
1688 平台店铺全商品接口技术实现:从店铺页解析到分页采集全方案
本文系统阐述了1688店铺全商品数据采集的技术方案,重点解决店铺ID解析、多页数据采集和品类筛选等核心问题。方案包含店铺信息解析器、商品分页参数生成器、请求调度器和数据解析器等组件,支持按分类采集商品并处理批发价、起订量等B端特色字段。通过控制请求频率(单店铺间隔15秒)、采用代理轮换和会话保持等策略应对反爬限制,严格遵循平台数据采集规范。该技术方案为供应链分析和竞品调研提供数据支持,但强调必须获
1688 店铺商品数据是供应链分析、竞品调研的重要基础,包含店铺所有商品的批发价、起订量、品类分布等核心信息。与单商品接口不同,店铺全商品接口需要处理分页加载、品类筛选、防反爬限制等特殊问题。本文系统讲解 1688 店铺所有商品接口的技术实现,重点解决店铺 ID 解析、多页数据采集、品类筛选等核心问题,提供一套合规、高效的技术方案,严格遵循平台规则与数据采集规范。
一、1688 店铺商品接口架构与合规要点
1688 店铺商品数据通过 "店铺首页→商品列表页→分页加载" 的层级架构展示,核心接口为店铺商品列表分页接口,支持按品类、销量等维度筛选。实现需遵守以下合规要点:
- 请求频率控制:单店铺采集时,页面请求间隔不低于 15 秒,单店铺单日最多采集 3 次
- 数据范围限制:仅采集公开的商品信息,不涉及店铺交易数据、客户信息等隐私内容
- 商业用途合规:数据仅用于市场调研,不得用于恶意竞争或商业诋毁
- 反爬机制尊重:不伪造请求头或破解接口加密,模拟正常用户浏览行为
店铺全商品采集核心技术流程:
plaintext
店铺ID解析 → 首页品类提取 → 分页参数构造 → 分布式请求调度 → 数据解析与去重 → 结构化存储
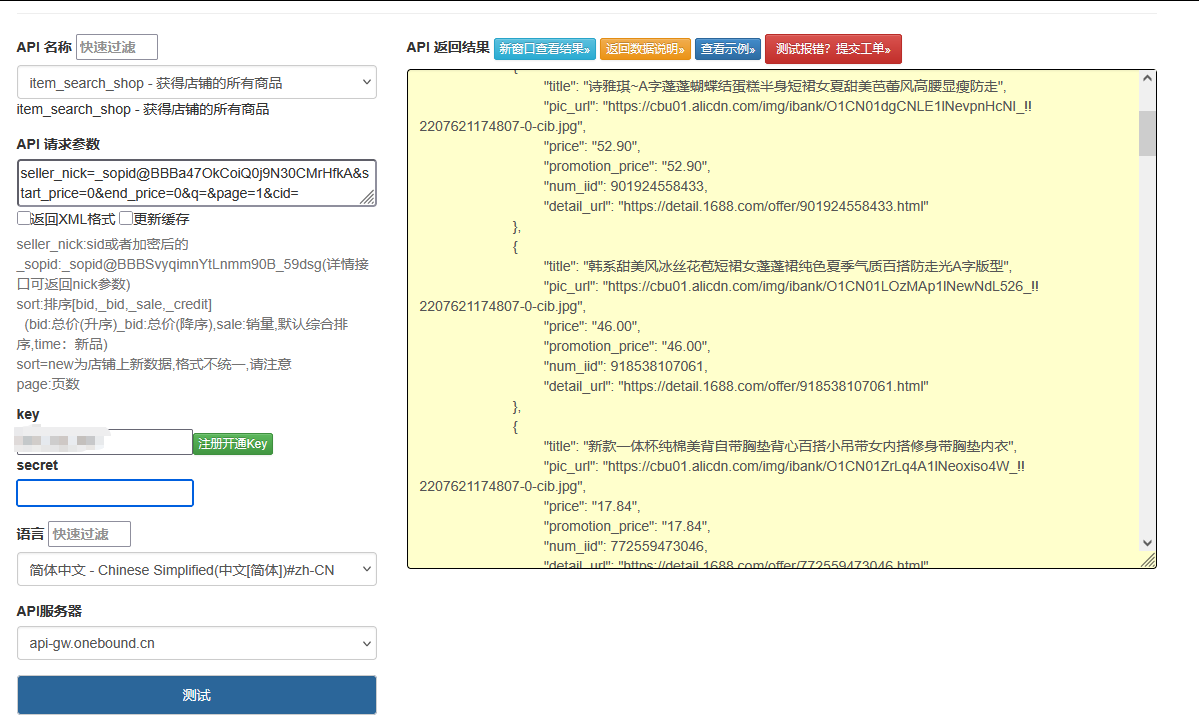
点击获取key和secret
二、核心技术实现
1. 店铺 ID 与信息解析器(适配 1688 店铺 URL 特色)
1688 店铺 URL 格式多样,需从不同格式的 URL 中解析店铺 ID(memberId),并提取基础信息:
python
运行
import re
import requests
from lxml import etree
class AlibabaShopParser:
"""1688店铺信息与ID解析器"""
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "https://www.1688.com/"
}
# 店铺URL匹配模式
self.shop_patterns = [
r"https?://(\w+)\.1688\.com", # 主域名模式:https://abc123.1688.com
r"https?://shop(\d+)\.1688\.com", # 数字ID模式:https://shop123456789.1688.com
r"https?://www\.1688\.com/shop/view_shop\.htm\?memberId=(\w+)" # 标准店铺页
]
def extract_shop_id(self, shop_url):
"""从店铺URL提取memberId(店铺唯一标识)"""
for pattern in self.shop_patterns:
match = re.search(pattern, shop_url)
if match:
return match.group(1)
# URL直接解析失败,尝试从页面内容提取
return self._extract_id_from_page(shop_url)
def _extract_id_from_page(self, shop_url):
"""从店铺页面内容提取memberId"""
try:
response = requests.get(
shop_url,
headers=self.headers,
timeout=15,
allow_redirects=True
)
response.encoding = "utf-8"
# 从meta标签提取
tree = etree.HTML(response.text)
member_id_meta = tree.xpath('//meta[@name="memberId"]/@content')
if member_id_meta and member_id_meta[0]:
return member_id_meta[0]
# 从脚本标签提取
scripts = tree.xpath('//script/text()')
for script in scripts:
match = re.search(r'memberId\s*[:=]\s*["\'](\w+)["\']', script)
if match:
return match.group(1)
return None
except Exception as e:
print(f"页面提取店铺ID失败: {str(e)}")
return None
def get_shop_base_info(self, shop_url):
"""获取店铺基础信息(名称、主营类目等)"""
try:
response = requests.get(
shop_url,
headers=self.headers,
timeout=15
)
response.encoding = "utf-8"
tree = etree.HTML(response.text)
# 提取店铺名称
shop_name = tree.xpath('//h1[@class="shop-name"]/text()')
shop_name = shop_name[0].strip() if shop_name else ""
# 提取主营类目
main_category = tree.xpath('//div[contains(text(), "主营产品")]/following-sibling::div/text()')
main_category = main_category[0].strip() if main_category else ""
# 提取经营年限
years = tree.xpath('//div[contains(@class, "year")]/text()')
years = years[0].strip() if years else "未知"
# 提取诚信通等级
credit_level = tree.xpath('//div[contains(@class, "credit-level")]/@title')
credit_level = credit_level[0].strip() if credit_level else "未评级"
return {
"shop_url": shop_url,
"member_id": self.extract_shop_id(shop_url),
"shop_name": shop_name,
"main_category": main_category,
"operation_years": years,
"credit_level": credit_level
}
except Exception as e:
print(f"获取店铺信息失败: {str(e)}")
return None
def get_shop_categories(self, member_id):
