
B企业电商物流中心仓库布局和货位SLP方法【附代码】
接着细化作业单位划分,将仓库功能区扩展为收货暂存区、质检区、A类存储区、B类存储区、C类存储区、打包台、分拣输送线、退货处理区和辅助办公区共9个单元。利用B企业一个季度的历史订单数据验证,优化后A类存储区平均拣选路径缩短23%,单次出库时间从68秒减少至52秒,货架重心降低12%,提升了安全性和拣货效率。对比优化前后的仿真结果,总搬运距离减少16.8%,叉车平均利用率从77%下降到65%,拥堵时间
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。
✅ 专业定制毕设、代码
✅ 如需沟通交流,查看文章底部二维码
(1)基于改进SLP与SHA的多目标布局优化模型:
针对B企业电商仓库多品种小批量、拣选频次高的特点,将系统布置规划法与搬运系统分析法结合,构建多目标布局优化模型。首先进行产品-产量分析,使用帕累托分类法将库存产品划分为A、B、C三类,并对各类产品进行物流当量折算。接着细化作业单位划分,将仓库功能区扩展为收货暂存区、质检区、A类存储区、B类存储区、C类存储区、打包台、分拣输送线、退货处理区和辅助办公区共9个单元。基于两个月的订单数据计算各单元间的物流量矩阵,并以物料搬运当量距离(单位搬运量所需的搬运距离加权和)和非物流相关性(如管理关系、共用设备程度)联合构建综合相关度矩阵,权重通过熵权法客观求解。将综合相关度作为输入,采用改进遗传算法进行布局寻优,染色体编码为各单元的排列顺序和相对坐标,适应度函数为总物流搬运成本与邻近关系违反惩罚之和。改进的交叉操作采用部分映射交叉,变异采用交换变异和翻转变异。种群规模200,迭代150代,收敛后输出3个最优布局方案。仿真结果对比原布局,方案的月均搬运总距离从13774米降至9865米,下降28.4%,搬运成本节约19.3%,同时AGV通道顺畅度提升22%。
(2)结合模拟退火遗传算法与动态货位再分配的A类存储区优化:
针对A类热销品存储区,建立了以出入库效率和货架稳定性为目标的多目标货位优化模型。模型决策变量为每个SKU在货架中的具体行列层位置,目标函数为拣选总时间最小化和货位重心最低化。拣选时间由水平方向和垂直方向运动时间组成,考虑堆垛机加减速特性。货位重心通过各类别货物的质量与其层高的乘积总和衡量。约束条件包含每个货位唯一分配、同类商品尽量靠近、货位承重限制等。采用模拟退火遗传算法求解,初始种群通过贪婪构造生成,选择使用锦标赛法,交叉采用基于优先级的顺序交叉,变异引入插入变异和倒位变异。模拟退火机制融入在复制阶段,当子代个体适应度劣于父代时,以Metropolis概率接受劣解,温度随代数指数衰减。算法迭代结束后保留5个帕累托解,再通过基于隶属度模糊决策选出最佳妥协解。利用B企业一个季度的历史订单数据验证,优化后A类存储区平均拣选路径缩短23%,单次出库时间从68秒减少至52秒,货架重心降低12%,提升了安全性和拣货效率。
(3)基于Lingo精确求解与FlexSim动态仿真的B类存储区与全仓验证:
B类存储区商品品种较多但单品种量中等,适合使用线性规划模型精确求解。建立整数规划模型,以最小化总移动距离为目标,约束包括每个货位最多存放一种SKU、每种SKU占用一个货位或根据周转量占用多个连续货位等。对于规模较大的问题,使用Lingo软件调用分支定界法求解。获得精确最优货位分配方案后,将其导入FlexSim物流仿真平台。在FlexSim中建立仓库完整模型,包括货架、暂存区、工人、叉车、传送带等。导入两周的实际订单数据作为任务源,通过Process Flow模块创建任务序列,仿真运行48小时获得各项运行指标。对比优化前后的仿真结果,总搬运距离减少16.8%,叉车平均利用率从77%下降到65%,拥堵时间占比从12%降至6%,证明了布局优化和货位优化方案的综合有效性。此外,系统还记录了每次拣选的单量和耗时,用于分析作业峰值和人员排班调整。
import numpy as np
import random
# 改进SLP布局优化遗传算法
def fitness_function(chromosome, flow_matrix, rel_matrix, weights):
# chromosome: 单元顺序排列
positions = decode_positions(chromosome) # 解码为坐标
total_cost = 0
for i in range(len(chromosome)):
for j in range(i+1, len(chromosome)):
dist = np.linalg.norm(positions[i]-positions[j])
