
京东热点缓存探测系统JDHotkey架构深度剖析:多级缓存在亿级流量场景下的最佳实践
多级缓存与热点探测系统架构解析 本文系统阐述了多级缓存架构和热点探测系统的设计原理与实践方案。多级缓存通过本地+远程缓存组合,显著降低高并发场景下的访问延迟,但需注意数据一致性和容量限制问题。热点探测作为系统"体温计",通过滑动窗口计数等算法实时识别突发流量,预防缓存击穿和数据库雪崩。文章深度解析了京东JDHotkey系统的三层架构(客户端-Worker-Server),涵盖关
一、多级缓存:从理论到实践
1. 为什么需要多级缓存?
在高并发场景下,单纯的远程缓存(如Redis)已无法满足极致性能要求。多级缓存架构应运而生:
本地缓存的优势:
-
✅ 减少网络请求:数据在进程内直接访问,延迟降至纳秒级
-
✅ 天然分布式缓存:每个实例独立缓存,分散压力
-
✅ 保护远程缓存:降低Redis等中间件的读压力
本地缓存的挑战:
-
❌ 容量限制:受JVM堆内存制约,无法存储大数据量
-
❌ 数据易失:进程重启导致缓存丢失
-
❌ 一致性问题:分布式环境下各节点数据可能不一致
-
❌ 与远程缓存不一致:需要额外的同步机制
2. 多级缓存适用场景
| 场景 | 示例 | 缓存策略 |
|---|---|---|
| 热点商品详情页 | 双11爆款商品 | 本地缓存 + Redis + DB |
| 实时热搜榜 | 微博热搜TOP10 | 本地缓存 + Redis定时更新 |
| 热门帖子/文章 | 知乎热门回答 | 本地缓存 + 分级过期 |
| 高频用户数据 | 头部主播用户信息 | 进程缓存 + 监听更新 |
核心原则:只有高并发、热点集中的场景才需要引入多级缓存。过度设计会增加系统复杂度和维护成本。
二、热点探测:系统的"体温计"
1. 什么是热点?
热点数据具备两个核心特征:
-
时间有限性:在特定时间段内集中出现
-
流量高聚集:访问量远超平均值
热点分类:
// 1. 有预期的热点(可预知)
public class ExpectedHotspot {
// 电商活动:双11爆款商品
// 秒杀场景:限量商品抢购
// 营销活动:红包雨、抽奖
}
// 2. 无预期的热点(突发性)
public class UnexpectedHotspot {
// 黑客攻击:CC攻击、爬虫
// 突发事件:明星离婚、重大新闻
// 系统异常:缓存穿透、雪崩
}
2. 热点探测的核心价值
数据层风险防控:
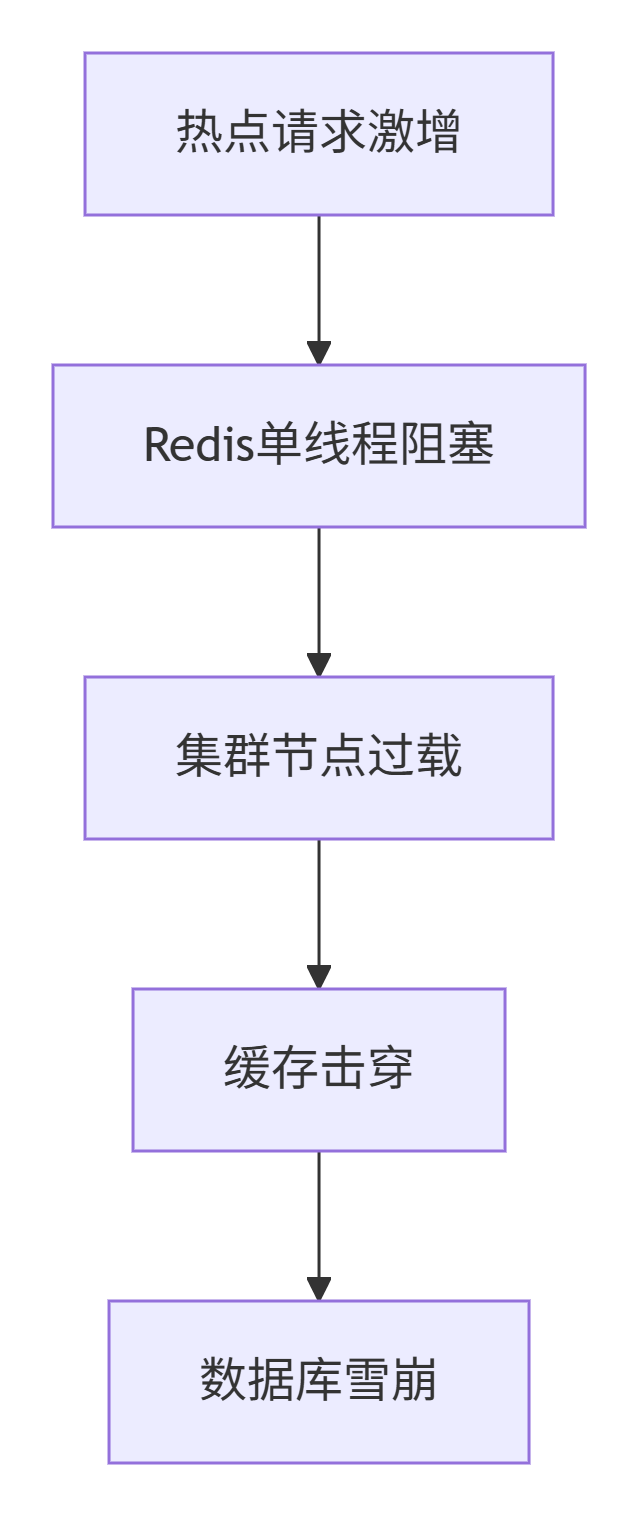
应用层风险防控:
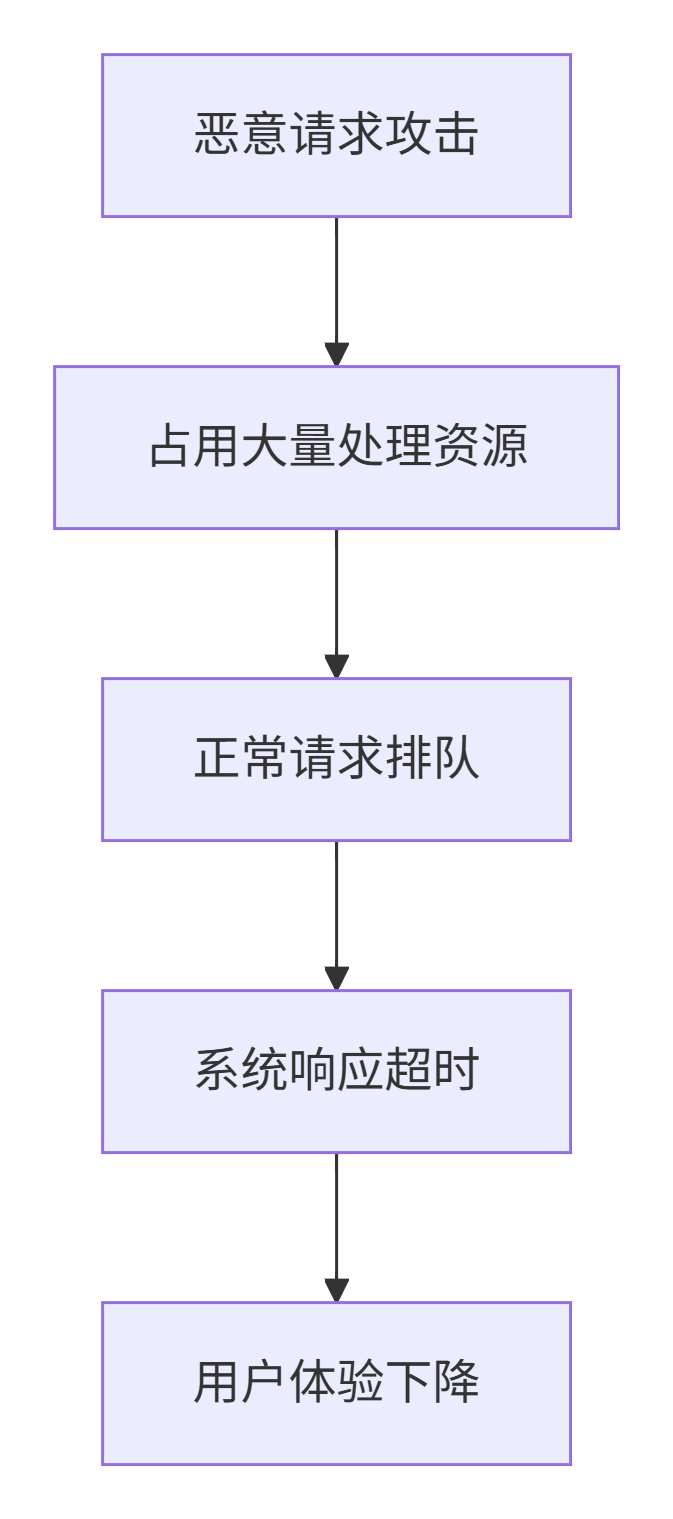
热点探测的价值矩阵:
| 风险类型 | 无热点探测 | 有热点探测 |
|---|---|---|
| 缓存击穿 | 概率高 | 概率低 |
| 数据库雪崩 | 可能发生 | 有效避免 |
| 恶意攻击 | 难以防御 | 及时发现 |
| 系统弹性 | 较差 | 良好 |
三、热点探测系统架构设计
1. 核心设计原则
5大设计目标:
-
实时性:毫秒级热点识别
-
准确性:低误报、低漏报
-
可扩展性:支持水平扩容
-
低侵入性:业务改造成本低
-
高可用性:故障自动恢复
2. 单机热点探测实现
/**
* 滑动窗口计数器实现
*/
public class SlidingWindowCounter {
// 时间窗口:1秒
private static final long WINDOW_SIZE_MS = 1000;
// 窗口分片数:10个(每100ms一个分片)
private static final int SHARD_COUNT = 10;
// 环形数组存储计数器
private final AtomicLongArray[] counters;
// 当前时间索引
private final AtomicInteger currentIndex = new AtomicInteger(0);