"""获取店铺商品分类(用于筛选采集)"""
if not member_id:
return None
category_url = f"https://{member_id}.1688.com/page/offerlist.htm"
try:
response = requests.get(
category_url,
headers=self.headers,
timeout=15
)
response.encoding = "utf-8"
tree = etree.HTML(response.text)
# 提取分类列表
categories = []
cat_elements = tree.xpath('//div[@class="filter-sort-item"]//a[@class="filter-item"]')
for elem in cat_elements[1:]: # 跳过"全部"
cat_name = elem.xpath('./text()')[0].strip() if elem.xpath('./text()') else ""
cat_url = elem.xpath('./@href')[0].strip() if elem.xpath('./@href') else ""
# 提取分类ID
cat_id = ""
match = re.search(r'categoryId=(\d+)', cat_url)
if match:
cat_id = match.group(1)
if cat_name and cat_id:
categories.append({
"category_id": cat_id,
"category_name": cat_name,
"url": cat_url
})
return categories
except Exception as e:
print(f"获取店铺分类失败: {str(e)}")
return None
2. 店铺商品分页参数生成器(处理 B 端分页逻辑)
1688 店铺商品采用特殊的分页机制,不同排序方式和筛选条件对应不同的参数规则:
python
运行
import time
import random
import hashlib
import urllib.parse
class AlibabaShopProductParamsGenerator:
"""1688店铺商品分页参数生成器"""
def __init__(self):
self.base_url = "https://offerlist.1688.com/offerlist.htm"
# 排序方式映射
self.sort_mapping = {
"default": "", # 默认排序
"newest": "create_desc", # 最新上架
"price_asc": "price_asc", # 价格从低到高
"price_desc": "price_desc", # 价格从高到低
"sales": "volume_desc" # 销量从高到低
}
def generate_params(self, member_id, page=1, sort="default", category_id="", **filters):
"""
生成店铺商品列表请求参数
:param member_id: 店铺memberId
:param page: 页码
:param sort: 排序方式
:param category_id: 分类ID(空表示全部)
:param filters: 筛选条件,支持:
- min_price: 最低价格
- max_price: 最高价格
- is_wholesale: 是否批发(True/False)
:return: 完整参数字典
"""
params = {
"memberId": member_id,
"pageNum": page,
"pageSize": 60, # 每页最大商品数
"sortType": self.sort_mapping.get(sort, ""),
"categoryId": category_id,
"offline": "false", # 只显示在线商品
"sample": "false", # 不显示样品
"isNoReload": "true",
"enableAsync": "true",
"async": "true",
"_input_charset": "UTF-8",
"timestamp": str(int(time.time() * 1000)),
"rn": str(random.randint(1000000000, 9999999999))
}
# 添加价格筛选
if "min_price" in filters and filters["min_price"]:
params["priceStart"] = filters["min_price"]
if "max_price" in filters and filters["max_price"]:
params["priceEnd"] = filters["max_price"]
# 添加批发筛选
if "is_wholesale" in filters and filters["is_wholesale"]:
params["wholesale"] = "true"
# 生成签名(部分接口需要)
if random.random() > 0.5: # 模拟部分请求需要签名的场景
params["sign"] = self._generate_sign(params)
return params
def _generate_sign(self, params):
"""生成参数签名"""
# 按参数名排序
sorted_params = sorted(params.items(), key=lambda x: x[0])
# 拼接签名字符串
sign_str = "&".join([f"{k}={urllib.parse.quote(str(v), safe='')}" for k, v in sorted_params])
# 添加固定密钥(模拟)
sign_str += "&secret=shop_product_demo_key"
# MD5加密
return hashlib.md5(sign_str.encode()).hexdigest().upper()
def get_list_url(self, params):
"""生成完整的商品列表URL"""
return f"{self.base_url}?{urllib.parse.urlencode(params)}"
3. 店铺商品请求调度器(应对 B 端反爬限制)
1688 对店铺商品批量采集有严格的反爬限制,需实现会话保持、代理轮换、请求间隔控制等策略:
python
运行
import time
import random
import requests
from fake_useragent import UserAgent
import urllib3
# 禁用不安全请求警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class AlibabaShopProductRequester:
"""1688店铺商品请求调度器"""
def __init__(self, proxy_pool=None):
