
基于 LightFM 的电商商品混合推荐系统实战
摘要
本文围绕一个电商商品混合推荐项目展开,重点使用 UCI Machine Learning Repository 的 Online Retail 公开交易数据集。项目把真实发票明细转换为 users.csv、products.csv、interactions.csv 三张推荐系统核心表,再完成隐式反馈建模、用户/商品特征构造、混合推荐训练、Top-N 推荐、评估指标计算、HTML 报告生成和截图展示。
本次真实运行保留了 180 个客户、320 个商品、53349 条购买交互。项目按 --backend auto 选择稳定后端;在 Windows 编译版 LightFM 对 WARP/BPR 排序损失不稳定时,会自动使用 fallback_svd_content,即 SVD 协同信号 + 商品内容特征 + 热度分数融合。源码仍保留 LightFM 后端,如果希望验证编译版 LightFM,可使用 --backend lightfm --loss logistic。本文所有指标图、推荐列表、报告截图均由本项目代码真实运行生成。
关键词:推荐系统、LightFM、电商推荐、混合推荐、隐式反馈、UCI Online Retail、Top-N 推荐、Python 项目实战
真实数据与业务场景
电商推荐系统的核心输入通常不是显式评分,而是浏览、收藏、加购、购买等行为。UCI Online Retail 数据集记录了一家英国线上零售商在 2010-12-01 至 2011-12-09 之间的真实交易明细,字段包含 InvoiceNo、StockCode、Description、Quantity、InvoiceDate、UnitPrice、CustomerID 和 Country。这些字段非常适合改造成推荐系统中的用户、商品、行为三张表。
下面这张真实商品陈列图来自 Wikimedia Commons,用来对应电商商品推荐的业务语境:真实平台里商品有价格、品类、陈列位置和库存变化,推荐系统需要在大量 SKU 中为用户选出更可能购买的候选商品。

