
Hive电商数据分析项目 过程记录Raw
注意这里sqoop数据迁移 连接的MySQL地址 要仔细比照,不要用老师原有的那个ip,否则就会出现连接被拒绝访问,出现同步半天hdfs那边什么都没有的情况。(一般实际情况下,数据存在MySQL数据库中,还是一般存在hive里面?,这是这里为了做项目被迫将数据从MySQL迁移到HDFS?
背景信息
技术选型:
选择星型模型而不是雪花模型
- 星型模型(Star Schema):
- 事实表在中间,维度表在周围。
- 特点:维度表是大宽表,不做规范化,把所有属性(包括子维度的属性)都冗余在一张表里。
- 例子:
dim_user表里直接包含user_id, name, city, province, country等等超级多维度的信息。
- 雪花模型(Snowflake Schema):
- 事实表在中间,维度表可以关联其他子维度表。
- 特点:维度表做了规范化(Normalization),将大维度拆分成小维度,减少数据冗余。
- 例子:
dim_user表只有user_id, name, city_id;dim_city表有city_id, city_name, province_id;dim_province表有province_id, province_name。查询时需要user -> city -> province多层关联。
这里数据量没有那么大,受得了这样的冗余,为了后面SQL减少JOIN连接的麻烦,暂时保留使用星型模型
结合你的场景(电商数仓)
在你现在的电商项目中,老师让你用「星型模型」是完全正确的,因为:
- 分析需求简单:你主要是统计销量、金额、好评数,这些都是简单的聚合。
- 查询性能优先:星型模型 JOIN 少,查询速度快,适合跑报表。
- 数据冗余可接受:Hadoop/HDFS 存储便宜,冗余一点数据(比如把省份名存在订单表里)完全没问题,换来的是查询速度的提升
但是,如果你遇到以下情况,就需要向老师提出用雪花模型:
- 用户表太大:如果用户有 10 亿,且包含很多详细的画像标签,为了省空间,你可以把
dim_user拆成dim_user_base(基础信息)和dim_user_profile(画像信息)。 - 商品分类层级深:如果分类有 5 级(类目 1 - 类目 2 - 类目 3-...),虽然星型模型通常把所有层级都冗余在事实表里(方便统计各个层级),但如果你需要专门分析分类树结构,可能需要雪花模型。
二、 什么场景下【必须】用雪花模型?(3 种情况)
虽然星型模型查询快,但在以下 3 种场景下,雪花模型是唯一解或最优解:
1. 维度表的数据量【极度庞大】,且存在大量重复数据(为了节省存储空间)
这是最常见的理由。如果维度表非常大(比如上亿行),且某些属性重复率极高,星型模型的冗余存储成本会高到无法接受。
-
场景举例:
- 你有一张
dim_sku(商品维度表),有 10 亿行数据。 - 商品都有品牌(Brand),但品牌只有 1000 个。
- 星型模型:在 10 亿行里都存一遍品牌名称(比如 "Apple"),浪费巨大存储空间。
- 雪花模型:把品牌拆成
dim_brand(1000 行),dim_sku里只存brand_id(整数)。存储空间瞬间节省几十倍。
- 你有一张
-
结论:当维度表巨大且属性重复率极高,导致存储成本过高时,必须用雪花模型拆分。
2. 维度属性的【更新频率】不同(为了避免全表重刷)
在星型模型中,如果维度表的一个属性变了(比如商品的价格变了,或者用户的等级变了),通常需要重写整个分区或整个维度表,这在大数据中代价很大。
-
场景举例:
dim_user表有 1 亿用户。- 静态属性:性别、出生日期(几乎不怎么变)。
- 动态属性:会员等级(黄金 / 铂金,每天都在变)。
- 星型模型:如果会员等级每天更新,你需要每天重写这 1 亿行数据的维度表,IO 压力巨大。
- 雪花模型:把动态属性拆成
dim_user_status小表。每天只需要更新dim_user_status里变化的几千行数据,主表dim_user不动。
-
结论:当维度表中存在高频更新的属性,且与低频属性混合时,必须用雪花模型拆分,以减少维护成本。
3. 多值维度(一对多关系)
这是星型模型无法处理的场景。如果一个事实表的行对应维度表的多个值,星型模型会导致事实表爆炸(一行变多行),而雪花模型可以优雅处理。
-
场景举例:
- 一篇文章(Fact)可以有多个标签(Tag)。
- 星型模型:事实表一行文章,维度表怎么存?存
tag1, tag2, tag3?扩展性差。或者事实表复制成 3 行?导致事实表数据膨胀。 - 雪花模型:建立
fact_article(文章事实),dim_article_tag(文章 - 标签映射表),dim_tag(标签维度)。通过fact -> mapping -> tag关联查询。
-
结论:处理多值维度(一个事实对应多个维度值)时,必须使用雪花模型的结构(桥接表)。
终极总结(一句话记住)
- 星型模型:大宽表,反规范化,JOIN 少,查询快,适合 90% 的报表统计场景。(老师要求的)
- 雪花模型:规范化,JOIN 多(查询慢),节省空间,适合维度巨大、属性更新频繁、多值维度的场景。
1.构建ODS层数据
Step 1将数据从MySQL迁移到HDFS
【问:】数据来源是什么?
