
数据分析项目|淘宝用户行为分析(Python+可视化)
数据分析项目|淘宝用户行为分析(Python+可视化)
一、认识数据
了解数据的来源、字段等信息
1.1 数据来源及介绍
本数据来源于阿里云天池,是其随机选择约100万用户在2017年11月25日至12月3日之间发生的行为记录,具有包括点击、购买、加购物车和收藏商品的行为。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。
1.2 数据格式
二、提出问题
针对不同的数据提出问题,总结分析思路
了解到所给数据集只有5个字段、时间维度限制在9天内、商品数据均为脱敏数据、行为数据只有4种等,具有一定的局限性。结合电商平台分析指标和AARRR漏斗分析模型,比较有分析价值的是用户行为和时间这两个维度。可以初步计划从用户行为习惯、用户消费习惯和用户价值等方分析。
2.1 用户行为方面
- 页面浏览量PV和独立访客数UV如何变化?和时间有关系吗?
- 用户的平均访问深度是多少?平台的跳失率怎么样?
- 用户从浏览到购买会经历哪些过程?最终的转化率如何?
- 平台用户留存率怎么样?
2.2 用户消费方面
- 平台的用户付费率是多少?用户复购的情况怎么样?
- 平台商品销售情况是怎么样?
- 商品销售之间有没有一定的联系?
2.3 用户价值方面
- 如何判断用户价值?针对不同用户如何采取不同的运营策略?
将上述问题整理如下,便于之后有针对性的进行分析: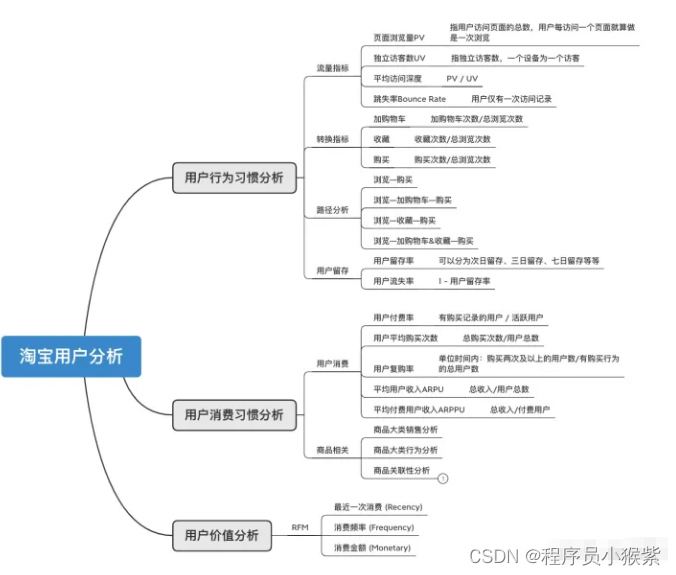
三、数据处理
处理数据,主要包括对异常值、重复值和缺失值的处理
3.1 数据导入
# 源数据共有五个字段,为其定义英文字段
columns = ['user_id','item_id','category_id','behavior_type', 'timestamp']
# 迭代读取数据
df = pd.read_csv('UserBehavior.csv', names=columns, iterator=True)
loop, chunkSize, chunks = True, 10000000, [] # 分块大小为1000W
while loop:
try:
chunk = df.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print('Iteration is stopped.')