self.proxy_pool = proxy_pool or []
self.ua = UserAgent()
self.session = self._init_session()
self.last_request_time = 0
self.min_interval = 15 # 页面请求最小间隔(秒)
self.max_retries = 3 # 最大重试次数
def _init_session(self):
"""初始化会话,获取基础Cookie"""
session = requests.Session()
session.headers.update({
"User-Agent": self.ua.random,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Referer": "https://www.1688.com/",
"Upgrade-Insecure-Requests": "1"
})
# 预访问1688首页获取必要Cookie
session.get("https://www.1688.com", verify=False, timeout=10)
return session
def _rotate_user_agent(self):
"""轮换User-Agent"""
self.session.headers["User-Agent"] = self.ua.random
def _get_proxy(self):
"""获取可用代理"""
if not self.proxy_pool:
return None
# 随机选择代理并验证
proxy = random.choice(self.proxy_pool)
try:
test_url = "https://www.1688.com"
response = requests.get(
test_url,
proxies={"https": proxy},
timeout=5,
verify=False
)
if response.status_code == 200:
return proxy
else:
if proxy in self.proxy_pool:
self.proxy_pool.remove(proxy)
return self._get_proxy() if self.proxy_pool else None
except:
if proxy in self.proxy_pool:
self.proxy_pool.remove(proxy)
return self._get_proxy() if self.proxy_pool else None
def _control_request_interval(self):
"""控制请求间隔,避免触发反爬"""
current_time = time.time()
elapsed = current_time - self.last_request_time
if elapsed < self.min_interval:
sleep_time = self.min_interval - elapsed + random.uniform(2, 5)
print(f"请求间隔不足,休眠 {sleep_time:.1f} 秒")
time.sleep(sleep_time)
self.last_request_time = time.time()
def fetch_shop_products_page(self, params, retry_count=0):
"""
获取店铺商品列表页面
:param params: 请求参数
:param retry_count: 当前重试次数
:return: 页面HTML内容或None
"""
# 控制请求频率
self._control_request_interval()
# 轮换User-Agent
self._rotate_user_agent()
# 获取代理
proxy = self._get_proxy()
proxies = {"https": proxy} if proxy else None
try:
response = self.session.get(
"https://offerlist.1688.com/offerlist.htm",
params=params,
proxies=proxies,
timeout=20,
verify=False,
allow_redirects=True
)
# 检查状态码
if response.status_code != 200:
if retry_count < self.max_retries:
print(f"请求失败,状态码: {response.status_code},重试 {retry_count+1}/{self.max_retries}")
return self.fetch_shop_products_page(params, retry_count + 1)
return None
# 检查是否被反爬拦截
if self._is_blocked(response.text):
print("请求被反爬机制拦截")
# 重置会话
self.session = self._init_session()
if retry_count < self.max_retries:
print(f"更换会话重试 {retry_count+1}/{self.max_retries}")
return self.fetch_shop_products_page(params, retry_count + 1)
return None
return response.text
except Exception as e:
print(f"请求异常: {str(e)}")
if retry_count < self.max_retries:
print(f"重试 {retry_count+1}/{self.max_retries}")
return self.fetch_shop_products_page(params, retry_count + 1)
return None
def _is_blocked(self, html_content):
"""判断是否被反爬拦截"""
block_keywords = [
"请输入验证码",
"访问过于频繁",
"安全验证",
"系统繁忙,请稍后再试",
"您的操作过于频繁"
]
for keyword in block_keywords:
if keyword in html_content:
return True
return False
4. 店铺商品数据解析器(提取 B 端特色字段)
解析店铺商品列表页面,提取包含批发价、起订量、销量等 B 端特色数据,并处理分页信息:
python
运行
import re
import json
from datetime import datetime
from lxml import etree
class AlibabaShopProductParser:
"""1688店铺商品数据解析器"""
def __init__(self):
# 匹配商品数据的正则表达式
self.product_data_pattern = re.compile(r'window\.__page__data__\s*=\s*({.*?});\s*</script>', re.DOTALL)
