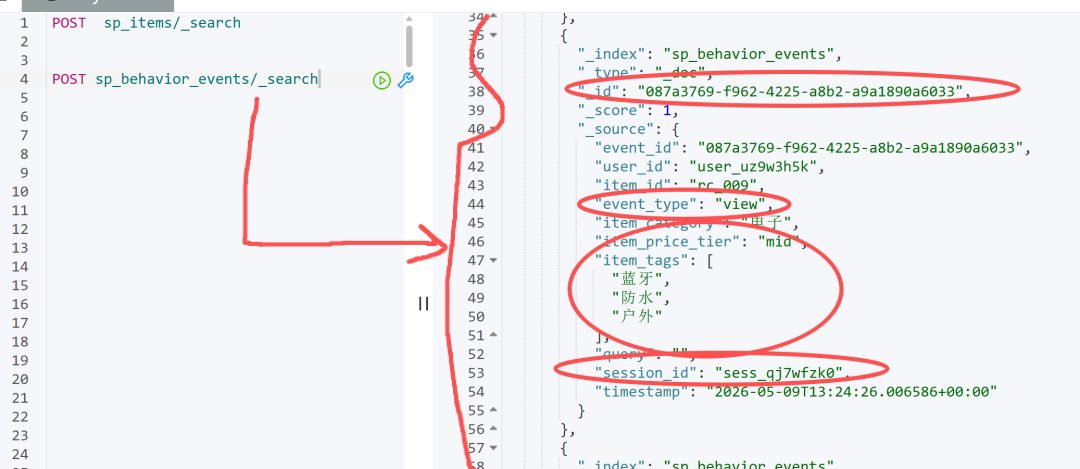
-
更新内存里的 Session 上下文,把点击的类目和浏览的标签记下来,供本次会话内的搜索立刻使用。
为什么不能只靠 ES 里的历史行为?因为 ES 的刷新有延迟(默认 1 秒),而用户可能刚点了一个“椅子”,马上搜“家具”,我们总不能让他等 1 秒才看到椅子排在前面吧?所以内存里的 Session 上下文就是解决“秒级实时性”的,后面改进的时候准备放 redis 会更好!。
Session 上下文长这样:
{
"clicked_categories": ["电子", "电子", "家居"],
"viewed_tags": ["蓝牙", "降噪", "静音"]
}很简单,就是两个列表。在搜索时,我会临时给这些类目和标签加分。
五、用户画像:怎么把你的“隐性偏好”算成“显性权重”?
只有实时的 Session 上下文还不够,因为换个浏览器、过几小时可能就丢了,我们需要一个长期的兴趣档案,这就是用户画像。
画像的生成逻辑在 core/profile_builder.py 里,核心方法是 build_from_events。

5.1 统计聚合 + 时间衰减
我取出你最近 N 天(比如 30 天)的点击、浏览、购买事件,然后给不同行为不同的基础权重:
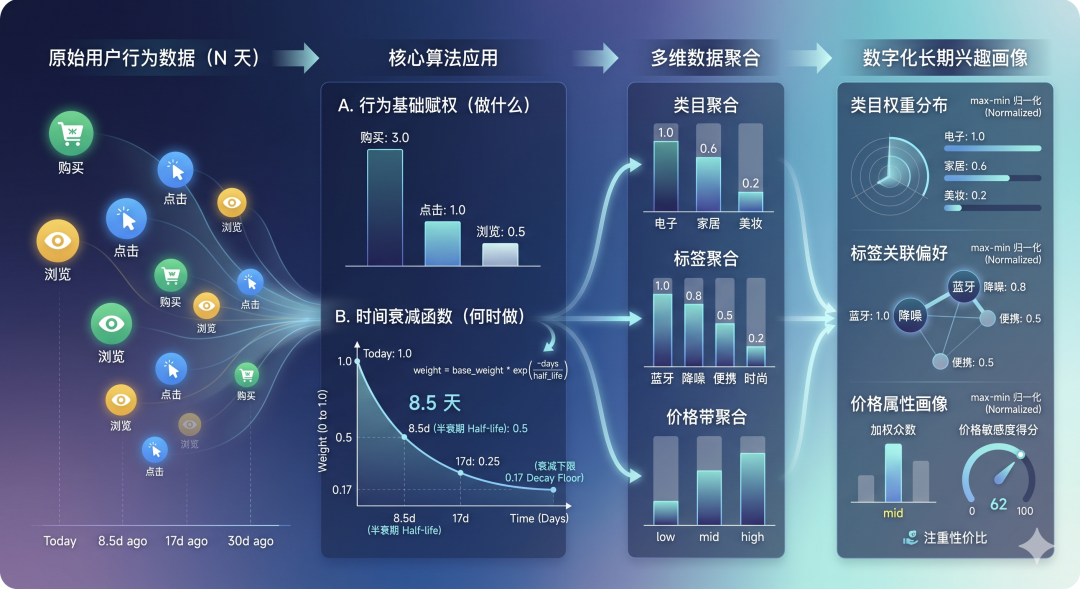
-
购买:3.0
-
点击:1.0
-
浏览:0.5
同时加一个时间衰减函数,越久远的事件权重越低:
weight = base_weight * exp(-days / half_life)半衰期设为 8.5 天,也就是说 8.5 天前的行为权重剩一半,17 天前剩 1/4。还设了个衰减下限 0.17,不至于老行为影响归零。