public SlidingWindowCounter() {
counters = new AtomicLongArray[SHARD_COUNT];
for (int i = 0; i < SHARD_COUNT; i++) {
counters[i] = new AtomicLongArray(10000); // 支持最多10000个key
}
}
/**
* 记录访问
* @param keyHash key的哈希值
* @return 当前窗口内的访问次数
*/
public long recordAndGet(int keyHash) {
long currentTime = System.currentTimeMillis();
int timeIndex = (int) ((currentTime / 100) % SHARD_COUNT);
// 清空过期的分片
if (timeIndex != currentIndex.get()) {
counters[timeIndex].set(keyHash, 0);
currentIndex.set(timeIndex);
}
// 累加计数
long count = counters[timeIndex].incrementAndGet(keyHash);
// 计算窗口内总次数
long total = 0;
for (int i = 0; i < SHARD_COUNT; i++) {
total += counters[i].get(keyHash);
}
return total;
}
}
/**
* 单机热点探测器
*/
public class LocalHotspotDetector {
// 热点阈值:1秒内访问1000次
private static final long HOT_THRESHOLD = 1000;
private final SlidingWindowCounter counter;
private final ConcurrentHashMap<String, Boolean> hotspotKeys;
public LocalHotspotDetector() {
this.counter = new SlidingWindowCounter();
this.hotspotKeys = new ConcurrentHashMap<>();
}
public boolean detect(String key) {
int hash = Math.abs(key.hashCode()) % 10000;
long count = counter.recordAndGet(hash);
if (count >= HOT_THRESHOLD) {
hotspotKeys.putIfAbsent(key, true);
return true;
}
return false;
}
}
3. 分布式热点探测架构
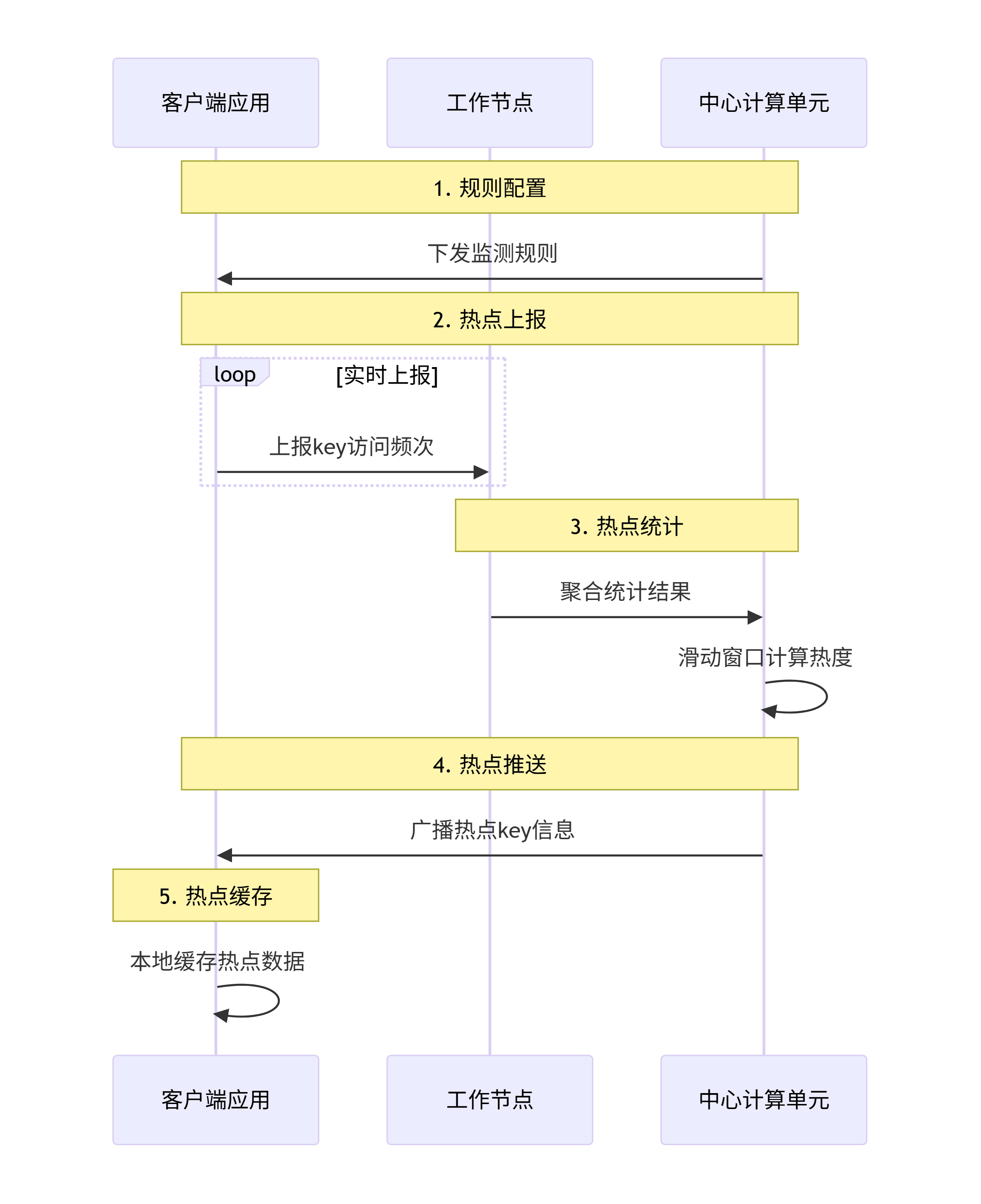
五步核心流程:
四、京东JDHotkey系统深度解析
1. 系统架构概览
JDHotkey系统架构:
┌─────────────────────────────────────────────┐
│ 客户端应用集群 │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │App 1 │ │App 2 │ │App 3 │ │App N │ │
│ └──┬───┘ └──┬───┘ └──┬───┘ └──┬───┘ │
└─────┼─────────┼─────────┼─────────┼───────┘
│上报 │上报 │上报 │上报
▼ ▼ ▼ ▼
┌─────────────────────────────────────────────┐