self.offer_list_pattern = re.compile(r'offerList\s*:\s*(\[.*?\])', re.DOTALL)
def parse_products_page(self, html_content):
"""解析店铺商品列表页面"""
if not html_content:
return None
# 尝试从页面提取JSON数据
json_data = self._extract_json_data(html_content)
if json_data:
return self._parse_from_json(json_data)
# JSON解析失败,尝试从HTML解析
return self._parse_from_html(html_content)
def _extract_json_data(self, html_content):
"""从页面提取JSON数据"""
match = self.product_data_pattern.search(html_content)
if match:
try:
return json.loads(match.group(1))
except json.JSONDecodeError:
print("JSON数据解析失败")
# 尝试提取简化的商品列表数据
match = self.offer_list_pattern.search(html_content)
if match:
try:
return {"offerList": json.loads(match.group(1))}
except json.JSONDecodeError:
print("商品列表数据解析失败")
return None
def _parse_from_json(self, json_data):
"""从JSON数据解析商品信息"""
# 提取分页信息
pagination = self._parse_pagination(json_data)
# 提取商品列表
products = []
offer_list = json_data.get("offerList", [])
if not offer_list:
offer_list = json_data.get("data", {}).get("offerList", [])
for item in offer_list:
# 解析价格信息
price_info = self._parse_price(item)
# 解析销量信息
sales_info = self._parse_sales(item)
products.append({
"offer_id": str(item.get("offerId", "")),
"title": item.get("title", "").strip(),
"main_image": item.get("imageUrl", ""),
"price": price_info,
"min_order": item.get("minOrderQuantity", "1"),
"unit": item.get("unit", "件"),
"sales": sales_info,
"category": item.get("categoryName", ""),
"detail_url": item.get("detailUrl", ""),
"is_promotion": "promotionPrice" in item,
"update_time": item.get("modifyTime", "")
})
return {
"products": products,
"pagination": pagination,
"parse_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
def _parse_from_html(self, html_content):
"""从HTML解析商品信息(备用方案)"""
tree = etree.HTML(html_content)
# 提取分页信息
pagination = self._parse_html_pagination(tree)
# 提取商品列表
products = []
product_elements = tree.xpath('//div[contains(@class, "offer-item")]')
for elem in product_elements:
# 提取商品ID
offer_id = ""
link_elem = elem.xpath('.//a[@class="offer-title"]/@href')
if link_elem:
match = re.search(r'offer/(\d+)\.html', link_elem[0])
if match:
offer_id = match.group(1)
# 提取标题
title = elem.xpath('.//a[@class="offer-title"]/@title')
title = title[0].strip() if title else ""
# 提取价格
price_text = elem.xpath('.//div[contains(@class, "price")]/text()')
price_text = price_text[0].strip() if price_text else "0"
# 提取起订量
min_order = elem.xpath('.//div[contains(@class, "moq")]/text()')
min_order = min_order[0].strip() if min_order else "1件"
products.append({
"offer_id": offer_id,
"title": title,
"price": {"type": "text", "value": price_text},
"min_order": min_order.split()[0],
"unit": min_order.split()[-1] if len(min_order.split()) > 1 else "件",
"main_image": elem.xpath('.//img/@src')[0] if elem.xpath('.//img/@src') else ""
})
return {
"products": products,
"pagination": pagination,
"parse_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
def _parse_pagination(self, json_data):
"""从JSON解析分页信息"""
pagination = json_data.get("pagination", {})
if not pagination:
pagination = json_data.get("data", {}).get("pagination", {})
return {
"current_page": pagination.get("pageNum", 1),
"page_size": pagination.get("pageSize", 60),
"total_pages": pagination.get("totalPage", 0),
