
数据驱动未来:构建下一代湖仓一体电商数据分析平台,引领实时商业智能革命
在数据仓库架构的演进历程中,Lambda架构作为一个标志性的阶段,它融合了离线处理和实时处理两种数据处理途径,为满足多样化的数据处理需求提供了有效的解决方案。因此,在实时数仓的构建中,许多企业并没有完全采用Kappa架构,而是选择了混合架构,以兼顾实时性和离线数据处理的需求。综上所述,这一架构通过巧妙地融合了数据湖技术和现代计算引擎,不仅解决了Kappa架构的多项挑战,还为构建一个可落地的实时数仓
1.1 项目背景
本项目是一个创新的湖仓一体实时电商数据分析平台,旨在为电商平台提供深度的数据洞察和业务分析。技术层面,项目涵盖了从基础架构搭建到大数据技术组件的集成,采用了湖仓一体的设计理念,实现了数据仓库与数据湖的有效融合。这一架构创新旨在打通数据流通的壁垒,支持企业级项目的离线与实时数据指标分析,确保数据分析的全面性和时效性。
在业务应用方面,项目初期重点关注会员和商品两大核心主题。通过精细化的数据分析,我们提供了一系列关键指标,包括但不限于用户实时登录行为、页面浏览量(PV)与独立访客(UV)的实时统计、商品浏览信息的动态分析,以及用户积分体系的深度挖掘。这些分析指标将为平台运营提供数据支撑,优化用户体验,并驱动业务增长。展望未来,我们计划进一步扩展业务分析的广度与深度,增加更多业务指标,并不断完善技术架构,以适应不断变化的市场需求。我们致力于通过该项目,为客户提供一个可靠、灵活且功能强大的数据分析解决方案,帮助他们在电商领域中捕捉机遇,实现价值最大化。
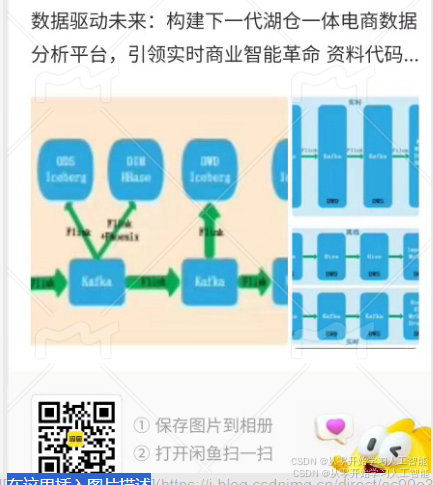
1.2 项目架构
1.2.1实时数仓现状
目前,基于Hive构建的离线数据仓库技术已经达到了高度成熟的状态。然而,随着实时计算引擎技术的飞速进步以及业务领域对实时报表生成需求的日益增长,业界近年来一直在紧密关注并积极投身于实时数据仓库的构建与优化。在数据仓库架构的演进历程中,Lambda架构作为一个标志性的阶段,它融合了离线处理和实时处理两种数据处理途径,为满足多样化的数据处理需求提供了有效的解决方案。这种架构通过精心设计的数据处理流程,确保了数据处理的高效率和高可靠性,同时也为实时数仓的进一步发展奠定了坚实的基础,其架构图如下:
正是由于在Lambda架构中存在离线和实时两条数据处理链路,这种双重路径有时会引发数据一致性问题。为了解决这些问题并简化数据处理流程,Kappa架构应运而生。
Kappa架构以其简洁和高效的特点,被誉为实现真正实时数仓的理想架构。在业界,Flink与Kafka的结合是实现Kappa架构的典型方式。然而,即便如此强大的组合也并非完美无缺。以下是Kappa架构的一些显著缺陷:
-
数据存储限制:Kafka在处理海量数据存储方面存在局限。对于数据量巨大的业务场景,Kafka通常只能保留短期内的数据,如最近一周或甚至仅一天。
-
OLAP查询效率:Kafka并不擅长支持高效的OLAP(在线分析处理)查询。许多业务场景需要在DWD(数据仓库详细层)和DWS(数据仓库服务层)进行即时查询,而Kafka在这方面的支持并不尽如人意。
-
数据管理和血缘:Kappa架构难以复用现有的、成熟的离线数仓数据血缘和数据质量管理机制。企业可能需要重新构建一套完整的数据血缘和数据质量管理系统。
-
数据更新限制:Kafka目前不支持update或upsert操作,仅支持数据的追加。在DWS层,可能需要对数据进行更新,尤其是在数据聚合和时间窗口处理时,Kafka无法满足这些需求。
因此,在实时数仓的构建中,许多企业并没有完全采用Kappa架构,而是选择了混合架构,以兼顾实时性和离线数据处理的需求。尽管Kappa架构在提高数据报表的时效性方面取得了一定进展,但它依然面临诸多挑战。除了上述问题,对于那些实时业务需求密集的公司,Kappa架构可能还需要针对特定层的Kafka数据重新编写实时处理程序,这无疑增加了操作的复杂性和不便。
随着数据湖技术的发展,Kappa架构在实现批量数据和实时数据的统一计算方面展现出了巨大的潜力。这一趋势催生了“批流一体”的概念,它指的是在数据处理的不同层面上实现批量和流式数据的无缝集成。
在业界,对“批流一体”的理解存在两种主要视角:
-
开发层面的统一:一些观点认为,当批量处理和流处理的逻辑能够通过相同的SQL语句来实现时,就达到了批流一体。这种方式简化了开发流程,使得开发者能够用统一的逻辑来处理不同类型的数据。
-
计算引擎层面的集成:另一些观点则强调计算引擎层面的统一。例如,Spark及其相关组件(如Spark Streaming、Structured Streaming)和Flink等框架,已经在计算引擎层面实现了批处理和流处理的集成。这种集成使得同一引擎能够同时处理批量作业和实时数据流。
无论从哪个角度来看,批流一体的核心都在于存储层面的统一。数据湖技术提供了一个统一的存储解决方案,使得批量数据和实时数据能够共存于同一环境中,实现统一的处理和计算。
通过将离线数仓和实时数仓的数据统一存储在数据湖中,我们能够构建起“湖仓一体”的架构。这种架构不仅简化了数据管理,还提高了数据处理的灵活性和效率。例如,使用Iceberg作为数据湖的存储解决方案,可以解决Kappa架构中的许多挑战,使得Kappa架构更加完善和高效。
在这种“湖仓一体”的架构下,Kappa架构的实现变得更加简洁和强大。数据湖技术的应用使得数据的存储、处理和分析更加一体化,为企业提供了一个更加灵活和高效的数据处理平台。这种架构的构建已经成为许多大型公司在处理离线和实时数据时的首选方案,它代表了数据处理领域的未来趋势。
在现代数据处理架构中,数据湖技术尤其是Iceberg的引入,为Kappa架构带来了革新性的改进。这一架构的演进,通过将数据存储统一到数据湖Iceberg上,无论是流处理还是批处理,都实现了存储层面的高效整合。以下是该架构解决Kappa架构痛点的几个关键方面:
-
数据存储容量:数据湖Iceberg建立在HDFS之上,提供了一个可扩展的文件管理系统,有效解决了Kafka在数据存储量上的限制,能够处理大规模数据集。
-
OLAP查询支持:数据湖架构允许DW层数据继续支持高效的OLAP查询。通过适配现有的OLAP查询引擎,可以无缝地进行交互式分析和即席查询。
-
数据管理和治理:统一的存储基础使得可以复用一套数据血缘和数据质量管理工具和流程,简化了数据治理工作,提高了数据的可管理性和可追溯性。
