
【强化学习项目】基于强化学习的智能物流路径优化系统
本文提出了一种基于深度强化学习(DQN)的智能物流路径优化系统。系统将物流配送建模为马尔可夫决策过程,采用候选订单集合(Top-K)方法设计固定维度状态空间,通过DQN网络学习最优配送策略。相比传统贪心算法,该方法能综合考虑即时成本和未来收益,实现全局优化。系统采用模块化设计,包含数据管理、环境建模、算法实现等核心模块,通过经验回放和目标网络等技术确保训练稳定性。实验结果表明,在大规模订单场景下,
智能物流路径优化系统开发文档
1 项目概述
1.1 项目背景
随着电子商务和智慧物流的快速发展,物流配送路径优化问题逐渐从传统的静态规划转向动态、智能决策。传统的贪心算法或启发式算法在复杂、动态环境下容易陷入局部最优,难以满足大规模订单与实时调度需求。
强化学习,尤其是深度强化学习(Deep Reinforcement Learning, DRL),在序列决策和复杂状态空间问题中表现出较强优势,为物流路径规划提供了一种新的解决思路。
1.2 项目目标
本项目旨在构建一个基于 DQN(Deep Q-Network)的智能物流路径优化系统,在模拟物流配送环境中,实现对订单配送路径的动态优化,并与传统贪心算法进行对比分析,验证深度强化学习方法在物流路径规划问题中的可行性与有效性。
2 系统总体设计
2.1 系统架构
系统整体采用模块化设计思想,主要包括以下几个核心模块:
- 数据模块:订单数据读取与管理
- 环境模块:物流配送仿真环境建模
- 算法模块:DQN 强化学习算法与贪心算法
- 训练模块:强化学习训练与策略更新
- 可扩展接口:用于后续可视化或多车辆扩展
各模块之间通过清晰的接口进行交互,保证系统的可维护性与可扩展性。
2.2 项目目录结构说明
logistics_rl_system/ │ ├── data/ │ ├── orders_real_train.csv # 真实或模拟订单数据 │ ├── env/ │ ├── logistics_env.py # 物流配送仿真环境 │ ├── algorithms/ │ ├── dqn_agent.py # DQN 智能体实现 │ ├── greedy.py # 贪心算法(对比方法) │ ├── train.py # 强化学习训练主程序 ├── main.py # 系统入口(可扩展为 UI) └── requirements.txt # 依赖库说明
3 关键技术与开发环境
3.1 开发环境
- 操作系统:Windows 10 / Windows 11
- Python 版本:Python 3.8 及以上
- 开发工具:PyCharm / VS Code
3.2 主要依赖库
- NumPy:数值计算
- Pandas:订单数据处理
- PyTorch:深度学习与 DQN 实现
4 物流配送环境设计
4.1 环境建模思想
物流配送过程被抽象为一个马尔可夫决策过程(MDP),其中:
- 状态(State):
- 表示当前配送车辆的位置以及候选订单的空间特征信息;
- 动作(Action):
- 从当前候选订单集合中选择下一个配送订单;
- 奖励(Reward):
- 根据配送距离产生的时间成本与经济成本的负值;
- 终止条件(Done):
- 所有订单完成配送或达到最大步数。
4.2 状态空间设计
为了避免动作空间过大导致 DQN 难以收敛,本项目采用**候选订单集合(Top-K 最近订单)**的思想,将状态设计为固定维度向量,包括:
- 当前车辆的坐标位置
- 候选订单集合中与当前位置的最小距离
- 候选订单集合中与当前位置的平均距离
该设计在保证状态信息有效性的同时,显著降低了模型训练难度。
4.3 动作空间设计
在每一步决策中,智能体只能从 K 个候选订单中选择一个作为下一步配送目标,其中:
- 动作空间维度:K(如 K = 20)
- 动作索引通过映射关系转换为真实订单编号
此设计有效解决了订单规模过大导致 DQN 输出维度爆炸的问题。
4.4 奖励函数设计