来自己公司的mysql备份。数据中台,数据湖,华为云 阿里云里面取数据。
mysql_to_hdfs.sh
注意:这里sqoop数据迁移 连接的MySQL地址 要仔细比照,不要用老师原有的那个ip,否则就会出现连接被拒绝访问,出现同步半天hdfs那边什么都没有的情况。要用集群主机的那个ip
为了用户下单访问快,数据存在MySQL数据库上。数据分析的时候,需要把今天和过去非常多天的数据放在一起 所以数据量大 需要放在Hadoop的hive上分析。所以需要把数据从MySQL上迁移到HDFS上。
#! /bin/bash
sqoop=/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/bin/sqoop
# `` 反引号包裹的内容,代表「执行 Linux 命令,并把命令的执行结果赋值给变量」;
# date -d '-1 day' +%F:Linux 的日期命令,含义是 获取「昨天」的日期,格式是 年-月-日(比如 2025-12-30);
# -d '-1 day' :往前推 1 天;如果写+1 day就是往后推 1 天;
# +%F :日期格式化,固定输出 yyyy-MM-dd 格式
do_date=`date -d '-1 day' +%F`
# 如果你写了第二个参数(你指定了日期),就把第二个参数赋值给do_date
# 如果没写第二个参数(你没指定日期),第二个参数就还是取上面定义的昨天的日期
if [[ -n "$2" ]]; then
do_date=$2
fi
# 与python不同,bash中定义函数不需要事先说明函数有几个参数,参数的名字是什么
import_data(){
$sqoop import \
--connect jdbc:mysql://192.168.10.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /origin_data/duoduo_db/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t'
}
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from coupon_use
where (date_format(get_time,'%Y-%m-%d')='$do_date'
or date_format(using_time,'%Y-%m-%d')='$do_date'
or date_format(used_time,'%Y-%m-%d')='$do_date')"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,'%Y-%m-%d')='$do_date'"
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_user_info(){
import_data "user_info" "select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"
}
import_order_detail(){
import_data order_detail "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
od.create_time
from order_detail od
join order_info oi
on od.order_id=oi.id
where DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from comment_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from order_refund_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
tm_id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_province
import_base_region
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
esac
echo "数据同步完成。"Step2 创立ODS层表
#!/bin/bash
hive=/bigdata/apache-hive-2.3.3-bin/bin/hive
sql="
drop database if exists duoduo_db cascade;
create database duoduo_db;
use duoduo_db;
drop table if exists ods_order_info;
create external table ods_order_info(
id string COMMENT '订单号',
final_total_amount decimal(10,2) COMMENT '订单金额',
order_status string COMMENT '订单状态',
user_id string COMMENT '用户id',
out_trade_no string COMMENT '支付流水号',
create_time string COMMENT '创建时间',
operate_time string COMMENT '操作时间',
province_id string COMMENT '省份ID',
benefit_reduce_amount decimal(10,2) COMMENT '优惠金额',
original_total_amount decimal(10,2) COMMENT '原价金额',
feight_fee decimal(10,2) COMMENT '运费'
) COMMENT '订单表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_order_info/';
drop table if exists ods_order_detail;
create external table ods_order_detail(
id string COMMENT '订单编号',
order_id string COMMENT '订单号',
user_id string COMMENT '用户id',
sku_id string COMMENT '商品id',
sku_name string COMMENT '商品名称',
order_price decimal(10,2) COMMENT '商品价格',
sku_num bigint COMMENT '商品数量',
create_time string COMMENT '创建时间'
) COMMENT '订单详情表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_order_detail/';
drop table if exists ods_sku_info;
create external table ods_sku_info(
id string COMMENT 'skuId',
spu_id string COMMENT 'spuid',
price decimal(10,2) COMMENT '价格',
sku_name string COMMENT '商品名称',
sku_desc string COMMENT '商品描述',
weight string COMMENT '重量',
tm_id string COMMENT '品牌id',
category3_id string COMMENT '品类id',
create_time string COMMENT '创建时间'
) COMMENT 'SKU商品表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_sku_info/';
drop table if exists ods_user_info;
create external table ods_user_info(
id string COMMENT '用户id',
name string COMMENT '姓名',
birthday string COMMENT '生日',
gender string COMMENT '性别',
email string COMMENT '邮箱',
user_level string COMMENT '用户等级',
create_time string COMMENT '创建时间',
operate_time string COMMENT '操作时间'
) COMMENT '用户表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_user_info/';
drop table if exists ods_base_category1;
create external table ods_base_category1(
id string COMMENT 'id',
name string COMMENT '名称'
) COMMENT '商品一级分类表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_category1/';
drop table if exists ods_base_category2;
create table ods_base_category2(
id string COMMENT 'id',
name string COMMENT '名称',
category1_id string COMMENT '一级品类id'
) COMMENT '商品二级分类表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/base_category2/';
drop table if exists ods_base_category3;
create external table ods_base_category3(
id string COMMENT ' id',
name string COMMENT '名称',
category2_id string COMMENT '二级品类id'
) COMMENT '商品三级分类表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_category3/';
drop table if exists ods_payment_info;