项目新增了 scripts/prepare_uci_online_retail.py,用于把 UCI 原始 Excel/zip 文件转换成项目可直接读取的 CSV。转换时保留真实 CustomerID 和 StockCode,并派生出推荐模型需要的字段:
| 目标文件 | 来源与处理方式 | 作用 |
|---|---|---|
users.csv |
由 CustomerID 聚合得到,偏好类目和价格偏好来自历史购买行为 |
构建用户特征 |
products.csv |
由 StockCode、Description、UnitPrice 和 Country 聚合得到 |
构建商品特征 |
interactions.csv |
每条有效购买记录转换为一次 purchase 隐式反馈 |
构建用户-商品交互矩阵 |
source_summary.json |
保存原始行数、保留规模和时间范围 | 方便复现实验 |
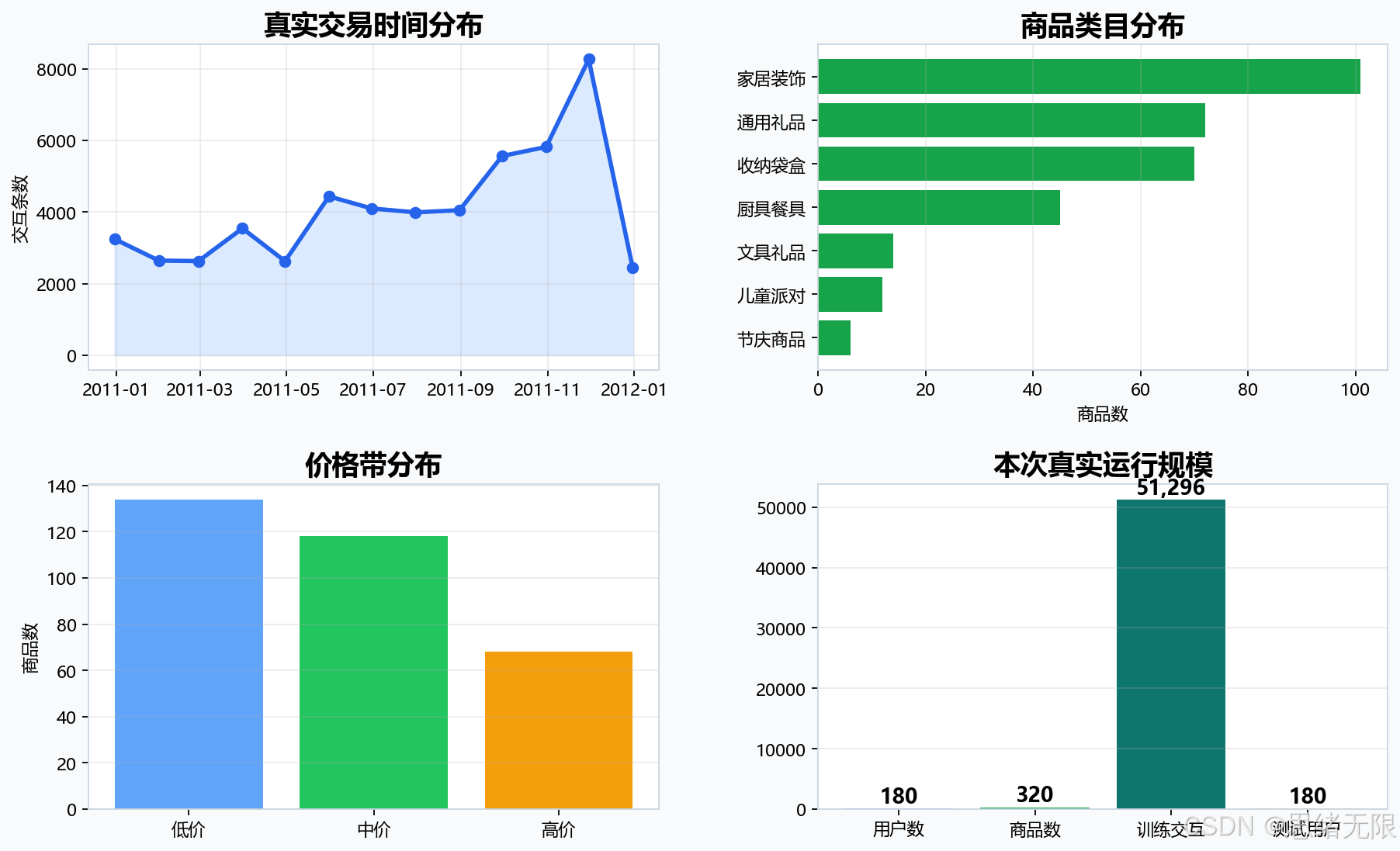
本次运行的数据概览如下。可以看到,交易在 2011 年下半年逐渐升高,商品主要集中在家居装饰、通用礼品、收纳袋盒和厨具餐具等类目,价格带也被拆成低价、中价和高价三档。
系统流程与模型实现
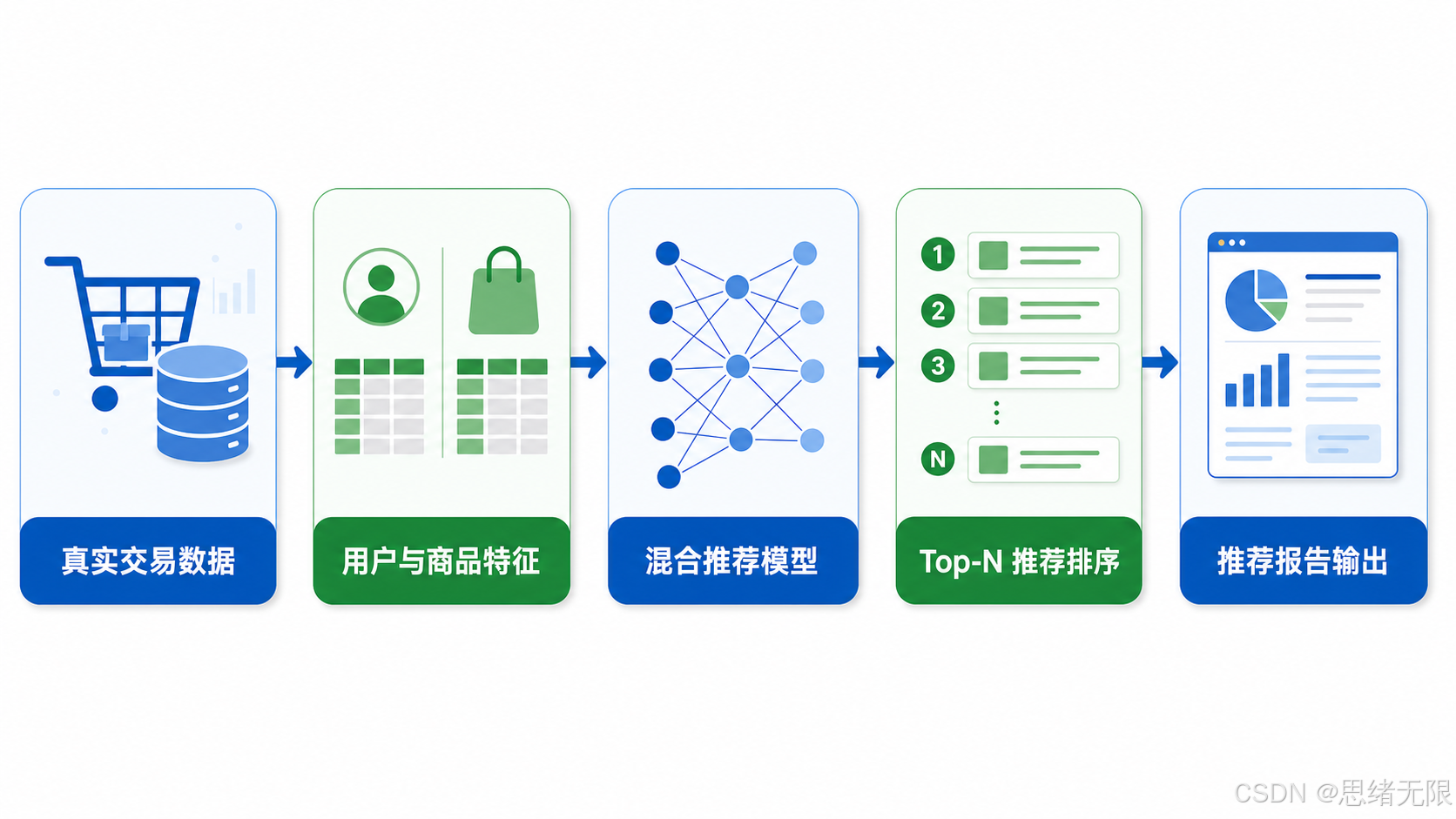
项目流程可以概括为:真实交易数据进入数据转换脚本,生成用户特征、商品特征和交互行为,再进入混合推荐模型,输出 Top-N 推荐列表和 HTML 报告。下面这张流程图根据本项目实际流程绘制,图中只保留中文模块标签,便于直接放进中文博客正文。
核心代码入口是 main.py。它会加载三张 CSV,调用 temporal_train_test_split 做时间切分,然后通过 build_recommender 选择推荐后端。若当前环境能导入 lightfm,--backend auto 会使用 LightFM;若不能导入,则自动使用 fallback 后端,避免读者在 Windows 编译环境上卡住。
