
阿里巴巴高并发架构到底多牛逼?是如何抗住淘宝双11亿级并发量?
高并发,几乎是每个程序员都想拥有的经验。原因很简单:随着流量变大,会遇到各种各样的技术问题,比如接口响应超时、CPU load升高、GC频繁、死锁、大数据量存储等等,这些问题能推动我们在技术深度上不断精进。:不清楚选择什么样的指标来衡量高并发系统?分不清并发量和QPS,甚至不知道自己系统的总用户量、活跃用户量,平峰和高峰时的QPS和TPS等关键数据。:讲不出该方案要关注的技术点和可能带来的副作用。
高并发,几乎是每个程序员都想拥有的经验。原因很简单:随着流量变大,会遇到各种各样的技术问题,比如接口响应超时、CPU load升高、GC频繁、死锁、大数据量存储等等,这些问题能推动我们在技术深度上不断精进。
在过往的面试中,如果候选人做过高并发的项目,我通常会让对方谈谈对于高并发的理解,但是能系统性地回答好此问题的人并不多,大概分成这样几类:
1、对数据化的指标没有概念:不清楚选择什么样的指标来衡量高并发系统?分不清并发量和QPS,甚至不知道自己系统的总用户量、活跃用户量,平峰和高峰时的QPS和TPS等关键数据。
2、设计了一些方案,但是细节掌握不透彻:讲不出该方案要关注的技术点和可能带来的副作用。比如读性能有瓶颈会引入缓存,但是忽视了缓存命中率、热点key、数据一致性等问题。
3、理解片面,把高并发设计等同于性能优化:大谈并发编程、多级缓存、异步化、水平扩容,却忽视高可用设计、服务治理和运维保障。
4、掌握大方案,却忽视最基本的东西:能讲清楚垂直分层、水平分区、缓存等大思路,却没意识去分析数据结构是否合理,算法是否高效,没想过从最根本的IO和计算两个维度去做细节优化。
这篇文章,我想结合自己的高并发项目经验,系统性地总结下高并发需要掌握的知识和实践思路,希望对你有所帮助。内容分成以下3个部分:
- 如何理解高并发?
- 高并发系统设计的目标是什么?
- 高并发的实践方案有哪些?
1 、如何理解高并发?
高并发意味着大流量,需要运用技术手段抵抗流量的冲击,这些手段好比操作流量,能让流量更平稳地被系统所处理,带给用户更好的体验。
我们常见的高并发场景有:淘宝的双11、春运时的抢票、微博大V的热点新闻等。除了这些典型事情,每秒几十万请求的秒杀系统、每天千万级的订单系统、每天亿级日活的信息流系统等,都可以归为高并发。
很显然,上面谈到的高并发场景,并发量各不相同,那到底多大并发才算高并发呢?
1、不能只看数字,要看具体的业务场景。不能说10W QPS的秒杀是高并发,而1W QPS的信息流就不是高并发。信息流场景涉及复杂的推荐模型和各种人工策略,它的业务逻辑可能比秒杀场景复杂10倍不止。因此,不在同一个维度,没有任何比较意义。
2、业务都是从0到1做起来的,并发量和QPS只是参考指标,最重要的是:在业务量逐渐变成原来的10倍、100倍的过程中,你是否用到了高并发的处理方法去严谨你的系统,从架构设计、编码实现、甚至产品方案等维度去预防和解决高并发引起的问题?而不是一味的升级硬件、加机器做水平扩展。
此外,各个高并发场景的业务特点完全不同:有读多写少的信息流场景、有读多写多的交易场景,那是否有通用的技术方案解决不同场景的高并发问题呢?
我觉得大的思路可以借鉴,别人的方案也可以参考,但是真正落地过程中,细节上还会有无数的坑。另外,由于软硬件环境、技术栈、以及产品逻辑都没法做到完全一致,这些都会导致同样的业务场景,就算用相同的技术方案也会面临不同的问题,这些坑还得一个个趟。
因此,这篇文章我会将重点放在基础知识、通用思路、和我曾经实践过的有效经验上,希望让你对高并发有更深的理解。
2 、高并发系统设计的目标是什么?