"total_products": pagination.get("totalCount", 0)
}
def _parse_html_pagination(self, tree):
"""从HTML解析分页信息"""
# 提取当前页码
current_page = tree.xpath('//a[contains(@class, "current")]/text()')
current_page = int(current_page[0]) if current_page else 1
# 提取总页数
total_pages = tree.xpath('//span[contains(@class, "total-page")]/text()')
if total_pages:
match = re.search(r'\d+', total_pages[0])
total_pages = int(match.group()) if match else 0
else:
total_pages = 0
return {
"current_page": current_page,
"page_size": 60,
"total_pages": total_pages,
"total_products": 0 # HTML中通常不直接显示总商品数
}
def _parse_price(self, item):
"""解析价格信息(处理区间价格)"""
if "price" in item:
return {
"type": "fixed",
"value": float(item.get("price", 0))
}
elif "priceRange" in item:
return {
"type": "range",
"min": float(item.get("priceRange", {}).get("minPrice", 0)),
"max": float(item.get("priceRange", {}).get("maxPrice", 0))
}
return {"type": "unknown", "value": 0}
def _parse_sales(self, item):
"""解析销量信息(B端特色)"""
if "volume" in item:
return {
"count": int(item.get("volume", 0)),
"unit": item.get("volumeUnit", "件"),
"period": "30天" # 1688默认显示30天销量
}
return {"count": 0, "unit": "件", "period": ""}
def remove_duplicates(self, products):
"""去除重复商品(基于offer_id)"""
seen_ids = set()
unique_products = []
for product in products:
if product["offer_id"] not in seen_ids:
seen_ids.add(product["offer_id"])
unique_products.append(product)
return unique_products
5. 店铺商品分类采集器(按品类批量获取)
实现按店铺内部分类采集商品,支持多分类并行采集与数据合并:
python
运行
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
class AlibabaShopCategoryCollector:
"""1688店铺商品分类采集器"""
def __init__(self, requester, parser, params_generator):
self.requester = requester
self.parser = parser
self.params_generator = params_generator
self.max_workers = 2 # 分类采集并发数(不宜过高)
def collect_by_category(self, member_id, categories, max_pages_per_cat=3):
"""
按分类采集店铺商品
:param member_id: 店铺ID
:param categories: 分类列表(从AlibabaShopParser获取)
:param max_pages_per_cat: 每个分类最大采集页数
:return: 合并后的商品列表
"""
if not categories:
print("没有分类信息,无法按分类采集")
return None
all_products = []
category_results = {}
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
# 提交分类采集任务
future_tasks = {}
for cat in categories:
future = executor.submit(
self._collect_single_category,
member_id,
cat,
max_pages_per_cat
)
future_tasks[future] = cat["category_name"]
# 处理任务结果
for future in as_completed(future_tasks):
cat_name = future_tasks[future]
try:
result = future.result()
if result and result["products"]:
category_results[cat_name] = result
all_products.extend(result["products"])
print(f"分类 [{cat_name}] 采集完成,获取 {len(result['products'])} 个商品")
else:
print(f"分类 [{cat_name}] 采集失败或无商品")
except Exception as e:
print(f"分类 [{cat_name}] 采集异常: {str(e)}")
# 去重并添加分类信息
unique_products = self.parser.remove_duplicates(all_products)
for product in unique_products:
# 为每个商品添加所属分类(简化处理)
for cat_name, cat_data in category_results.items():
if product in cat_data["products"]:
product["category"] = cat_name
break
return {
"total_products": len(unique_products),
"category_counts": {k: len(v["products"]) for k, v in category_results.items()},
"products": unique_products
}
def _collect_single_category(self, member_id, category, max_pages):
"""采集单个分类的商品"""