-
实时数据更新:数据湖技术提供了对实时数据更新的支持,这对于需要动态调整和维护数据准确性的场景至关重要。
此外,该架构可以被视为Kappa架构的优化版本,它保留了两条数据链路的设计模式:
- 离线数据链路:基于Spark的批处理能力,适用于数据的全量处理和修正,以及其他非实时数据处理需求。
- 实时数据链路:基于Flink的流处理能力,用于处理实时数据流,确保数据的实时性和动态性。
这种混合链路架构不仅提高了数据处理的灵活性,还增强了数据的准确性和可靠性。在数据修正和非常规场景下,离线链路发挥着重要作用,而实时链路则保障了日常业务的连续性和报表的即时生成。
综上所述,这一架构通过巧妙地融合了数据湖技术和现代计算引擎,不仅解决了Kappa架构的多项挑战,还为构建一个可落地的实时数仓方案提供了坚实的基础,实现了实时报表的快速产出,满足了企业对实时数据分析的迫切需求。
1.2.2 项目架构及数据分层
在本项目中,我们采用了前沿的数据湖技术——Apache Iceberg,来构建一个创新的“湖仓一体”架构。这一架构的核心优势在于其能够无缝地整合实时和离线分析能力,专门针对电商业务指标进行优化。
在本项目中,我们采用了先进的数据湖技术——Apache Iceberg,来构建一个创新的“湖仓一体”架构,旨在实现对电商业务指标的实时和离线分析。以下是我们项目数据处理流程的详细描述:
-
数据采集:
- 我们的项目涉及两类主要数据源:一是来自MySQL的业务数据库数据,二是用户行为日志数据。
- 这两类数据通过特定的数据采集工具,被实时地收集并发送到Kafka的不同topic中。
-
数据摄入与处理:
- 使用Flink作为数据处理引擎,从Kafka的相应topic中读取业务和日志数据。
- Flink对数据进行必要的清洗、转换和聚合操作,以适应后续的分析需求。
-
数据存储与Iceberg-ODS层:
- 处理后的数据首先存储在Iceberg的ODS(操作数据存储)层中。
- 由于Flink在处理Iceberg时可能存在的数据消费位置信息保存问题,我们同时将数据写入Kafka,利用Flink的offset维护机制确保程序在停止和重启后能正确地继续消费数据。
-
数据仓库分层:
- 我们的架构基于Iceberg构建了多层数据仓库模型,每一层都针对不同的数据处理和分析需求。
-
实时数据分析:
- 实时分析的数据结果被存储在Clickhouse中,利用其优异的查询性能来支持快速的实时数据分析。
-
离线数据分析:
- 离线数据分析结果则从Iceberg的DWS(数据仓库服务层)中获取,确保了数据分析的深度和广度。
-
数据存储与展示:
- 分析结果最终存储在MySQL数据库中,用于长期的业务回顾和决策支持。
- 通过先进的数据可视化工具,我们将Clickhouse和MySQL中的分析结果以直观、易理解的形式展现出来。
-
架构优势:
- 整个架构的优势在于其灵活性和扩展性,能够适应不断变化的业务需求和数据量增长。
- 同时,它还能够保证数据处理的实时性和准确性,为业务决策提供强有力的数据支持。
通过这种综合运用多种数据处理技术的方式,我们的项目能够高效地处理和分析大规模数据,为电商业务提供深刻的洞察和实时的决策支持。
1.2.3项目可视化效果

1.3项目使用技术及版本
在项目中,使用了多种大数据技术组件来构建一个高效、可靠的数据处理和分析平台。以下是项目中使用的技术组件及其版本概览:
| 使用技术 | 版本 |
|---|---|
| Zookeeper | 3.4.13 |
| HDFS | 3.1.4/3.2.2 |
| Hive | 3.1.2 |
| (MySQL 5.7.32) | |
| Iceberg | 0.11.1 |
| HBase | 2.2.6 |
| Phoenix | 5.0.0 |
| Kafka | 0.11.0.3 |
| Redis | 2.8.18 |
| Flink | 1.11.6 |
| Flume | 1.9.0 |
| Maxwell | 1.28.2 |
| ClickHouse | 21.9.4.35 |
1.4 项目基础环境的准备
基础环境的准备是确保大数据组件顺利安装和运行的关键步骤
考虑到容器化部署的便利性,也可以使用Docker安装相应的组件。但在本项目中,为了更好地理解各个组件和流程,选择使用二进制部署方式。
基础环境:
在 windows 上 安装 VMware 并安装,centos7 。
节点配置:
每台节点配置了4GB内存和4个CPU核心,这为运行大数据组件提供了基本的硬件支持。
网络设置:
关闭了每台节点的防火墙,确保网络通信不受限制。
配置了每台节点的主机名,便于管理和识别。
配置了YUM源,确保软件包能够顺利下载和更新。
时间同步:
确保了所有节点之间的时间同步,这对于分布式系统的一致性和日志记录非常重要。
SSH设置:
实现了各个节点之间的SSH密钥认证,使得节点间可以免密码登录,方便管理和维护。
实现各个节点之间的SSH密钥认证是一个重要的步骤,它允许无密码登录到远程服务器,从而简化了管理和维护过程。以下是实现这一目标的步骤:
-
生成SSH密钥对:
在主节点上(例如node1),生成SSH密钥对。如果不指定,SSH将自动生成一个默认的RSA密钥对。ssh-keygen -t rsa -
复制公钥到其他节点:
将公钥复制到所有其他节点的~/.ssh/authorized_keys文件中。这可以通过SSH-copy-id命令完成:ssh-copy-id node2 ssh-copy-id node3 ssh-copy-id node4 ssh-copy-id node5 -
验证SSH密钥认证:
测试从主节点到其他节点的SSH连接,看是否能够无密码登录:ssh node2 ssh node3 ssh node4 ssh node5 -
配置SSH免密登录:
在~/.ssh/config文件中为每个节点配置免密登录,这样SSH客户端就会自动使用正确的密钥进行认证:Host node2 HostName 192.168.179.5 User your_username IdentityFile ~/.ssh/id_rsa Host node3 HostName 192.168.179.6 User your_username IdentityFile ~/.ssh/id_rsa # 为其他节点重复上述配置 -