data = pd.concat(chunks, ignore_index = True)
不需要全部数据的话,可以在读取数据之后通过get_chunk( ) 函数获取所需数据,如:
data = df.get_chunk(1000000) # 获取100W数据
大家可能会有疑问,这里是不是可以用Pandas的sample( )函数随机抽样比较好,我个人觉得最好不要随机抽样,稍后会解释原因。
3.2 了解数据
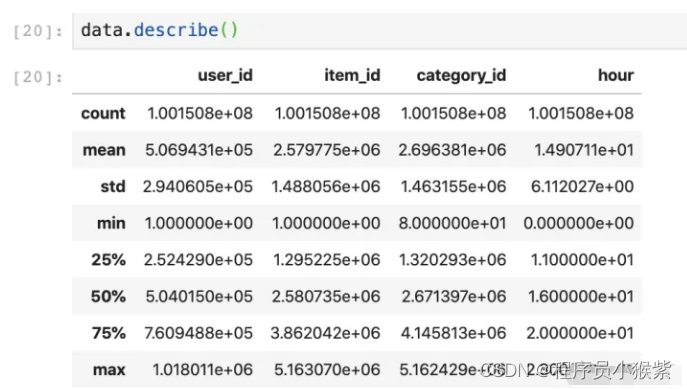
可以通过data.head( ) / http://data.info / data.describe( )等快速了解数据
通过对数据查看,发现原数据集是按照user_id排好序的,如果之前采用随机抽样的话,可能会破坏原有数据的信息,比如用户A在浏览多次后最终完成下单支付,随机抽样的话,可能会错过用户购买记录,最终导致数据分析不准确。
数据集原有的时间列是采用时间戳存储的,为了方便后续分析,这里将原有时间戳转为北京时间,并从中抽取出日期、时间和小时数据,处理代码如下:
# 将时间戳转换为北京时间
data['timestamp'] = pd.to_datetime(data.timestamp, unit='s') + datetime.timedelta(hours = 8)
# 将日期提取出来,这种方法提取出的日期需要进一步处理为datetime64格式
data['date'] = data['timestamp'].dt.date
data['date'] = pd.to_datetime(data['date'])
# 将时间取出来
data['time'] = data['timestamp'].dt.time
# 将小时提取出来
data['hour'] = data['timestamp'].dt.hour
格式修改完后数据如下: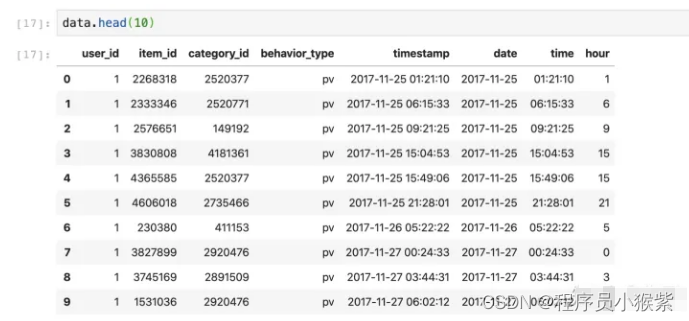
3.3 缺失值处理
# 判断是否有缺失值
data.isnull().sum()
阿里给的数据还是比较规范的,没有缺失值。如果有缺失值的话,需要对其填补或者删除等。
3.4 异常值处理
此数据集的异常值最有可能出现在时间范围上,这里筛选出符合时间范围的数据
# 异常值处理,时间超出给定范围的即为异常值
data = data[(data['timestamp'] >= '2017-11-25') & (data['timestamp'] < '2017-12-4')]
3.5 重复值处理
将数据集中重复数据删除
# 查看是否有重复值
data.duplicated().value_counts()
# 删除重复值
data = data.drop_duplicates(keep = 'first',inplace = False) # 去除重复值
3.6 整理数据
因为之前删除掉了异常值和重复值,会缺失部分数据索引,这里给数据按照时间和用户id排序,并重新索引。
# 重新排序、索引
data = data.sort_values(by = ['timestamp','user_id'], ascending=True)
data = data.reset_index(drop=True)
四、数据分析
根据之前提出的问题对数据集进行分析
(一)用户行为习惯分析
4.1.1 页面访问量PV和独立访客数UV
下面按照日期分析UV、PV的变化趋势:
# 定义函数,可以通过接收的key值进行分组,返回pv和uv
def cal_pvuv(key = ''):
pv = data.groupby(key)['user_id'].count()
pv.name = 'pv'
uv = data.groupby(key)['user_id'].apply(lambda x: x.drop_duplicates().count())
uv.name = 'uv'
return pd.concat([pv,uv], axis = 1).reset_index()
pvuv_daily = cal_pvuv('date') # 得到按日期聚合的pv和uv数据
pvuv_daily.plot(x = 'date', secondary_y = 'uv', grid = True, figsize =(10, 5))
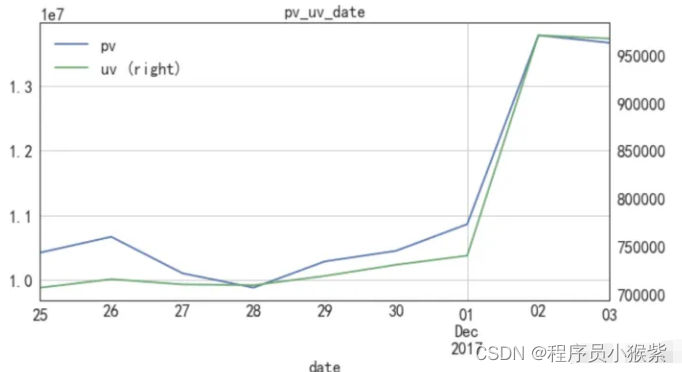
从图可以看出pv和uv整体变化趋势相同,11月25日到12月1日之间,uv变化不明显,pv在11月26日达到小高峰,与当天刚好是周六放假密切相关。从12月1日周四开始,pv和uv涨幅明显,12月2日和12月3日与上周相比较,环比增长率31.4%,uv环比增长率35.7%,可见本次活动宣传和引流效果不错,对实际销售情况的影响将在下个模块分析。
接下来按照小时去分析用户的行为习惯:
pvuv_hour = cal_pvuv('hour')
pvuv_hour.plot(x = 'hour', secondary_y = 'uv', grid = True, figsize = (10, 5),
xticks = [x for x in range(24)], title = 'pvuv_hour')

