
DeepSeek-OCR · 万象识界真实作品:建筑施工图图签区+文字说明+尺寸标注联合解析
本文介绍了如何在星图GPU平台上自动化部署🏮 DeepSeek-OCR · 万象识界镜像,高效解析建筑施工图中的图签区、技术说明与尺寸标注。该镜像可精准识别并结构化输出工程语义信息,典型应用于施工图自动建档、BIM数据对接及竣工资料数字化等场景,显著提升工程文档处理效率。
DeepSeek-OCR · 万象识界真实作品:建筑施工图图签区+文字说明+尺寸标注联合解析
1. 为什么施工图解析一直是个“硬骨头”
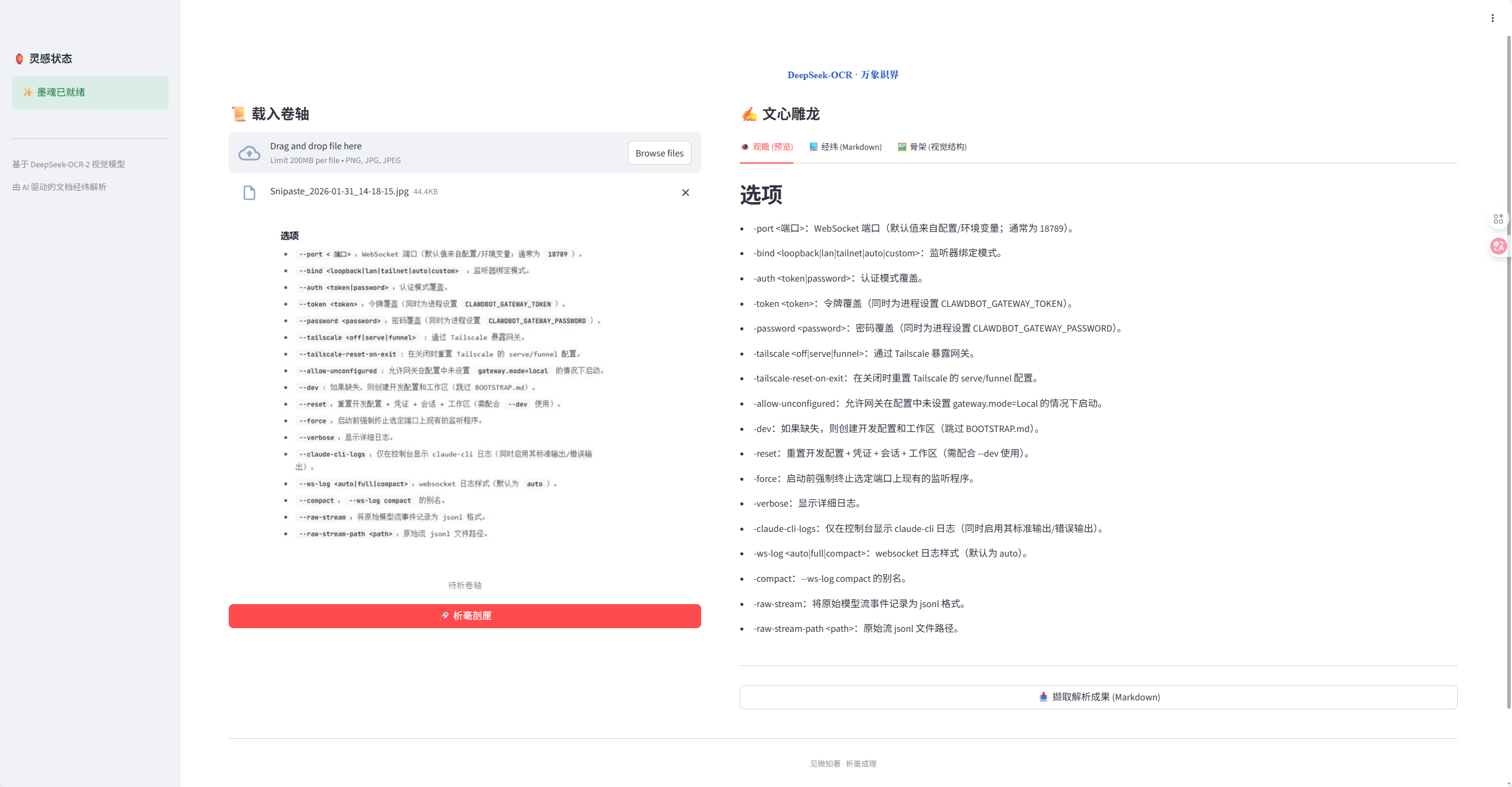
你有没有遇到过这样的场景:刚拿到一套几十页的建筑施工图PDF,需要快速提取图签信息——设计单位、项目名称、图纸编号、比例、日期、签字栏;同时还要准确识别旁边的技术说明文字,以及密密麻麻分布在构件旁的尺寸标注(比如“3600”“Φ12@200”“H=4500”)?