确保SSH服务配置正确:
在所有节点上,编辑/etc/ssh/sshd_config文件,确保以下配置项正确:PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys -
重启SSH服务:
在所有节点上,重启SSH服务以应用配置更改:sudo systemctl restart sshd -
确保防火墙规则允许SSH:
如果您的防火墙在稍后重新启用,确保防火墙规则允许SSH端口(默认为22):sudo firewall-cmd --permanent --add-service=ssh sudo firewall-cmd --reload
通过这些步骤,您可以在多个节点之间实现SSH密钥认证,从而无需每次手动输入密码即可登录到远程服务器。这对于自动化任务和批量管理非常有用。
JDK安装:
安装了Java开发工具包(JDK),为运行Java编写的大数据应用程序提供了环境支持。
| 节点IP | 节点名称 |
|---|---|
| 192.168.179.4 | node1 |
| 192.168.179.5 | node2 |
| 192.168.179.6 | node3 |
| 192.168.179.7 | node4 |
| 192.168.179.8 | node5 |
1.4.1搭建Zookeeper
以下展示了Zookeeper集群的节点IP、节点名称以及对应的角色分布:
| 节点IP | 节点名称 | Zookeeper |
| --------------- | -------- | --------- |
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | ★ |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 | ★ |
在这个表格中,★ 表示该节点将作为Zookeeper服务的实例运行。
以下是搭建Zookeeper集群的具体步骤:
1. 准备环境
- 在所有节点(node1, node2, node3, node4, node5)创建
/software目录,用于后续安装技术组件。mkdir -p /software
2. 上传并解压Zookeeper
- 将Zookeeper安装包上传至
node3的/software目录,并解压。tar -zxvf zookeeper-3.4.13.tar.gz -C /software
3. 配置环境变量
- 在
node3配置Zookeeper环境变量。echo 'export ZOOKEEPER_HOME=/software/zookeeper-3.4.13' >> /etc/profile echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile source /etc/profile
4. 配置Zookeeper
- 在
node3编辑Zookeeper配置文件。mv /software/zookeeper-3.4.13/conf/zoo_sample.cfg /software/zookeeper-3.4.13/conf/zoo.cfg - 修改
zoo.cfg文件,设置集群配置:tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/data/zookeeper clientPort=2181 server.1=node3:2888:3888 server.2=node4:2888:3888 server.3=node5:2888:3888
5. 分发Zookeeper配置
- 将配置好的Zookeeper发送至
node4和node5。scp -r /software/zookeeper-3.4.13 node4:/software/ scp -r /software/zookeeper-3.4.13 node5:/software/
6. 创建数据目录并配置环境变量
- 在
node3,node4,node5创建数据目录。mkdir -p /opt/data/zookeeper - 在
node4和node5配置Zookeeper环境变量。echo 'export ZOOKEEPER_HOME=/software/zookeeper-3.4.13' >> /etc/profile echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile source /etc/profile
7. 创建节点ID文件
- 在
node3,node4,node5的/opt/data/zookeeper路径中添加myid文件,并分别写入1, 2, 3。echo 1 > /opt/data/zookeeper/myid echo 2 > /opt/data/zookeeper/myid echo 3 > /opt/data/zookeeper/myid
8. 启动Zookeeper并检查状态
- 在各个节点启动Zookeeper。
zkServer.sh start - 检查Zookeeper进程状态。
zkServer.sh status
通过这些步骤,您可以在node3, node4, node5上搭建一个Zookeeper集群,为后续的大数据组件提供服务。确保在每个节点上重复相应的配置和启动步骤,以确保集群的一致性和稳定性。
以下是搭建HDFS集群的具体步骤,以及对应的角色分布表格,使用Markdown格式编写:
1.4.2搭建HDFS
HDFS集群角色分布
| 节点IP | 节点名称 | NN | DN | ZKFC | JN | RM | NM |
|---|---|---|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ★ | ★ | ★ | ||
| 192.168.179.5 | node2 | ★ | ★ | ★ | ★ | ||
| 192.168.179.6 | node3 | ★ | ★ | ★ | |||
| 192.168.179.7 | node4 | ★ | ★ | ★ | |||
| 192.168.179.8 | node5 | ★ | ★ | ★ |
搭建HDFS集群步骤
-