从上图可以看出用户的活跃时间从上午10点持续到晚上10点,尤其是从下午6点开始呈现明显上升趋势,到晚上九点左右达到峰值,这符合大多数人的日常作息规律。由此可以建议店铺调整客服工作时间,增加下午6点到晚上10点的客服数量,促使用户从浏览向购买转换。
4.1.2 平均访问深度和跳失率
# 计算总用户数量
uv_count = len(data.user_id.unique())
# 计算总的页面浏览数量
pv_count = data[data.behavior_type == 'pv'].shape[0]
# 计算平均访问深度
print('Average access depth is %.1f' % (pv_count / uv_count))
# 计算每个用户浏览的页面数
pv_count_perUser = data[data['behavior_type'] == 'pv'].groupby('user_id')['behavior_type']
.count().reset_index().rename(columns = {'behavior_type':'pv_count'})
# 计算只浏览过一次界面的用户数量
bounce_user_count = pv_count_perUser[pv_count_perUser['pv_count'] == 1].shape[0]
print('Bounce Rate is %.3f%% ' % (100 * (bounce_user_count / uv_count))
可以得到用户的平均访问深度为90.8,也就是说在11月25到12月3日9天内平均每个用户每天要访问10个界面,可见淘宝用户粘度很高。
按照流失率=只浏览一次界面/总用户计算的话,发现流失人数只有679人,Bounce Rate 是 0.069% 左右,所以平台整体流失率是相当低的。我觉得可以考虑将只有浏览记录再无其他行为的用户视为流失用户,分析此类人群的跳失原因。
之后可以细分到各个商品种类以及各个商品,计算其用户跳失率并采取相应的措施。
4.1.3 用户转化情况
接下来分析用户从浏览到最后下单的转化情况,首先先了解一下用户浏览、收藏、加购物车和购买行为的整体分布趋势。
pv_detail = data.groupby(['behavior_type','hour'])['user_id'].count().reset_index().rename(columns={'user_id':'total_behavior'})
fig, axes = plt.subplots(2, 1, figsize = (10,8), sharex = True)
sns.pointplot(x = 'hour',y = 'total_behavior', hue = 'behavior_type', data = pv_detail, ax = axes[0])
sns.pointplot(x = 'hour',y = 'total_behavior', hue = 'behavior_type', data = pv_detail[pv_detail.behavior_type!='pv'], ax = axes[1])
axes[0].set_title('different_behavior_count')
axes[0].grid()
axes[1].set_title('different_behavior_count_exceptpv')
axes[1].grid()

四种用户行为的波动情况基本一致,其中浏览页面pv数远大于其他三项,用户加购物车、收藏和购买数依次降低,可以通过漏斗模型整体分析用户转化情况。
从浏览到加入购物车的转换率为6.25%,收藏商品的转换率为3.26%,最后购买的转换率为2.23%左右。
4.1.4 用户行为路径分析
因为数据中用户行为分为四类,按照浏览在前,购买最后的话,一共有16种组合,利用桑基图分析如下所示:

一般认为购买之前必须得先浏览,因为所给数据是截取给定时间内的,所以会存在上图下方unpv的情况。现在只考虑最后产生购买行为的情况,用户从浏览到最后购买其实只有(1)浏览-购买、(2)浏览-加购物车-购买、(3)浏览-收藏-购买、(4)浏览-加购物车-收藏-购买(浏览-收藏-加购物车-购买)等四种情况,再次利用桑基图分析如下:
由上图可知,大多数购买行为发生在浏览之后,并没有加购物车、收藏等行为。
4.1.5 用户留存分析
下面计算本数据中的用户留存:
# 计算n日留存率
def cal_retention(n = 1):
# 用于记录出现过的user_id
user_list = []
# 取最后一天的前N天
cal_date = pd.Series(data['date'].unique()).sort_values()[:-n]
# 用于存储最后留存率结果
retention_rates = []
for to_date in cal_date:
# 通过与已经有记录的用户列表的集合对比,识别新用户
new_user_list = set(data[data['date'] == to_date]['user_id']) - set(user_list)
# 用于存储最后留存率结果
user_list.extend(new_user_list)