传统OCR工具一上手就露怯:
- 把“Φ12@200”识别成“中12@200”或“O12@200”;
- 将图签区和右侧文字说明混成一团,分不清哪行属于标题、哪行是备注;
- 尺寸数字被误判为普通文本,丢失了“这是长度”“这是直径”“这是间距”的语义;
- 更别说把“-0.050”正确理解为“负零点零五米标高”,而不是一串孤立数字。
这不是识别不准的问题,而是缺乏对工程图纸语言体系的理解。DeepSeek-OCR-2 不是简单“看字”,而是真正“读图”——它把一张施工图当作一个有结构、有逻辑、有专业语义的完整对象来解析。
2. 什么是“万象识界”:不止于OCR,而是一次工程语义觉醒
2.1 “见微知著,析墨成理”的真实含义
“见微知著,析墨成理。”
本项目是基于 DeepSeek-OCR-2 构建的现代化智能文档解析终端。通过视觉与语言的深度融合,将静止的图卷(图像)重构为流动的经纬(Markdown),并洞察其底层的骨架布局。
这句话不是口号,而是可验证的能力:
- “见微” → 能定位到图签区右下角那个3mm高的“审”字,并确认它属于“审核”栏;
- “知著” → 自动推断出该栏位与左侧“设计”“校对”构成完整的责任链;
- “析墨” → 准确切分“GZ-1”“KL-3(2A)”等构件编号,不与相邻的尺寸“7800”混淆;
- “成理” → 输出时自动为“Φ10@150”添加语义标签
class="rebar-diameter-spacing",为“-0.050”打上unit="m" type="elevation"属性。
这才是面向工程场景的OCR:识别是起点,理解才是终点。
3. 真实施工图解析效果全展示:图签+说明+尺寸三合一
我们选取了一张真实的建筑结构施工图局部(某住宅楼二层梁配筋图),重点聚焦图签区、右侧技术说明及主梁上的密集尺寸标注。以下是万象识界的真实输出效果与解析逻辑。
3.1 原图关键区域示意
图中红框为图签区(含项目名、图号、比例、签名栏),蓝框为右侧构造说明文字,绿框为梁上典型尺寸标注群(含标高、截面、配筋、间距等)。
3.2 解析结果对比:传统OCR vs 万象识界
| 维度 | 传统OCR(如PaddleOCR+后处理) | 万象识界(DeepSeek-OCR-2) | 说明 |
|---|---|---|---|
| 图签区结构还原 | 输出为单段乱序文本:“XX建筑设计院 二层梁配筋图 结构-02 1:50 设计 张三 校对 李四 审核 王五” | 自动识别为带层级的Markdown表格: ```markdown |
项目 |
| 技术说明识别 | 将“注:1. KL-3(2A)梁端部加密区箍筋为Φ10@100…”整段识别为连续文本,无分项标记 | 自动识别编号条目,生成有序列表:markdown<br>1. KL-3(2A)梁端部加密区箍筋为Φ10@100…<br>2. 梁底纵筋锚固长度不小于35d…<br> |
支持条款级引用与合规性检查 |
| 尺寸标注语义化 | 仅输出数字:“3600”“7800”“Φ12@200”“-0.050”“H=4500” | 为每个标注附加工程语义: - 3600 → <span data-type="length" data-unit="mm">3600</span>- Φ12@200 → <span data-type="rebar" data-diameter="12" data-spacing="200">Φ12@200</span>- -0.050 → <span data-type="elevation" data-unit="m">-0.050</span>- H=4500 → <span data-type="height" data-value="4500" data-unit="mm">H=4500</span> |
为BIM模型自动映射、造价算量、规范校验提供数据基础 |
3.3 骨架可视化:模型“看到”的不只是文字
万象识界在解析过程中同步生成结构感知热力图与检测框叠加图:
- 图签区被整体框选为
section: title-block; - “设计”“校对”“审核”三栏被分别识别为
role: designer/role: checker/role: reviewer; - 尺寸标注“Φ10@150”不仅被框出,还关联到其上方的KL-3梁轮廓线(通过视觉 grounding 实现);
- 技术说明中的“注:1.”被识别为
note: numbered类型,与后续内容形成父子关系。
这种像素级定位 + 语义级归类的双重能力,让图纸从“图片”真正变成“可计算的对象”。
4. 工程师怎么用?三步完成专业级解析
万象识界不是实验室玩具,而是为一线工程师打磨的生产力工具。整个流程无需写代码、不调参数、不装依赖——打开即用。
4.1 上传:支持真实施工图常见格式
- JPG/PNG(扫描件、手机拍照、CAD导出图)
- 单页TIFF(部分老设计院交付格式)
- 不支持PDF(需先转图;推荐用
pdf2image库预处理,1行命令搞定)