create external table ods_payment_info(
id bigint COMMENT '编号',
out_trade_no string COMMENT '对外业务编号',
order_id string COMMENT '订单编号',
user_id string COMMENT '用户编号',
alipay_trade_no string COMMENT '支付宝交易流水编号',
total_amount decimal(16,2) COMMENT '支付金额',
subject string COMMENT '交易内容',
payment_type string COMMENT '支付类型',
payment_time string COMMENT '支付时间'
) COMMENT '支付流水表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_payment_info/';
drop table if exists ods_base_province;
create external table ods_base_province (
id bigint COMMENT '编号',
name string COMMENT '省份名称',
region_id string COMMENT '地区ID',
area_code string COMMENT '地区编码',
iso_code string COMMENT 'iso编码'
) COMMENT '省份表'
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_province/';
drop table if exists ods_base_region;
create external table ods_base_region (
id bigint COMMENT '编号',
region_name string COMMENT '地区名称'
) COMMENT '地区表'
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_region/';
drop table if exists ods_base_trademark;
create external table ods_base_trademark (
tm_id bigint COMMENT '编号',
tm_name string COMMENT '品牌名称'
) COMMENT '品牌表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_trademark/';
drop table if exists ods_order_status_log;
create external table ods_order_status_log (
id bigint COMMENT '编号',
order_id string COMMENT '订单ID',
order_status string COMMENT '订单状态',
operate_time string COMMENT '修改时间'
) COMMENT '订单状态表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_order_status_log/';
drop table if exists ods_spu_info;
create external table ods_spu_info(
id string COMMENT 'spuid',
spu_name string COMMENT 'spu名称',
category3_id string COMMENT '品类id',
tm_id string COMMENT '品牌id'
) COMMENT 'SPU商品表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_spu_info/';
drop table if exists ods_comment_info;
create external table ods_comment_info(
id string COMMENT '编号',
user_id string COMMENT '用户ID',
sku_id string COMMENT '商品sku',
spu_id string COMMENT '商品spu',
order_id string COMMENT '订单ID',
appraise string COMMENT '评价',
create_time string COMMENT '评价时间'
) COMMENT '商品评论表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_comment_info/';
drop table if exists ods_order_refund_info;
create external table ods_order_refund_info(
id string COMMENT '编号',
user_id string COMMENT '用户ID',
order_id string COMMENT '订单ID',
sku_id string COMMENT '商品ID',
refund_type string COMMENT '退款类型',
refund_num bigint COMMENT '退款件数',
refund_amount decimal(16,2) COMMENT '退款金额',
refund_reason_type string COMMENT '退款原因类型',
create_time string COMMENT '退款时间'
) COMMENT '退单表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_order_refund_info/';
drop table if exists ods_cart_info;
create external table ods_cart_info(
id string COMMENT '编号',
user_id string COMMENT '用户id',
sku_id string COMMENT 'skuid',
cart_price string COMMENT '放入购物车时价格',
sku_num string COMMENT '数量',
sku_name string COMMENT 'sku名称 (冗余)',
create_time string COMMENT '创建时间',
operate_time string COMMENT '修改时间',
is_ordered string COMMENT '是否已经下单',
order_time string COMMENT '下单时间'
) COMMENT '加购表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_cart_info/';
drop table if exists ods_favor_info;
create external table ods_favor_info(
id string COMMENT '编号',
user_id string COMMENT '用户id',
sku_id string COMMENT 'skuid',
spu_id string COMMENT 'spuid',
is_cancel string COMMENT '是否取消',
create_time string COMMENT '收藏时间',
cancel_time string COMMENT '取消时间'
) COMMENT '商品收藏表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_favor_info/';
drop table if exists ods_coupon_use;
create external table ods_coupon_use(
id string COMMENT '编号',
coupon_id string COMMENT '优惠券ID',
user_id string COMMENT 'skuid',
order_id string COMMENT 'spuid',
coupon_status string COMMENT '优惠券状态',
get_time string COMMENT '领取时间',
using_time string COMMENT '使用时间(下单)',
used_time string COMMENT '使用时间(支付)'
) COMMENT '优惠券领用表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_coupon_use/';
drop table if exists ods_coupon_info;
create external table ods_coupon_info(
id string COMMENT '购物券编号',
coupon_name string COMMENT '购物券名称',
coupon_type string COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
condition_amount string COMMENT '满额数',
condition_num string COMMENT '满件数',
activity_id string COMMENT '活动编号',
benefit_amount string COMMENT '减金额',
benefit_discount string COMMENT '折扣',
create_time string COMMENT '创建时间',
range_type string COMMENT '范围类型 1、商品 2、品类 3、品牌',
spu_id string COMMENT '商品id',
tm_id string COMMENT '品牌id',
category3_id string COMMENT '品类id',
limit_num string COMMENT '最多领用次数',
operate_time string COMMENT '修改时间',
expire_time string COMMENT '过期时间'
) COMMENT '优惠券表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_coupon_info/';
