
从 0 到 1 用 tRPC-Go 写一个图书管理服务:一份可跑、可读、可拓展的实战笔记
本文介绍如何使用tRPC-Go框架开发一个图书管理服务,从接口定义到业务实现完整流程。主要内容包括: 使用protobuf定义服务契约,通过trpc create命令自动生成代码桩 业务层实现CRUD操作,采用依赖注入分离业务逻辑与数据访问 关键设计: 嵌入UnimplementedService保证增量开发 构造函数注入仓储接口 业务不变量集中维护(如借书操作的库存同步) 项目结构清晰划分各层职
从 0 到 1 用 tRPC-Go 写一个图书管理服务:一份可跑、可读、可拓展的实战笔记
本文配套源码已经在我的本地工程
trpc/library跑通:一条go run .启动 tRPC 服务 + HTTP 网关,浏览器访问http://127.0.0.1:8080就能看到一个可用的"图书管理"小后台。本文带你把这套工程从 proto 契约 → 业务实现 → 持久化层 → HTTP 网关 → 单元测试 → 客户端验证完整走一遍,并给出每一处"为什么这么写"的设计理由。适合人群:刚接触 tRPC-Go、想要一份真·能跑起来的最小生产级范例的同学。
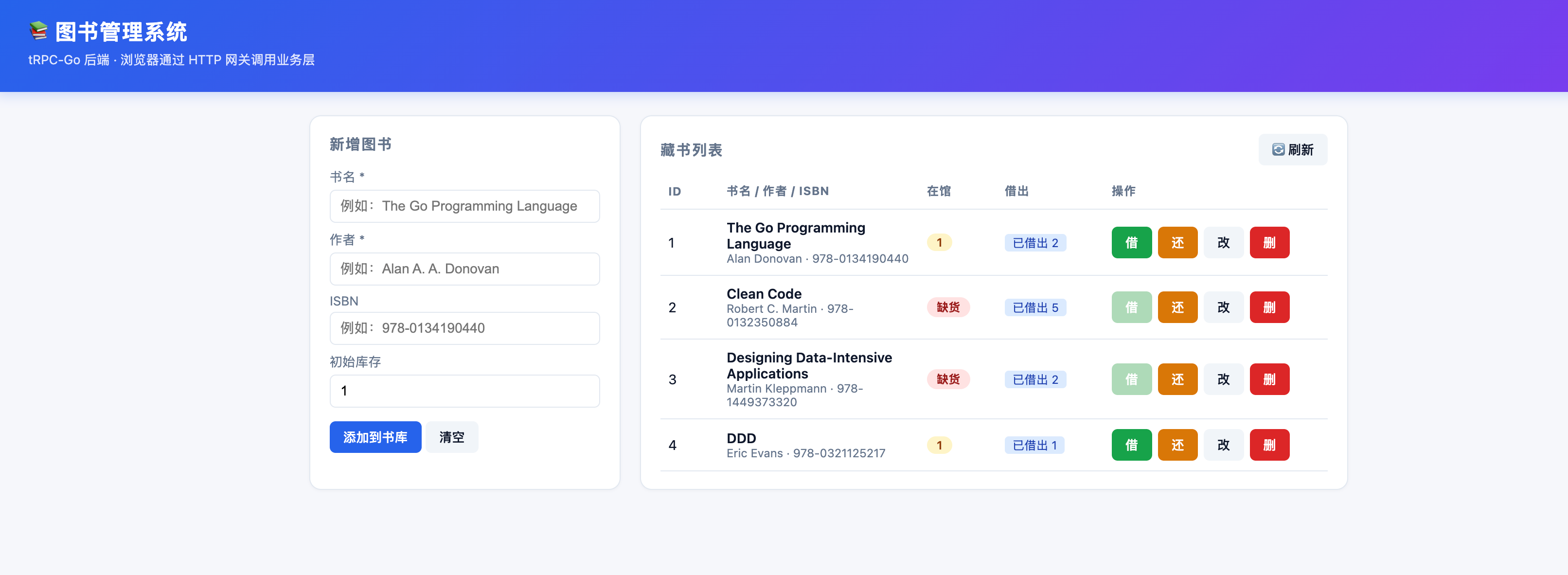
一、为什么选 tRPC-Go 写这个 demo
很多人第一次接触 tRPC-Go,会被它的体量唬住——配置文件长达上百行、插件机制、名字服务、过滤器……一上来就讲框架,结果业务的影子都没有。
我做这个图书管理 demo 的目标恰恰相反:用最少的"框架味道"把 tRPC-Go 的核心能力串一遍:
- 用
proto定义接口契约,让通讯协议、消息结构都自动生成 - 用
trpc create一行命令生成 stub,业务代码只需要"补方法" - 用依赖注入把存储层抽出来,业务代码不感知是内存还是 MySQL
- 用
errs把业务错误码与框架错误码隔离,便于上层做统一映射 - 顺手再挂一个 HTTP 网关 + 静态前端,让浏览器也能直连同一份业务
整个 repo 的最终目录长这样:
trpc/library/
├── library.proto ← ① 契约:接口定义
├── stub/.../library.{pb,trpc}.go ← ② 自动生成的 stub(不要手改)
├── library_service.go ← ③ 业务实现层(CRUD 业务规则)
├── internal/repository/book_repo.go ← ④ 数据访问层(可换 MySQL)
├── internal/httpgw/gateway.go ← ⑤ HTTP/JSON 网关(给浏览器用)
├── web/index.html ← ⑥ 极简前端
├── cmd/client/main.go ← ⑦ tRPC 客户端 demo
├── library_service_test.go ← ⑧ 业务层单元测试
├── trpc_go.yaml ← ⑨ 框架/插件配置
└── main.go ← ⑩ 启动入口 + DI
划重点:这十个文件的角色一定要分清楚。新手最容易犯的错就是把业务写到
stub/里——而stub/是会被trpc create重写覆盖的。
二、第一步:用 proto 定义"接口契约"
library.proto 是整个项目的唯一信息源。无论你之后用 Go、Java 还是 Python 写客户端,都要先看这份文件。
syntax = "proto3";
package library;
option go_package = "git.code.oa.com/examples/library";
service LibraryService {
rpc ListBooks (ListBooksReq) returns (ListBooksRsp);
rpc GetBook (GetBookReq) returns (Book);
rpc CreateBook (CreateBookReq) returns (Book);
rpc UpdateBook (UpdateBookReq) returns (Book);
rpc DeleteBook (DeleteBookReq) returns (DeleteBookRsp);
rpc BorrowBook (BorrowBookReq) returns (Book);
rpc ReturnBook (ReturnBookReq) returns (Book);
}
message Book {
int64 id = 1;
string title = 2;
string author = 3;
string isbn = 4;
int32 stock = 5; // 在馆可借数量
int32 borrowed = 6; // 已借出数量
int64 created_at = 7;
int64 updated_at = 8;
}
设计上的小细节
stock与borrowed成对维护:这是后续BorrowBook/ReturnBook的不变量,所有对它们的修改都收敛在这两个 RPC 内部,普通UpdateBook不允许改borrowed。- 专门定义
BorrowBookReq/ReturnBookReq:而不是复用UpdateBookReq。这样接口语义更明确,客户端调用时一眼能看出"我要借书",而不是"我要把库存减一"。 go_package必须显式声明:不然trpc create不知道往哪个 import path 生成 stub。
用 trpc create 生成 stub
