
LangFlow场景应用:电商客服自动化流程搭建教程
本文介绍了如何在星图GPU平台上自动化部署LangFlow镜像,快速搭建低代码AI应用开发环境。基于该平台,用户可通过可视化拖拽方式,轻松构建电商客服自动化流程,实现智能问答、订单查询与个性化推荐,有效提升客服效率与用户体验。
LangFlow场景应用:电商客服自动化流程搭建教程
1. 引言:当电商客服遇上AI编排工具
想象一下这个场景:你的电商店铺每天涌入上千条咨询,从“这件衣服有货吗”到“我买的手机怎么还没发货”,再到“这个护肤品适合敏感肌吗”。客服团队忙得焦头烂额,重复性问题占据了他们80%的时间,而真正需要人工处理的复杂问题却常常被淹没在信息洪流中。
这就是今天大多数电商客服面临的真实困境——人力成本高、响应速度慢、服务质量参差不齐。传统解决方案要么是简单的关键词回复机器人(体验生硬),要么是昂贵的企业级客服系统(部署复杂、定制困难)。
有没有一种方法,既能像搭积木一样灵活构建智能客服流程,又能快速对接企业内部的数据和模型,还不需要写大量代码?
LangFlow给出了肯定的答案。
LangFlow是一款基于LangChain的低代码可视化AI应用构建工具。如果说LangChain是AI应用的“乐高积木”,那么LangFlow就是那个让你无需看说明书就能轻松拼出各种造型的“智能拼装台”。它通过拖拽节点、连线连接的方式,让非技术背景的业务人员也能快速搭建复杂的AI工作流。
本文将带你一步步用LangFlow搭建一个完整的电商客服自动化流程。从简单的商品咨询回复,到复杂的订单状态查询,再到个性化的推荐服务,你会发现,原来AI客服可以如此简单、如此强大。
2. 准备工作:快速部署LangFlow环境
2.1 环境要求与一键部署
在开始搭建客服流程之前,我们需要先准备好LangFlow的运行环境。好消息是,整个过程比你想的要简单得多。
系统要求:
- 操作系统:Linux/Windows/macOS均可
- 内存:至少8GB(建议16GB以上)
- 存储:20GB可用空间
- Python版本:3.8或更高
快速部署步骤:
如果你使用的是CSDN星图镜像,那么LangFlow已经预装好了。直接启动容器即可:
# 如果你使用Docker部署
docker run -d -p 7860:7860 \
--name langflow-ai \
-v ./data:/data \
langflowai/langflow:latest
启动后,在浏览器中打开 http://localhost:7860 就能看到LangFlow的界面了。
如果你需要本地安装,也只需要几行命令:
# 创建虚拟环境(可选但推荐)
python -m venv langflow-env
source langflow-env/bin/activate # Linux/macOS
# 或 langflow-env\Scripts\activate # Windows
# 安装LangFlow
pip install langflow
# 启动服务
langflow run --host 0.0.0.0 --port 7860
2.2 界面初识:你的AI画布
第一次打开LangFlow,你会看到一个简洁的界面,主要分为三个区域:
- 左侧组件库:这里分类展示了所有可用的AI组件,就像工具箱一样
- 中间画布区:这是你的主战场,在这里拖拽组件、连线构建流程
- 右侧属性面板:选中组件后,在这里配置具体参数
默认情况下,画布上已经有一个简单的工作流示例。你可以先点击右上角的“运行”按钮试试效果,感受一下LangFlow的基本操作。
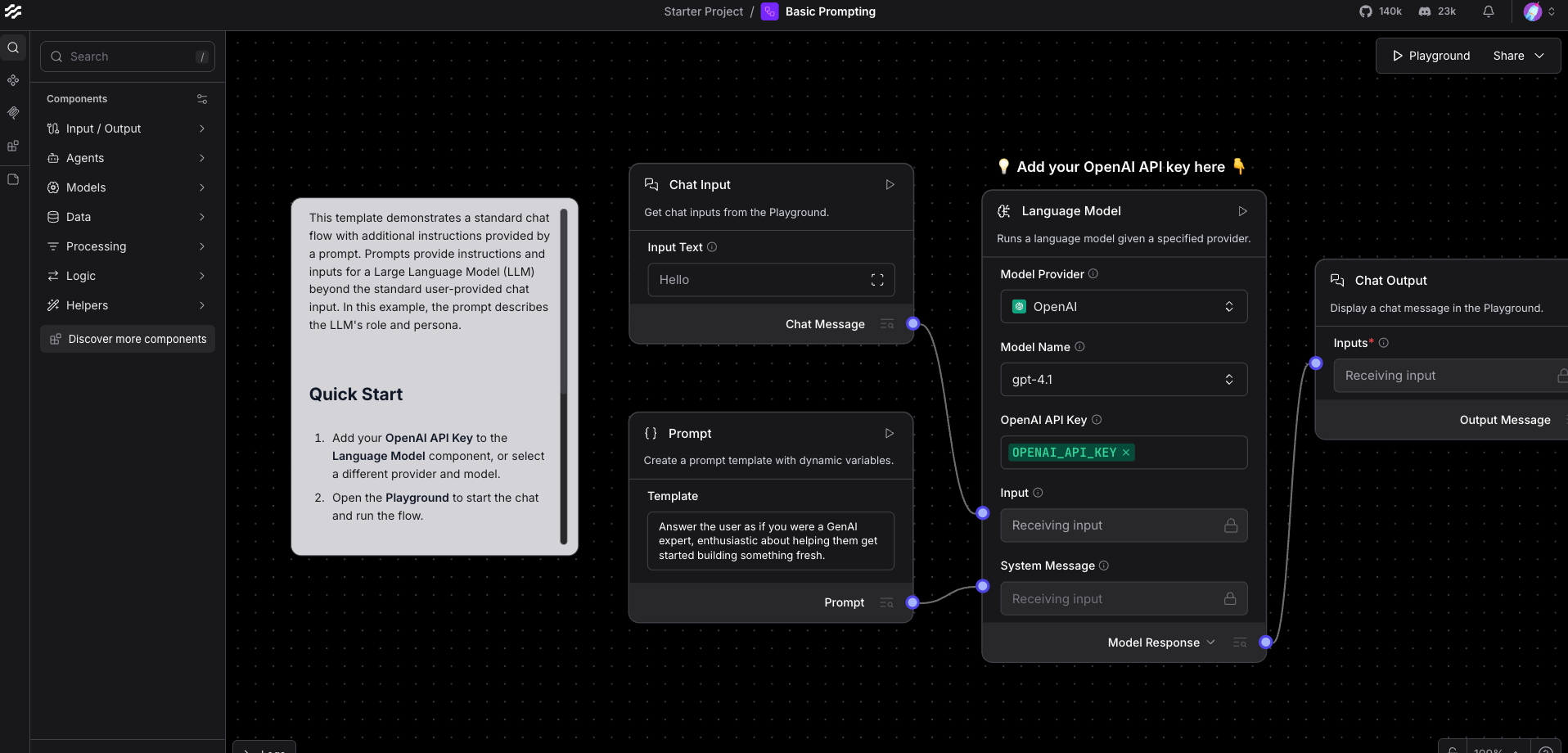
2.3 连接你的AI模型
LangFlow本身不提供AI模型,它需要连接外部的模型服务。对于电商客服场景,我们推荐以下几种方案:
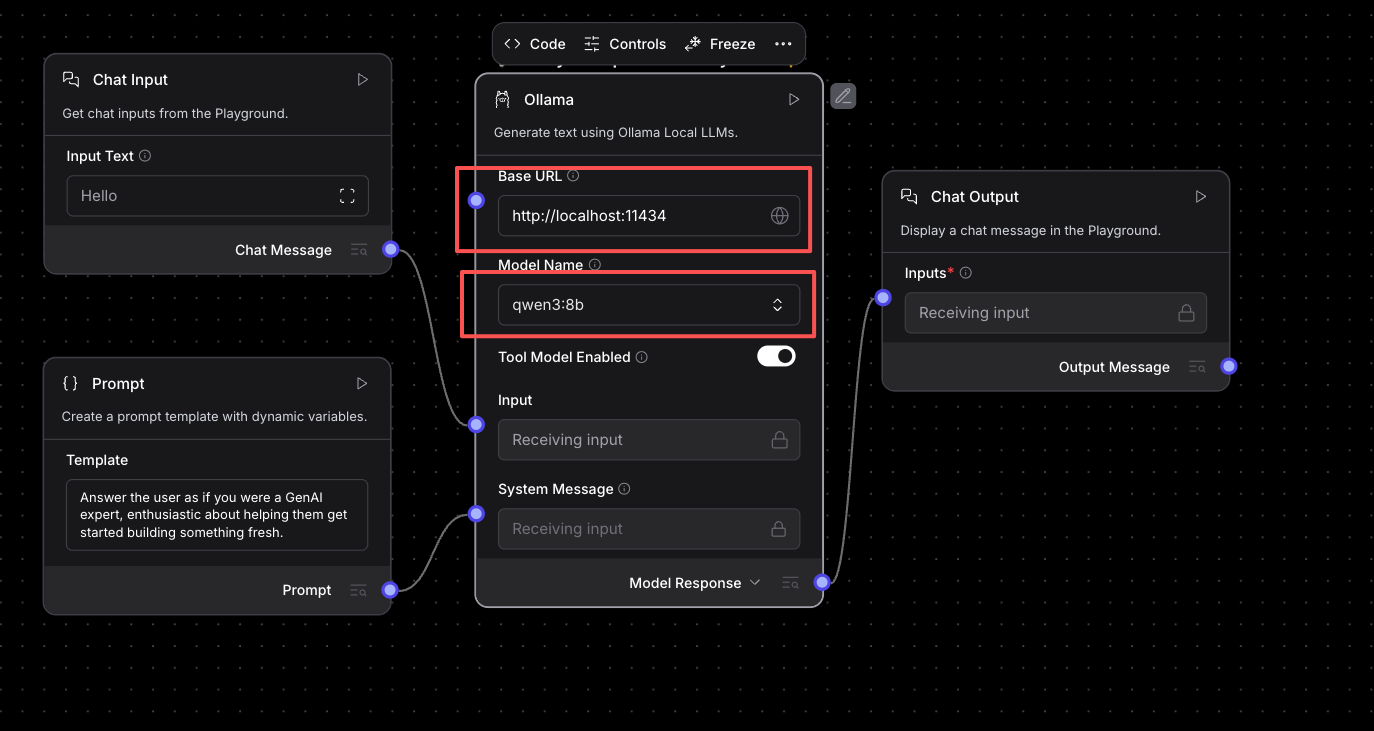
方案一:使用本地部署的Ollama(推荐给初学者)
如果你已经在容器中部署了Ollama,配置起来非常简单:
- 在左侧组件库找到“Models”分类
- 拖拽一个“Ollama”组件到画布
- 在右侧属性面板配置:
- Model: 选择你安装的模型,如
llama3:8b - Base URL: 通常是
http://localhost:11434 - Temperature: 设置为0.7(平衡创造性和准确性)