drop table if exists ods_activity_info;
create external table ods_activity_info(
id string COMMENT '编号',
activity_name string COMMENT '活动名称',
activity_type string COMMENT '活动类型',
start_time string COMMENT '开始时间',
end_time string COMMENT '结束时间',
create_time string COMMENT '创建时间'
) COMMENT '活动表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_activity_info/';
drop table if exists ods_activity_order;
create external table ods_activity_order(
id string COMMENT '编号',
activity_id string COMMENT '优惠券ID',
order_id string COMMENT 'skuid',
create_time string COMMENT '领取时间'
) COMMENT '活动订单关联表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_activity_order/';
drop table if exists ods_activity_rule;
create external table ods_activity_rule(
id string COMMENT '编号',
activity_id string COMMENT '活动ID',
condition_amount string COMMENT '满减金额',
condition_num string COMMENT '满减件数',
benefit_amount string COMMENT '优惠金额',
benefit_discount string COMMENT '优惠折扣',
benefit_level string COMMENT '优惠级别'
) COMMENT '优惠规则表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_activity_rule/';
drop table if exists ods_base_dic;
create external table ods_base_dic(
dic_code string COMMENT '编号',
dic_name string COMMENT '编码名称',
parent_code string COMMENT '父编码',
create_time string COMMENT '创建日期',
operate_time string COMMENT '操作日期'
) COMMENT '编码字典表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_base_dic/';
"
hive -e "$sql"
echo "建库建表完成。"
ODS层所有的建表SQL语句都会在结尾加一句”location '/origin_data/duoduo_db/ods/ods_order_info/'; “ 这句话指定Hive上存储的数据会被存在hdfs上哪个位置。
Step3 HDFS数据加载进ODS层的Hive数据库
#!/bin/bash
APP=duoduo_db
hive=/bigdata/apache-hive-2.3.3-bin/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [[ -n "$2" ]]; then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
# inpath写hdfs上被加载的数据文件的地址
# OVERWRITE into的表 写存储进去hive表的名字
# partition写分区
# 关于partition有下面这几个疑问:
# 【???疑问???】do_date这个日期是本来就有的一列,按照这列进行分组,还是你人为的添加了一列,
# 填入当天的日期,就能把MySQL中属于当天的数据集就加载进来?
# ods_base_province, ods_base_region这两个不随着日期变化的,就不做这个partition
#
sql1="
load data
inpath '/origin_data/$APP/db/order_info/$do_date'
OVERWRITE into table ${APP}.ods_order_info
partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table ${APP}.ods_sku_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table ${APP}.ods_user_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table ${APP}.ods_payment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table ${APP}.ods_base_category1 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table ${APP}.ods_base_category2 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table ${APP}.ods_base_category3 partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_trademark/$do_date' OVERWRITE into table ${APP}.ods_base_trademark partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_info/$do_date' OVERWRITE into table ${APP}.ods_activity_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_order/$do_date' OVERWRITE into table ${APP}.ods_activity_order partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/cart_info/$do_date' OVERWRITE into table ${APP}.ods_cart_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/comment_info/$do_date' OVERWRITE into table ${APP}.ods_comment_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/coupon_info/$do_date' OVERWRITE into table ${APP}.ods_coupon_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/coupon_use/$do_date' OVERWRITE into table ${APP}.ods_coupon_use partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/favor_info/$do_date' OVERWRITE into table ${APP}.ods_favor_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_refund_info/$do_date' OVERWRITE into table ${APP}.ods_order_refund_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/order_status_log/$do_date' OVERWRITE into table ${APP}.ods_order_status_log partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/spu_info/$do_date' OVERWRITE into table ${APP}.ods_spu_info partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/activity_rule/$do_date' OVERWRITE into table ${APP}.ods_activity_rule partition(dt='$do_date');
load data inpath '/origin_data/$APP/db/base_dic/$do_date' OVERWRITE into table ${APP}.ods_base_dic partition(dt='$do_date');
"
sql2="
load data inpath '/origin_data/$APP/db/base_province/$do_date' OVERWRITE into table ${APP}.ods_base_province;
load data inpath '/origin_data/$APP/db/base_region/$do_date' OVERWRITE into table ${APP}.ods_base_region;
"
case $1 in
"first"){
$hive -e "$sql1"
$hive -e "$sql2"
};;
"all"){
$hive -e "$sql1"
};;
esac
echo "数据加载完成。"【问1】:请问这句hive数据加载hdfs上数据到hive的代码会把数据文件从'/origin_data/$APP/db/order_detail/$do_date' 剪切到'/origin_data/$APP/ods/order_detail/$do_date'去?是剪切还是复制?剪切到到哪个位置,如何设定?