│ Worker工作节点集群 │
│ 负责接收、聚合、转发上报数据 │
└───────────────────┬─────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Server中心节点 │
│ 核心计算单元,进行热点判断和规则管理 │
└───────────────────┬─────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ 存储层 │
│ 规则配置、热点历史、监控数据 │
└─────────────────────────────────────────────┘
2. 核心组件设计
客户端SDK
/**
* JDHotkey客户端核心类
*/
public class JDHotkeyClient {
// 配置管理器
private ConfigManager configManager;
// 上报器
private Reporter reporter;
// 本地缓存
private LocalCache localCache;
// 热点监听器
private HotspotListener listener;
/**
* 初始化客户端
*/
public void init() {
// 1. 拉取配置规则
HotspotRule rule = configManager.fetchRule();
// 2. 启动上报线程
reporter.start(rule.getReportInterval());
// 3. 注册监听器
listener.register(this::onHotspotDetected);
}
/**
* 处理数据访问
*/
public <T> T get(String key, Supplier<T> loader) {
// 1. 检查本地缓存
T value = localCache.get(key);
if (value != null) {
return value;
}
// 2. 统计访问频次
reporter.report(key);
// 3. 加载数据
value = loader.get();
// 4. 如果是热点,加入本地缓存
if (listener.isHotspot(key)) {
localCache.put(key, value);
}
return value;
}
/**
* 热点回调处理
*/
private void onHotspotDetected(HotspotEvent event) {
for (String key : event.getHotKeys()) {
// 预加载热点数据到本地缓存
preloadToLocalCache(key);
}
}
}
Worker工作节点
/**
* 工作节点核心逻辑
*/
public class HotspotWorker {
// 数据接收器
private DataReceiver receiver;
// 数据聚合器
private DataAggregator aggregator;
// 数据发送器
private DataSender sender;
/**
* 处理上报数据
*/
public void process(ReportData data) {
// 1. 数据预处理
PreprocessedData preprocessed = preprocess(data);
// 2. 时间窗口聚合
AggregatedResult result = aggregator.aggregate(preprocessed);
// 3. 发送到Server节点
sender.send(result);
}
/**
* 数据预处理
*/
private PreprocessedData preprocess(ReportData data) {
// 数据清洗、去重、格式转换