- Model: 选择你安装的模型,如
方案二:使用OpenAI兼容的API
如果你的公司有私有模型服务,或者使用第三方API:
# 如果你需要自定义模型组件,可以这样配置
from langflow.interface.custom_components import CustomComponent
from langchain_community.llms import OpenAI
class CustomOpenAILLM(CustomComponent):
def build_config(self):
return {
"model": {"display_name": "模型名称", "value": "gpt-4"},
"base_url": {"display_name": "API地址", "value": "https://api.openai.com/v1"},
"api_key": {"display_name": "API密钥", "password": True}
}
def build(self, model, base_url, api_key):
return OpenAI(model=model, base_url=base_url, api_key=api_key)
方案三:使用HuggingFace模型
对于开源模型爱好者,可以直接连接HuggingFace的推理端点:
from langchain_community.llms import HuggingFaceEndpoint
# 在LangFlow中配置
# Endpoint URL: https://api-inference.huggingface.co/models/meta-llama/Llama-2-7b-chat-hf
# Token: 你的HuggingFace Token
选择哪种方案取决于你的具体需求:
- 测试和原型开发:用Ollama最方便
- 生产环境:建议使用私有部署的模型服务
- 成本考虑:开源模型通常更经济
3. 搭建基础客服问答流程
3.1 第一步:创建商品知识库问答机器人
让我们从最简单的场景开始——用户询问商品信息。比如“这个手机有什么颜色?”“这件衣服的材质是什么?”