按类目、标签、价格带分别累加权重,然后归一化(max-min 归一化),得到:
"category_weights": { "电子": 1.0, "家居": 0.6 },
"tag_weights": { "蓝牙": 1.0, "降噪": 0.8, "便携": 0.5 },
"price_tier_pref": "mid" // 加权众数
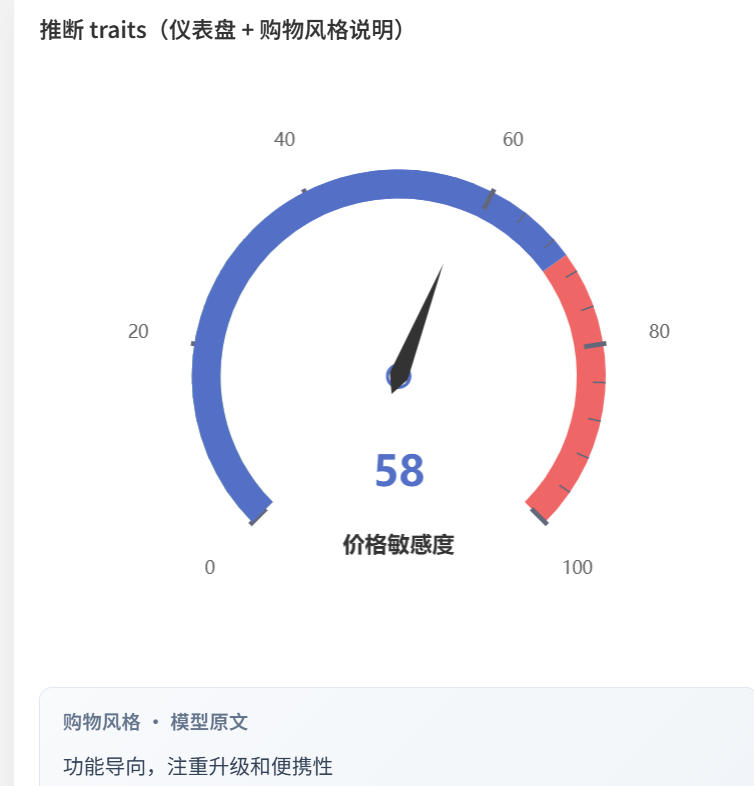
"price_sensitivity_score": 62 // 0~100 连续值,越接近 100 越在意价格这样,你的长期兴趣就数字化了。
画像重建时,还会把本次会话的点击类目也加进去(PROFILE_REBUILD_SESSION_CATEGORY_BOOST=1.2),保证刚发生的兴趣也能立刻反映在画像里,等下次 rebuild 时彻底固化。
5.2 让大模型(DeepSeek)帮你“读懂”你的行为
纯统计画像有时候太硬了,只知道你点了“蓝牙”“降噪”,但不知道你到底是个科技发烧友还是普通上班族。所以我们把最近的行为流水喂给 DeepSeek(OpenAI 兼容接口),让它生成一段文字描述和一些兴趣标签。
比如我们构造这样的 prompt:
你是电商搜索的用户画像分析师。只根据用户行为列表推断兴趣……
用户近期行为如下:
- [purchase] 类目=电子 价格带=主流价(mid) tags=[降噪,长续航] 搜索词=降噪耳机
- [click] 类目=电子 价格带=入门价(budget) tags=[运动,防水] 搜索词=跑步耳机
...要求它输出 JSON:
{
"summary": "用户偏好中端降噪耳机与运动音频设备,对性价比敏感",
"interest_tags": ["降噪耳机", "运动耳机", "百元档"],