安装依赖:在所有节点安装HDFS HA自动切换必须的依赖。
yum -y install psmisc -
上传并解压Hadoop:将Hadoop安装包上传至
node1并解压。tar -zxvf hadoop-3.1.4.tar.gz -C /software -
配置环境变量:在
node1配置Hadoop环境变量。echo 'export HADOOP_HOME=/software/hadoop-3.1.4/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:' >> /etc/profile source /etc/profile -
配置
hadoop-env.sh:设置JAVA_HOME。
在$HADOOP_HOME/etc/hadoop目录下,编辑hadoop-env.sh文件,添加以下内容:export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/ -
配置
hdfs-site.xml:编辑配置项,包括逻辑名称、权限禁用、NameNode名称、编辑日志目录等。
配置路径:$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- 配置
core-site.xml:设置Hadoop客户端默认路径、Hadoop临时目录、Zookeeper集群地址。
配置路径:$HADOOP_HOME/ect/hadoop/core-site.xml
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name
datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>
- 配置
yarn-site.xml:设置YARN辅助服务、环境变量白名单、YARN ResourceManager高可用配置。
配置路径:$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>
- 配置
mapred-site.xml:设置MapReduce框架名称。
配置路径:$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 配置
workers文件:列出所有工作节点。
配置路径:$HADOOP_HOME/etc/hadoop/workers
[root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workers
node3
node4
node5
- 添加用户参数:在启动脚本中添加用户参数,防止启动错误。
配置路径:$HADOOP_HOME/sbin/start-dfs.sh 和stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
配置路径:$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
- 分发Hadoop安装包:将Hadoop安装包发送到其他4个节点。
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/
- 配置其他节点的环境变量:在node2、node3、node4、node5节点配置HADOOP_HOME。
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
- 启动HDFS和YARN服务:格式化Zookeeper、启动JournalNode、格式化NameNode、同步Standby NameNode、启动HDFS和YARN。
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby
#node1上启动HDFS,启动Yarn
[root@node1 sbin]# start-dfs.sh
[root@node1 sbin]# start-yarn.sh
注意以上也可以使用start-all.sh命令启动Hadoop集群。
- 访问WebUI:通过Web界面访问HDFS和YARN的状态。

#访问Yarn WebUI :http://node1:8088

- 停止集群:使用相应命令停止Hadoop集群服务。
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
1.4.3搭建Hive
搭建Hive的版本为3.1.2,下图展示了Hive搭建的节点IP、节点名称以及对应的角色分布:
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ||
| 192.168.179.5 | node2 | ★ | ★ (已搭建) | |
| 192.168.179.6 | node3 | ★ |
以下是搭建Hive集群的具体步骤,包括您已经开始的步骤:
1. 上传并解压Hive安装包到node1节点
- 切换到
/software目录,上传并解压Hive安装包。cd /software/ tar -zxvf ./apache-hive-3.1.2-bin.tar.gz mv apache-hive-3.1.2-bin hive-3.1.2
2. 发送Hive安装包到其他节点
- 将Hive安装包发送到
node3节点。scp -r /software/hive-3.1.2/ node3:/software/
3. 配置Hive环境变量
- 在
node1和node3上设置Hive的环境变量。echo 'export HIVE_HOME=/software/hive-3.1.2' >> /etc/profile echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile source /etc/profile
4. 配置Hive的配置文件
- 编辑Hive的配置文件
hive-site.xml来设置Hive的运行环境,在node1节点$HIVE_HOME/conf下创建hive-site.xml并配置。
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
5. 在node3节点 配置Hive的配置文件