核心思路:
- 用户输入问题
- 系统从商品知识库中查找相关信息
- AI模型基于找到的信息生成回答
- 返回给用户
具体搭建步骤:
步骤1:准备商品数据
首先,我们需要一个商品知识库。假设我们有这样一个简单的CSV文件 products.csv:
product_id,name,category,price,colors,material,stock,description
1001,智能手机X,电子产品,2999,"黑色,白色,蓝色","玻璃+金属",50,"最新款智能手机,搭载AI芯片"
1002,棉质T恤,服装,99,"白色,灰色,藏青","100%纯棉",200,"舒适透气,适合日常穿着"
1003,蓝牙耳机,电子产品,399,"黑色,白色","塑料+硅胶",100,"降噪蓝牙耳机,续航20小时"
在LangFlow中,我们可以用“CSV Loader”组件加载这个文件。
步骤2:构建工作流
在LangFlow画布上,按顺序拖拽以下组件并连接:
- Text Input(文本输入)→ 用户输入问题的地方
- CSV Loader(CSV加载器)→ 加载商品数据
- Vector Store(向量存储)→ 将数据转换为可搜索的格式
- Retriever(检索器)→ 根据问题查找相关商品
- Prompt Template(提示模板)→ 设计回答的格式
- LLM Chain(LLM链)→ 连接模型生成回答
- Text Output(文本输出)→ 显示最终答案
连线顺序应该是:
- Text Input → Prompt Template(提供用户问题)
- CSV Loader → Vector Store → Retriever → Prompt Template(提供商品信息)
- Prompt Template → LLM Chain → Text Output
步骤3:配置关键组件
提示模板配置:
你是一个专业的电商客服助手。请根据以下商品信息回答用户的问题。
商品信息:
{context}
用户问题:{question}
请用友好、专业的语气回答,如果信息不足请如实告知。
回答:
LLM Chain配置:
- 选择你配置好的模型(如Ollama)
- Temperature设置为0.3(客服回答需要准确性)
- Max Tokens设置为500(足够回答大多数问题)
步骤4:测试运行
点击“运行”按钮,在Text Input中输入“智能手机X有哪些颜色?”,看看系统如何回答。
你应该会得到类似这样的回答: “您好!智能手机X目前有黑色、白色和蓝色三种颜色可选。这是一款最新款的智能手机,搭载了AI芯片,价格为2999元。如果您需要了解更多信息,请随时告诉我!”
3.2 第二步:添加订单状态查询功能
电商客服的另一个常见需求是查询订单状态。这个功能稍微复杂一些,因为需要连接数据库。
核心思路:
- 识别用户意图(是否是查询订单)
- 提取订单号(从用户问题中)
- 查询数据库获取订单信息
- 生成友好的状态描述
具体实现:
步骤1:创建订单模拟数据
由于真实数据库连接较复杂,我们先创建一个模拟的订单数据组件:
# 在LangFlow中创建自定义Python组件
from langflow.interface.custom_components import CustomComponent
class MockOrderDB(CustomComponent):
display_name = "模拟订单数据库"
description = "模拟订单查询功能"
def build_config(self):
return {
"order_id": {"display_name": "订单号", "required": True}
}
def build(self, order_id: str):
# 模拟订单数据
orders = {
"ORD2024001": {"status": "已发货", "tracking": "SF123456789", "estimate": "3天后送达"},
"ORD2024002": {"status": "待发货", "estimate": "明天发货"},
"ORD2024003": {"status": "已签收", "signed_by": "张先生"}
}
if order_id in orders:
return orders[order_id]
else:
return {"status": "未找到订单", "message": "请检查订单号是否正确"}
步骤2:构建订单查询流程
这个流程需要两个分支:
- 分支一:意图识别(判断用户是否要查询订单)
- 分支二:订单查询和回答生成
工作流结构:
Text Input → Intent Classifier → [如果是订单查询] → Order Extractor → MockOrderDB → Answer Generator → Text Output
[如果是其他问题] → 跳转到商品问答流程
步骤3:配置意图识别
我们可以用简单的关键词匹配来实现意图识别:
class IntentClassifier(CustomComponent):
def build(self, question: str):
question_lower = question.lower()
if any(word in question_lower for word in ["订单", "物流", "发货", "快递", "tracking"]):
return "order_query"
elif any(word in question_lower for word in ["商品", "产品", "颜色", "尺寸", "价格"]):
return "product_query"
else:
return "general_query"
步骤4:测试订单查询
输入“我的订单ORD2024001到哪里了?”,系统应该能识别出这是订单查询,提取订单号,查询数据库,然后生成回答: “您好!您的订单ORD2024001状态是:已发货。快递单号:SF123456789,预计3天后送达。请保持手机畅通以便快递员联系您。”
3.3 第三步:实现多轮对话记忆
真实的客服对话往往是多轮的。用户可能先问“这个手机怎么样?”,接着问“有优惠吗?”,然后问“怎么购买?”。系统需要记住对话历史。
实现方法:
在LangFlow中,可以使用“Conversation Buffer Memory”组件:
- 在画布上添加“Conversation Buffer Memory”组件
- 将其连接到LLM Chain的“memory”输入
- 配置记忆长度(通常保留最近5-10轮对话)
配置示例:
- Memory Key: chat_history
- Input Key: question
- Output Key: answer
- Return Messages: True
这样,每次用户提问时,系统都会自动带上之前的对话历史,让AI能理解上下文。
4. 进阶功能:个性化推荐与复杂场景处理
4.1 基于用户历史的个性化推荐