trpc create -p library.proto -o library --mod git.code.oa.com/examples/library
这条命令会在 stub/git.code.oa.com/examples/library/ 下生成三件套:
library.pb.go:消息结构体(Book、CreateBookReq…)library.trpc.go:服务接线代码(RegisterLibraryServiceService、UnimplementedLibraryService…)library_mock.go:用于单元测试的 mock 桩
🚨 铁律:stub 目录下的代码绝对不要手改。它是 proto 的衍生物,下次重新生成会覆盖你的修改。
三、第二步:业务层只关心"业务规则"
业务实现写在 library_service.go,文件结构很干净——一个嵌入了自动生成 UnimplementedLibraryService 的结构体 + 一个 repository 字段:
type libraryServiceImpl struct {
pb.UnimplementedLibraryService
repo repository.BookRepository
}
func newLibraryServiceImpl(repo repository.BookRepository) *libraryServiceImpl {
return &libraryServiceImpl{repo: repo}
}
两个关键设计决策:
- 嵌入
UnimplementedLibraryService:意味着即使 proto 增加了新方法、你还没来得及实现,编译也不会失败,新方法会自动返回UNIMPLEMENTED。这对增量开发非常友好。 - 构造函数注入
BookRepository:业务代码只依赖接口,不依赖具体实现。单元测试时塞内存仓储,生产环境塞 MySQL 仓储——零业务改动。
3.1 CreateBook:参数校验 + 委托存储
func (s *libraryServiceImpl) CreateBook(
ctx context.Context,
req *pb.CreateBookReq,
) (*pb.Book, error) {
title := strings.TrimSpace(req.Title)
author := strings.TrimSpace(req.Author)
isbn := strings.TrimSpace(req.Isbn)
if title == "" || author == "" {
return nil, errs.New(codeInvalidArgument, "title and author are required")
}
if req.Stock < 0 {
return nil, errs.New(codeInvalidArgument, "stock cannot be negative")
}
book, err := s.repo.Create(&pb.Book{
Title: title, Author: author, Isbn: isbn, Stock: req.Stock,
})
if err != nil {
return nil, mapRepoError(ctx, err)
}
log.InfoContextf(ctx, "book created: id=%d title=%q", book.Id, book.Title)
return book, nil
}
新手最常见的反模式是把校验和存储搅在一起——比如直接在 handler 里 map[id]=book、然后又去查 ISBN 是否重复。这里把它们清晰拆开:
| 职责 | 谁负责 |
|---|---|
| 字段去空白、空值校验、范围校验 | 业务层 CreateBook |
| ISBN 唯一性、并发安全、ID 自增 | 数据层 repo.Create |
错误码翻译(ErrISBNDuplicate → codeConflict) |
mapRepoError |
3.2 BorrowBook:业务不变量收敛在一处
借书逻辑必须满足两条不变量:
stock - 1, borrowed + 1始终是同步的stock <= 0时直接拒绝
func (s *libraryServiceImpl) BorrowBook(
ctx context.Context, req *pb.BorrowBookReq,
) (*pb.Book, error) {
if req.Id <= 0 {
return nil, errs.New(codeInvalidArgument, "id must be positive")
}
current, err := s.repo.Get(req.Id)
if err != nil {
return nil, mapRepoError(ctx, err)
}
if current.Stock <= 0 {
return nil, errs.New(codeConflict, "book is out of stock")
}
current.Stock--
current.Borrowed++
updated, err := s.repo.Update(current)
if err != nil {
return nil, mapRepoError(ctx, err)
}
