
基于多目标粒子群算法的无人机物流路径优化
✨ 专业领域
擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
针对城市环境下无人机物流配送的多目标路径优化问题,提出一种基于多目标粒子群算法(MOPSO)的路径规划方法。无人机从配送中心出发,需服务多个分散的客户点后返回,优化目标包括总飞行距离最短、总能耗最低(考虑负载变化与逆风影响)、总风险最小(飞越人口密集区、禁飞区的风险)以及客户满意度最高(即送达时间与客户期望时间窗的偏差最小)。这些目标相互冲突,如最短路径可能穿越高风险区,最低能耗可能需牺牲时间窗。传统单目标优化无法同时平衡多个目标。
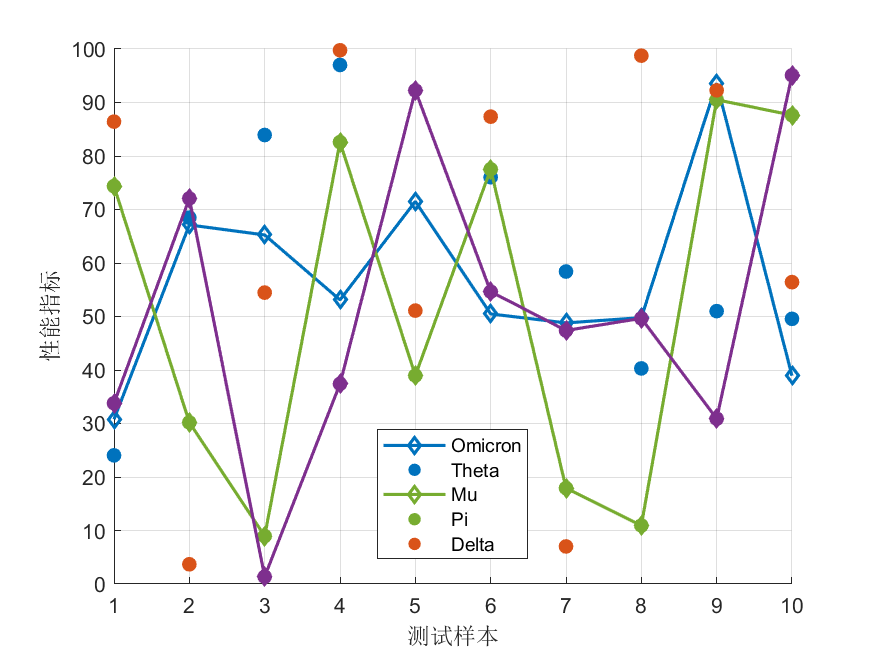
基于动态拥挤距离的帕累托前沿维护策略,在每次迭代中更新粒子群的非支配解存档,当存档大小超过设定值时,计算每个解在目标空间中的拥挤距离(即相邻解在各目标维度上的距离之和),优先保留拥挤距离大的解以维持前沿分布的广度与均匀性,同时引入精英保留机制,将历史最优非支配解集与当前存档合并更新;二是提出了基于领导粒子选择的多样性增强机制,每个粒子在选择全局领导粒子时,采用轮盘赌方式从非支配解存档中选择,选择概率与拥挤距离成正比,使得较稀疏区域的解有更高概率被追随,从而避免粒子群过早聚集到某一局部前沿区域,此外为每个粒子分配一个随机邻居拓扑,使其同时参考自身历史最优与邻居最优,平衡全局与局部搜索;三是构建了多目标约束处理模型,将无人机最大航程、最大负载、客户时间窗作为硬约束,采用约束支配原则比较粒子优劣
比较约束违反程度,违反程度小的粒子占优,若违反程度相同则比较目标向量支配关系,同时为软时间窗约束设计二次惩罚函数,轻微超时惩罚较小,严重超时惩罚剧增。算法初始化时随机生成粒子位置(即客户点访问序列),采用编码解码机制将连续粒子位置向量通过随机键排序转换为离散路径序列;每个粒子根据自身历史最优、全局领导粒子(或邻居最优)更新速度与位置;更新后评估各目标函数值与约束违反程度,更新个体最优与非支配解存档;迭代结束后输出非支配解集供决策者根据实际偏好选择。该方法能为无人机物流配送提供一组均衡各目标的帕累托最优路径方案。
import numpy as np
import random
def initialize_particles(num_particles, num_customers):
particles = []
for _ in range(num_particles):
position = np.random.rand(num_customers) * 100
particles.append(position)
return particles
def decode_position_to_route(position, depot, customers):
order = np.argsort(position)
route = [depot]
for idx in order:
route.append(customers[idx])
route.append(depot)
return route
def calculate_distance(route):
dist = 0
for i in range(len(route)-1):
dist += np.sqrt((route[i+1][0]-route[i][0])**2 + (route[i+1][1]-route[i][1])**2)
return dist
def calculate_energy(route, load_weight):
energy = 0
for i in range(len(route)-1):
dist = np.sqrt((route[i+1][0]-route[i][0])**2 + (route[i+1][1]-route[i][1])**2)
energy += dist * (1 + 0.01*load_weight)
return energy
def calculate_risk(route, risk_zones):
total_risk = 0
for point in route:
for zone in risk_zones:
dist = np.sqrt((point[0]-zone[0])**2 + (point[1]-zone[1])**2)
if dist < zone[2]:
total_risk += zone[3] * (zone[2]-dist)/zone[2]
return total_risk
def calculate_time_window_violation(route, time_windows, speed):
violation = 0
current_time = 0
for i in range(1, len(route)):
dist = np.sqrt((route[i][0]-route[i-1][0])**2 + (route[i][1]-route[i-1][1])**2)
current_time += dist / speed
if i-1 < len(time_windows):
early, late = time_windows[i-1]
if current_time < early:
violation += (early - current_time) * 0.5
elif current_time > late:
violation += (current_time - late) * 2.0
return violation
def dominates(a, b):
return all(a[i] <= b[i] for i in range(len(a))) and any(a[i] < b[i] for i in range(len(a)))
def update_archive(archive, new_particle, max_archive):
to_remove = []
for i, sol in enumerate(archive):
if dominates(sol['obj'], new_particle['obj']):
return archive
if dominates(new_particle['obj'], sol['obj']):