当客服系统能记住用户的历史行为时,就可以提供个性化服务了。
实现思路:
- 记录用户的浏览和购买历史
- 分析用户的偏好(品类、价格区间、风格等)
- 当用户咨询时,结合偏好进行推荐
工作流设计:
用户问题 → 用户识别 → 查询用户历史 → 分析用户偏好 → 结合商品库推荐 → 生成回答
用户偏好分析组件示例:
class UserPreferenceAnalyzer(CustomComponent):
def build(self, user_id: str, purchase_history: list):
# 简单分析逻辑
categories = {}
price_range = []
for item in purchase_history:
cat = item.get("category", "")
price = item.get("price", 0)
categories[cat] = categories.get(cat, 0) + 1
price_range.append(price)
# 找出最常购买的品类
favorite_category = max(categories, key=categories.get) if categories else None
# 计算平均价格区间
avg_price = sum(price_range) / len(price_range) if price_range else 0
return {
"favorite_category": favorite_category,
"avg_price": avg_price,
"total_purchases": len(purchase_history)
}
当用户问“有什么推荐的吗?”,系统可以这样回答: “根据您的购买记录,我发现您经常购买电子产品,平均消费在2000元左右。我为您推荐以下几款产品:1. 智能手机Y(新品上市,符合您的偏好) 2. 智能手表Z(与您之前购买的手机兼容)...”
4.2 处理复杂问题:退换货流程指导
退换货是电商客服的难点,因为涉及规则判断、流程指导等多个步骤。
分步骤解决方案:
步骤1:问题分类
- 质量问题退货
- 七天无理由退货
- 换货请求
- 仅退款
步骤2:构建决策树工作流
在LangFlow中,可以用多个条件判断节点构建决策流程:
用户问题 → 问题分类器 →
[如果是质量问题] → 收集证据要求 → 生成退货指引
[如果是七天无理由] → 检查时间条件 → 生成退货指引
[如果是换货] → 确认库存 → 生成换货流程
[其他] → 转人工客服
步骤3:动态表单生成
对于需要用户填写的信息(如退货原因、照片等),可以用动态表单:
class ReturnFormGenerator(CustomComponent):
def build(self, return_type: str):
forms = {
"quality_issue": {
"fields": [
{"name": "problem_desc", "label": "问题描述", "type": "textarea"},
{"name": "photos", "label": "问题照片", "type": "file"},
{"name": "expectation", "label": "您的期望", "type": "select",
"options": ["退货退款", "换货", "维修"]}
]
},
"seven_days": {
"fields": [
{"name": "reason", "label": "退货原因", "type": "text"},
{"name": "product_condition", "label": "商品状态", "type": "select",
"options": ["未拆封", "已拆封未使用", "已使用"]}
]
}
}
return forms.get(return_type, {})
4.3 集成外部系统:库存查询与物流跟踪
真正的生产环境需要连接企业内部的各个系统。
库存查询集成:
class InventoryChecker(CustomComponent):
def build(self, product_id: str, warehouse: str = "default"):
# 这里连接真实的库存系统API
import requests
try:
response = requests.get(
f"http://inventory-api.internal/stock/{product_id}",
params={"warehouse": warehouse},
timeout=5
)
if response.status_code == 200:
stock_info = response.json()
return {
"available": stock_info.get("quantity", 0) > 0,
"quantity": stock_info.get("quantity", 0),
"location": stock_info.get("warehouse", "未知")
}
else:
return {"available": False, "error": "库存查询失败"}
except Exception as e:
return {"available": False, "error": str(e)}
物流跟踪集成:
class LogisticsTracker(CustomComponent):
def build(self, tracking_number: str, carrier: str = "auto"):
# 支持多家快递公司
carriers = {
"sf": "顺丰",
"sto": "申通",
"yto": "圆通",
"zto": "中通"
}
# 自动识别快递公司
if carrier == "auto":
if tracking_number.startswith("SF"):
carrier = "sf"
elif tracking_number.startswith("77"):
carrier = "yto"
# ... 其他识别逻辑
# 调用物流查询API
# 实际项目中这里会调用真实的物流接口
return {
"status": "运输中",
"current_location": "上海分拨中心",
"next_location": "杭州分拨中心",
"estimate_time": "2024-06-15 14:00前",
"history": [
{"time": "2024-06-12 08:30", "location": "上海仓库", "action": "已发货"},
{"time": "2024-06-12 14:20", "location": "上海分拨中心", "action": "已揽收"}
]
}
5. 优化与部署:让客服系统更智能可靠
5.1 性能优化技巧
缓存常用回答: 对于高频问题(如“运费多少?”“发货时间?”),可以设置缓存避免重复调用AI模型。