"category_hints": ["电子"],
"traits": { "price_sensitivity": "medium" }
}这些 LLM 生成的标签 llm_interest_tags 和 llm_category_hints 会存进用户画像文档,后续搜索时当额外标签用,权重系数 LLM_TAG_WEIGHT 可配置(默认 1.25)。


即使你是个新用户,只有几条点击,统计画像还没累积,LLM 也能猜个八九不离十,让你的冷启动体验不“冷”。
六、搜索排序:怎么把画像变成搜索结果?
这是整套系统的灵魂。所有的画像、会话上下文,最终都注入到 Easysearch 的查询 DSL 里。
核心代码在 core/persona_ranker.py 的 build_query 方法。我一步步说它怎么拼 DSL。
假设用户搜“耳机”,我们先用一个简单的 multi_match 把基础相关度算出来:
{
"multi_match": {
"query": "耳机",
"fields": ["title^2", "tags"],
"type": "best_fields"
}
}标题权重是标签的两倍,这个只是基础的文本相似分。
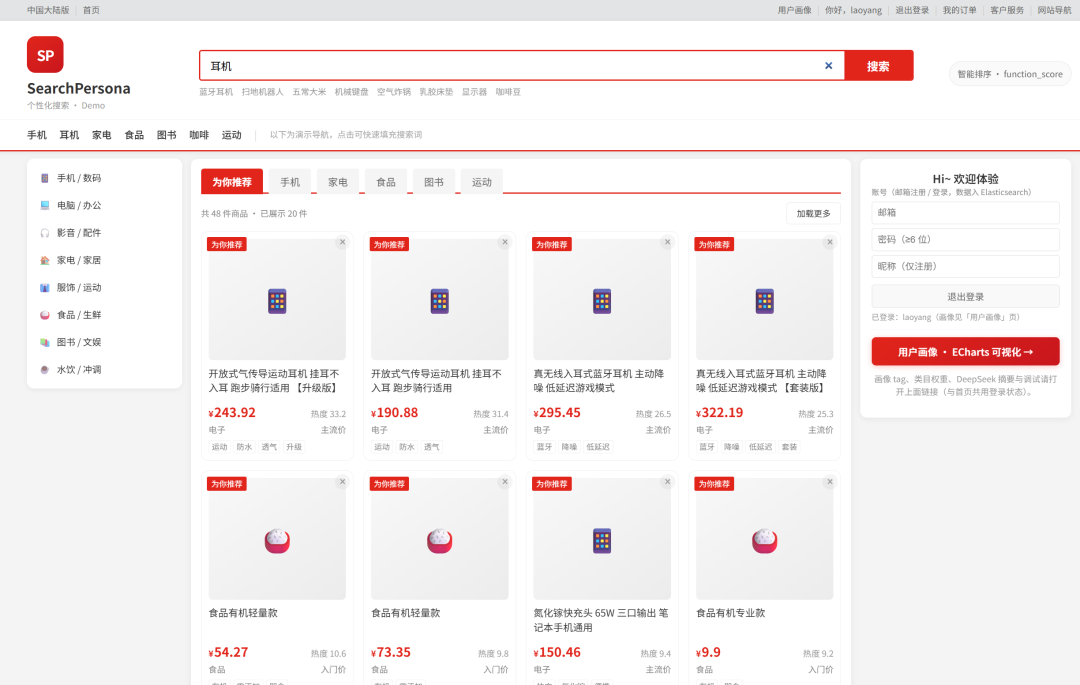
然后就到 function_score 上场了。它可以在基础分之上叠加很多“函数”,我们用它来注入个性化。
6.1 类目加权
从画像里取出 category_weights,遍历每个权重超过阈值(0.45)的类目,构建:
{ "filter": { "term": { "category": "电子" } }, "weight": 2.4 }这个 weight 是怎么算的?