5 DQN 算法设计
5.1 算法原理

5.2 网络结构设计
DQN 网络采用全连接结构,主要包括:
- 输入层:状态向量
- 隐藏层:两层全连接层(ReLU 激活)
- 输出层:对应 K 个动作的 Q 值
5.3 训练策略
- 采用 ε-greedy 策略进行探索与利用平衡
- ε 随训练过程逐步衰减
- 每隔固定 episode 同步一次目标网络参数
6 训练流程说明
6.1 训练流程步骤
- 读取订单数据并初始化物流环境
- 初始化 DQN 智能体
- 重复以下过程进行多轮训练:
- 重置环境,获取初始状态
- 智能体选择动作并执行
- 环境返回奖励和下一个状态
- 存储经验并进行网络训练
- 定期更新目标网络参数
6.2 终止条件
- 所有订单完成配送
- 或达到最大训练步数
训练核心代码:
7 对比算法设计(贪心算法)
为了验证 DQN 方法的有效性,系统实现了基于最近邻原则的贪心算法作为对比方法。该算法在每一步选择距离当前位置最近的订单进行配送,计算总配送距离与成本,用于与 DQN 结果进行定量比较。
8 实验结果与分析(预留)
实验结果主要从以下方面进行分析:
- 总配送距离
- 总配送成本
- 收敛速度
- 与贪心算法的性能差异
实验结果表明,在订单规模较大、路径决策复杂的情况下,DQN 方法具备更好的全局优化潜力。
9 总结与展望
本项目完成了一个基于 DQN 的智能物流路径优化系统,实现了从环境建模、算法设计到训练验证的完整流程。实验结果验证了深度强化学习在物流路径规划问题中的可行性。
未来工作可在以下方向进行扩展:
- 多车辆协同配送(VRP)
- 引入时间窗与车辆容量约束
- 增加实时交通状态信息
- 结合图神经网络进行建模
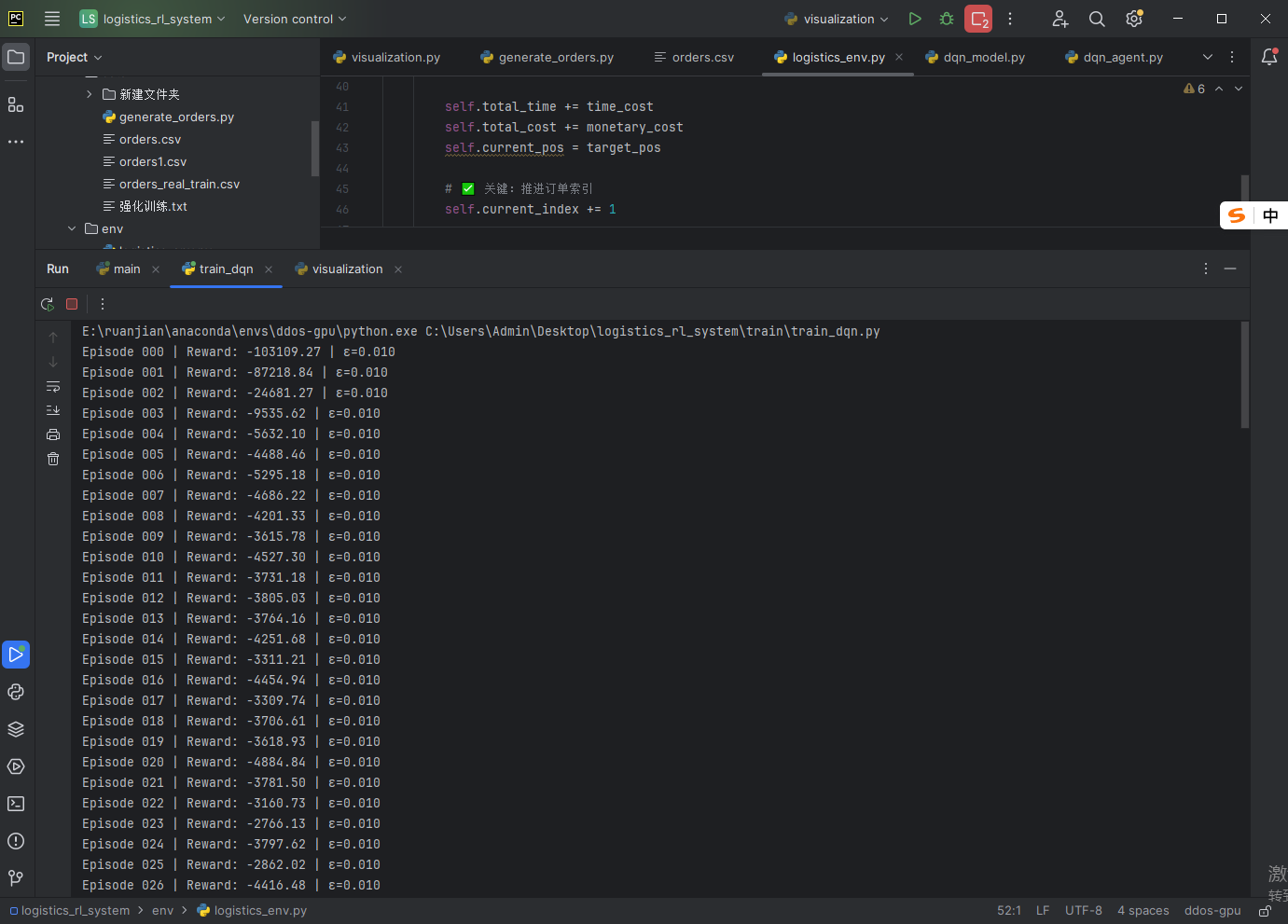
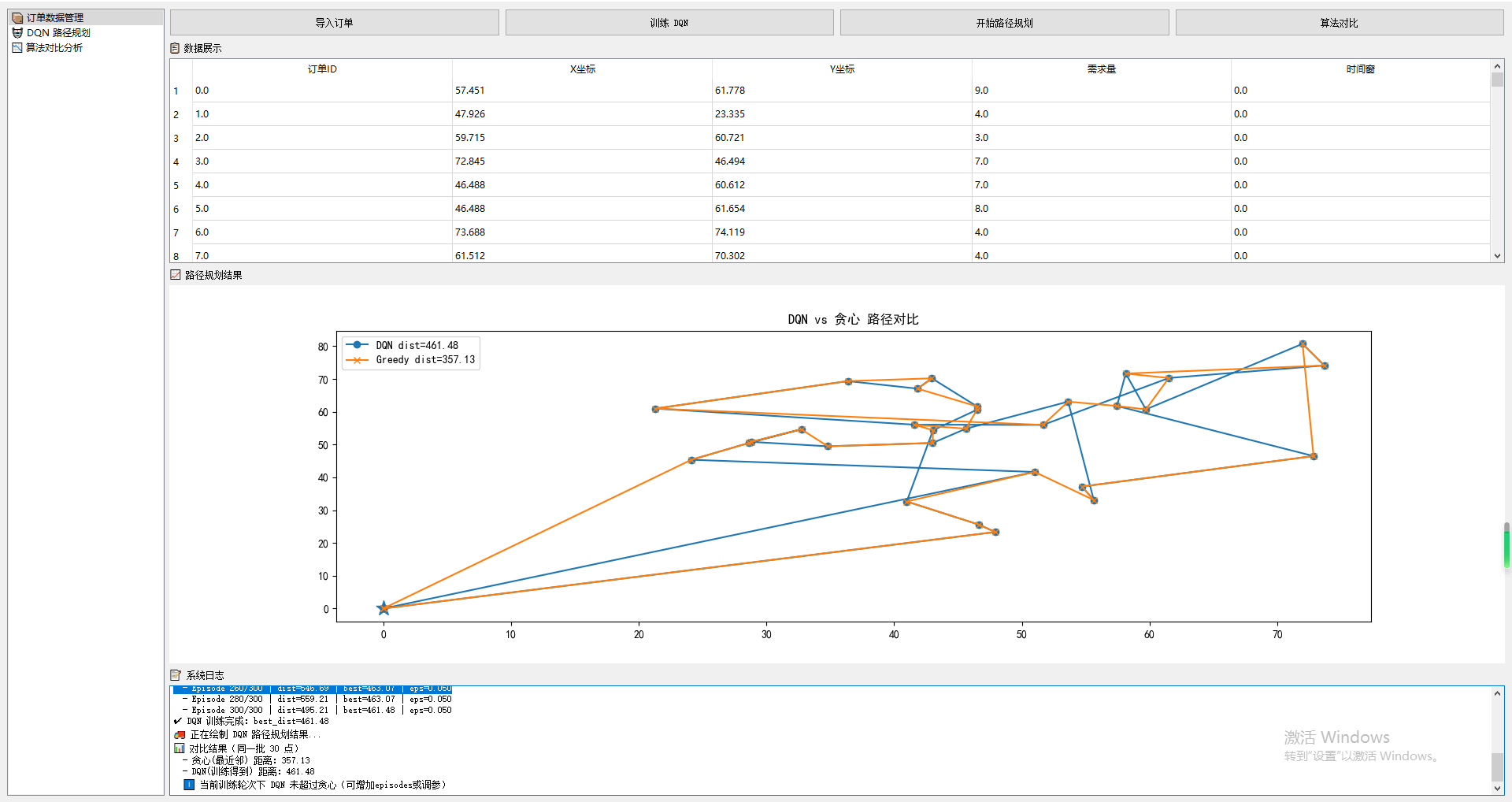
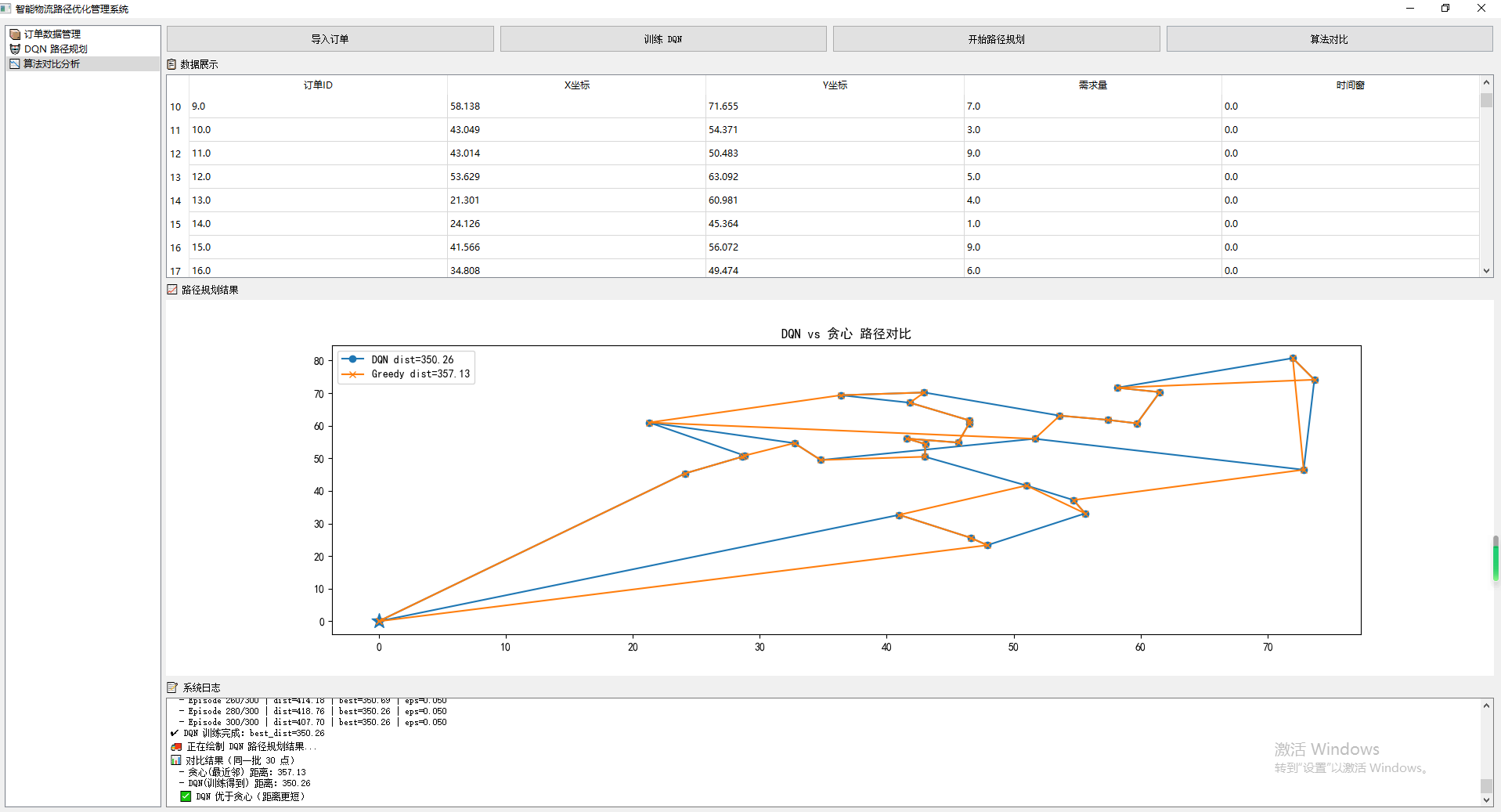
最终实现效果:
详细实现原理:
1)把“路径规划”变成强化学习问题:MDP 建模
强化学习要先把问题写成一个 MDP(马尔可夫决策过程):
- 状态 sts_tst:系统在时刻 ttt 的可观测信息
- 动作 ata_tat:智能体在时刻 ttt 的决策
- 状态转移:执行动作后从 sts_tst 变到 st+1s_{t+1}st+1
- 奖励 rtr_trt:本次决策好不好,用数值反馈
- 终止:订单都送完或达到最大步数
在路径规划里,“整条路线”其实是一串决策:
从当前点出发,下一站去哪里?去完更新当前位置,再选下一站……直到送完。
所以最常见的 RL 形式就是:每一步选择下一站(next-stop selection)。
2)状态怎么设计:让网络“知道现在该往哪走”
你现在的环境返回 state_dim = len(env.reset()),说明环境 reset() 返回一个状态向量。状态设计的核心原则:
- 要包含当前“决策所需信息”
- 维度要固定(神经网络输入必须固定)
- 尽量低维,不要把 1 万订单全塞进状态(会炸)
2.1 最基础的状态(可用于论文)