from functools import lru_cache
import hashlib
@lru_cache(maxsize=100)
def get_cached_answer(question: str, context: str = ""):
# 生成缓存键
cache_key = hashlib.md5(f"{question}_{context}".encode()).hexdigest()
# 检查缓存
cached = cache.get(cache_key)
if cached:
return cached
# 如果没有缓存,调用AI生成
answer = generate_answer(question, context)
# 存入缓存(有效期1小时)
cache.set(cache_key, answer, timeout=3600)
return answer
异步处理: 对于耗时的操作(如查询多个系统),使用异步提高响应速度。
import asyncio
async def handle_complex_query(question: str):
# 并行查询多个数据源
inventory_task = check_inventory_async(question)
user_task = get_user_profile_async(question)
product_task = search_products_async(question)
# 等待所有任务完成
inventory, user_profile, products = await asyncio.gather(
inventory_task, user_task, product_task
)
# 综合所有信息生成回答
return await generate_comprehensive_answer(inventory, user_profile, products)
5.2 错误处理与降级策略
分级降级机制:
- 一级降级:主模型失败 → 切换到备用模型
- 二级降级:所有AI模型失败 → 使用规则引擎
- 三级降级:规则引擎失败 → 返回预设话术
class FallbackHandler:
def __init__(self):
self.primary_model = "gpt-4"
self.backup_model = "claude-3"
self.rule_engine = RuleEngine()
self.default_responses = {
"greeting": "您好!我是客服助手,有什么可以帮您?",
"unknown": "抱歉,我暂时无法回答这个问题。已为您转接人工客服。",
"error": "系统暂时有点忙,请稍后再试。"
}
async def get_response(self, question: str):
try:
# 尝试主模型
response = await self.call_primary_model(question)
return response
except Exception as e:
print(f"主模型失败: {e}")
try:
# 尝试备用模型
response = await self.call_backup_model(question)
return response
except Exception as e2:
print(f"备用模型失败: {e2}")
# 尝试规则引擎
response = self.rule_engine.process(question)
if response:
return response
# 最后返回默认话术
return self.get_default_response(question)
5.3 监控与数据分析
关键指标监控:
- 响应时间:确保95%的请求在3秒内响应
- 准确率:定期抽样检查回答准确性
- 用户满意度:收集用户反馈评分
- 转人工率:AI无法处理转人工的比例
实现监控面板:
class MetricsCollector:
def __init__(self):
self.metrics = {
"total_requests": 0,
"successful_responses": 0,
"avg_response_time": 0,
"error_rate": 0
}
def record_request(self, start_time):
self.metrics["total_requests"] += 1
# 计算响应时间
response_time = time.time() - start_time
# 更新平均响应时间(滑动平均)
old_avg = self.metrics["avg_response_time"]
count = self.metrics["total_requests"]
self.metrics["avg_response_time"] = old_avg + (response_time - old_avg) / count
def record_success(self):
self.metrics["successful_responses"] += 1
def record_error(self):
self.metrics["error_rate"] = (
self.metrics["total_requests"] - self.metrics["successful_responses"]
) / self.metrics["total_requests"]
def get_dashboard_data(self):
return {
"今日请求量": self.metrics["total_requests"],
"成功率": f"{(self.metrics['successful_responses'] / self.metrics['total_requests'] * 100):.1f}%",
"平均响应时间": f"{self.metrics['avg_response_time']:.2f}秒",
"热门问题": self.get_top_questions()
}
5.4 部署到生产环境
容器化部署:
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# 安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 创建数据目录
RUN mkdir -p /data/flows
# 暴露端口
EXPOSE 7860
# 启动命令
CMD ["langflow", "run", "--host", "0.0.0.0", "--port", "7860", "--backend-only"]
使用Docker Compose编排:
# docker-compose.yml
version: '3.8'
services:
langflow:
build: .
