
八爪鱼 RPA 实战复盘:从淘宝首页到连衣裙数据表,我是如何一步步抓到完整商品信息的
本文通过八爪鱼RPA工具实现了淘宝电商数据的自动化采集实战。作者以"连衣裙"为关键词,完整模拟用户搜索行为,依次完成淘宝首页访问、商品列表页采集和详情页补充数据,最终输出结构化Excel表格。核心经验包括:RPA能有效规避反爬机制、网页对象管理是复杂流程关键、数据价值在于可分析性。该方案不仅验证了可视化RPA的可行性,更提供了可直接用于选品分析的真实业务数据,为电商数据采集提供
关键词:八爪鱼 RPA|淘宝爬虫|电商数据采集|连衣裙选品|自动化实战
一、背景说明:我为什么要做这个爬虫?
最近在学习 八爪鱼 RPA,我给自己定了一个目标:
不用代码,只靠可视化 RPA,完整跑通一次「真实电商网站的数据采集流程」
最终选择了一个非常典型、也非常有实战价值的场景:
- 网站:淘宝
- 场景:首页搜索
- 关键词:连衣裙
- 目标:
👉 抓取商品列表 + 商品详情
👉 最终导出结构化 Excel 数据
这篇文章就是一次完整实操后的技术复盘。
二、整体流程总览(先看全局)
这次的八爪鱼流程,我可以概括为 5 个关键阶段:
- 打开淘宝首页,模拟真实用户操作
- 搜索关键词「连衣裙」,进入商品列表页
- 在列表页中批量采集商品基础信息
- 进入商品详情页,补充深度字段
- 汇总数据,导出为 Excel 表格
这不是“随便点点”,而是完整的用户路径模拟 + 数据采集闭环。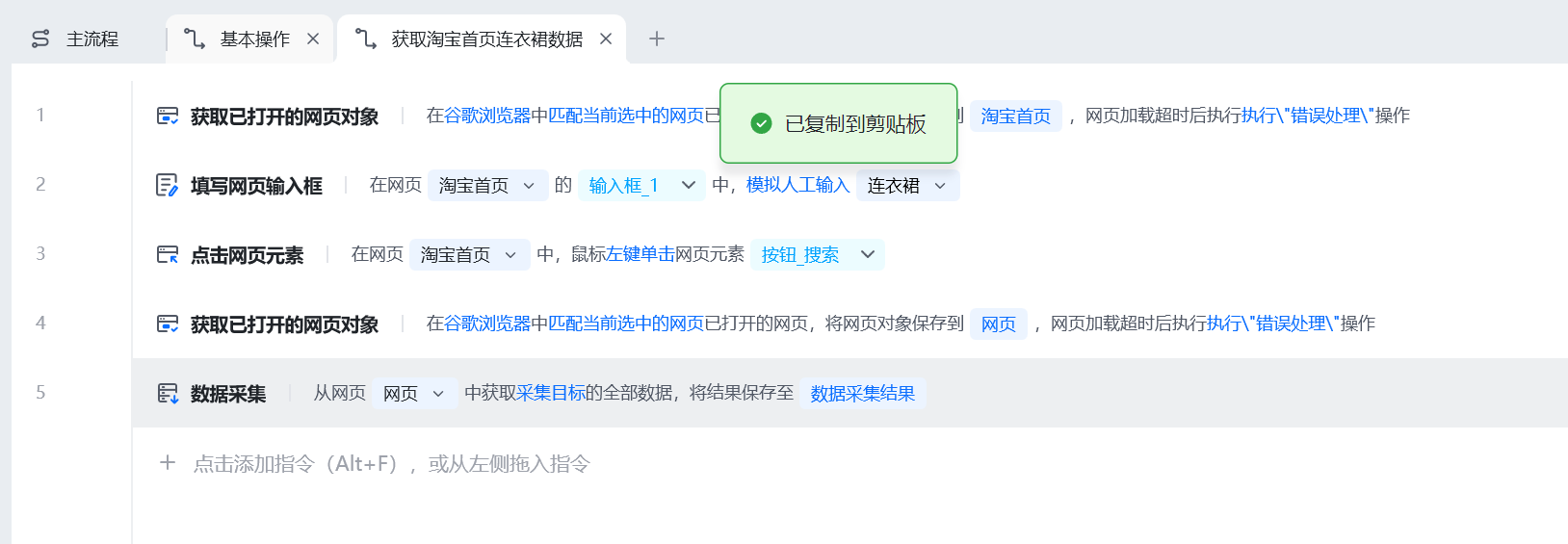
三、关键操作复盘(核心步骤拆解)
1️⃣ 打开网页 & 模拟搜索行为
在八爪鱼中,我首先做的是:
- 打开浏览器(Chrome)
- 访问淘宝首页
- 定位搜索输入框
- 模拟人工输入:
连衣裙 - 点击【搜索】按钮
这一点非常关键。
📌 为什么不直接请求列表页 URL?