to_remove.append(i)
archive = [archive[i] for i in range(len(archive)) if i not in to_remove]
archive.append(new_particle)
if len(archive) > max_archive:
crowding_distances = []
obj_matrix = np.array([sol['obj'] for sol in archive])
for m in range(obj_matrix.shape[1]):
order = np.argsort(obj_matrix[:, m])
crowding = np.zeros(len(archive))
crowding[order[0]] = np.inf
crowding[order[-1]] = np.inf
for i in range(1, len(archive)-1):
crowding[order[i]] += (obj_matrix[order[i+1], m] - obj_matrix[order[i-1], m])
sorted_idx = np.argsort(crowding)
archive = [archive[i] for i in sorted_idx[:max_archive]]
return archive
def mopso_optimization(depot, customers, risk_zones, time_windows, max_iter, num_particles):
particles = initialize_particles(num_particles, len(customers))
velocities = [np.random.rand(len(customers)) * 0.1 for _ in range(num_particles)]
personal_best = particles.copy()
personal_best_obj = []
for p in particles:
route = decode_position_to_route(p, depot, customers)
obj1 = calculate_distance(route)
obj2 = calculate_energy(route, 5)
obj3 = calculate_risk(route, risk_zones)
obj4 = calculate_time_window_violation(route, time_windows, 10)
personal_best_obj.append([obj1, obj2, obj3, obj4])
archive = []
for i, p in enumerate(particles):
archive = update_archive(archive, {'pos': p, 'obj': personal_best_obj[i]}, 20)
for iteration in range(max_iter):
for i in range(num_particles):
if len(archive) > 0:
leader = random.choice(archive)['pos']
else:
leader = particles[i]
r1, r2 = random.random(), random.random()
velocities[i] = 0.7*velocities[i] + 1.5*r1*(personal_best[i]-particles[i]) + 1.5*r2*(leader-particles[i])
particles[i] = particles[i] + velocities[i]
route = decode_position_to_route(particles[i], depot, customers)
obj1 = calculate_distance(route)
obj2 = calculate_energy(route, 5)
obj3 = calculate_risk(route, risk_zones)
obj4 = calculate_time_window_violation(route, time_windows, 10)
new_obj = [obj1, obj2, obj3, obj4]
if dominates(new_obj, personal_best_obj[i]):
personal_best[i] = particles[i]
personal_best_obj[i] = new_obj
archive = update_archive(archive, {'pos': particles[i], 'obj': new_obj}, 20)
elif not dominates(personal_best_obj[i], new_obj):
if random.random() < 0.1:
personal_best[i] = particles[i]
personal_best_obj[i] = new_obj
return archive
depot_location = (50, 50)
customer_locations = [(10,20), (30,40), (70,80), (90,30), (60,10), (20,70)]
risk_areas = [(40,40,20,5), (80,20,15,3)]
time_windows_list = [(0,50), (10,60), (20,70), (30,80), (40,90), (50,100)]
pareto_front = mopso_optimization(depot_location, customer_locations, risk_areas, time_windows_list, 100, 30)
print("Number of Pareto solutions:", len(pareto_front))如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)