# 第n天留存情况
user_ndate = data[data['date'] == to_date + timedelta(n)]['user_id'].unique()
retention_cnt = 0
for user_id in user_ndate:
if user_id in new_user_list:
retention_cnt += 1
retention_rate = retention_cnt / len(new_user_list)
# 汇总N日留存数据
retention_rates.append(retention_rate)
u_retention = pd.Series(retention_rates, index = cal_date)
return u_retention
将每日的留存率聚合后如下图所示:
可视化后如下:
因为所给数据是截取的部分数据,这里暂认为11月25日所有的登录用户都是新用户,所以11月25日的用户留存率最高。从之前的PV和UV分析可推测平台从12月1日开始搞活动,进而吸引用户登录,所以11月30日和12月1日用户留存率增加。
(二)用户消费习惯分析
4.2.1 用户付费率PUR(Paying User Rate)
根据用户付费率 = 有购买记录的用户 / 活跃用户计算:
# 分析用户付费率
paying_user_count = data[data.behavior_type == 'buy'].user_id.unique().shape[0]
print('Paying user Rate is %.2f%%' % ( 100 * paying_user_count / uv_count))
得到用户付费率为67.94%,淘宝用户付费率还是比较高的。
4.2.2 用户购买次数
根据总购买次数 / 总付费用户可得到付费用户平均消费次数为3次,下面进一步分析各购买次数的用户分布:
由上图可知,购买次数为1次的用户数量最多,大约有88%的用户购买次数在5次以内,购买次数在10次以内的用户占总付费用户的98%。
4.2.3 用户复购率
根据用户复购率 = 多次购买用户数 / 总付费用户计算:
#每个付费用户的购买次数
peruser_paying_count = data[data['behavior_type'] == 'buy'].groupby('user_id').count()['behavior_type']
.reset_index().rename(columns={'behavior_type':'paying_count'})
# 复购用户数量 通过筛选支付次数>=2
paying_retention_user_count = peruser_paying_count[peruser_paying_count['paying_count'] >= 2]['user_id'].count()
print('Buyer Retention Rate %.2f%%' % (100 * paying_retention_user_count / paying_user_count))
可得用户复购率为66.01%。还可以计算用户复购的间隔时间:
buyer_retention_diff = data[data.type == 'buy'].groupby('user_id').date.apply(lambda x: x.sort_values().diff(1).dropna())
buyer_retention_diff = buyer_retention_diff.map(lambda x: x.days)
buyer_retention_diff.describe()

箱线图表示不太明显,根据describe()返回值分析,用户复购平均间隔1.2天,有超过50%的用户在同一天内产生多笔交易。
4.2.4 商品大类销售分析
分析商品浏览TopN和商品销售TopN的数据:
# 定义计算销售/浏览TopN的函数
def cal_topN (index, behavior_type, n):
# 创建透视表
topN = pd.pivot_table(data, index = index, values = 'user_id', columns = 'behavior_type', fill_value=0,
aggfunc='count', margins = True).sort_values(by = behavior_type, ascending = False).fillna(0).head(n)
topN['paying_rate'] = topN.apply(lambda x: x.buy / x.pv, axis = 1).apply(lambda x: format(x, '.2%'))
topN = topN[['pv','buy','paying_rate']]
return topN
分别查看商品浏览量前10和商品销售量前10:
# 计算商品大类浏览量前10
category_pv_topN = cal_topN('category_id', 'pv', 10)
# 计算商品大类购买量前10
category_buy_topN = cal_topN('category_id', 'buy', 10)