log.InfoContextf(ctx, "book borrowed: id=%d stock=%d borrowed=%d",
updated.Id, updated.Stock, updated.Borrowed)
return updated, nil
}
⚠️ 在 demo 中这里是"先读后写",没有事务。生产环境如果换 MySQL,要么用
UPDATE ... WHERE stock > 0一条 SQL 完成,要么用乐观锁 (WHERE updated_at = ?)。这是把业务层和存储层分开后最容易升级的一处。
3.3 错误码集中翻译:mapRepoError
func mapRepoError(ctx context.Context, err error) error {
switch {
case errors.Is(err, repository.ErrNotFound):
return errs.New(codeNotFound, "book not found")
case errors.Is(err, repository.ErrISBNDuplicate):
return errs.New(codeConflict, "isbn already exists")
default:
log.ErrorContextf(ctx, "repository error: %v", err)
return errs.New(errs.RetServerSystemErr, err.Error())
}
}
为什么要单独抽一个函数?因为多个 RPC 都可能拿到同一类底层错误(ErrNotFound 至少出现在 Get/Update/Delete/Borrow/Return 五个方法里)。集中翻译可以保证:相同的底层错误,对外的 code/message 完全一致。
业务码本身用了 10000+ 区段,是为了避开 errs 框架保留区:
const (
codeInvalidArgument = 10001
codeNotFound = 10002
codeConflict = 10003
)
四、第三步:用接口隔离把"换存储"这件事变得无痛
数据访问层放在 internal/repository/book_repo.go,遵循的是 Go 社区里很经典的"小接口 + 多实现"模式:
type BookRepository interface {
List() ([]*pb.Book, error)
Get(id int64) (*pb.Book, error)
Create(b *pb.Book) (*pb.Book, error)
Update(b *pb.Book) (*pb.Book, error)
Delete(id int64) error
}
var (
ErrNotFound = errors.New("book not found")
ErrISBNDuplicate = errors.New("isbn already exists")
)
接口只有 5 个方法、没有任何业务概念,纯 CRUD——这就是它强大的地方。哪天想接 MySQL/PostgreSQL/Redis,只要新写一个实现,业务代码一行不用改。
内存版的实现要点:
type memoryBookRepo struct {
mu sync.RWMutex
books map[int64]*pb.Book
nextID int64
}
func (r *memoryBookRepo) Create(b *pb.Book) (*pb.Book, error) {
r.mu.Lock()
defer r.mu.Unlock()
if b.Isbn != "" {
for _, existing := range r.books {
if existing.Isbn == b.Isbn {
return nil, ErrISBNDuplicate
}
}
}
r.nextID++
b.Id = r.nextID
if b.CreatedAt == 0 {
b.CreatedAt = time.Now().Unix()
}
b.UpdatedAt = b.CreatedAt
stored := *b // ★ 值拷贝,避免外部继续修改
r.books[b.Id] = &stored
return b, nil
}
三处值得注意的小心思:
sync.RWMutex而不是sync.Mutex:List/Get是读多写少,读用RLock性能更好。- 存进 map 前先值拷贝:避免外部代码修改原指针时绕过锁污染内部状态。
List/Get返回的也是副本:调用方拿到的是只读快照,对外部"善意"。
五、第四步:把 main 写成"装配车间"
main.go 不是该写业务的地方,它的唯一职责是装配 + 启动:
func main() {
s := trpc.NewServer()
// 自底向上构造依赖:repo -> service。
repo := repository.NewMemoryBookRepo()
impl := newLibraryServiceImpl(repo)
pb.RegisterLibraryServiceService(s, impl)
// 在另一个 goroutine 启动 HTTP 网关(仅用于浏览器对接)
go func() {
mux := httpgw.NewMux(impl, "./web")
const addr = "127.0.0.1:8080"
log.Infof("http gateway listening on http://%s", addr)