cat_id = category["category_id"]
cat_name = category["category_name"]
print(f"开始采集分类 [{cat_name}] (ID: {cat_id})")
all_products = []
current_page = 1
total_pages = 1
while current_page <= max_pages and current_page <= total_pages:
# 生成参数
params = self.params_generator.generate_params(
member_id=member_id,
page=current_page,
category_id=cat_id,
sort="sales" # 按销量排序
)
# 获取页面
html_content = self.requester.fetch_shop_products_page(params)
if not html_content:
print(f"分类 [{cat_name}] 第 {current_page} 页获取失败")
current_page += 1
continue
# 解析页面
result = self.parser.parse_products_page(html_content)
if not result:
print(f"分类 [{cat_name}] 第 {current_page} 页解析失败")
current_page += 1
continue
# 更新分页信息
total_pages = min(result["pagination"]["total_pages"], max_pages)
# 添加商品
all_products.extend(result["products"])
print(f"分类 [{cat_name}] 第 {current_page}/{total_pages} 页解析完成")
current_page += 1
# 分类间添加额外间隔
time.sleep(random.uniform(5, 10))
return {
"category_id": cat_id,
"category_name": cat_name,
"products": all_products,
"total_pages_collected": current_page - 1
}
三、完整店铺商品采集服务封装
整合上述组件,实现完整的店铺商品采集服务:
python
运行
class AlibabaShopProductService:
"""1688店铺商品完整采集服务"""
def __init__(self, proxy_pool=None):
self.shop_parser = AlibabaShopParser()
self.params_generator = AlibabaShopProductParamsGenerator()
self.requester = AlibabaShopProductRequester(proxy_pool=proxy_pool)
self.product_parser = AlibabaShopProductParser()
self.category_collector = AlibabaShopCategoryCollector(
self.requester,
self.product_parser,
self.params_generator
)
def collect_shop_products(self, shop_url, max_pages=5, by_category=False, max_pages_per_cat=3):
"""
采集店铺所有商品
:param shop_url: 店铺URL
:param max_pages: 最大采集页数(全量采集时)
:param by_category: 是否按分类采集
:param max_pages_per_cat: 每个分类最大采集页数
:return: 包含店铺信息和商品列表的字典
"""
# 1. 获取店铺基础信息
print("获取店铺基础信息...")
shop_info = self.shop_parser.get_shop_base_info(shop_url)
if not shop_info or not shop_info["member_id"]:
print("无法获取店铺信息,采集终止")
return None
member_id = shop_info["member_id"]
print(f"店铺信息:{shop_info['shop_name']} (ID: {member_id})")
# 2. 获取店铺分类
print("获取店铺商品分类...")
categories = self.shop_parser.get_shop_categories(member_id)
if categories:
print(f"发现 {len(categories)} 个商品分类:{[c['category_name'] for c in categories]}")
else:
print("未获取到店铺分类信息")
by_category = False # 无法按分类采集
# 3. 采集商品
if by_category and categories:
# 按分类采集
print("开始按分类采集商品...")
product_result = self.category_collector.collect_by_category(
member_id=member_id,
categories=categories,
max_pages_per_cat=max_pages_per_cat
)
else:
# 全量采集
print("开始全量采集商品...")
product_result = self._collect_all_products(
member_id=member_id,
max_pages=max_pages
)
if not product_result or not product_result["products"]:
print("未采集到任何商品")
return None
# 4. 整合结果
return {
"shop_info": shop_info,
"collection_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"total_products": product_result["total_products"],
"category_distribution": product_result.get("category_counts", {}),
"products": product_result["products"]
}
def _collect_all_products(self, member_id, max_pages):
"""全量采集店铺商品(不按分类)"""
all_products = []
current_page = 1
total_pages = 1
while current_page <= max_pages and current_page <= total_pages:
print(f"采集第 {current_page}/{max_pages} 页商品...")