针对支付率较高的商品应该分析其原因,思考是否能拓展到其他商品上去。
进一步查看购买量前10和浏览量前10的交集:
# 查看购买量和浏览量前10的交集
category_pv_buy_topN = pd.merge(category_pv_topN, category_buy_topN,
on = 'category_id', how ='inner')

由上图可知存在部分商品浏览量高但购买量较低,应进一步分析原因。
此部分只对商品大类进行分析,可以套用此代码,将‘categoryid’换为‘item_id’进一步分析具体商品销售情况。
4.2.5 商品大类行为分析
即针对所有产生购买行为的商品种类,分析其从浏览到最后购买发生的行为数量和最终购买量的关系。
# 筛选出产生购买行为的数据
data_buy = data[data['behavior_type'] == 'buy']
# 计算各种商品大类的交易数
buy_category = data_buy[['category_id','behavior_type']].groupby('category_id')
.count().rename(columns = {'behavior_type':'buy_count'})
# 整理各种商品大类的交易数
buy_category = buy_category.sort_values('buy_count',ascending=False).reset_index()
# 将产生购买行为的数据和原数据外连接,进而得到有购买记录的商品大类的其他行为信息
behav_category = pd.merge(data_buy[['user_id','category_id']], data,
on = ['user_id','category_id'], how = 'left')
# 计算各种商品大类的行为数
behav_category = behav_category[['category_id', 'behavior_type']].groupby('category_id').count()
.reset_index().rename(columns={'behavior_type':'behavior_count'})
# 统计分析各种商品大类的购买数和产生行为数
buy_behav_category = pd.merge(buy_category, behav_category, on = 'category_id', how = 'inner')
buy_behav_category = buy_behav_category.assign(behav_per_buy = buy_behav_category['behavior_count'] / buy_behav_category['buy_count'])
可视化后如下:
由上图可知,大部分购买行为平均只会产生20次以内的行为,可以据此对商品初步分类,以实施不同的运营策略。
- 购买量大、行为数多(上图右上部分):推测该区域商品是快销产品或高频刚需物品,不仅销量大而且可选择品牌众多,如食品、日用品、护肤品和衣物服装等。平台可以据此将该商品类别建立专区,可以同时浏览查看该类别下的诸多产品,减少用户的多次搜索,提升用户体验度
- 购买量大、行为数少(上图左上部分):推测该区域商品主要为高频产品,行为数少说明可能品牌种类少、被少数品牌垄断,或者是用户对某品牌建立了一定的依赖度等等。此类区域的商品,用户决策相对会轻松,因此应着重快速让用户触达商品,可以优先展示用户购买过的品牌等。
- 购买量小、行为数少(上图左下部分):大多数商品大类都集中分布在这个区域,应该针对具体类别具体分析。
- 购买量小、行为数多(上图右下部分):推测该区域商品低频或者商品贵重,用户需要货比三家、再三考虑后下单,对此可以改善商品的介绍方式,如现在的品牌直播,让用户更快速、直观的了解商品。
4.2.6 商品关联性分析
之后准备做专题分析,这里先占个坑…
(三)用户价值分析
这里利用RFM模型去分析用户价值,以便针对不同用户采取不同措施。RFM模型的概念如下:
- R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
- M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。

由于所给数据集不包含用户购买金额,所以只考虑最近消费时间R和购买频率F,将客户分为有价值的客户、保持客户、发展客户和挽留客户。
# 1 R: 最近一次消费距今天数统计
nowDate = datetime.datetime(2017,12,4) # 假定当前时间为(2017,12,4)
user_recent_pay = data[data['behavior_type'] == 'buy'].groupby('user_id')['date']
.apply(lambda x: nowDate - x.sort_values().iloc[-1])
user_recent_pay = user_recent_pay.reset_index().rename(columns={'date':'recent'})
# 2 F: 消费次数统计
user_freq = data[data['behavior_type'] == 'buy'].groupby('user_id').date.count()