先搞清楚高并发系统设计的目标,在此基础上再讨论设计方案和实践经验才有意义和针对性。
2.1 宏观目标
高并发绝不意味着只追求高性能,这是很多人片面的理解。从宏观角度看,高并发系统设计的目标有三个:高性能、高可用,以及高可扩展。
1、高性能:性能体现了系统的并行处理能力,在有限的硬件投入下,提高性能意味着节省成本。同时,性能也反映了用户体验,响应时间分别是100毫秒和1秒,给用户的感受是完全不同的。
2、高可用:表示系统可以正常服务的时间。一个全年不停机、无故障;另一个隔三差五出现上事故、宕机,用户肯定选择前者。另外,如果系统只能做到90%可用,也会大大拖累业务。
3、高扩展:表示系统的扩展能力,流量高峰时能否在短时间内完成扩容,更平稳地承接峰值流量,比如双11活动、明星离婚等热点事件。
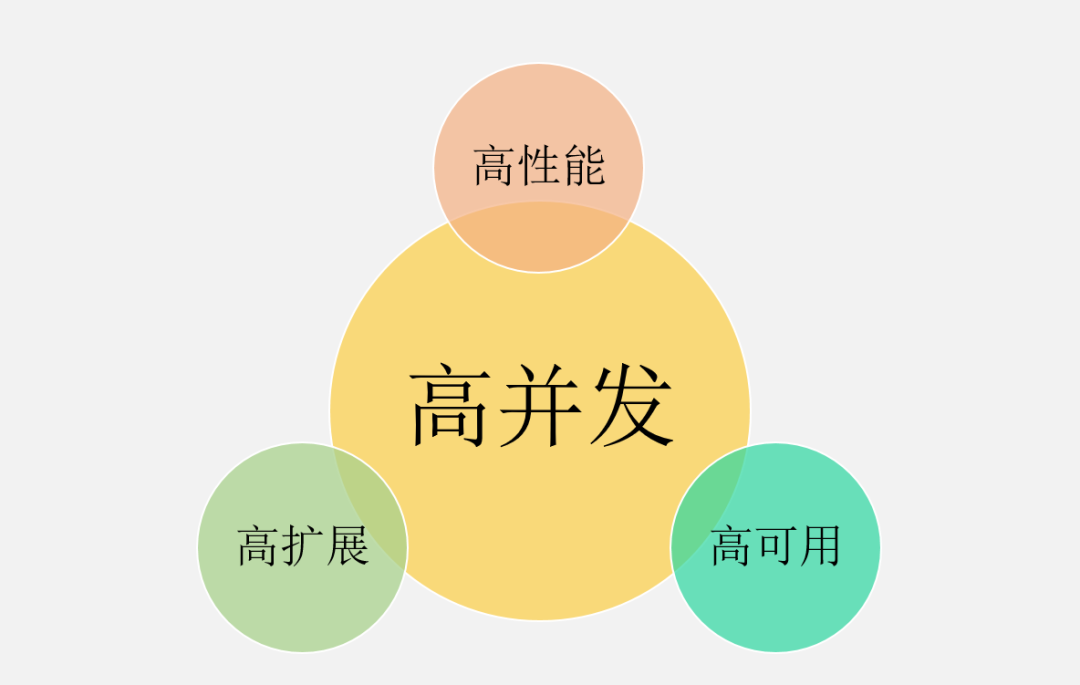
这3个目标是需要通盘考虑的,因为它们互相关联、甚至也会相互影响。
比如说:考虑系统的扩展能力,你会将服务设计成无状态的,这种集群设计保证了高扩展性,其实也间接提升了系统的性能和可用性。
再比如说:为了保证可用性,通常会对服务接口进行超时设置,以防大量线程阻塞在慢请求上造成系统雪崩,那超时时间设置成多少合理呢?一般,我们会参考依赖服务的性能表现进行设置。
2.2 微观目标
再从微观角度来看,高性能、高可用和高扩展又有哪些具体的指标来衡量?为什么会选择这些指标呢?