画像中电子权重(比如 1.0) × PERSONA_CATEGORY_WEIGHT(默认 2.0)= 2.0。
如果当前会话也点击过“电子”,再加 PERSONA_SESSION_BONUS(0.5),所以最终是 2.5 左右。
这就意味着,只要你历史上对“电子”感兴趣,所有“电子”类的商品在“耳机”这个关键词下的原始得分上,都会被额外乘以一个大权重。
6.2 价格带匹配
从画像里拿到你的价格带偏好,比如 price_tier_pref: "mid",于是我加两个函数:
{ "filter": { "term": { "price_tier": "mid" } }, "weight": 1.5 },
{ "filter": { "bool": { "must_not": [{ "term": { "price_tier": "mid" } }] } }, "weight": 0.8 }-
恰好是“主流价”的商品,基础分乘以 1.5 加成。
-
不是“主流价”的商品,乘以 0.8 降权,但不至于完全不能出现,只是排在后面。
6.3 标签加权
画像里的 tag_weights 和 LLM 兴趣标签,只要权重 >0.3 的标签,都加上:
{ "filter": { "term": { "tags": "蓝牙" } }, "weight": 1.5 },
{ "filter": { "term": { "tags": "降噪" } }, "weight": 1.25 }如果你当前会话还浏览过这些标签,再加一点 bonus。
6.4 会话兜底
这是非常关键的一步:
假如你根本没登录,或者画像里还没有多少兴趣标签(新用户),我们不能让你看到的搜索结果完全是随机的文本排序。