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
6. node1、node3节点删除$HIVE_HOME/lib下“guava”包,使用Hadoop下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
[root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
[root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下
[root@node1 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
[root@node3 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
7.将“mysql-connector-java-5.1.47.jar”驱动包上传到node1节点的$HIVE_HOME/lib目录下
上传后,需要将mysql驱动包传入$HIVE_HOME/lib/目录下,这里node1,node3节点都需要传入。
8.在node1节点中初始化Hive
#初始化hive,hive2.x版本后都需要初始化
[root@node1 ~]# schematool -dbType mysql -initSchema
9.在服务端和客户端操作Hive
#在node1中登录Hive ,创建表test
[root@node1 conf]# hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t';
#向表test中插入数据
hive> insert into test values(1,"zs",18);
#在node1启动Hive metastore
[root@node1 hadoop]# hive --service metastore &
#在node3上登录Hive客户端查看表数据
[root@node3 lib]# hive
hive> select * from test;
OK
1 zs 18
1.4.4Hive与Iceberg整合
以下展示了Hive 2.x与Hive 3.1.2版本对Iceberg表格式支持的操作:
| 操作 | Hive 2.x | Hive 3.1.2 |
|------------------|-----------|------------|
| CREATE EXTERNAL TABLE | √ | √ |
| CREATE TABLE | √ | √ |
| DROP TABLE | √ | √ |
| SELECT | √ | √ |
| INSERT INTO | √ | √ |
在这个表格中,"√"表示对应的Hive版本支持该操作。
1.4.4.1开启Hive支持Iceberg
1.下载iceberg-hive-runtime.jar
要实现Hive对Iceberg表的查询支持,首先需要下载“iceberg-hive-runtime.jar”,Hive通过该Jar可以加载Hive或者更新Iceberg表元数据信息。下载地址
将以上jar包下载后,上传到Hive服务端和客户端对应的HIVE_HOME/lib目录下。另外在向Hive中Iceberg格式表插入数据时需要到“libfb303-0.9.3.jar”包(jar可以自行maven下载),将此包也上传到Hive服务端和客户端对应的$HIVE_HOME/lib目录下。
2.配置hive-site.xml
在Hive客户端$HIVE_HOME/conf/hive-site.xml中追加如下配置:
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
1.4.4.2 Hive中操作Iceberg格式表
从Hive引擎的视角来看,Catalog扮演着关键角色,它主要负责描述数据集的位置信息,即存储元数据。在Hive与Iceberg的整合过程中,Iceberg展现了对多种Catalog类型的支持,包括Hive原生的Catalog、Hadoop,以及第三方服务如AWS Glue,还有自定义Catalog的可能性。这种多样性使得Hive在实际应用中可以灵活地使用不同的Catalog类型,甚至能够实现跨Catalog类型的数据连接。
为了支持Hive对Iceberg表的读写操作,Hive引入了org.apache.iceberg.mr.hive.HiveIcebergStorageHandler类(包含在iceberg-hive-runtime.jar包中)。这个类允许Hive通过设置Hive配置属性iceberg.catalog.<catalog_name>.type来决定如何加载Iceberg表,这里的<catalog_name>是用户自定义的名称,用于在Hive中创建Iceberg格式的表,并配置Iceberg的Catalog属性。
以下是Hive中创建Iceberg格式表时的三种加载方式,这取决于是否在创建表时指定了iceberg.catalog属性值:
- 指定Catalog类型:如果在创建表时明确指定了
iceberg.catalog属性值,Hive将根据这个属性来确定Iceberg表的加载方式和数据存储位置。
这种情况就是说在Hive中创建Iceberg格式表时,如果指定了iceberg.catalog属性值,那么数据存储在指定的catalog名称对应配置的目录下。
在Hive客户端node3节点进入Hive,操作如下:
#注册一个HiveCatalog叫another_hive
hive> set iceberg.catalog.another_hive.type=hive;
#在Hive中创建iceberg格式表
create table test_iceberg_tbl2(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
tblproperties ('iceberg.catalog'='another_hive');
#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
#插入数据,并查询
hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212");
hive> select * from test_iceberg_tbl2;
OK
2 ls 20 20211212
以上方式指定“iceberg.catalog.another_hive.type=hive”后,实际上就是使用的hive的catalog,这种方式与默认不设置效果一样,创建后的表存储在hive默认的warehouse目录下。也可以在建表时指定location 写上路径,将数据存储在自定义对应路径上。
除了可以将catalog类型指定成hive之外,还可以指定成hadoop,在Hive中创建对应的iceberg格式表时需要指定location来指定iceberg数据存储的具体位置,这个位置是具有一定格式规范的自定义路径。在Hive客户端node3节点进入Hive,操作如下:
#注册一个HadoopCatalog叫hadoop
hive> set iceberg.catalog.hadoop.type=hadoop;
#使用HadoopCatalog时,必须设置“iceberg.catalog.<catalog_name>.warehouse”指定warehouse路径
hive> set iceberg.catalog.hadoop.warehouse=hdfs://mycluster/iceberg_data;
#在Hive中创建iceberg格式表,这里创建成外表
create external table test_iceberg_tbl3(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location 'hdfs://mycluster/iceberg_data/default/test_iceberg_tbl3'
tblproperties ('iceberg.catalog'='hadoop');
注意:以上location指定的路径必须是“iceberg.catalog.hadoop.warehouse”指定路径的子路径,格式必须是${iceberg.catalog.hadoop.warehouse}/${当前建表使用的hive库}/${创建的当前iceberg表名}
#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
#插入数据,并查询
hive> insert into test_iceberg_tbl3 values (3,"ww",20,"20211213");
hive> select * from test_iceberg_tbl3;
OK
3 ww 20 20211213
在指定的“iceberg.catalog.hadoop.warehouse”路径下可以看到创建的表目录:
- 使用默认Catalog:如果没有指定
iceberg.catalog属性,Hive将采用默认的Catalog配置来加载Iceberg表。
这种方式就是说如果在Hive中创建Iceberg格式表时,不指定iceberg.catalog属性,那么数据存储在对应的hive warehouse路径下。
在Hive客户端node3节点进入Hive,操作如下:
#在Hive中创建iceberg格式表
create table test_iceberg_tbl1(
id int ,
name string,
age int)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
#在Hive中加载如下两个包,在向Hive中插入数据时执行MR程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
#向表中插入数据
hive> insert into test_iceberg_tbl1 values (1,"zs",18,"20211212");
#查询表中的数据
hive> select * from test_iceberg_tbl1;
OK
1 zs 18 20211212
在Hive默认的warehouse目录下可以看到创建的表目录:
- 跨Catalog类型连接:如果iceberg.catalog属性设置为“location_based_table”,可以从指定的根路径下加载Iceberg 表
这种情况就是说如果HDFS中已经存在iceberg格式表,我们可以通过在Hive中创建Icerberg格式表指定对应的location路径映射数据。,在Hive客户端中操作如下:
CREATE TABLE test_iceberg_tbl4 (
id int,
name string,
age int,
dt string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/spark/person'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
注意:指定的location路径下必须是iceberg格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到Hive iceberg格式表。
注意:由于Hive建表语句分区语法“Partitioned by”的限制,如果使用Hive创建Iceberg格式表,目前只能按照Hive语法来写,底层转换成Iceberg标识分区,这种情况下不能使用Iceberge的分区转换,例如:days(timestamp),如果想要使用Iceberg格式表的分区转换标识分区,需要使用Spark或者Flink引擎创建表。
通过这种灵活的配置方式,Hive能够更好地与Iceberg集成,为用户提供了强大的数据管理和分析能力,同时也保持了对不同存储和元数据解决方案的兼容性。
1.4.5搭建HBase
HBase集群的节点IP、节点名称以及对应的HBase角色分布:
| 节点IP | 节点名称 | HBase服务 |
| --------------- | -------- | ---------------- |
| 192.168.179.6 | node3 | RegionServer |
| 192.168.179.7 | node4 | HMaster, RegionServer |