return new PreprocessedData(data);
}
}
Server中心节点
/**
* Server节点热点判断引擎
*/
public class HotspotEngine {
// 滑动窗口管理器
private SlidingWindowManager windowManager;
// 规则引擎
private RuleEngine ruleEngine;
// 通知服务
private NotificationService notificationService;
/**
* 判断是否为热点
*/
public HotspotDecision decide(String key, long count, long timestamp) {
// 1. 获取历史数据
HistoricalData history = windowManager.getHistory(key);
// 2. 应用规则
RuleResult ruleResult = ruleEngine.apply(key, count, history);
// 3. 生成决策
HotspotDecision decision = new HotspotDecision();
decision.setHot(ruleResult.isHot());
decision.setConfidence(ruleResult.getConfidence());
// 4. 如果是热点,广播通知
if (decision.isHot()) {
notificationService.broadcast(new HotspotNotification(key));
}
return decision;
}
}
3. 关键技术实现
滑动窗口算法优化
public class OptimizedSlidingWindow {
// 使用环形缓冲区避免内存复制
private final CircularBuffer<WindowSlot> buffer;
// 使用LongAdder替代AtomicLong提高并发性能
private final LongAdder[] counters;
// 使用布隆过滤器减少内存占用
private final BloomFilter<String> bloomFilter;
public void optimize() {
// 1. 时间分片压缩
// 2. 数据采样(对于超大数据集)
// 3. 冷热数据分离
// 4. 增量计算
}
}
通信协议设计
// 使用Protobuf定义通信协议
syntax = "proto3";
message HotspotReport {
string app_id = 1;
repeated KeyCounter counters = 2;
int64 timestamp = 3;
}
message KeyCounter {
string key = 1;
int64 count = 2;
int32 hash = 3;
}
message HotspotNotification {
repeated string hot_keys = 1;
int64 detect_time = 2;
int32 ttl = 3; // 热点持续时间
}
五、生产环境最佳实践
1. 部署架构建议
生产环境部署方案:
┌─────────────────────────────────────────────────────┐
│ 负载均衡层 (Nginx) │
└───────────────┬──────────────────┬──────────────────┘
│ │
┌───────▼──────┐ ┌───────▼──────┐
│ Worker集群 │ │ Worker集群 │
│ 区域A │ │ 区域B │
└───────┬──────┘ └───────┬──────┘