所以我把你当前会话已经点击的类目、浏览的标签,拿出来也弄成加权函数:
// 本会话点击过的类目(即使画像中没有)
{ "filter": { "term": { "category": "家居" } }, "weight": 0.76 }
// 本会话浏览过多次的标签
{ "filter": { "term": { "tags": "静音" } }, "weight": 0.56 }权重系数分别为 PERSONA_SESSION_ONLY_CATEGORY_BOOST=0.38 和 PERSONA_SESSION_ONLY_TAG_BOOST=0.28,乘以频次。这样即使你之前从来没看过家居,此刻随便点了一个“台灯”,再搜“桌子”也能看到相关的家居桌子排前面。
6.5 内容质量分
最后再加一个 field_value_factor:
{ "field_value_factor": { "field": "score_base", "factor": 1.2, "modifier": "ln1p", "missing": 0.1 } }score_base 是内容热度分,0~1,取 ln(1 + 1.2 * 分),让高质量商品基础动能大一点。
所有这些函数使用 score_mode: "sum",也就是把各个函数的得分加起来,再乘以基础查询的 _score(boost_mode: "multiply")。最终总分就是文本相关度 × 个性化综合权重。
6.6 最终 DSL 长这样(截短示例)
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "耳机",
"fields": ["title^2", "tags"],
"type": "best_fields"
}
},