if err := http.ListenAndServe(addr, mux); err != nil {
log.Errorf("http gateway exited: %v", err)
}
}()
if err := s.Serve(); err != nil {
log.Fatal(err)
}
}
两条 main 函数的最佳实践:
- 依赖构造从内到外:先 repo,再 service,最后注册到 server。读起来一目了然。
- HTTP 网关跑在独立 goroutine,且失败不退主进程:tRPC 主链路才是核心业务,HTTP 仅仅是为了让浏览器能用——主次分明。
至于配置,全部交给 trpc_go.yaml,框架会自动读取。最关键的几项:
server:
app: library
server: LibraryService
service:
- name: library.LibraryService
ip: 127.0.0.1
port: 8000
network: tcp
protocol: trpc
transport: tnet
这里
transport: tnet是腾讯自研的高性能网络库;如果你后面把 protocol 改成http,记得把这一行删掉,因为 tnet 暂不支持 HTTP。
六、第五步:HTTP/JSON 网关——用 80 行让浏览器能调 tRPC
很多同学不知道:tRPC 服务完全可以同时承载 HTTP 流量。但 demo 里我故意没用框架的多协议支持,而是另起一个普通的 http.ServeMux 跑在 :8080,原因有三:
- 路由灵活——可以做
/api/books/{id}/borrow这种 RESTful 子动作 - 直接挂静态文件服务,前端文件零成本对接
- 复用同一个业务实例——不是再写一遍业务,而是直接把
impl当Handler调
关键是这个 Handler 接口:
type Handler interface {
ListBooks(ctx context.Context, req *pb.ListBooksReq) (*pb.ListBooksRsp, error)
GetBook(ctx context.Context, req *pb.GetBookReq) (*pb.Book, error)
CreateBook(ctx context.Context, req *pb.CreateBookReq) (*pb.Book, error)
UpdateBook(ctx context.Context, req *pb.UpdateBookReq) (*pb.Book, error)
DeleteBook(ctx context.Context, req *pb.DeleteBookReq) (*pb.DeleteBookRsp, error)
BorrowBook(ctx context.Context, req *pb.BorrowBookReq) (*pb.Book, error)
ReturnBook(ctx context.Context, req *pb.ReturnBookReq) (*pb.Book, error)
}
它的方法签名和 tRPC 自动生成的服务接口完全一致——*libraryServiceImpl 自动满足这个接口。这就是接口隔离原则在工程里的实际收益:网关包不依赖 main 包的具体类型,反向依赖被切断了。
业务码 → HTTP 状态码 的映射也是一处典型 trick:
func writeBizError(w http.ResponseWriter, err error) {
var e *errs.Error
if errors.As(err, &e) {
switch int(e.Code) {
case codeInvalidArgument: writeError(w, http.StatusBadRequest, e.Msg); return
case codeNotFound: writeError(w, http.StatusNotFound, e.Msg); return
case codeConflict: writeError(w, http.StatusConflict, e.Msg); return
}
}
writeError(w, http.StatusInternalServerError, err.Error())
}
七、调用链全景图
把上面六层串起来,一次"创建图书"的完整链路:
浏览器
│ POST /api/books body: {"title":"DDD","author":"Eric","stock":2}
▼
┌──────────────────────────────────────────────────────────────────┐
│ httpgw/gateway.go (HTTP 协议适配层) │
│ - json.Decode(req) │
│ - 调 impl.CreateBook(ctx, &req) │
│ - errs.Code → HTTP Status │
└──────────────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ library_service.go (业务规则层 ★) │
│ - TrimSpace 字段 │
│ - 必填项 / 范围校验 │
│ - 调 repo.Create │