| 192.168.179.8 | node5 | RegionServer |
在这个表格中,HBase服务列列出了每个节点上运行的HBase服务角色。例如,node4同时运行了HMaster和RegionServer角色。
具体搭建步骤如下:
1.将下载好的安装包发送到node4节点上,并解压,配置环境变量
#将下载好的HBase安装包上传至node4节点/software下,并解压
[root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz
当前节点配置HBase环境变量
#配置HBase环境变量
[root@node4 software]# vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
[root@node4 software]# source /etc/profile
2.配置$HBASE_HOME/conf/hbase-env.sh
#配置HBase JDK
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
#配置 HBase不使用自带的zookeeper
export HBASE_MANAGES_ZK=false
3.配置$HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node3,node4,node5</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
4.配置$HBASE_HOME/conf/regionservers,配置RegionServer节点
node3
node4
node5
5.配置backup-masters文件
手动创建$HBASE_HOME/conf/backup-masters文件,指定备用的HMaster,需要手动创建文件,这里写入node5,在HBase任意节点都可以启动HMaster,都可以成为备用Master ,可以使用命令:hbase-daemon.sh start master启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5
[root@node4 conf]# vim backup-masters
node5
6.复制hdfs-site.xml到$HBASE_HOME/conf/下
[root@node4conf]# scp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/
7.将HBase安装包发送到node3,node5节点上,并在node3,node5节点上配置HBase环境变量
[root@node4 software]# cd /software
[root@node4 software]# scp -r ./hbase-2.2.6 node3:/software/
[root@node4 software]# scp -r ./hbase-2.2.6 node5:/software/
注意:在node3、node5上配置HBase环境变量。
vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
source /etc/profile
8.重启Zookeeper、重启HDFS及启动HBase集群
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群
[root@node4 software]# start-hbase.sh
#访问WebUI,http://node4:16010。
停止集群:在任意一台节点上stop-hbase.sh

9.测试HBase集群
在Hbase中创建表test,指定’cf1’,'cf2’两个列族,并向表test中插入几条数据:
#进入hbase
[root@node4 ~]# hbase shell
#创建表test
create 'test','cf1','cf2'
#查看创建的表
list
#向表test中插入数据
put 'test','row1','cf1:id','1'
put 'test','row1','cf1:name','zhangsan'
put 'test','row1','cf1:age',18
#查询表test中rowkey为row1的数据
get 'test','row1'
1.4.6搭建Phoenix
以下展示了Phoenix的节点IP、节点名称以及Phoenix服务的分布情况:
| 节点IP | 节点名称 | Phoenix服务 |
| --------------- | --------- | ------------- |
| 192.168.179.7 | node4 | Phoenix Client |
在这个表格中,Phoenix服务列指明了在特定节点上安装的Phoenix组件。
1.下载Phoenix
Phoenix对应的HBase有版本之分,可以从官网:http://phoenix.apache.org/download.html来下载,要对应自己安装的HBase版本下载。我们这里安装的HBase版本为2.2.6,这里下载Phoenix5.0.0版本。下载地址如下:
http://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/

2.上传解压
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
3.拷贝Phoenix整合HBase需要的jar包
将前面解压好安装包下的phoenix开头的包发送到每个HBase节点下的lib目录下。
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin
#直接复制到node4节点对应的HBase目录下
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# cp ./phoenix-*.jar /software/hbase-2.2.6/lib/
#发送到node3,node5两台HBase节点
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node3:/software/hbase-2.2.6/lib/