性能指标
通过性能指标可以度量目前存在的性能问题,同时作为性能优化的评估依据。一般来说,会采用一段时间内的接口响应时间作为指标。
1、平均响应时间:最常用,但是缺陷很明显,对于慢请求不敏感。比如1万次请求,其中9900次是1ms,100次是100ms,则平均响应时间为1.99ms,虽然平均耗时仅增加了0.99ms,但是1%请求的响应时间已经增加了100倍。
2、TP90、TP99等分位值:将响应时间按照从小到大排序,TP90表示排在第90分位的响应时间, 分位值越大,对慢请求越敏感。
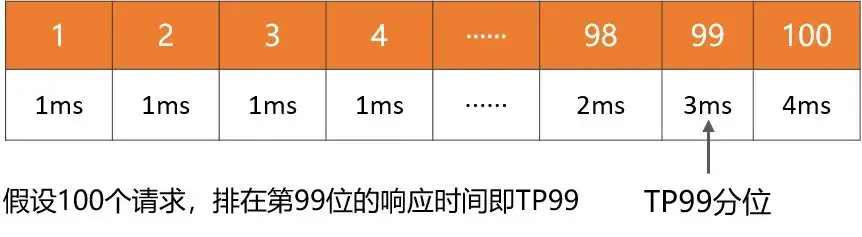
3、吞吐量:和响应时间呈反比,比如响应时间是1ms,则吞吐量为每秒1000次。
通常,设定性能目标时会兼顾吞吐量和响应时间,比如这样表述:在每秒1万次请求下,AVG控制在50ms以下,TP99控制在100ms以下。对于高并发系统,AVG和TP分位值必须同时要考虑。
另外,从用户体验角度来看,200毫秒被认为是第一个分界点,用户感觉不到延迟,1秒是第二个分界点,用户能感受到延迟,但是可以接受。
因此,对于一个健康的高并发系统,TP99应该控制在200毫秒以内,TP999或者TP9999应该控制在1秒以内。
Synchronized 相关问题
问题一:Synchronized 用过吗,其原理是什么?
问题二:你刚才提到获取对象的锁,这个“锁”到底是什么?如何确定对象的锁?
问题三:什么是可重入性,为什么说 Synchronized 是可重入锁?
问题四:JVM 对 Java 的原生锁做了哪些优化?
问题五:为什么说 Synchronized 是非公平锁?
问题六:什么是锁消除和锁粗化?
问题七:为什么说 Synchronized 是一个悲观锁?乐观锁的实现原理又是什么?什么是
问题八:乐观锁一定就是好的吗?
可重入锁 ReentrantLock 及其他显式锁相关问题
问题一:跟 Synchronized 相比,可重入锁 ReentrantLock 其实现原理有什么不同?
问题二:那么请谈谈 AQS 框架是怎么回事儿?
问题三:请尽可能详尽地对比下 Synchronized 和 ReentrantLock 的异同。
问题四:ReentrantLock 是如何实现可重入性的?
问题五:除了 ReetrantLock,你还接触过 JUC 中的哪些并发工具?
问题六:请谈谈 ReadWriteLock 和 StampedLock。
问题七:如何让 Java 的线程彼此同步?你了解过哪些同步器?请分别介绍下。
问题八:CyclicBarrier 和 CountDownLatch 看起来很相似,请对比下呢?
Java 线程池相关问题
问题一:Java 中的线程池是如何实现的?
问题二:创建线程池的几个核心构造参数?
问题三:线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗?
问题四:既然提到可以通过配置不同参数创建出不同的线程池,那么 Java 中默认实现好的线程池又有哪些呢?请比较它们的异同。
问题五:如何在 Java 线程池中提交线程?
Java 内存模型相关问题
问题一:什么是 Java 的内存模型,Java 中各个线程是怎么彼此看到对方的变量的?
问题二:请谈谈 volatile 有什么特点,为什么它能保证变量对所有线程的可见性?
问题三:既然 volatile 能够保证线程间的变量可见性,是不是就意味着基于 volatile 变量的运算就是并发安全的?