"functions": [
{ "filter": { "term": { "category": "电子" } }, "weight": 2.4 },
{ "filter": { "term": { "price_tier": "mid" } }, "weight": 1.5 },
{ "filter": { "term": { "tags": "蓝牙" } }, "weight": 1.5 },
{ "filter": { "term": { "tags": "降噪" } }, "weight": 1.25 },
{ "filter": { "term": { "category": "家居" } }, "weight": 0.76 },
{ "field_value_factor": { "field": "score_base", "factor": 1.2, "modifier": "ln1p", "missing": 0.1 } }
],
"score_mode": "sum",
"boost_mode": "multiply",
"min_score": 0.1
}
},
"from": 0,
"size": 20
}现在你明白了吧,同一个 query“耳机”,A 用户因为画像权重里“电子”1.0、“蓝牙”0.9,结果中电子类、带蓝牙的商品分超高;
B 用户画像里“运动”权重高,且价格带是“value”,那运动耳机就更靠前。
千人千面就是这么来的。
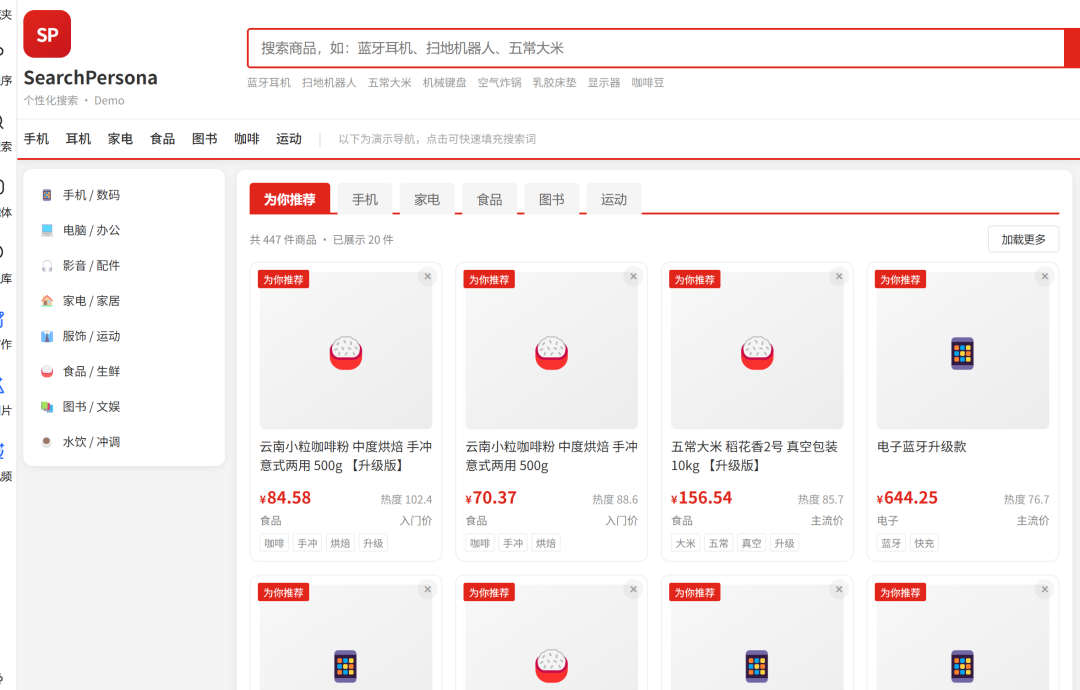
七、“为你推荐”怎么做?没有查询词,画像替你造词
在首页推荐场景,用户没主动搜,但我们仍然想给他个性化的商品。思路很简单:拿用户画像里的标签、类目,以及 LLM 推断的兴趣词,拼成一个多词查询,然后用 multi_match 去搜。