│ - mapRepoError 翻译错误 │
│ - log.InfoContextf 记业务日志 │
└──────────────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ internal/repository/book_repo.go (持久化层 ★) │
│ - 加锁 │
│ - ISBN 唯一性检查 │
│ - 自增 ID + 写入 map │
└──────────────────────────────────────────────────────────────────┘
这就是为什么"业务代码到底写在哪"是新手最常问的问题——一旦理解了这三层的职责划分,任何 RPC 都能精准定位。
八、第六步:用真实仓储写单元测试
很多人写单元测试第一反应是 mock 一切。但本项目的内存仓储本身就是天然的 fake——纯内存、并发安全、几微秒就能 Create 一本书。所以测试夹具简单到一行:
func newTestService() *libraryServiceImpl {
return newLibraryServiceImpl(repository.NewMemoryBookRepo())
}
下面这条用例覆盖了 BorrowBook / ReturnBook 的全部分支,包括"库存不足"和"重复归还"两个边界:
func TestBorrowAndReturn(t *testing.T) {
svc := newTestService()
ctx := context.Background()
created, _ := svc.CreateBook(ctx, &pb.CreateBookReq{
Title: "X", Author: "Y", Isbn: "Z", Stock: 1,
})
borrowed, _ := svc.BorrowBook(ctx, &pb.BorrowBookReq{Id: created.Id})
if borrowed.Stock != 0 || borrowed.Borrowed != 1 {
t.Fatalf("counters wrong: stock=%d borrowed=%d",
borrowed.Stock, borrowed.Borrowed)
}
// 库存为 0 时再借应该被拒绝
if _, err := svc.BorrowBook(ctx, &pb.BorrowBookReq{Id: created.Id});
errs.Code(err) != codeConflict {
t.Fatalf("expected codeConflict on out-of-stock, got %v", err)
}
// 还书 → stock + 1, borrowed - 1
returned, _ := svc.ReturnBook(ctx, &pb.ReturnBookReq{Id: created.Id})
if returned.Stock != 1 || returned.Borrowed != 0 {
t.Fatalf("counters wrong: stock=%d borrowed=%d",
returned.Stock, returned.Borrowed)
}
// 没人借的时候再还,应该被拒绝
if _, err := svc.ReturnBook(ctx, &pb.ReturnBookReq{Id: created.Id});
errs.Code(err) != codeConflict {
t.Fatalf("expected codeConflict on duplicate return, got %v", err)
}
}
经验:业务层测试不要绕过 errs.Code() 直接
err != nil。错误码是接口的一部分,覆盖到错误码才能保证客户端能稳定区分错误类型。
跑起来:
go test ./...
九、第七步:写一个 tRPC 客户端验证"二进制协议链路"
光跑单测还不够,还要真的从外部用 tRPC 协议打一遍才能确认 stub、wire 协议、配置都对。这就是 cmd/client/main.go 的作用。
func newProxy() pb.LibraryServiceClientProxy {
return pb.NewLibraryServiceClientProxy(
client.WithTarget("ip://127.0.0.1:8000"),
client.WithProtocol("trpc"),
)
}
它做了一件比较克制的事——复用同一份 trpc_go.yaml:
cfg, _ := trpc.LoadConfig(trpc.ServerConfigPath)
trpc.SetGlobalConfig(cfg)
trpc.Setup(cfg)
这样客户端的日志、名字服务、过滤器配置都和服务端保持一致,避免出现"服务端有 trace、客户端没 trace"这种神坑。
main 里走了一条完整生命周期:
ListBooks (3 books) → CreateBook (DDD)
→ GetBook → BorrowBook → ReturnBook
→ UpdateBook → DeleteBook → ListBooks (3 books)
任何一步失败都直接 log.Fatalf——demo 的所有步骤都是上下游依赖关系,前一步失败后面没意义,不要在 demo 里写"宽容降级"。
启动方式:
# 终端 1
go run .