问题四:请对比下 volatile 对比 Synchronized 的异同。
问题五:请谈谈 ThreadLocal 是怎么解决并发安全的?
问题六:很多人都说要慎用 ThreadLocal,谈谈你的理解,使用 ThreadLocal 需要注意些什么?
如何学习并发编程
学习java并发就像进入了另外一个学习领域,就像学习一门新的编程语言,或者是学习一套新的语言概念,要理解并发编程,其难度跟理解面向对象编程难度差不多。你花一点功夫,就可以理解它的基本机制,但是要想真正掌握它的本质,就需要深入的学习与理解。最后在分享一个并发编程知识的学习导图给大家!
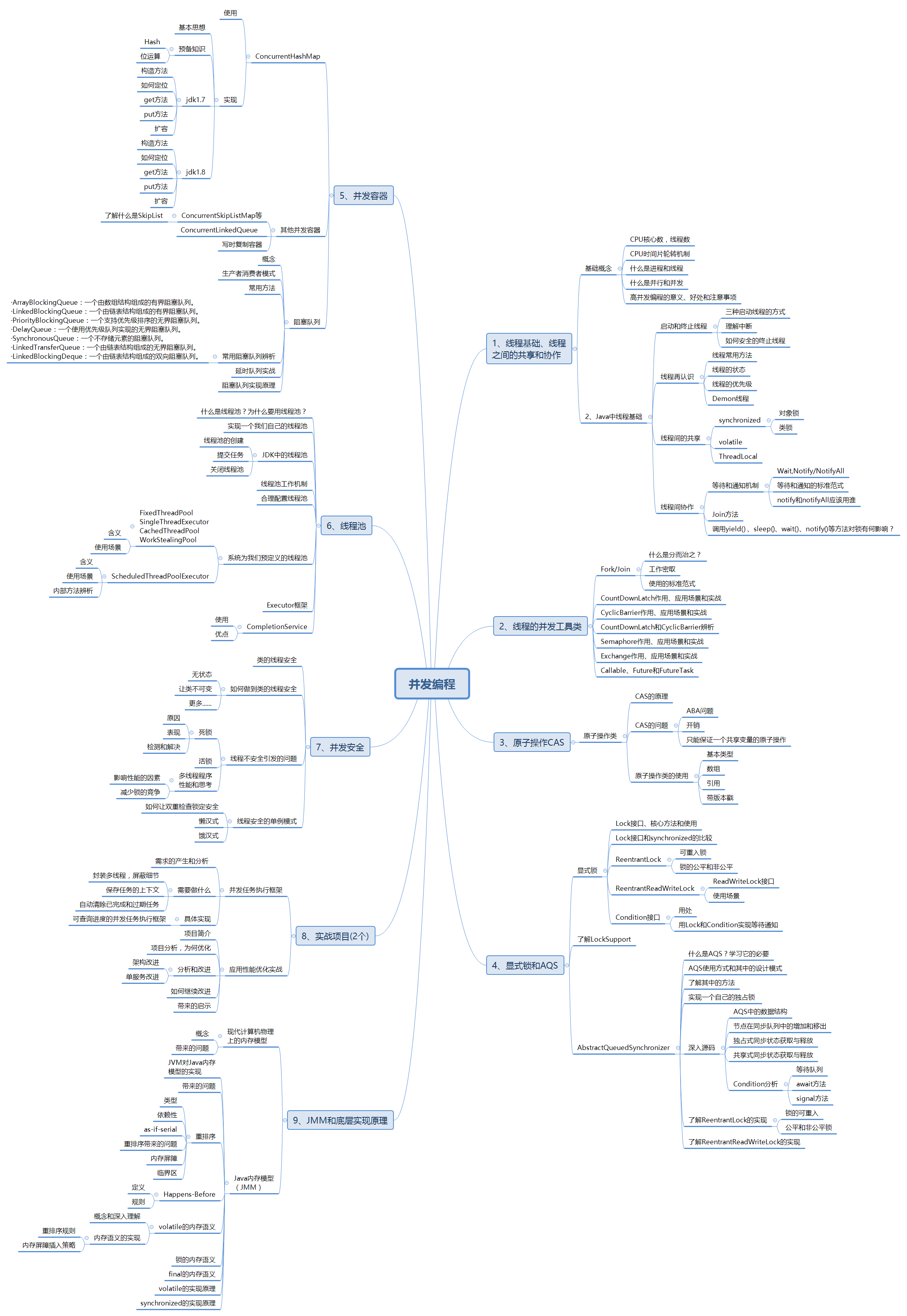
2019版多线程与高并发(马士兵)
各位同学,大家好,这是首次使用比较口语化的文字形成-本书,其实也不知道效果如何,希望各位收到书本后能够多提意见和建议。同时也请大家体谅,由于时间关系和忙碌程度,暂时只能总结成为口语化的形式,后面时间充裕了,将会以书面语言的方式进行重新更新。
线程的基本概念
首先给大家交代- -下我们2019年这个版本给大家讲哪些内容,这个版本主要集中在多线程和高并发这两大块,这两大块儿是现在面试问的越来越多,也是相对-一个初级的程序员向中高级迈进的必须要踏过的一-个坎儿。
volatile与CAS
volatile
我们先来看这个volatile的概念,volatile它是什么意思。现在像大的互联网企业的面试,基本上volatile是必会的,有时候他也不会太问,认为你应该会,但是中小企业也就开始问这方面的问题。
我们来看一下这个小程序,写了-一个方法啊,首先定义了-个变布尔类型等于true ,这里模拟的是一个服务器的操作,我的值为true你就给我不间断的运行,什么时候为false你再停止。测试new Thread启动-个线程,调用m方法,睡了-秒,最后running等于false ,运行方法他是不会停止的。如果你要把volatile打开,那么结果就是启动程序-秒之后他就会m end停止。( volatile就是不停的追踪这个值,时刻看什么时候发生了变化)

Atomic类和线程同步新机制