代码在 PersonaRanker.build_persona_feed_keyword 里,拼词顺序:
-
画像 tag_weights 里权重 >0.12 的标签(最多 10 个)
-
画像 category_weights 里权重 >0.2 的类目名
-
LLM 的
interest_tags(最多 8 个) -
LLM 的
category_hints(最多 4 个) -
当前会话点击类目和浏览标签
去重后拼接成字符串,比如:“蓝牙 降噪 电子产品 运动耳机 家居”。如果啥也没有,就用兜底词“键盘 大米 咖啡 图书 家居 耳机”。
然后这个字符串作为 query 丢给上面那个 build_query,同样注入画像加权,首页推荐流就出来了。每个用户看到的推荐流都不一样。
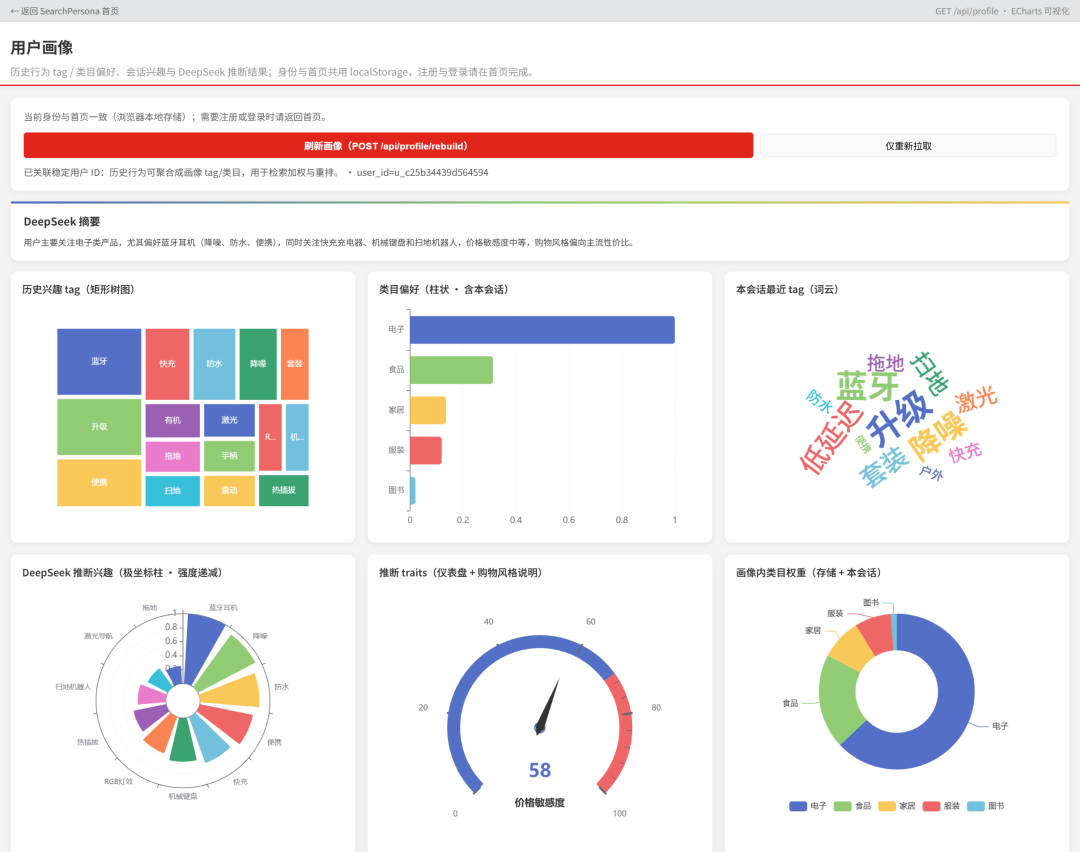
八、可视化:让你亲眼看见“系统怎么懂你”
我做了个简洁的画像页面(/persona),用 ECharts 把你所有的兴趣可视化:
-
矩形树图:展示画像里的兴趣标签权重。
-
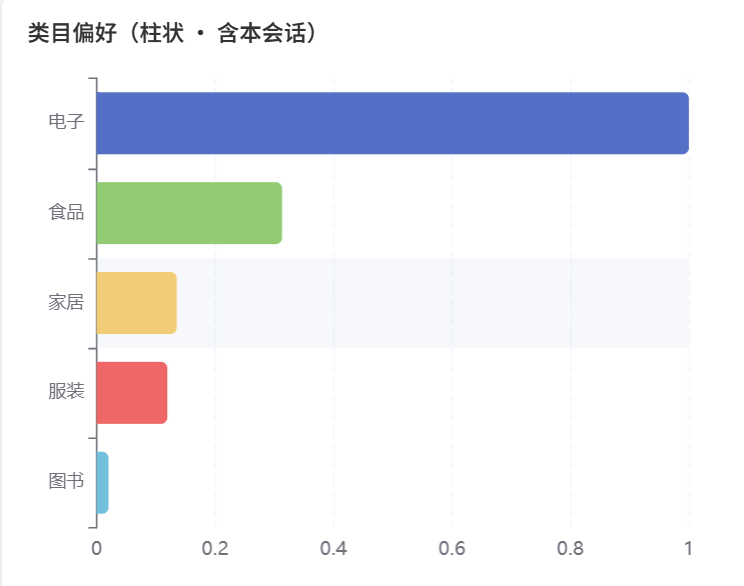
柱状图:展示类目偏好(融合了存储权重和当前会话点击)。
-
词云:本会话最近查看的标签。
-
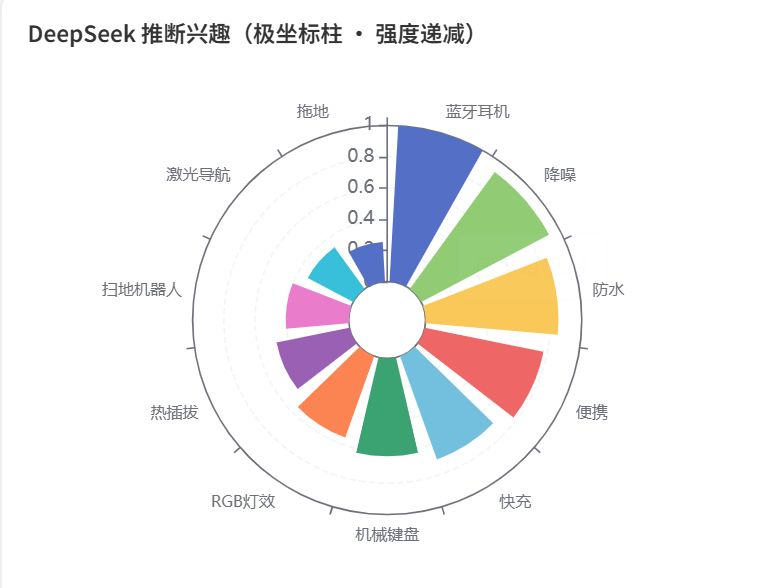
极坐标图:LLM 推断的兴趣标签(强度递减)。
-
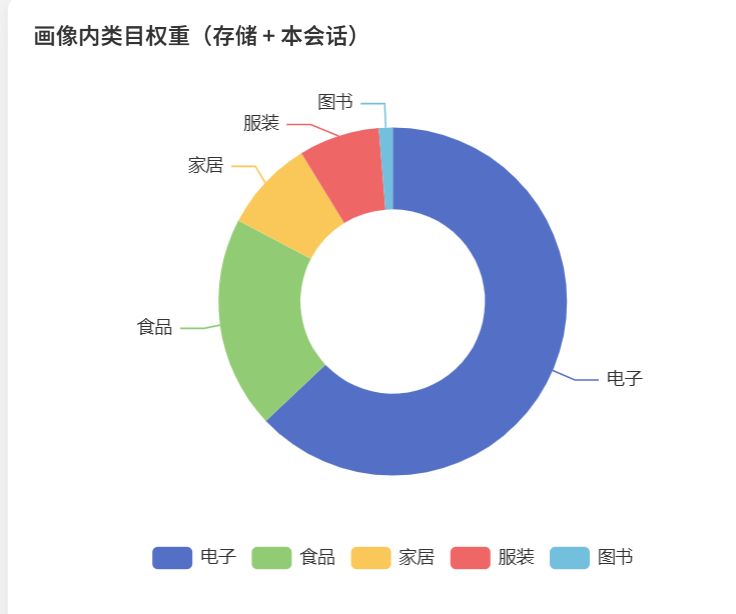
饼图:画像内类目权重分布。
-
文字描述:LLM 生成的用户摘要。