python main.py --user CUS_14646 --top-k 8 --backend auto
LightFM 后端的思路是把用户 ID、用户画像、商品 ID、商品画像一起放入矩阵分解模型中。这样模型不仅学习“谁买过什么”,还学习“什么样的用户更偏好什么类商品”。对于真实电商数据,这种混合建模比单纯协同过滤更适合处理冷启动和长尾商品。
fallback 后端不是简单热门榜。它先用 TruncatedSVD 学习用户-商品矩阵中的协同信号,再用商品类目、品牌、价格带、标签计算内容相似度,最后融合少量热度分数:
final_score = 0.62 * collaborative_score
+ 0.33 * content_score
+ 0.05 * popularity_score
这套后端让项目在没有 LightFM 的机器上仍然能跑出真实推荐结果,同时保持“行为协同 + 商品内容”的混合推荐结构。
真实运行结果
本次运行命令为:
python main.py --user CUS_14646 --top-k 8 --backend auto
本次验证使用 fallback_svd_content 稳定后端。训练集包含 51296 条交互,测试集覆盖 180 个用户。程序生成了推荐 CSV、评估 JSON、模型文件、结果图和 HTML 报告。
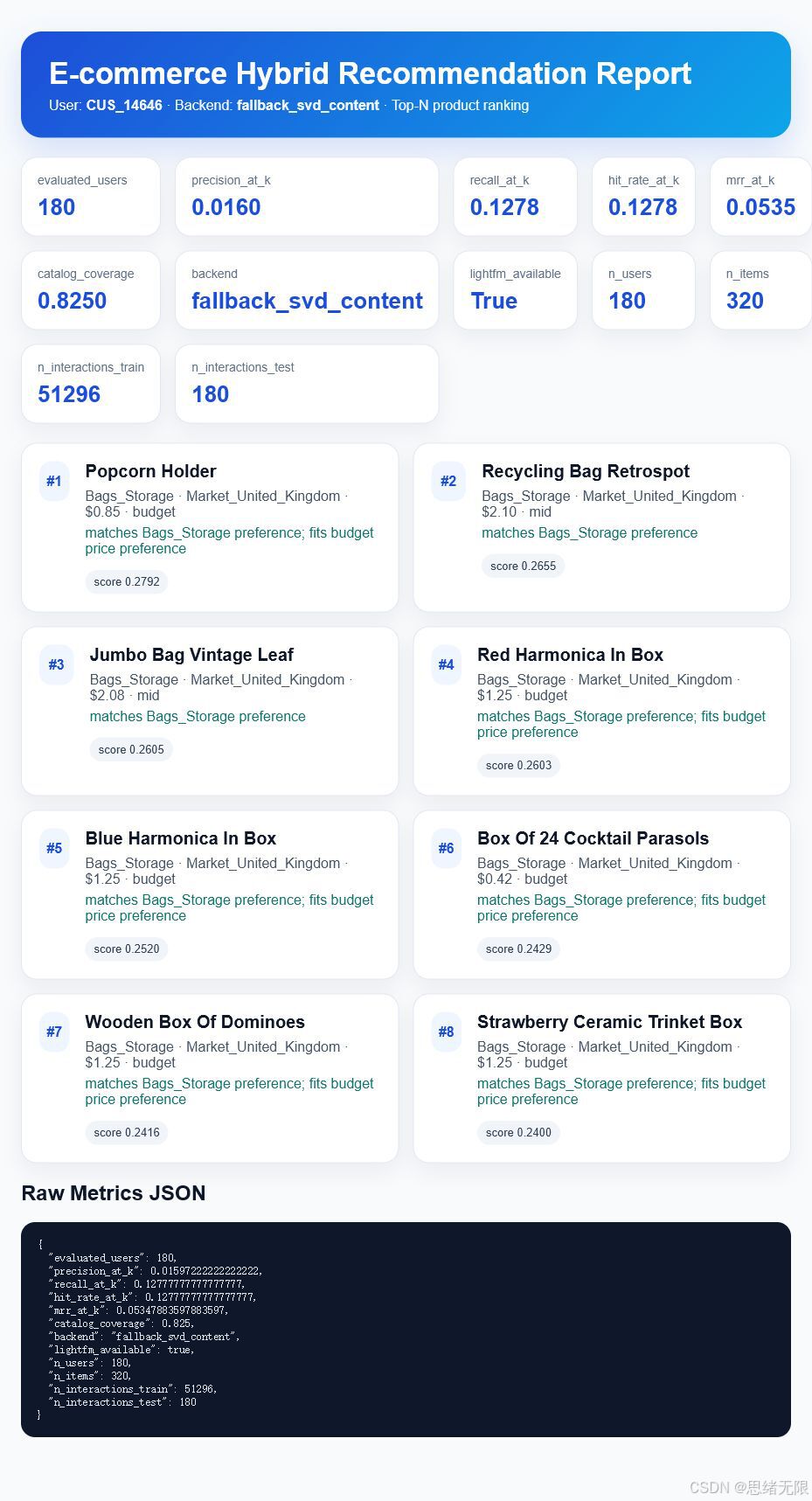
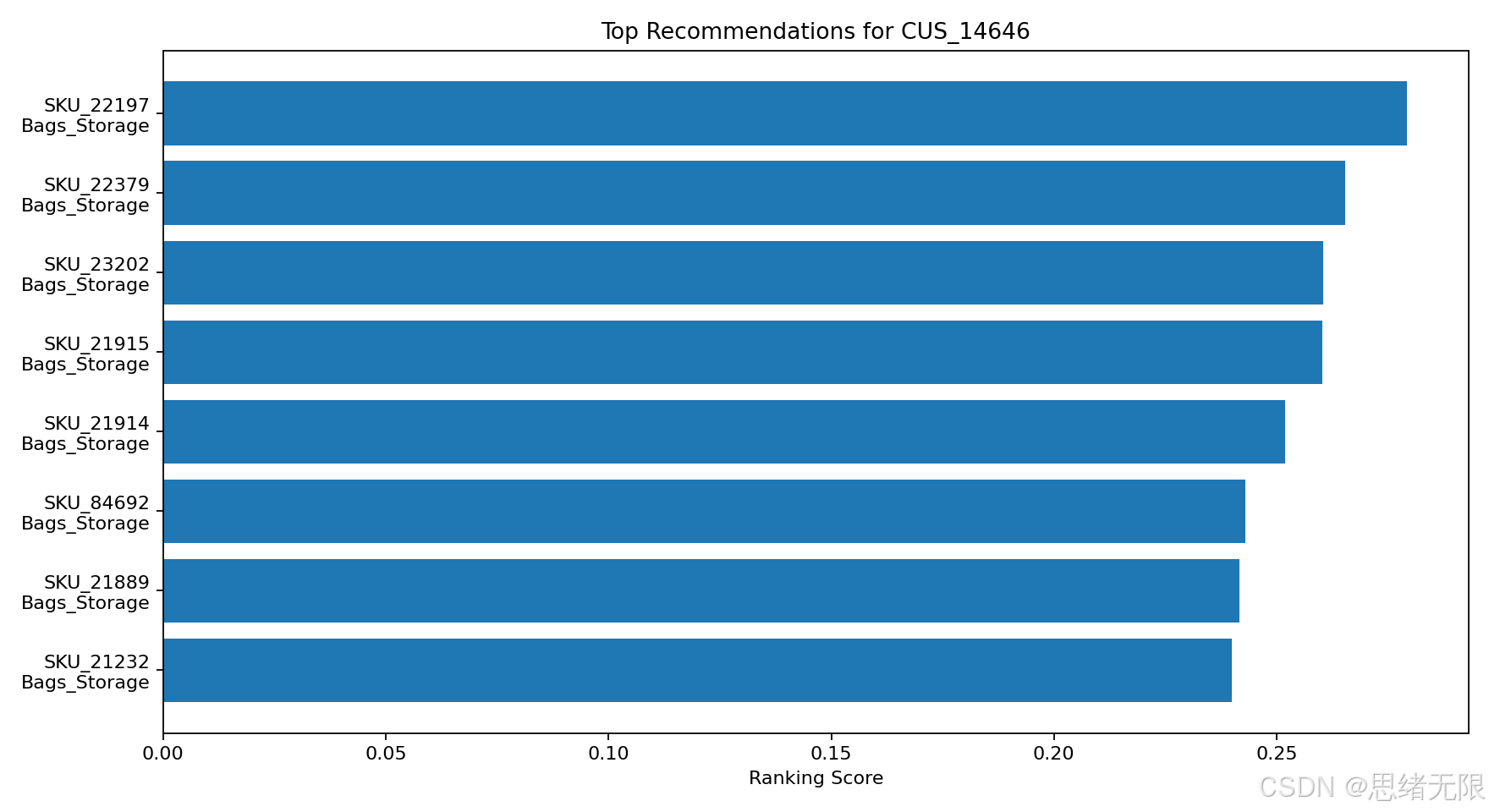
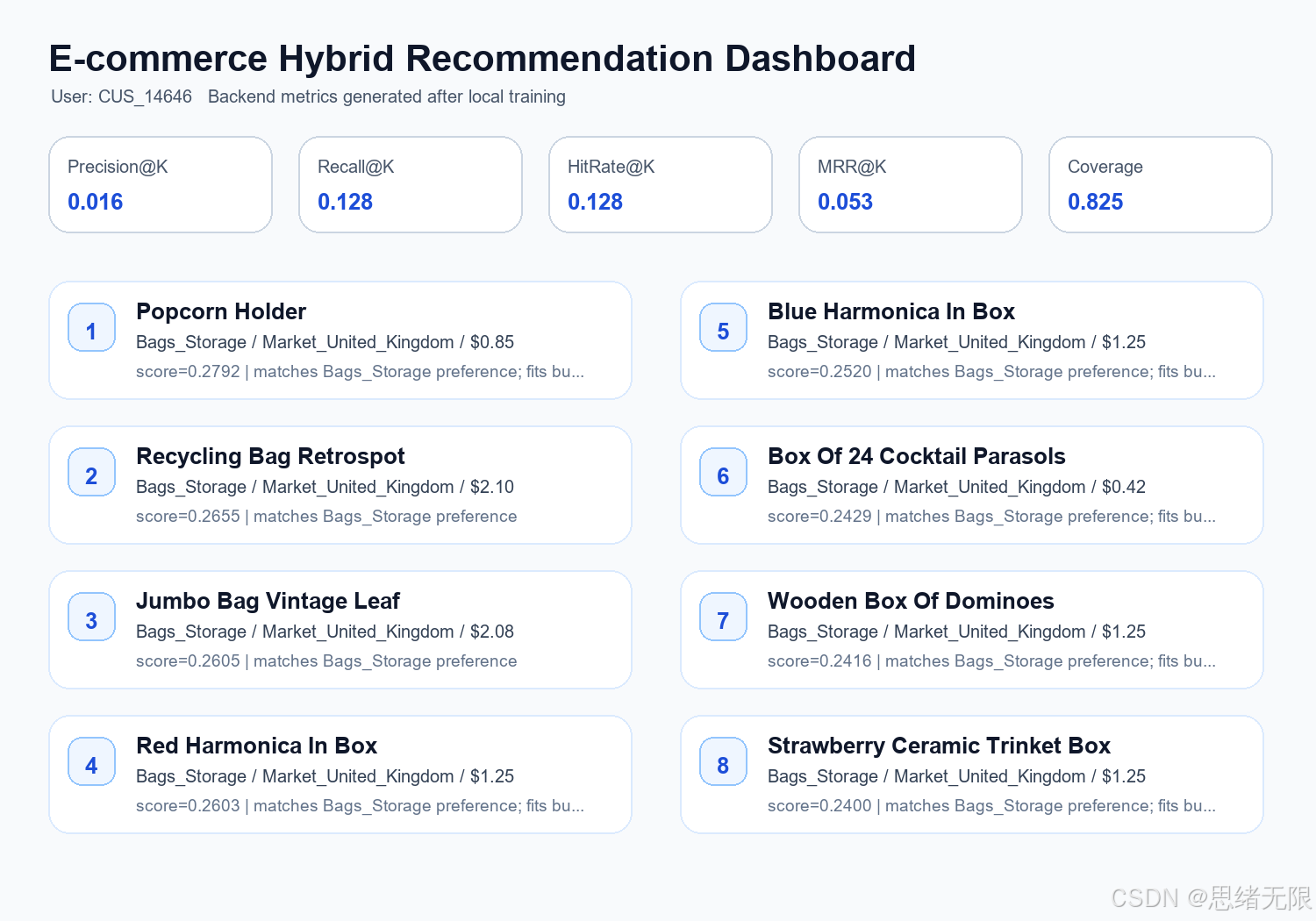
目标用户 CUS_14646 的 Top-8 推荐如下,商品名称和 SKU 来自 UCI Online Retail 的真实商品描述:
| item_id | title | category | price | price_bucket | score | reason |
|---|---|---|---|---|---|---|