今天,我们继续讲-个Atomic的问题 ,然后开始讲除synchronized之外的别的锁。在前面内容我们讲了synchronized. volatile. Atomic和CAS , Atomic我们只是讲了-个开头还没有讲完,今天我们继续。
像原来我们写m++你得加锁,在多线程访问的情况下,那现在我们可以用Atomicinteger了,它内部就已经帮我们实现了原子操作。直接写count. incrementAndGet(: /count1++这个就相当于count++.原来我们对count是需要加锁的, 现在就不需要加锁了。
我们看下面小程序,模拟,我们计一个数,所有的线程都要共同访问这个数count值,大家知道如果所有线程都要访问这个数的时候,如果每个线程给它往上加了10000 ,你这个时候是需要加锁的,不加锁会出问题。但是,你把它改成AtomicInteger之后就不用在做加锁的操作了,因为incrementAndGet内部用了cas操作,直接无锁的操作往上递增,有同学可能会讲为什么要用无锁操作啊,原因是无锁的操作效率会更高。

LockSupport、淘宝面试题与源码阅读方法论
首先我们简单回顾一下前面三节课讲的内容 ,分别有线程的基本概念、synchronized. volatile.AtomicXXX、各种JUC同步框架(ReentrantLock. CountDownLatch. CyclicBarrier, Phaser.ReadWriteLock- StampedLock. Semaphore. Exchanger. LockSupport) ,其中synchornized重点讲了-下,包括有synchor nized的底层实现原理、锁升级的概念(四种状态:无锁、偏向锁、轻量级锁重量级锁) , volatile我们讲了可见性和禁止指令重排序如何实现。

AQS源码阅读与强软弱虚4种引用以及ThreadLocal原理与源码
今天咱们继续讲AQS的源码,在上节课我教大家怎么阅读AQS源码。跑不起来的不读。解决问题就好一目的性。- -条线索到底、无关细节略过,读源码的时候应该先读骨架,比如拿AQS来说,你需要了解AQS是这么一一个数据结构,你读源码的时候读起来就会好很多, 在这里需要插-句,从第一章到本章,章章的内容都是环环相扣的,没学习前边,建议先去补习- -下前面的章节。

