
京东二面:你对Hive的Join有了解吗?
Hive支持的连接包含[inner]join、left [outer] join、right [outer] join、full [outer] join、left semi join、cross join以及特殊的Common Join和Map Join,其实在使用过程中尽量避免使用笛卡尔积(cross join),因其会增加大量的IO消耗,可能会导致内存不够、集群崩坏等。有时为了得到完整的数据
Hive Join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。有时为了得到完整的数据,将多个表的数据行根据一定的规则连接起来,那么就需要执行Join。
Join连接分为常用Join和特殊Join,常用的有:
①内连接,可查询出的数据是两张表的交集。
②外连接,会先将连接的表分为基表和参考表,再以基表为依据返回满足和不满足条件的记录。
③全连接,可查询出左右两表的所有数据。
④left semi join和笛卡尔积join。
特殊的有Common Join和Map Join。
一、常用Join
测试用例:
表 t1
|
id(int) |
name(string) |
|
1 |
lucy |
|
2 |
jack |
|
3 |
tony |
表 t2
|
id(int) |
age(int) |
|
1 |
12 |
|
2 |
22 |
|
4 |
32 |
1. [inner] join
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
selectt1.id,t1.name,t2.agefrom t1inner join t2on t1.id = t2.id;
|
1 |
lucy |
12 |
|
2 |
jack |
22 |
2. left [outer] join
左外连接:Join操作符左边表中所有记录将会被返回,不符合关联条件的记录将被置为null。
selectt1.id,t1.name,t2.agefrom t1left join t2on t1.id = t2.id;
|
1 |
lucy |
12 |
|
2 |
jack |
22 |
|
3 |
tony |
null |
3. right [outer] join
左外连接:Join操作符右边表中所有记录将会被返回,不符合关联条件的记录将被置为null。
selectt1.id,t1.name,t2.agefrom t1right join t2on t1.id = t2.id;
|
1 |
lucy |
12 |
|
2 |
jack |
22 |
|
null |
null |
32 |
4. full [outer] join
满外连接:将会返回所有表中的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用null值替代。
selectt1.id,t1.name,t2.agefrom t1full join t2on t1.id = t2.id;
|
1 |
lucy |
12 |
|
2 |
jack |
22 |
|
3 |
tony |
null |
|
null |
null |
32 |
5. left semi join
以LEFT SEMI JOIN关键字前面的表为主表,返回主表的关联条件也在副表中的记录。
selectt1.id,t1.name,t2.agefrom t1left semi join t2on t1.id = t2.id;
|
1 |
lucy |
|
2 |
jack |
相当于:
selectt1.id,t1.namefrom t1where t1.id in(select t2.id from t2);
6. cross join
笛卡尔积关联:返回两个表的笛卡尔积结果,不需要指定关联键。
selectt1.id,t1.name,t2.agefrom t1cross join t2;
|
1 |
lucy |
12 |
|
1 |
lucy |
22 |
|
1 |
lucy |
32 |
|
2 |
jack |
12 |
|
2 |
jack |
22 |
|
2 |
jack |
32 |
|
3 |
tony |
12 |
|
3 |
tony |
22 |
|
3 |
tony |
32 |
二、特殊Join
利用Hive进行Join连接操作,相较于MR有两种执行方案,一种为Common Join,另一种为Map Join,Map Join是相对于Common Join的一种优化,省去Shullfe和Reduce的过程,大大的降低的作业运行的时间。
1. Common Join
也称之为Shuffle Join/Reduce Join。
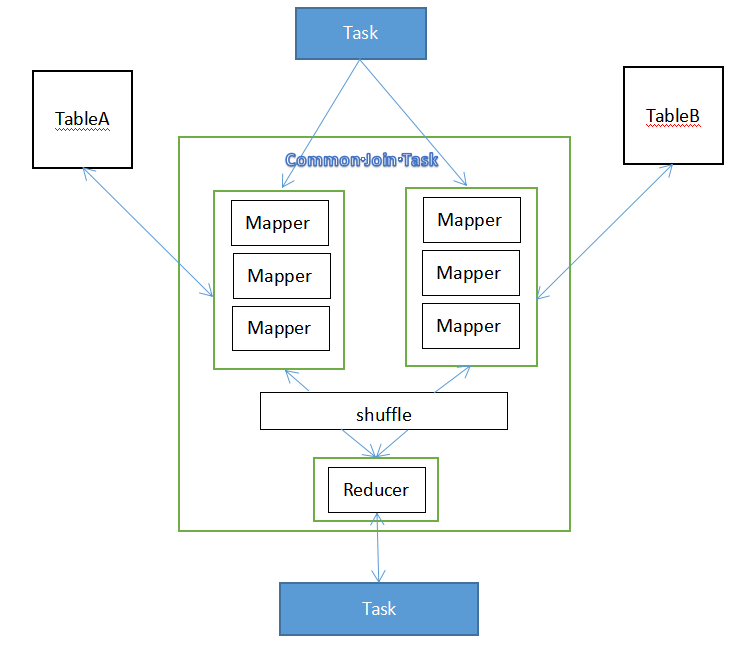
过程:
① 首先会启动一个Task,Mapper会去读表HDFS上两张A/B表中的数据。
② Mapper处理过数据再经过Shuffle处理。
③ 最后由Reduce输出Join结果。
缺点 :
① 存在Shuffle过程,效率低。
② 每张表都要去磁盘读取,磁盘IO大。
2. Map Join
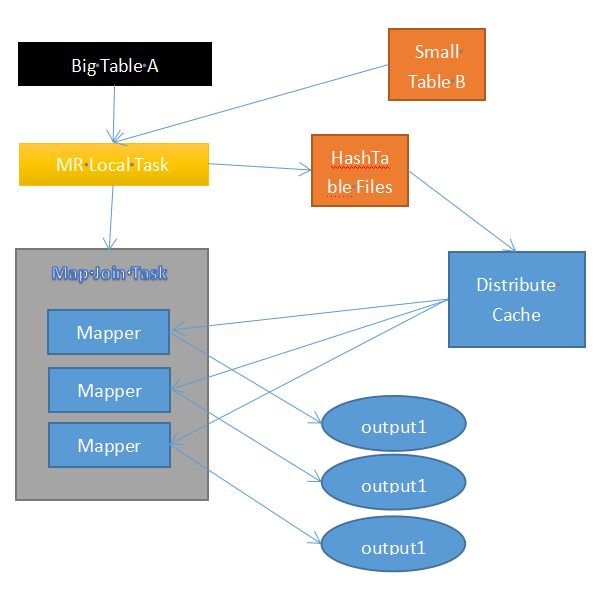
过程:
① Mapjoin首先会通过本地MapReduce Task将要join的小表转成Hash Table Files,然后加载到分布式缓存中。
② Mapperh会去缓存中读取小表数据来和Big Table数据进行join。
③ Map直接给出结果。
优点:没有Shuffle/Reduce过程,效率提高。
缺点:由于小表都加载到内存当中,读内存的要求提高了。
另:Hive中专门有个参数来设置是否自动Common Join 转化为Map Join:hive.auto.convert.join。当hive.auto.convert.join=true hive会为我们自动转换。
三、总结
Hive支持的连接包含[inner]join、left [outer] join、right [outer] join、full [outer] join、left semi join、cross join以及特殊的Common Join和Map Join,其实在使用过程中尽量避免使用笛卡尔积(cross join),因其会增加大量的IO消耗,可能会导致内存不够、集群崩坏等。
Hive Join 非常重要,是Hive查询的基础知识,需要大家多加练习。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)