│ │
┌───────▼──────────────────▼──────┐
│ Server主备集群 │
│ (异地多活部署) │
└───────┬──────────────────┬──────┘
│ │
┌───────▼──────┐ ┌───────▼──────┐
│ MySQL主库 │ │ MySQL从库 │
│ (配置存储) │ │ (数据同步) │
└──────────────┘ └──────────────┘
2. 配置调优指南
# application-hotspot.yml
jdhotkey:
client:
enabled: true
app-name: "order-service"
# 上报配置
report:
interval: 1000 # 上报间隔(ms)
batch-size: 100 # 批量上报大小
queue-size: 10000 # 队列容量
# 缓存配置
cache:
local:
type: "caffeine"
maximum-size: 10000
expire-after-write: 300s
# 规则配置
rules:
- pattern: "goods:*"
threshold: 1000 # 1秒内访问次数
window-size: 10s # 时间窗口
action: "local_cache" # 处理动作
server:
worker-threads: 32
aggregation-interval: 500ms
notification-timeout: 2000ms
3. 监控告警体系
/**
* 监控指标收集
*/
@RestController
public class MonitorController {
@Autowired
private MeterRegistry meterRegistry;
@GetMapping("/metrics/hotspot")
public Map<String, Object> getMetrics() {
return Map.of(
"detect_rate", meterRegistry.counter("hotspot.detect.count").count(),
"false_positive", meterRegistry.counter("hotspot.false.positive").count(),
"notification_latency", meterRegistry.timer("hotspot.notify.latency").mean(),
"cache_hit_rate", meterRegistry.gauge("hotspot.cache.hit.rate", 0.95)
);
}
/**
* 关键告警规则
*/
@Component
public class AlertRule {
// 1. 热点误报率 > 5%
// 2. 通知延迟 > 1秒
// 3. 内存使用率 > 80%
// 4. 队列积压 > 1000
}
}
六、二次开发与扩展
1. 自定义规则引擎
/**
* 自定义热点规则
*/
public class CustomHotspotRule implements HotspotRule {
@Override
public boolean isHot(String key, HotspotContext context) {
// 1. 基础频率判断
boolean frequencyHot = context.getCount() > 1000;
// 2. 趋势判断(环比增长)
boolean trendHot = context.getGrowthRate() > 5.0;
// 3. 业务权重(VIP用户访问权重更高)
boolean businessHot = isVipUserAccess(key) && context.getCount() > 500;