| SKU_22197 | Popcorn Holder | Bags_Storage | 0.85 | budget | 0.2792 | matches Bags_Storage preference; fits budget price preference |
| SKU_22379 | Recycling Bag Retrospot | Bags_Storage | 2.10 | mid | 0.2655 | matches Bags_Storage preference |
| SKU_23202 | Jumbo Bag Vintage Leaf | Bags_Storage | 2.08 | mid | 0.2605 | matches Bags_Storage preference |
| SKU_21915 | Red Harmonica In Box | Bags_Storage | 1.25 | budget | 0.2603 | matches Bags_Storage preference; fits budget price preference |
| SKU_21914 | Blue Harmonica In Box | Bags_Storage | 1.25 | budget | 0.2520 | matches Bags_Storage preference; fits budget price preference |
| SKU_84692 | Box Of 24 Cocktail Parasols | Bags_Storage | 0.42 | budget | 0.2429 | matches Bags_Storage preference; fits budget price preference |
| SKU_21889 | Wooden Box Of Dominoes | Bags_Storage | 1.25 | budget | 0.2416 | matches Bags_Storage preference; fits budget price preference |
| SKU_21232 | Strawberry Ceramic Trinket Box | Bags_Storage | 1.25 | budget | 0.2400 | matches Bags_Storage preference; fits budget price preference |
推荐分数图能更直观看出排序差异。前几名都集中在 Bags_Storage,说明该用户历史行为中收纳袋盒类商品偏好很强,模型在过滤已购买商品后继续推荐相近 SKU。
评估指标来自时间切分测试:每个用户优先留出最近一次“首次购买”的商品作为测试目标,训练阶段只使用此时间点之前的历史记录,避免把已过滤商品作为不可命中的测试答案。本次结果如下:
| 指标 | 结果 | 含义 |
|---|---|---|
| Precision@8 | 0.0160 | Top-8 推荐中命中的平均比例 |
| Recall@8 / HitRate@8 | 0.1278 | 180 个用户中,有 12.78% 的留出商品进入 Top-8 |
| MRR@8 | 0.0535 | 命中商品越靠前,该值越高 |
| Catalog Coverage | 0.8250 | 推荐结果覆盖了 82.5% 的商品池 |
需要注意,UCI Online Retail 是交易数据,不是曝光日志,因此离线评估只能验证“历史购买倾向能否被召回”,不能等同于线上点击率或转化率。若用于真实业务,还需要曝光日志、负采样、A/B 测试和多目标重排。
源码结构与复现方法
资源包中的源码目录保持教学项目常见结构,重点文件如下:
lightfm_ecommerce_hybrid_recommender/
├── main.py
├── app.py
├── scripts/
│ └── prepare_uci_online_retail.py
├── src/
│ ├── data_generator.py
│ ├── features.py
│ ├── recommender.py
│ ├── evaluation.py
│ ├── visualization.py