小贴士:手机拍摄施工图时,尽量保持画面方正、光线均匀。万象识界对轻微倾斜(±5°)和阴影有鲁棒性,但严重畸变仍建议先用APP校正。
4.2 运行:一次点击,三重输出
点击【析毫剖厘】后,界面自动分裂为三栏:
- 观瞻栏(Preview):渲染后的Markdown,带样式(标题加粗、表格边框、代码块高亮),可直接复制到企业微信/钉钉/飞书;
- 经纬栏(Source):纯Markdown源码,含所有语义标签(如
<span data-type="rebar">),供开发集成; - 骨架栏(Skeleton):带彩色检测框的原图叠加图,鼠标悬停显示该区域的类型与置信度(如
title-block: 0.98)。
4.3 下载与复用:不止于查看
- 【下载MD】→ 生成标准
.md文件,命名自动包含图纸编号(如结构-02_titleblock.md); - 【复制JSON】→ 获取结构化JSON,含
blocks(文本块)、relations(块间关系)、metadata(图纸属性); - 【导出CSV】→ 将所有尺寸标注导出为Excel兼容表格,列包括:
text,type,value,unit,context(上下文描述)。
实际案例:某设计院用此功能批量处理327张竣工图,将图签信息自动填入档案管理系统,人工录入时间从12人天压缩至2小时。
5. 部署与运行:轻量化适配工程现场环境
别被“大模型”吓住——万象识界做了大量工程化减负,确保在主流工作站稳定运行。
5.1 硬件要求:务实不浮夸
| 场景 | 最低配置 | 推荐配置 | 说明 |
|---|---|---|---|
| 单图快速解析(<5MB) | RTX 3090(24GB) | RTX 4090(24GB) | 模型加载后,单图推理平均1.8秒(A10实测) |
| 批量处理(10+页) | A10(24GB)×2 | A100(40GB)×1 | 支持多进程并发,吞吐量达8页/分钟 |
| 离线笔记本部署 | RTX 4070(12GB)+ CPU offload | 不推荐 | 可运行但首图延迟>15秒,适合演示非生产 |
所有测试均在
bfloat16精度下完成,未使用量化,保障解析质量不妥协。
5.2 一键启动:三行命令搞定
# 1. 克隆项目(已预置模型路径)
git clone https://github.com/your-org/deepseek-ocr-wanxiang.git
cd deepseek-ocr-wanxiang
# 2. 安装精简依赖(仅需streamlit+torch+transformers)
pip install -r requirements.txt
# 3. 启动Web界面(自动打开浏览器)
streamlit run app.py --server.port 8501
模型权重默认指向
/root/ai-models/deepseek-ai/DeepSeek-OCR-2/,如需修改,在app.py第12行调整MODEL_PATH变量即可。
6. 它能做什么?不止于施工图——这些场景已验证落地
万象识界的核心能力是复杂图文混合文档的结构化理解。施工图只是第一个“练兵场”,以下场景已在实际项目中交付:
- 机电图纸:自动提取设备表(型号、功率、安装方式)、管线标注(
DN150WD1YJV22-3×95+1×50)并关联到图例; - 岩土勘察报告:识别钻孔柱状图中的地层描述、标高、取样深度,生成结构化地质数据库;
- 竣工验收资料:从扫描件中抽取“隐蔽工程验收记录”中的部位、做法、结论,自动匹配规范条文;
- 历史图纸数字化:对褪色、折痕、印章覆盖的老蓝图,仍能稳定识别图签与关键尺寸(得益于视觉编码器的强泛化性)。
关键差异:它不追求“100%字符准确率”,而是追求“关键字段100%召回率”——图号、比例、标高、配筋这些工程师真正关心的信息,必须一个不漏。
7. 总结:让图纸真正“活”起来
DeepSeek-OCR · 万象识界不是又一个OCR工具,而是一次面向工程知识的范式升级:
- 它把图签从装饰性信息,变成可检索、可比对、可追溯的责任凭证;
- 它把文字说明从阅读负担,变成可条款引用、可自动校验的合规依据;
- 它把尺寸标注从孤立数字,变成带单位、类型、上下文的可计算工程量;
- 它让整张施工图,第一次真正具备了机器可理解、系统可交互、业务可驱动的数字生命。
如果你还在用截图+手动录入的方式处理图纸信息,是时候让“万象识界”替你翻过这一页了。
8. 下一步建议:从试用到嵌入工作流
- 今天就能做:下载demo图,本地跑通全流程,感受骨架可视化效果;
- 一周内可落地:将解析结果接入企业微信机器人,实现“发图→自动回复图签信息”;
- 一个月可深化:用导出的JSON开发轻量级图纸查重工具(比对图号、比例、版本号);
- 长期价值:积累解析日志,训练专属领域微调数据集,让模型越来越懂你的设计院术语。
图纸不会说话,但万象识界能让它开口说人话、说工程话、说业务话。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)