# 生成参数
params = self.params_generator.generate_params(
member_id=member_id,
page=current_page,
sort="sales" # 按销量排序
)
# 获取页面
html_content = self.requester.fetch_shop_products_page(params)
if not html_content:
print(f"第 {current_page} 页获取失败,跳过")
current_page += 1
continue
# 解析页面
result = self.product_parser.parse_products_page(html_content)
if not result:
print(f"第 {current_page} 页解析失败,跳过")
current_page += 1
continue
# 更新分页信息
total_pages = min(result["pagination"]["total_pages"], max_pages)
# 添加商品
all_products.extend(result["products"])
print(f"第 {current_page} 页解析完成,获取 {len(result['products'])} 个商品")
current_page += 1
# 去重
unique_products = self.product_parser.remove_duplicates(all_products)
return {
"total_products": len(unique_products),
"pages_collected": current_page - 1,
"products": unique_products
}
四、使用示例与数据存储分析
1. 基本使用示例
python
运行
def main():
# 代理池(实际使用时替换为有效代理)
proxy_pool = [
# "http://123.123.123.123:8080",
# "http://111.111.111.111:8888"
]
# 初始化店铺商品采集服务
service = AlibabaShopProductService(proxy_pool=proxy_pool)
# 店铺URL(替换为实际店铺URL)
shop_url = "https://shop123456789.1688.com"
# 采集店铺商品(按分类采集,每个分类最多2页)
result = service.collect_shop_products(
shop_url=shop_url,
by_category=True,
max_pages_per_cat=2
)
# 处理结果
if result:
print(f"\n采集完成!共获取 {result['total_products']} 个商品")
# 打印店铺信息
print(f"\n店铺名称:{result['shop_info']['shop_name']}")
print(f"主营类目:{result['shop_info']['main_category']}")
print(f"经营年限:{result['shop_info']['operation_years']}")
print(f"诚信等级:{result['shop_info']['credit_level']}")
# 打印分类分布
if result["category_distribution"]:
print("\n商品分类分布:")
for cat, count in result["category_distribution"].items():
print(f"- {cat}: {count} 个商品")
# 打印部分商品信息
if result["products"]:
print("\n部分商品信息:")
for i, product in enumerate(result["products"][:5], 1):
print(f"{i}. {product['title'][:50]}...")
# 处理价格信息
price_str = ""
if product["price"]["type"] == "fixed":
price_str = f"{product['price']['value']}元/{product['unit']}"
elif product["price"]["type"] == "range":
price_str = f"{product['price']['min']}-{product['price']['max']}元/{product['unit']}"
else:
price_str = product["price"]["value"]
print(f" 价格:{price_str} | 起订量:{product['min_order']}{product['unit']}")
print(f" 分类:{product.get('category', '未知')}")
if product["sales"]["count"] > 0:
print(f" 30天销量:{product['sales']['count']}{product['sales']['unit']}")
print()
else:
print("店铺商品采集失败")
if __name__ == "__main__":
main()
2. 数据存储与分析工具
python
运行
import json
import csv
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
from datetime import datetime
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
class ShopProductStorageAnalyzer:
"""店铺商品数据存储与分析工具"""
def __init__(self, storage_dir="./1688_shop_products"):
self.storage_dir = Path(storage_dir)
self.storage_dir.mkdir(exist_ok=True, parents=True)
def save_results(self, result):
"""保存采集结果"""
shop_name = result["shop_info"]["shop_name"].replace('/', '_')
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 保存完整结果(JSON)
json_path = self.storage_dir / f"{shop_name}_full_{timestamp}.json"
with open(json_path, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2, default=str)
# 保存商品列表(CSV)
csv_path = self.storage_dir / f"{shop_name}_products_{timestamp}.csv"
self._save_products_to_csv(result["products"], csv_path)
print(f"数据已保存至:\n- {json_path}\n- {csv_path}")
return json_path, csv_path
def _save_products_to_csv(self, products, csv_path):
"""将商品列表保存为CSV"""
if not products:
return
# 转换为可导出格式
export_data = []
for p in products:
# 处理价格
price_str = ""
if p["price"]["type"] == "fixed":
price_str = f"{p['price']['value']}"
elif p["price"]["type"] == "range":
price_str = f"{p['price']['min']}-{p['price']['max']}"
else:
price_str = str(p["price"]["value"])
export_data.append({
"offer_id": p["offer_id"],
"title": p["title"],
"category": p.get("category", ""),
"price": price_str,
"unit": p["unit"],
"min_order": p["min_order"],
"sales_count": p["sales"]["count"],
"sales_unit": p["sales"]["unit"],
"is_promotion": p.get("is_promotion", False),
"detail_url": p["detail_url"]
})
# 保存为CSV
df = pd.DataFrame(export_data)
df.to_csv(csv_path, index=False, encoding="utf-8-sig")
def analyze_shop_products(self, result):
"""分析店铺商品数据"""
if not result or not result["products"]:
return None
print("\n开始分析店铺商品数据...")