ports:
- "7860:7860"
volumes:
- ./flows:/data/flows
- ./components:/app/custom_components
environment:
- LANGFLOW_DATABASE_URL=sqlite:///data/langflow.db
- LANGFLOW_CONFIG_DIR=/data/config
restart: unless-stopped
redis:
image: redis:alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
restart: unless-stopped
volumes:
redis_data:
6. 总结:从零到一的AI客服搭建之旅
通过本文的步骤,我们完成了一个电商客服自动化系统的搭建。让我们回顾一下关键收获:
6.1 核心价值总结
1. 可视化开发,降低门槛 LangFlow最大的优势是让AI应用开发变得可视化。你不需要是Python专家,也不需要深入理解LangChain的复杂API,通过拖拽组件就能构建智能流程。这对于业务人员、产品经理来说,意味着他们可以直接参与AI应用的构建。
2. 快速迭代,灵活调整 传统的客服系统修改一个流程可能需要开发人员改代码、测试、部署,周期很长。而在LangFlow中,你可以实时调整工作流,立即测试效果。今天发现用户经常问退货政策,明天就能在画布上添加一个退货咨询节点。
3. 无缝集成,扩展性强 无论是连接内部的商品数据库、订单系统,还是外部的物流查询API,LangFlow都能通过自定义组件轻松实现。这种开放性让AI客服不再是信息孤岛,而是真正融入企业业务流。
4. 成本可控,效果可测 你可以从简单的规则引擎开始,逐步引入AI能力。先解决80%的常见问题,再处理20%的复杂场景。每一步的投入和产出都清晰可见,避免了“一次性投入巨大,效果未知”的风险。
6.2 实际效果展示
在我们搭建的系统中,你可以看到:
- 商品咨询场景:用户问“这个手机电池多大?”,系统能准确回答“5000mAh,支持快充”
- 订单查询场景:用户提供订单号,系统能返回完整的物流轨迹
- 个性化推荐:老用户咨询时,系统能基于历史购买记录推荐相关商品
- 复杂流程处理:用户要退货,系统能引导完成整个流程,包括上传照片、选择原因等
更重要的是,所有这些功能都在一个统一的界面中管理。你可以看到每个问题的处理路径,知道AI在哪里做出了判断,在哪里调用了外部系统。
6.3 下一步建议
如果你已经跟着教程搭建了基础系统,接下来可以考虑:
1. 丰富知识库
- 添加更多商品信息
- 完善常见问题库
- 收集用户真实对话进行优化
2. 接入更多数据源
- 连接CRM系统获取用户画像
- 接入库存系统实时查询
- 对接客服工单系统
3. 优化AI模型
- 尝试不同的模型(GPT-4、Claude、国产大模型等)
- 针对客服场景微调提示词
- 建立评估体系持续优化
4. 扩展应用场景
- 售前咨询自动化
- 售后问题分类与路由
- 客户满意度自动调研
- 营销活动智能推荐
6.4 最后的思考
AI客服不是要完全取代人工,而是让人工客服能够专注于更有价值的工作——处理复杂问题、提供情感支持、创造卓越体验。通过LangFlow这样的工具,企业可以快速构建自己的智能客服系统,让AI成为客服团队的有力助手。
从今天开始,尝试用LangFlow解决一个你业务中的具体问题。从一个简单的问答开始,逐步扩展,你会发现,AI应用的开发从未如此简单、如此有趣。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)