1. 你的 SQL 执行后,一定会发生「剪切」
执行这句命令后,HDFS 上 /origin_data/$APP/db/order_detail/$do_date 目录下的所有数据文件,会被彻底剪切(move) 到 Hive 表 ${APP}.ods_order_detail 对应分区 dt='$do_date' 的 HDFS 存储目录下,原目录的数据文件会被清空。
为什么是「剪切」不是「复制」?【关键核心原理】
原因:HDFS 是分布式文件系统,文件在集群内移动的「IO 成本极低」(本质只是修改 NameNode 的元数据,DataNode 的真实数据块不用动),Hive 设计时为了节省集群存储、避免重复数据,对 HDFS 内的 load 操作默认用「剪切」,这是 Hive 的最优设计。
数据文件被「剪切到哪里」?由谁决定?【核心规则】
✅ 数据最终存储路径 = Hive 表的「存储位置」 + "分区字段 = 分区值"
问:数据存入ODS层Hive数据库,那请问数据文件存在HDFS的什么位置?
答:
ODS层所有的建表语句都会在结尾加一句”location '/origin_data/duoduo_db/ods/ods_order_info/'; “ 这句话指定Hive上存储的数据会被存在hdfs上哪个位置。
也就是'/origin_data/duoduo_db/ods/ods_表名/';
create external table ods_order_info(
id string COMMENT '订单号',
final_total_amount decimal(10,2) COMMENT '订单金额',
order_status string COMMENT '订单状态',
user_id string COMMENT '用户id',
out_trade_no string COMMENT '支付流水号',
create_time string COMMENT '创建时间',
operate_time string COMMENT '操作时间',
province_id string COMMENT '省份ID',
benefit_reduce_amount decimal(10,2) COMMENT '优惠金额',
original_total_amount decimal(10,2) COMMENT '原价金额',
feight_fee decimal(10,2) COMMENT '运费'
) COMMENT '订单表'
PARTITIONED BY (dt string)
row format delimited fields terminated by '\t'
location '/origin_data/duoduo_db/ods/ods_order_info/';Hive 的分区表有固定的分区目录命名规范:分区字段名=分区值,这是 Hive 的元数据约定,不可修改。你的表是按 dt 分区,分区值是 $do_date,所以分区目录就是 dt=$do_date。
【问2】:为什么你这里加载数据的时候选择用overwrite覆盖写入,而不是使用 没有overwrite的追加写入?
load data inpath
'/origin_data/$APP/db/order_info/$do_date'
OVERWRITE into
table ${APP}.ods_order_info
partition(dt='$do_date');答:
你的场景是 ODS 层(数仓贴源层)加载订单明细,用 OVERWRITE 是行业标准写法,因为 ODS 层一般按天全量同步,当天的数据需要覆盖当天的分区,避免重复数据。下一天的数据又写在新的dt分区里,不会干扰前面日期的数据。
【问】:
数据导入后代码,没有报错,是不是意味着数据导入就成功了?没有错误?所以要如何检查数据是否出错了?
LOAD DATA 只做「文件移动」,不做「数据校验」
Hive 的 LOAD DATA 是一个纯文件级别的操作,它只会把文件剪切 / 复制到表的存储目录,不会校验文件的内容和表的字段是否匹配!
- 比如:你的表定义了 3 个字段,但数据文件里有 5 列,LOAD 操作依然成功;
- 比如:数据文件是乱码、格式错误,LOAD 操作也依然成功;
- 只有当你执行
select * from ods_order_detail where dt='$do_date'查询时,才会发现数据解析异常。
2.加工ODS层数据,形成DWD层数据

2.1 数据清洗
数据清洗:手机号乱填的移除,地址全是空格的移除
2.2 常用的表合并 构建DWD为层
领导派发下来10个指标让我们计算。我们写SQL可以算出来。但是计算的过程中要拼接好几张表才能算出一个指标,这个拼接表格的过程是挺花时间也易出错的。为了避免重复拼接表格,我们直接把经常拼接在一起这些列全部拼好,方便你后面直接调用。这个拼接表格的过程就称之为”加工ODS层数据,形成DWD层数据“。
拼接合并后表格的命名:dwd开头,维度用dim、事实用fact,
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区 维表的特征:
-
维表的范围很宽(具有多个属性、列比较多)
-
跟事实表相比,行数相对较小:通常< 10万条
-
内容相对固定:编码表
事实表:中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、件数、金额等),例如,订单事件中的下单金额。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
事实表的特征:
-
非常的大
-
内容相对的窄:列数较少
-
经常发生变化,每天会新增加很多。
拼接合并后表格的命名:dwd_fact_order_info
#指标 7:统计 90 天内所有支付金额前 10 名的用户!