products = result["products"]
shop_name = result["shop_info"]["shop_name"]
# 1. 分类分布分析
self._analyze_category_distribution(products, shop_name)
# 2. 价格分布分析
self._analyze_price_distribution(products, shop_name)
# 3. 起订量分析
self._analyze_min_order(products, shop_name)
# 4. 销量与价格关系
self._analyze_sales_vs_price(products, shop_name)
return True
def _analyze_category_distribution(self, products, shop_name):
"""分析商品分类分布"""
categories = [p.get("category", "未知") for p in products]
cat_counts = pd.Series(categories).value_counts()
plt.figure(figsize=(12, 6))
cat_counts.plot(kind='bar', color='skyblue')
plt.title(f'{shop_name} 商品分类分布')
plt.xlabel('分类名称')
plt.ylabel('商品数量')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
def _analyze_price_distribution(self, products, shop_name):
"""分析价格分布"""
prices = []
for p in products:
try:
if p["price"]["type"] == "fixed":
prices.append(float(p["price"]["value"]))
elif p["price"]["type"] == "range":
prices.append((p["price"]["min"] + p["price"]["max"]) / 2)
except:
continue
if not prices:
return
plt.figure(figsize=(12, 6))
plt.hist(prices, bins=15, color='lightgreen', edgecolor='black')
plt.title(f'{shop_name} 商品价格分布')
plt.xlabel('价格(元)')
plt.ylabel('商品数量')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
def _analyze_min_order(self, products, shop_name):
"""分析起订量分布(B端特色)"""
orders = []
for p in products:
try:
order_num = int(p["min_order"])
orders.append(order_num)
except:
continue
if not orders:
return
# 起订量区间划分
order_ranges = {
"1-10": 0, "11-50": 0, "51-100": 0, "101-500": 0, "501+": 0
}
for num in orders:
if num <= 10:
order_ranges["1-10"] += 1
elif num <= 50:
order_ranges["11-50"] += 1
elif num <= 100:
order_ranges["51-100"] += 1
elif num <= 500:
order_ranges["101-500"] += 1
else:
order_ranges["501+"] += 1
plt.figure(figsize=(10, 6))
plt.bar(order_ranges.keys(), order_ranges.values(), color='salmon')
plt.title(f'{shop_name} 商品起订量分布')
plt.xlabel('起订量区间(件)')
plt.ylabel('商品数量')
plt.tight_layout()
plt.show()
def _analyze_sales_vs_price(self, products, shop_name):
"""分析销量与价格关系"""
data = []
for p in products:
try:
# 处理价格
if p["price"]["type"] == "fixed":
price = float(p["price"]["value"])
elif p["price"]["type"] == "range":
price = (p["price"]["min"] + p["price"]["max"]) / 2
else:
continue
# 处理销量
sales = p["sales"]["count"]
if sales > 0:
data.append({"price": price, "sales": sales})
except:
continue
if not data:
return
df = pd.DataFrame(data)
plt.figure(figsize=(10, 6))
plt.scatter(df["price"], df["sales"], alpha=0.6, color='purple')
plt.title(f'{shop_name} 商品销量与价格关系')
plt.xlabel('价格(元)')
plt.ylabel('30天销量')
plt.grid(linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
五、合规优化与风险提示
1. 系统优化策略
-
增量采集机制:记录已采集商品 ID,仅采集新增或更新的商品
python
运行
-
def incremental_collect(self, shop_url, last_collected_ids): """增量采集:仅获取新商品""" # 实现逻辑... return new_products -
智能缓存策略:缓存店铺分类信息和已采集商品,减少重复请求
-
分布式采集:大规模采集时采用分布式架构,分散 IP 压力
2. 合规与风险提示
- 商业应用前必须获得 1688 平台和店铺的书面授权,遵守《电子商务法》
- 单店铺采集频率不宜过高,建议间隔 24 小时以上重复采集
- 不得将采集的店铺商品数据用于生成与该店铺竞争的产品或服务
- 尊重店铺商业信息,不滥用数据进行价格战或恶意竞争
- 当检测到反爬机制触发时,应立即停止采集并间隔 48 小时以上再试
通过本文提供的技术方案,可构建一套功能完善的 1688 店铺全商品采集系统。该方案针对 B2B 电商特色进行了优化,支持按分类采集、商品去重、数据分布分析等功能,为供应链分析、竞品调研等场景提供技术支持。在实际应用中,需特别注意平台对店铺批量采集的严格限制,确保合规使用。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 23
23 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)