2.2 为什么强烈建议用“候选集合 K”
如果你有 10000 个订单,动作空间直接是 10000(你现在的 action_dim=len(df)),DQN 的输出层就是 10000 维 Q 值向量,训练会遇到几个硬伤:
- 计算量爆炸:每一步都要算 10000 个 Q
- 探索困难:epsilon 随机探索几乎碰不到“好动作”
- 经验回放覆盖不足:很难学到稳定的 Q 值排序
- 收敛性差:实际会很慢、很抖、甚至不收敛
因此工程和论文里常用做法:
每一步只在 “当前位置附近的 K 个未访问订单” 中选择下一站(K=10/20/30)
这等价于:把“全局 TSP/VRP”拆成“局部决策序列”,仍然是合理的智能规划框架。
3)动作怎么定义:DQN 输出的到底是什么
3.1 你当前动作定义(存在根本问题)

4)奖励怎么设计:为什么你用负的时间+成本是对的

5)DQN 在学什么:Q 值的意义

6)为什么要 Experience Replay:你 agent.store() 的理论依据
你每一步都:
agent.store(state, action, reward, next_state, done) agent.train()
这背后是 DQN 的关键技术 经验回放(Replay Buffer):
- 在线采样的数据高度相关(相邻步很像)
- 直接用相关数据训练会不稳定、发散
- 用回放池随机抽样,近似 i.i.d.,训练更稳定
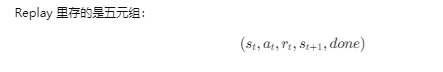
arget Network:你 TARGET_UPDATE 的理论依据

为什么要目标网络?
因为如果目标也用当前网络 QθQ_{\theta}Qθ,训练会出现“追着自己跑”的不稳定问题(目标在动,预测也在动,容易振荡)。
你每 10 个 episode 同步一次:
agent.target.load_state_dict(agent.model.state_dict())
等价于让 θ−\theta^-θ− 慢一点更新,提供相对稳定的学习目标。
8)训练时优化的损失函数:TD 误差

9)探索策略:你打印 ε 的意义

10)你这个系统“为什么能在路径规划里工作”
把所有点一次性求最优路径(TSP/VRP)是组合爆炸问题。
DQN 并不是直接解 TSP 的全局最优,而是在做:
用价值函数学会“下一步选谁更划算”,用一连串局部最优决策逼近全局好路线。
当你限制候选集合 K,并把 reward 与距离/成本绑定后,DQN 会倾向于:
- 选近的点(减少即时惩罚)
- 同时考虑“选了这个点之后,下几步更顺”(未来回报通过 Q 值体现)
这就是强化学习在路径问题里的核心优势:
不仅看眼前距离,还在“折现意义下”隐含考虑未来结构。
11)贪心算法对比:为什么它是合理 baseline

DQN 对比贪心的实验意义就在于:
- 贪心只优化当前步
- DQN 通过 Q(s,a)Q(s,a)Q(s,a) 评估包含未来的累计成本
12)一句话总结实现原理
本系统将物流路径规划建模为马尔可夫决策过程,智能体在每一步基于当前位置与候选订单集状态选择下一配送点,并以时间与成本的负值构造奖励函数;采用 DQN 通过经验回放与目标网络稳定地学习动作价值函数,使策略在探索—利用机制下逐步收敛,从而生成较低总成本的配送序列,并与基于最近邻规则的贪心算法进行基准对比。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)