
电商项目核心订单系统设计与实现:从业务分析到分库分表全解析
一、订单系统业务分析
订单系统是电商平台最重要的子系统之一,承载着用户交易的核心数据。一个合格的订单系统必须保证数据绝对正确,即使在复杂的分布式环境下也能保持一致性。主要挑战包括:
-
代码正确性:避免因Bug导致数据错误。
-
事务正确使用:在微服务架构下,不仅需要本地事务,还需分布式事务支持。
-
异常情况处理:如重复请求、并发更新等问题需特殊处理。
订单系统通常分为当前订单程序和历史订单处理程序,数据存储也进行分库分表设计。
二、订单系统的核心功能和数据表
核心功能包括:
-
填写并核对订单信息
-
创建订单(订单确认 + 订单提交)
-
更新订单状态(支付、发货、收货等)
-
查询订单
核心数据表(至少4张):
-
订单主表(oms_order):保存订单基本信息。
-
订单商品表(oms_order_item):保存订单商品信息。
-
订单支付表:保存支付与退款信息(本系统简化至订单主表中)。
-
订单优惠表:保存优惠信息(本系统未使用)。
在本文所述系统中,进行了适度简化:
-
取消独立优惠表
-
支付状态直接保存在订单主表
-
库存扣减由订单系统发起,产品服务执行
订单状态枚举:
-
0: 待付款
-
1: 待发货
-
2: 已发货
-
3: 已完成
-
4: 已关闭
-
5: 无效订单
三、订单重复下单问题与解决方案
问题描述:
用户重复点击“提交订单”按钮,或因网络重试、RPC框架自动重试等机制,导致重复创建订单。
解决方案:幂等性设计
-
幂等性定义:多次执行与一次执行影响相同。
-
实现方法:利用数据库主键唯一约束。
具体步骤:
-
前端预生成订单号(调用
generateOrderId服务) -
提交订单时携带该订单号
-
订单服务插入数据时使用该订单号作为主键
-
重复插入将因主键冲突而失败
时序图(见文档Page 8):
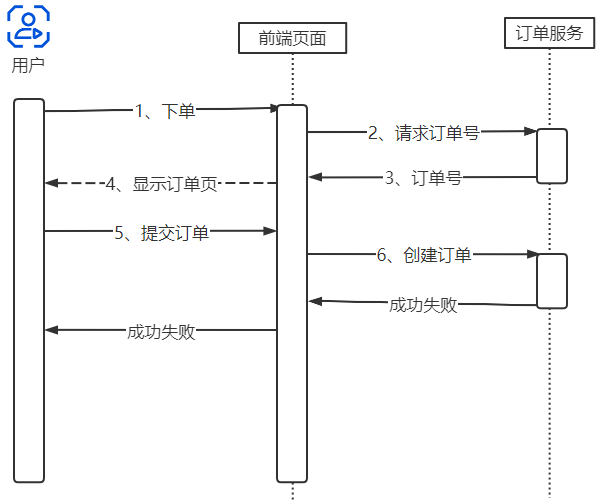
text
[前端] -> [订单服务]: 获取订单号 [订单服务] -> [前端]: 返回订单号 [前端] -> [订单服务]: 提交订单(携带订单号) [订单服务] -> [数据库]: 插入订单(主键=订单号)
异常处理:
捕获DuplicateKeyException或SQLIntegrityConstraintViolationException,直接返回“订单创建成功”。
四、订单ABA问题与解决方案
问题描述:
在并发更新订单时,可能出现状态回滚问题。例如:
-
订单单号更新为666
-
更新为888
-
重试更新为666(因第一次更新响应丢失),导致数据错误。
解决方案:版本戳机制
-
在订单主表增加
version字段 -
查询订单时返回版本号
-
更新时携带版本号,执行条件更新:
sql
UPDATE orders SET tracking_number=666, version=version+1 WHERE version=?
-
若版本号不匹配,则更新失败,需重新查询并重试。
注意事项:
-
比较版本号、更新数据、版本号+1必须在同一事务中
-
更新失败时应重试(本系统未实现,可自行扩展)
五、读写分离与分库分表
5.1 读写分离
-
适用场景:读多写少(读写比例可达9:1甚至几十:1)
-
架构:一主多从,主库写,从库读
-
好处:提升并发能力,易于实施
数据不一致问题:
主从同步有微小延迟(几毫秒),可能导致更新后立即查询读到旧数据。
解决方案:
-
业务层面规避:如支付完成后跳转至“支付成功页”,而非直接返回订单页
-
强制读主库:将更新与查询放在同一事务中,或指定查询主库
5.2 分库分表
适用场景:
-
分表:解决单表数据量过大导致的查询性能问题
-
分库:解决高并发请求压力
拆分原则:
-
能少拆就少拆,避免过度分散
-
一般同时进行分库分表
分片键选择:
-
订单表:常用分片键为订单ID或用户ID
-
挑战:按不同条件查询(如按用户ID、订单ID、店铺ID)需不同分片策略
解决方案:
-
订单ID中嵌入用户ID后缀,支持按订单ID和用户ID分片查询
-
数据同步至其他存储(如只读库、HDFS)支持复杂查询
六、商城订单服务的实现
6.1 数据量预估
-
月订单量:2000W
-
年订单量:2.4亿(每条约1KB)
-
单表建议不超过2000W行
-
订单商品表:平均每订单10商品,年记录24亿
6.2 分表设计
-
订单表:32张
-
订单商品表:32张
-
虽单表数据量达8000W,但综合考虑关联查询性能,选择32张表
6.3 分片键与算法
-
订单表分片键:
id(订单ID)、member_id(用户ID) -
订单商品表分片键:
order_id -
分片算法:哈希取模(对32取模)
-
订单ID生成:唯一ID + 用户ID后两位拼接
6.4 技术实现:Sharding-JDBC
采用Sharding-JDBC组件,配置读写分离与分库分表。
关键配置(见文档Page 14-15):
yaml
spring:
shardingsphere:
datasource:
names: ds-master
rules:
sharding:
tables:
oms_order:
actual-data-nodes: ds-master.oms_order_$->{0..31}
table-strategy:
complex:
sharding-columns: id,member_id
sharding-algorithm-name: oms_order_table_alg
oms_order_item:
actual-data-nodes: ds-master.oms_order_item_$->{0..31}
table-strategy:
complex:
sharding-columns: order_id
sharding-algorithm-name: oms_order_item_table_alg
分片算法类:
-
OmsOrderShardingAlgorithm:根据订单ID或用户ID后两位取模定位表 -
OmsOrderItemShardingAlgorithm:根据订单ID后两位取模定位表
七、总结
订单系统设计核心要点:
-
幂等性是保证数据正确的关键,通过预生成订单号和版本戳机制实现。
-
读写分离可有效提升读并发,但需注意主从延迟问题。
-
分库分表是应对大数据量和高并发的终极手段,需谨慎选择分片键。
-
Sharding-JDBC是较好的分库分表实现方案,侵入性低,性能稳定。
在实际项目中,应根据业务规模和发展阶段选择合适的架构方案,避免过度设计。订单系统作为电商核心,其稳定性和数据一致性永远是第一位的。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 29
29 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)