因为:
- 淘宝反爬严格
- 直接请求容易被拦
- RPA 模拟真实用户,成功率更高
👉 这一步,本质是:
用 RPA 复刻一个真实用户的搜索行为
2️⃣ 获取网页对象,固定操作上下文
在流程中,多次使用了:
获取已打开的网页对象
这一步看似简单,其实非常“专业”。
它的作用是:
- 锁定当前页面上下文
- 确保后续所有元素操作、数据采集,都发生在“正确页面”
- 避免页面跳转后元素失效
📌 经验总结:
页面一旦发生跳转,一定要重新获取网页对象
3️⃣ 列表页数据采集(最核心的一步)
进入搜索结果页后,我使用了八爪鱼的:
数据采集节点(重复结构识别)
八爪鱼会自动识别:
- 每一个商品卡片 = 一条数据记录
并批量采集了以下字段(从最终 Excel 可验证):
商品基础字段包括:
- 商品标题
- 商品类型(连衣裙)
- 款式特征(V 领 / 高腰 / 收腰 / 无袖等)
- 季节属性(春夏 / 秋冬 / 四季)
- 商品价格
- 付款人数
- 发货地(省 / 市)
- 是否包邮
- 店铺名称
- 店铺类型(旗舰店 / ifashion / 退货宝等)
📌 到这一步,其实已经完成了 80% 的电商数据采集需求。
4️⃣ 进入商品详情页,采集更高价值信息
为了让数据更有“商业价值”,我并没有只停留在列表页。
而是进一步:
-
抓取商品详情页链接
-
在新标签页中打开商品详情页
-
采集:
- 商品详情地址
- 商品图片属性(如 width)
- 更完整的商品描述信息
📌 经验总结:
列表页适合做“量化分析”
详情页才是做“选品、分析、AI 训练”的关键
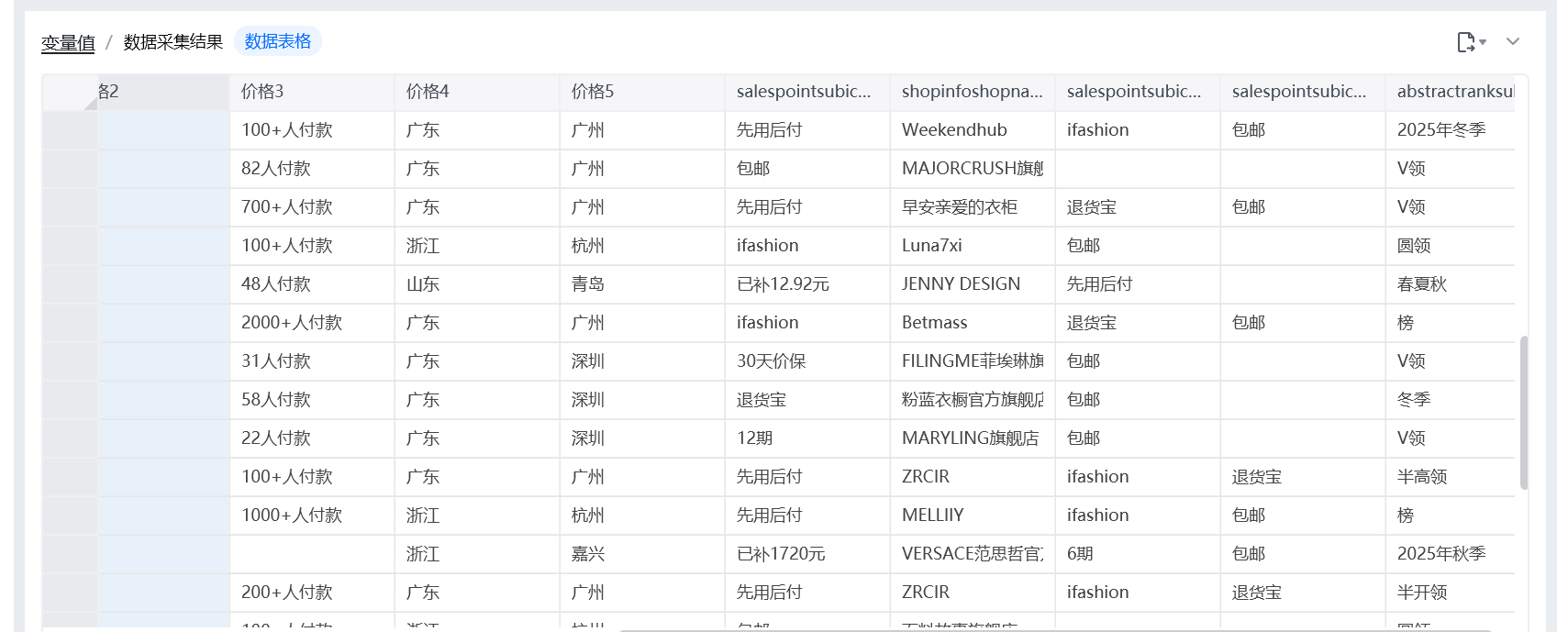
四、最终成果:我抓到了什么数据?
最终导出的 Excel,已经是一个结构化的淘宝连衣裙商品数据表:
-
每一行 = 一个商品
-
每一列 = 一个明确字段
-
数据可直接:
- 用于选品分析
- 做价格区间统计
- 研究爆款特征
- 作为 AI 训练样本
这已经不再是“练习数据”,而是:
具备真实业务分析价值的数据样本
五、这次实操给我的 3 个关键收获
✅ 1. RPA 非常适合“强反爬网站”
淘宝这种网站,用传统爬虫成本极高
但 RPA + 浏览器自动化,反而稳定、直观。
✅ 2. “网页对象”是复杂流程的核心
只要流程一复杂:
- 翻页
- 跳转
- 新标签页
👉 网页对象管理 = 是否稳定运行的关键
✅ 3. 数据采集的终点不是“抓到”,而是“能用”
当你能把数据:
- 结构化
- 落表
- 可分析
这套流程才真正“值钱”。
六、结语
这次八爪鱼 RPA 的实战,让我真正理解了一点:
爬虫不是技术炫技,而是“把真实世界的数据,转成可决策的信息”。
后续我也会继续基于这套流程:
- 尝试翻页采集
- 增加筛选条件
- 甚至接入 AI 做自动分析

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)