SELECT u.name, SUM(p.total_amount) money
FROM ods_user_info u
INNER JOIN ods_payment_info p
ON p.user_id = u.id
GROUP BY u.name
ORDER BY money
DESC LIMIT 10;这里老师的答案关于用户的定义是不够准确的。因为用户名有可能重复,id不会重复。为了能够同时看到用户名和id,用concat把用户名和id做拼接,然后再group by
【遇到的没发现的错误】:用户名重复了,同一个用户累计的金额特别高,类似XXX(问豆包)的网名特别多,结果发现是错误。
2.3 补充
这个项目采取星型模型:各种模型介绍一下,说出自己为什么采用星型模型
从关系型建模到维度建模
在完成下面这两个指标计算的时候,有可能写出下面这样的代码。这是关系建模,而不是维度建模。而DWD层,老师推荐维度建模。
#指标3:统计所有商品信息销量前10名分类!
#指标4:统计所有商品信息销量前10名品牌!

✔️ 关系型建模 → 对应 OLTP 数据库(MySQL/Oracle) → 你的写法就是这个
✔️ 事务性建模 → 对应 OLAP 数仓(Hive/ClickHouse) → 老师要求你写的是这个
你说的「事务性建模」,行业标准叫法是 【主题域建模 / 事实维度建模】
3. 关系型建模(OLTP 建模,你写的就是这个)
- 核心思想:基于「业务表的关联关系」建模,所有表都是「业务原始表」,表和表之间靠主键 / 外键关联(比如订单表的 sku_id 关联商品表的 id);
- 设计原则:第三范式 (3NF) → 尽量减少数据冗余,一张表只存一类业务数据(比如订单表只存订单信息,商品表只存商品信息);
- 你的 SQL 体现:
from order_detail d, sku_info s, base_trademark b三张业务原始表直接关联,就是典型的关系型建模思维。
4. 事务性建模(OLAP 建模,老师要求的,数仓核心思想)
- 核心思想:基于「业务分析主题」建模,不是基于表的关联关系!所有表被抽象成 【事实表】+【维度表】 两类,所有分析 SQL 都围绕「事实 + 维度」展开;
- 设计原则:反范式、数据冗余、主题域聚合 → 允许数据重复,目的是让分析 SQL 更简单、查询速度更快,这是和关系型建模的本质对立;
- 核心关键词:事实表(比如订单事实、退款事实)、维度表(比如省份维度、品牌维度、时间维度)、宽表、主题域,这是你 SQL 里完全没有的!
OLTP和OLAP的区别:
OLTP 里的业务表是「全量数据」,但 OLAP 里的分析永远是有时间范围的!而且 Hive 的表都是 按时间分区(dt) 的,你必须在 WHERE 里加上 dt >= '2025-01-01' and dt <= '2025-03-31' 这种时间筛选,否则会扫描全量数据,查询效率为 0。
关于上面这个话题,我没研究完,prompt如下,可以继续问豆包,补充完这个主题
SELECT b.'tm id`, SUM(d.`sku num’) total FROM order detail d, sku info s, base trademark bWHERE d.'sku id’= s.id AND s.'tm id'=b.tm id GROUP BY b.'tm id') t1 LEFT JOIN(SELECT b.'tm id', SUM(r.'refund num') nums FROM sku info s, order refund info r , base trademark bWHERE s.id =r.'sku id’AND b.'tm id'= s.'tm id` GROUP BY b.tm id)t2 ONt1.tm id = t2.tm id )t3 WHERE ctm id = t3.tm id ORDER BY t3.sales nums DESC LIMIT 10: #指标5:统计90天内所有下单金额前10名的省市!SELECT p.`name’, SUM(o.'final total amount') total FROM order info o, order detail d, base province pWHERE o.`province id’ = p.'id, AND o.id = d. order id’ GROUP BY p.'name’ ORDER BY total DESC, 我写了这两句SQL,老师说我这是关系型建模,不是事务性建模。我请问关系型建模应该就是OLTP吧?事务性建模应该是OLAP吧?开始OLTP的典型数据库MySQL的语法和OLAP的典型数据库Hive区别很小啊!凭什么老师说我这是关系型建模,不是事务性建模?