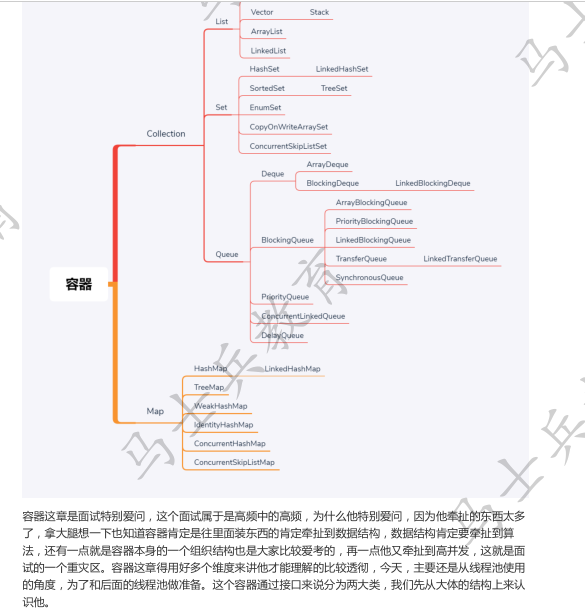
并发容器
今天是第六天了,这节课本来想上-个大而全的课,后来发现这个实在目标太大了,大而全的概念就是上节课讲到的那张容器图中的每一个都讲的非常的细致,然后去谈他们的源码。但是如果这么讲的话我们高井发的课就讲不完了,所以也别着急,后面单独开门课来讲集合,集合的发展历程,现在为什么讲这个并发容器呢,主要是为了线程池做准备,线程池里有一个参数就是用并发容器来做你工作任务的容器。
线程池
今天这节课呢,我们通过- -道面试把前面讲的哪些基础复习一下,然后再开始线程池这部分的内容,我们一点一点来看。
这道面试题呢实际上是华为的一-道面试题,其实它里面是一道填空题 ,后来就很多的开始考这道题,这个面试题是两个线程,第一个线程是从1到26 ,第二个线程是从A到- -直到Z ,然后要让这两个线程做到同时运行,交替输出,顺序打印。那么这道题目的解法有非常多。

线程池与源码阅读
第一个我们讲了一个Executor这个接口,大家回顾-下这个接口是干什么使的,把线程的定义和执行分开,主要来做线程的执行接口。在这他下面有一个整个的这 个线程池的生命周期,它里面的方法都给他定义全的接口ExecutorService ,他下面还有AbstractExecutor这个没有和大家说,这个无所谓了,是为了哪些个子类做准备的。


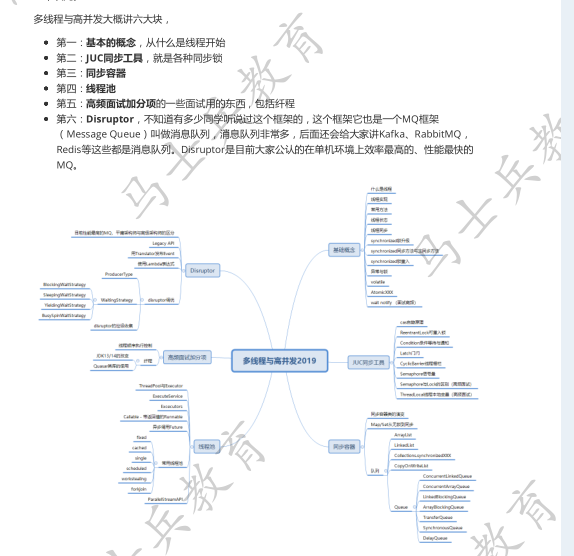
JMH与Disruptor
今天我们讲两个内容,第一个是IMH ,第二个是Disruptor.这两个内容是给大家做更进一步的这种多线程和高并发的一些专业上的处理。生产环境之中我们很可能不自己定义消息队列,而是使用Disruptor.我们生产环境做测试的时候也不是像我说的那样写一个start写一 个end就测试完了。 在这里给大家先介绍专业的MH测试工具,在给大家介绍Disruptor号称最快的消息队列。



电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)