│ └── report.py
├── demo_data/
│ ├── users.csv
│ ├── products.csv
│ ├── interactions.csv
│ └── source_summary.json
├── outputs/
├── images/
└── docs/
如果只想复现本文结果,直接安装最小依赖并运行主程序即可:
pip install -r requirements.txt
python main.py --user CUS_14646 --top-k 8 --backend auto
如果希望重新从 UCI 原始 zip 生成三张 CSV,可以运行:
python scripts/prepare_uci_online_retail.py ^
--source path/to/online+retail.zip ^
--out-dir demo_data ^
--top-users 180 ^
--top-items 320 ^
--min-user-events 8
如果当前 Python 版本和系统编译环境支持 LightFM,可以安装完整后端。Windows 环境建议先用 logistic 损失验证编译版 LightFM 是否稳定:
pip install -r requirements-lightfm.txt
python main.py --user CUS_14646 --top-k 8 --backend lightfm --loss logistic
运行后重点查看这些输出:
outputs/recommendations_CUS_14646.csv
outputs/evaluation_metrics.json
outputs/recommendation_report.html
images/results/report_browser_screenshot.png
images/results/real_data_overview.png
images/results/top_recommendations_user_CUS_14646.png
下面这张仪表盘图片也由项目代码生成,可作为报告或答辩材料中的结果总览。
项目扩展方向
这个项目已经完成“真实数据转换、混合推荐训练、指标评估、报告输出”的闭环。如果继续扩展,可以从三个方向入手。
第一,加入更细的行为权重。UCI 数据中主要是购买记录,如果换成真实平台日志,可以把曝光、点击、收藏、加购、购买、退款拆成不同权重,形成更细的隐式反馈强度。
第二,增加候选召回和重排。当前项目直接对商品池排序,适合教学规模;真实业务可先用协同过滤、内容相似、热门新品等多路召回,再用 LightFM 或学习排序模型重排。
第三,完善可解释推荐。现在的 reason 字段来自类目和价格带匹配,后续可以输出中文理由,例如“你近期购买过收纳袋盒类商品”“该商品价格带符合你的历史偏好”“相似客户近期也购买过该 SKU”。
总结
本项目实现了一个基于真实公开交易数据运行的 LightFM 思路电商混合推荐系统。博客包中的截图、指标图和推荐结果均由本地代码真实生成,资源包中也包含数据转换脚本、运行后的 CSV/JSON/HTML 报告和测试文件。对于课程设计、CSDN 项目实战或推荐系统入门来说,它的价值不只是“能跑”,而是展示了从真实交易明细到 Top-N 商品推荐的完整工程链路。
参考资料
- LightFM GitHub:https://github.com/lyst/lightfm
- LightFM Documentation:https://making.lyst.com/lightfm/docs/
- UCI Online Retail Dataset:https://archive.ics.uci.edu/dataset/352/online%2Bretail
- Wikimedia Commons 图片: https://commons.wikimedia.org/wiki/File:Laptops_in_store_20170514.jpg

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)