你可以一键点“刷新画像”,触发 POST /api/profile/rebuild,系统重新从 ES 聚合统计并调用 LLM 更新。
九、总结
咱们用一个完整的项目 SearchPersona 跑通了个人性化电商搜索的全流程:
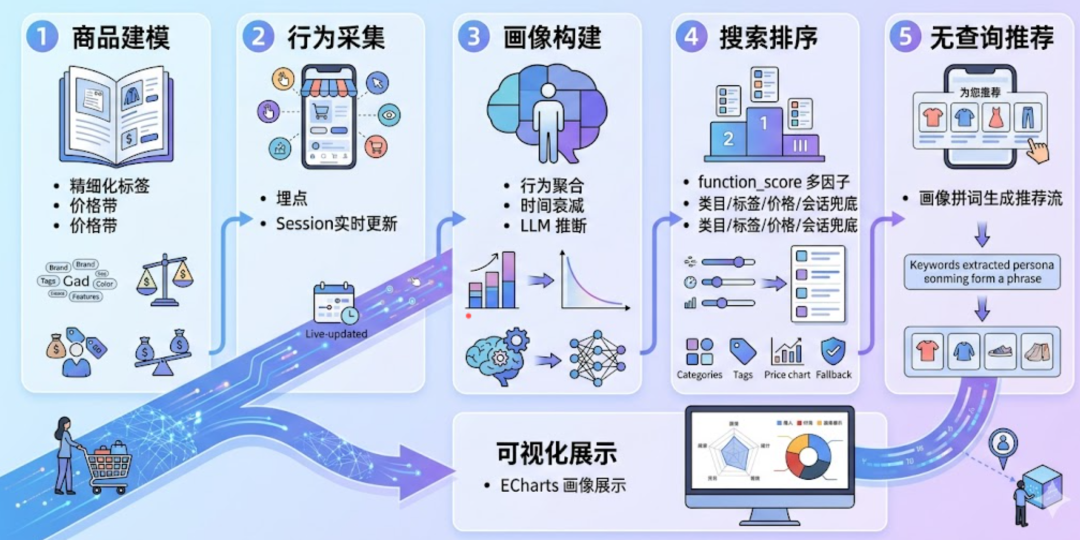
-
商品建模:精细化的标签和价格带。
-
行为采集:埋点 + Session 上下文实时更新。
-
画像构建:行为聚合 + 时间衰减 + LLM 推断。
-
搜索排序:function_score 多因子加权,包括类目、标签、价格、会话兜底。
-
无查询推荐:从画像拼词生成推荐流。
-
可视化:ECharts 展示画像。
整个系统足够简洁,但覆盖了工业级个性化搜索的核心理念。你可以直接拿去用,或者在现有 ES 搜索上加一层类似的 function_score 逻辑。
希望这篇大白话技术博客能让你对“千人千面”的实现不再觉得神秘。有任何问题,评论区找我聊。觉得有用的话,点个赞、点个在看,分享给更多做搜索的朋友。
铭毅天下,专注 ES / Easysearch 技术实践,关注我,搜索不迷路!
告别命令行!INFINI Easysearch 全新图形化部署体验实战详解
Easysearch——Elasticsearch 国产化替代方案!
EasySearch 最常见问题答疑——国产化搜索引擎实战指南
投标环节:如何科学、合理地介绍 Elasticsearch 国产化替代方案——Easysearch?

更短时间更快习得更多干货!
和全球 2100+ Elastic 爱好者一起精进!

AI 时代,抢先一步学习进阶干货!

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)