2.4 将SKU常用的11个指标拼接在一张表上
要求将数据计算出下面这11个指标
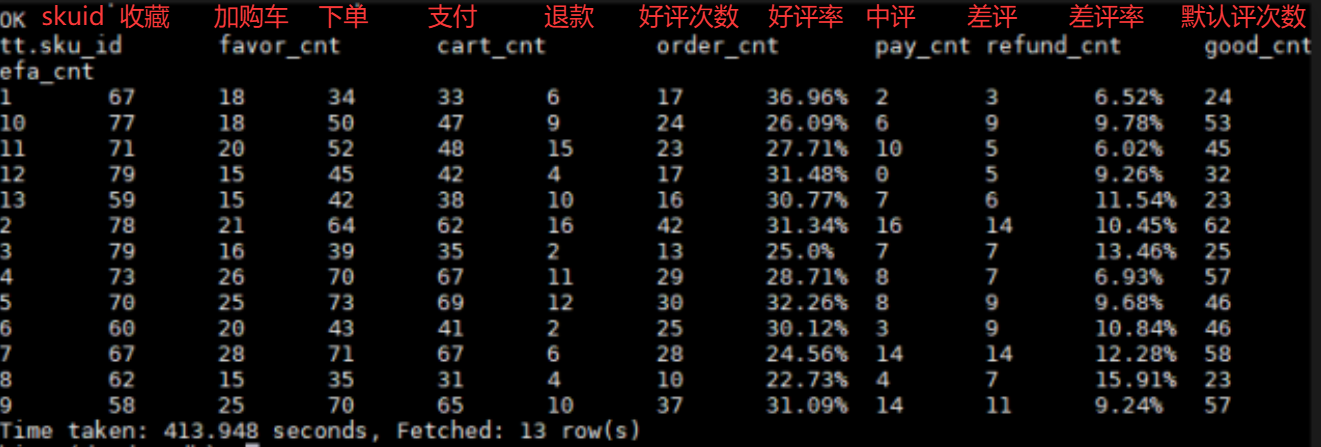
老师的答案,最优的版本
SELECT
tt.sku_id,
SUM(tt.favor_cnt) favor_cnt,
SUM(tt.cart_cnt) cart_cnt,
SUM(tt.order_cnt) order_cnt,
SUM(tt.pay_cnt) pay_cnt,
SUM(tt.refund_cnt) refund_cnt,
SUM(tt.good_cnt) good_cnt,
CONCAT(ROUND(100 * SUM(tt.good_cnt)/(SUM(tt.good_cnt)+ SUM(tt.midd_cnt)+ SUM(tt.bad_cnt)+ SUM(tt.defa_cnt)) , 2), '%') good_rate,
SUM(tt.midd_cnt) midd_cnt,
SUM(tt.bad_cnt) bad_cnt,
CONCAT(ROUND(100 * SUM(tt.bad_cnt)/(SUM(tt.good_cnt)+ SUM(tt.midd_cnt)+ SUM(tt.bad_cnt)+ SUM(tt.defa_cnt)) , 2), '%') bad_rate,
SUM(tt.defa_cnt) defa_cnt
FROM
(
-- 按照sku_id聚合出收藏的数量,然后新增其他你本来应该算的指标作为列 列的值填写0
-- 然后所有的表格纵向拼接。然后id相同的,加在一起吗?
SELECT
f.`sku_id`,
COUNT(*) favor_cnt,
0 cart_cnt,
0 order_cnt,
0 pay_cnt,
0 refund_cnt,
0 good_cnt,
0 midd_cnt,
0 bad_cnt,
0 defa_cnt
FROM
ods_favor_info f
WHERE
DATE_FORMAT( f.create_time, 'yyyy-MM-dd')= '2025-08-11'
GROUP BY
f.`sku_id`
UNION ALL
SELECT
f1.`sku_id`,
0 favor_cnt,
COUNT(*) cart_cnt,
0 order_cnt,
0 pay_cnt,
0 refund_cnt,
0 good_cnt,
0 midd_cnt,
0 bad_cnt,
0 defa_cnt
FROM
ods_cart_info f1
WHERE
DATE_FORMAT( f1.create_time, 'yyyy-MM-dd')= '2025-08-11'
GROUP BY
f1.`sku_id`
UNION ALL
SELECT
f2.`sku_id`,
0 favor_cnt,
0 cart_cnt,
COUNT(*) order_cnt,
0 pay_cnt,
0 refund_cnt,
0 good_cnt,
0 midd_cnt,
0 bad_cnt,
0 defa_cnt
FROM
ods_order_detail f2
WHERE
DATE_FORMAT( f2.create_time, 'yyyy-MM-dd')= '2025-08-11'
GROUP BY
f2.`sku_id`
UNION ALL
SELECT
a.`sku_id`,
0 favor_cnt,
0 cart_cnt,
0 order_cnt,
COUNT(*) pay_cnt,
0 refund_cnt,
0 good_cnt,
0 midd_cnt,
0 bad_cnt,
0 defa_cnt
FROM
ods_payment_info f3
INNER JOIN ods_order_info d ON
f3.`order_id` = d.id
INNER JOIN ods_order_detail a ON
a.`order_id` = d.`id`
WHERE
DATE_FORMAT( f3.payment_time, 'yyyy-MM-dd')= '2025-08-11'
GROUP BY
a.`sku_id`
UNION ALL
SELECT
f4.`sku_id`,
0 favor_cnt,
0 cart_cnt,
0 order_cnt,
0 pay_cnt,
COUNT(*) refund_cnt,
0 good_cnt,
0 midd_cnt,
0 bad_cnt,
0 defa_cnt
FROM
ods_order_refund_info f4
WHERE
DATE_FORMAT(f4.create_time, 'yyyy-MM-dd')= '2025-08-11'
GROUP BY
f4.`sku_id`
-- f5这里指的是用户的评论信息,里面有用户id
UNION ALL
SELECT
f5.`sku_id`,
0 favor_cnt,
0 cart_cnt,
0 order_cnt,
0 pay_cnt,
0 refund_cnt,
-- c是哪来的?