# 终端 2
go run cmd/client/main.go
输出大概长这样:
[ListBooks] 3 book(s) in catalog
- id=1 title="The Go Programming Language" stock=3 borrowed=0
- id=2 title="Clean Code" stock=5 borrowed=0
- id=3 title="Designing Data-Intensive Applications" stock=2 borrowed=0
[CreateBook] id=4 title="Domain-Driven Design" stock=2
[GetBook] id=4 author="Eric Evans"
[BorrowBook] stock=1 borrowed=1
[ReturnBook] stock=2 borrowed=0
[UpdateBook] title="Domain-Driven Design (Reference)" stock=3
[DeleteBook] ok=true
[ListBooks] catalog now has 3 book(s)
看到这一串,你就可以确信:proto stub、wire 协议、业务实现、配置加载,全链路打通。
十、踩过的坑 & 经验沉淀
坑 1:stub/ 用了独立 go.mod
为了给生成的 stub 一个稳定的 import path(git.code.oa.com/examples/library),我在 stub 目录里放了一份独立的 go.mod,然后在主项目用 replace 指过去。这样既不需要把生成代码 push 到内网仓库,也能让 import 路径"看起来很正经"。
坑 2:UpdateBook 不能改 borrowed
新手很容易顺手把 borrowed 也加进可改字段,结果就破坏了"借/还"两个 RPC 的不变量。让借还流程的写权限收敛在 BorrowBook/ReturnBook 里,哪怕代码看起来"重复",它换来的可维护性远大于写两个赋值。
坑 3:网关里的子动作路由
/api/books/{id}/borrow 这种"动词路径"用 http.ServeMux 处理时要自己解析后缀。我在 gateway 里用了 strings.Split + 长度判断而不是引第三方 router——demo 项目越简单越好,避免陡峭的依赖坡度。
坑 4:删除时的"孤儿数据"
DeleteBook 拒绝删除 borrowed > 0 的图书。这看起来是一条业务规则,其实是数据完整性。如果以后有"借阅记录表"指向 book_id,删图书等价于产生孤儿记录。业务层守住的不只是规则,还是数据约束。
坑 5:errs.Code() 与 HTTP 状态码不要直接相等
不要把 errs.New(404, msg) 写出来后期望 writeBizError 自动当 HTTP 404。业务码和 HTTP 状态码是两套语义,必须显式映射,不然会被框架内置错误码(比如 RetServerSystemErr)反向污染。
十一、把这套结构"放大"到生产项目
这个 demo 的目录结构其实就是一个很标准的 tRPC-Go 工程骨架,放大到生产项目几乎不需要改:
| demo 中的 | 生产中扩展为 |
|---|---|
internal/repository/book_repo.go(内存) |
internal/repository/mysql_book_repo.go、redis_book_repo.go,业务层无感 |
library_service.go |
拆分成 book_service.go / borrow_service.go,按聚合根切分 |
internal/httpgw/ |
改成 trpc 自带 HTTP 协议,或前置 nginx/网关 |
trpc_go.yaml 中的本地 IP |
接 Polaris 名字服务 + 配置中心 |
library_service_test.go |
增加 e2e 测试、压测脚本,用 library_mock.go 写跨服务联调 |
业务码 10001/10002/10003 |
在公司错误码规范里申请正式区段,单独维护 errs.go |
骨架本身不用动——这就是接口隔离 + 依赖注入带来的复利。
十二、总结:一份 tRPC-Go 工程的最小可读样本
回过头看,这个图书管理 demo 想传达的工程价值就三句话:
- proto 是契约——契约写好了,跨语言、跨团队的协作几乎是免费的。
- 业务层只关心业务规则——参数校验、不变量、错误码翻译,存储一律下沉。
- 存储用接口隔离——这是从"能跑的 demo"升级成"能上线的服务"最关键的一刀。
如果你正在学 tRPC-Go,建议你亲手把这个项目敲一遍,比看十篇框架介绍都有用。Happy hacking 🚀
📦 项目源码结构:
trpc/library/
📍 启动命令:go run .+ 浏览器打开http://127.0.0.1:8080
🧪 测试命令:go test ./...
🤝 客户端 demo:go run cmd/client/main.go

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)