user_freq = user_freq.reset_index().rename(columns={'date':'freq'})
# 3 通过user_id将R、F合并
rfm = pd.merge(user_recent_pay, user_freq, left_on='user_id', right_on='user_id')
# 4 给R、F打分score
rfm['score_recent'] = pd.qcut(rfm['recent'], 2, labels = ['1', '0'])
rfm['score_freq'] = pd.qcut(rfm['freq'], 2, labels = ['0', '1'])
# 5 得分拼接
rfm['rfm'] = rfm['score_recent'].str.cat(rfm['score_freq'])
# 6 根据RFM分类
rfm = rfm.assign(user_type = rfm['rfm']
.map({'11':'重要客户', '01':'保持客户', '10':'发展客户', '00':'挽留客户'}))
可视化后如下图所示:
由上图可知重要客户和发展客户比例相当,各占总用户的三分之一左右,挽留客户最少。
五、总结与建议
总结分析的结论并提出一些建议
5.1 用户行为分析
- 12月2日12月3日相较于其他日期用户活跃度、各指标增长明显。与同样是周末的11月25日、11月26日pv环比增长率31.4%,uv环比增长率35.7%,推测是12月2日周五平台开始双十二预热活动或其他活动所致。
- 用户的活跃时间从10:00持续到晚上22:00,其中5:00-10:00和18:00-21:00是用户活跃度迅速增长的时段。21:00点左右达到一天峰值,这符合大多数人的日常作息规律,由此可以建议店铺调整客服工作时间,增加18:00-22:00点的客服数量,提升用户的购买率。仔细观察的话,可以发现10:00和15:00分别达到了一个小高峰,所以可以在这两个时间段开始推广活动等。
- 针对用户路径:
①浏览—购买路径占比高达72.2%,转化率为1.39%。可以分析访问量高的商品,吸引用户将其收藏、加购物车,以提高后续转化率等。
②浏览—加购物车—购买路径占比19.9%,转化率为10.0%,一般为提前加入购物车或者多件商品共同购买。此路径转化率较高,可以分析最后成交商品在用户加入购物车后的状态,是自身降价还是参与活动促销等;还可以根据同一订单内的商品分析其联系,作为商品推荐的一个参考依据。
③浏览—收藏—购买路径占比6.9%,转化率为8%。可以在收藏界面添加商品动态,或者向用户推送商品补货信息,提高商品转化率。
④浏览—加购—收藏—购买路径占比1%,转化率为14.9%。既加购又收藏可说明此类商品比较受用户欢迎,可以挖掘商品共性,扩大其他相似产品的曝光度。
5.2 用户消费分析
- 用户付费率达到67.94%,所有用户平均消费次数为2次。
- 针对付费用户来看,用户平均消费次数为3次,其中购买次数为1次的用户数量最多,大约有88%的用户购买次数在5次以内,购买次数在10次以内的用户占总付费用户的98%。
- 用户复购率为66%,用户复购平均间隔1.2天,有超过50%的用户在同一天内产生多笔交易。
- 通过比对商品大类浏览top10和商品大类销售top10可知,存在某些商品浏览量高但成交量相对较低,对此应该分析用户流失原因,对症下药;对于成交量高但浏览量相对较低的商品,是否应该考虑增加商品的曝光率等等。
- 观察得知商品大类4159072和1464116商品转换率较高,分别达到了10%和5%以上,应该进一步分析这些商品成交率高的原因,是否能推广到其它商品。
- 在不同日期的不同时间点,商品销量具有不同的表现,可进一步对商品按照时间维度进行挖掘分析,更加精准地投放商品广告。
- 商品发生购买前产生的用户行为在100次之内,可以进一步简化用户的购买流程,提升用户体验。
5.3 用户价值分析
此部分将用户分为四个维度,针对不同维度的用户应当采取不同的运营策略:
- 针对重要客户(近期有付费且经常付费),即忠实用户,他们可能不需要额外的刺激消费,可以关注其售后体验等,提升用户的消费满意度;
- 针对保持客户(经常付费但是已经在很久之前了),曾经的忠实用户面临流失的风险,对其可以进行适当的提醒,如消息推送,还可以了解其离开的原因,以采取相应措施。
- 针对发展客户(近期有付费但是次数很少,或者只有一次付费),即新用户或者黏性较低的用户,我们的目标是刺激他们消费,可以通过开展促销活动等措施。
- 针对挽留客户(很少付费而且在很久之前),即流失用户,需要挽回并刺激其消费。从另一方面来看,可以尝试寻找用户流失的原因,通过反馈来调整我们的产品。
最后
在学习python中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入python交流学习
多多交流问题,互帮互助,这里有不错的学习教程和开发工具。
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。
最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)