SUM(CASE c.dic_name WHEN '好评' THEN 1 ELSE 0 END) good_cnt,
SUM(CASE c.dic_name WHEN '中评' THEN 1 ELSE 0 END) midd_cnt,
SUM(CASE c.dic_name WHEN '差评' THEN 1 ELSE 0 END) bad_cnt,
SUM(CASE c.dic_name WHEN '自动' THEN 1 ELSE 0 END) defa_cnt
FROM
ods_comment_info f5
INNER JOIN ods_base_dic c ON
f5.`appraise` = c.`dic_code`
WHERE
f5.dt = '2025-08-11'
GROUP BY
f5.`sku_id`
) tt
GROUP BY
tt.sku_id;
关于各种评论的计数这里是很妙的
SELECT
f5.`sku_id`,
0 favor_cnt,
0 cart_cnt,
0 order_cnt,
0 pay_cnt,
0 refund_cnt,
SUM(CASE c.dic_name WHEN '好评' THEN 1 ELSE 0 END) good_cnt,
SUM(CASE c.dic_name WHEN '中评' THEN 1 ELSE 0 END) midd_cnt,
SUM(CASE c.dic_name WHEN '差评' THEN 1 ELSE 0 END) bad_cnt,
SUM(CASE c.dic_name WHEN '自动' THEN 1 ELSE 0 END) defa_cnt
FROM
ods_comment_info f5
INNER JOIN ods_base_dic c ON
f5.`appraise` = c.`dic_code`
WHERE
f5.dt = '2025-08-11'
GROUP BY
f5.`sku_id`改进点1:代码可读性
首先他区分 好评 中评 差评 没有用 WHERE='好评',也没有做下面这样的表关联
我下面这个 用的是(1)自己手动查出’好评‘对应的编号(2)WHERE提取出好评的行,然后(3)用COUNT(*) 统计出好评的个数。
SELECT sku_id,COUNT(*) good FROM
(SELECT * FROM comment_info
WHERE appraise=1201) a1
GROUP BY sku_id他上面,老师的做法的思路是先把评论表ods_comment_info和评论字段含义的ods_base_dic做拼接,按照1201这样的标识码拼接
ods_comment_info f5
INNER JOIN ods_base_dic c ON
f5.`appraise` = c.`dic_code`【改进点】代码可读性,可维护性上的优化】然后因为已经拼接好了,直接从标识码含义字典ods_base_dic里面取’好评‘这个字段
这样比你上面直接人为找出好评的标识码1201,代码的可读性更好,也利于以后同事维护这个代码
改进点2:
【改进点】【减少子查询,提升性能】然后他没有使用 WHERE 字段=”好评“,外面再嵌套一层count*,而是一个步骤 (1)CASE WHEN 凸显出打好评的人,然后(2)求SUM就得出打好评的人
所有的WHERE 某个限定条件,外面一个子查询 COUNT(*)。都可以被CASE字段-列 WHEN条件1 THEN 0,然后SUM() 这样不套子查询这样来优化
SUM(CASE c.dic_name WHEN '好评' THEN 1 ELSE 0 END) good_cnt
FROM
ods_comment_info f5
INNER JOIN ods_base_dic c ON
f5.`appraise` = c.`dic_code`
GROUP BY
f5.`sku_id`改进点3:避免多表JOIN,用多零表UNION ALL 然后SUM完成拼接
原来的写法是11个表10个JOIN
疑问-揣测:UNION ALL只是按照列的位置直接纵向拼接,不会对比其他条件是否相等。是不是因此,才比较快
好评率,差评率的比例去哪里了?
支付是从哪张表上,怎么提取到的这些数据?
项目人员信息
项目经理1个
数据开发:3个
数据测试:1个
数据报表:兼职
业务老师:甲方,项目经理向他汇报
数据开发怎么分工:按业务模块分工(用户,订单)
业务做了多久?半年—一年
600-700指标(一个人200-300个指标)
TB
每张表百万到千万
一个脚本跑多久
说唯品会等小众电商
这个最怕的是别人问你从ODS到DWD层,你是怎么做的数据清洗

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)