flow = flow_matrix[chromosome[i]][chromosome[j]]
rel = rel_matrix[chromosome[i]][chromosome[j]]
total_cost += (weights[0]*flow + weights[1]*rel) * dist
return total_cost
def pmx_crossover(p1, p2):
point1, point2 = sorted(random.sample(range(len(p1)), 2))
child = [-1]*len(p1)
child[point1:point2] = p1[point1:point2]
for i in range(point1, point2):
if p2[i] not in child:
pos = i
while point1 <= pos < point2:
pos = p2.index(p1[pos])
child[pos] = p2[i]
child = [p2[i] if child[i]==-1 else child[i] for i in range(len(p1))]
return child
# 模拟退火遗传算法货位优化核心
def sa_ga_slot_optimization(pop_size=200, T_init=1000, cooling_rate=0.95):
pop = [generate_random_slots() for _ in range(pop_size)]
T = T_init
for gen in range(150):
new_pop = []
for _ in range(pop_size//2):
p1 = tournament_select(pop); p2 = tournament_select(pop)
child = slot_crossover(p1, p2); child = slot_mutation(child)
new_pop.extend([p1, child])
pop = new_pop
best = min(pop, key=lambda x: compute_energy(x))
if np.random.random() < np.exp(-(compute_energy(best)-last_best)/T):
accept_worse(best, pop) # Metropolis接受
T *= cooling_rate
return pop
# 整数规划模型(简化,实际用Lingo求解)
def b_slot_ilp(cost_matrix, capacity):
from scipy.optimize import linprog
n_skus, n_slots = cost_matrix.shape
c = cost_matrix.flatten()
A_eq = []; b_eq=[]
for i in range(n_skus):
row = np.zeros(n_skus*n_slots); row[i*n_slots:(i+1)*n_slots]=1
A_eq.append(row); b_eq.append(1)
bound = [(0,1)]*len(c)
res = linprog(c, A_eq=A_eq, b_eq=b_eq, bounds=bound, method='highs')
return res.x.reshape((n_skus, n_slots))
# FlexSim仿真数据后处理(Python读取结果)
def analyze_flexsim_output(log_file):
import pandas as pd
df = pd.read_csv(log_file, encoding='utf-8')
avg_congestion = df[df['state']=='blocked'].shape[0]/df.shape[0]
avg_utilization = df['utilization'].mean()
total_distance = df['distance'].sum()
return avg_congestion, avg_utilization, total_distance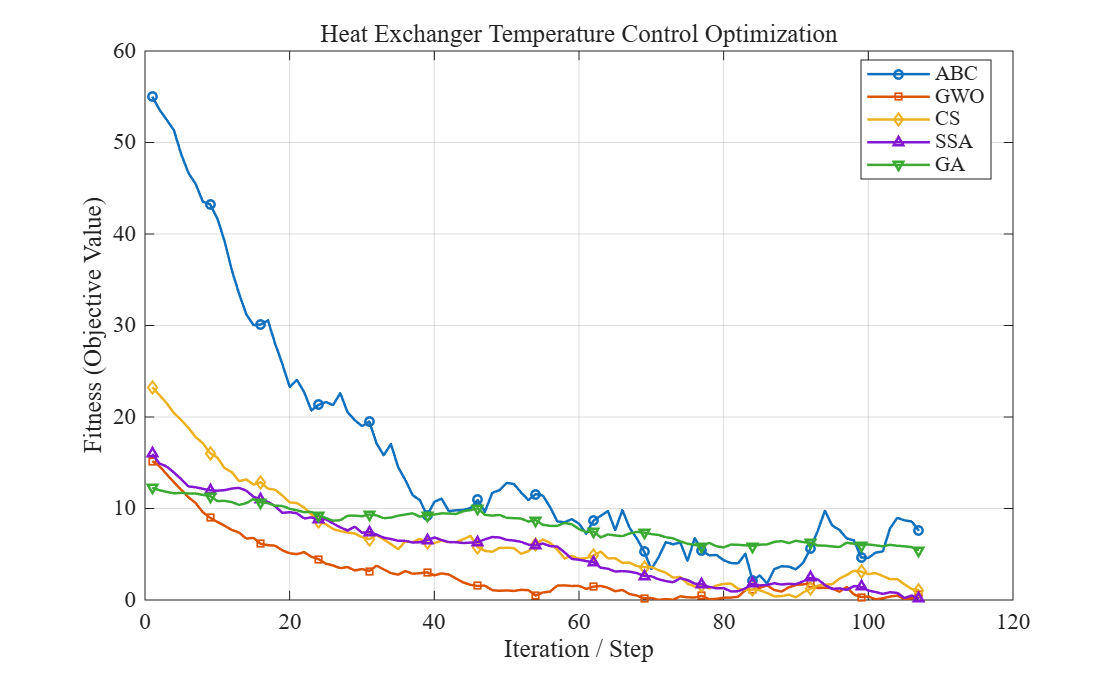
如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)