return frequencyHot || trendHot || businessHot;
}
private boolean isVipUserAccess(String key) {
// 解析key中的用户信息
return key.contains("vip_");
}
}
2. 集成现有系统
/**
* 与Spring Cache集成
*/
@Configuration
public class HotspotCacheConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
// 包装原有CacheManager
return new HotspotAwareCacheManager(cacheManager);
}
}
/**
* 热点感知的CacheManager
*/
public class HotspotAwareCacheManager implements CacheManager {
private final CacheManager delegate;
private final JDHotkeyClient hotkeyClient;
@Override
public Cache getCache(String name) {
Cache cache = delegate.getCache(name);
return new HotspotAwareCache(cache, hotkeyClient);
}
}
3. 扩展存储支持
/**
* 支持多种存储后端
*/
public interface HotspotStorage {
void save(HotspotRecord record);
List<HotspotRecord> query(HotspotQuery query);
}
// Redis实现
@Component
@ConditionalOnProperty(name = "hotspot.storage.type", havingValue = "redis")
public class RedisHotspotStorage implements HotspotStorage {
// Redis存储实现
}
// Elasticsearch实现(用于历史分析)
@Component
@ConditionalOnProperty(name = "hotspot.storage.type", havingValue = "elasticsearch")
public class ESHotspotStorage implements HotspotStorage {
// ES存储实现
}
七、总结与展望
JDHotkey系统的核心价值
-
实时性:毫秒级热点发现,抢占处理先机
-
准确性:多层次验证,降低误报率
-
扩展性:支持千万级key的监控
-
易用性:低侵入集成,快速上线
未来演进方向
-
AI智能预测:基于历史数据的机器学习预测
-
边缘计算:在CDN边缘节点进行热点预处理
-
多云适配:支持混合云、多云部署
-
生态集成:与Service Mesh、API网关深度集成
实施建议
对于计划引入热点探测系统的团队,建议:
-
渐进式推进:
阶段1:监控观察 → 阶段2:规则预警 → 阶段3:自动处理
-
场景优先:
-
优先保护核心业务(交易、支付)
-
重点监控高价值数据(库存、价格)
-
-
容量规划:
-
根据业务峰值设计系统容量
-
预留30%的buffer应对突发流量
-
热点数据管理是构建高可用系统的核心能力之一。JDHotkey系统代表了京东在应对亿级流量挑战上的最佳实践。通过合理的架构设计和精细化的运营,热点数据可以从系统风险转化为性能优势。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)