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node5:/software/hbase-2.2.6/lib/
4.复制core-site.xml、hdfs-site.xml、hbase-site.xml到Phoenix
将HDFS中的core-site.xml、hdfs-site.xml、hbase-site.xml复制到Phoenix bin目录下。
[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/core-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
#输入yes,覆盖Phoenix目录下的hbase-site.xml
[root@node4 ~]# cp /software/hbase-2.2.6/conf/hbase-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
5.启动HDFS,Hbase集群,启动Phoenix
[root@node1 ~]# start-all.sh
[root@node4 ~]# start-hbase.sh (如果已经启动Hbase,一定要重启HBase)
#启动Phoenix
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
#启动时可以不指定后面的zookeeper,默认连接当前节点的zookeeper,多个zookeeper节点逗号隔开,最后一个写端口2181
[root@node4 bin]# ./sqlline.py node3,node4,node5:2181
#退出Phoenix,使用!quit或者!exit
0: jdbc:phoenix:node3,node4,node5:2181> !quit
Closing: org.apache.phoenix.jdbc.PhoenixConnection
6.测试Phoenix
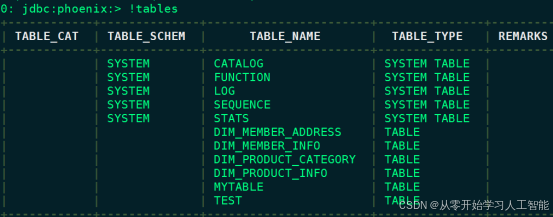
#查看Phoenix表
0: jdbc:phoenix:node3,node4,node5:2181> !tables
#Phoenix中创建表 test,指定映射到HBase的列族为f1
0: jdbc:phoenix:node3,node4,node5:2181> create table test(id varchar primary key ,f1.name varchar,f1.age integer);
#向表 test中插入数据
upsert into test values ('1','zs',18);
#查询插入的数据
0: jdbc:phoenix:node3,node4,node5:2181> select * from test;
+-----+-------+------+
| ID | NAME | AGE |
+-----+-------+------+
| 1 | zs | 18 |
+-----+-------+------+
#在HBase中查看对应的数据,hbase中将非String类型的value数据全部转为了16进制
hbase(main):013:0> scan 'TEST'
注意:在Phoenix中创建的表,插入数据时,在HBase中查看发现对应的数据都进行了16进制编码,这里默认Phoenix中对数据进行的编码,我们在Phoenix中建表时可以指定“column_encoded_bytes=0”参数,不让 Phoenix对column family进行编码。例如以下建表语句,在Phoenix中插入数据后,在HBase中可以查看到正常格式数据:
create table mytable ("id" varchar primary key ,"cf1"."name" varchar,"cf1"."age" varchar) column_encoded_bytes=0;
upsert into mytable values ('1','zs','18');
#以上再次在HBase中查看,显示数据正常

1.4.7 搭建Kafka
以下展示了Kafka集群的节点IP、节点名称以及Kafka服务的分布情况:
| 节点IP | 节点名称 | Kafka服务 |
| --------------- | -------- | ------------- |
| 192.168.179.4 | node1 | kafka broker |
| 192.168.179.5 | node2 | kafka broker |
| 192.168.179.6 | node3 | kafka broker |
搭建详细步骤如下:
1.上传解压
[root@node1 software]# tar -zxvf ./kafka_2.11-0.11.0.3.tgz
2.配置Kafka
在node3节点上配置Kafka,进入/software/kafka_2.11-0.11.0.3/config/中修改server.properties,修改内容如下:
broker.id=0 #注意:这里要唯一的Integer类型
port=9092 #kafka写入数据的端口
log.dirs=/kafka-logs #真实数据存储的位置
zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群
3.将以上配置发送到node2,node3节点上
[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node2:/software/
[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node3:/software/
4.修改node2,node3节点上的server.properties文件
node2、node3节点修改$KAFKA_HOME/config/server.properties文件中的broker.id,node2中修改为1,node3节点修改为2。
5.创建Kafka启动脚本
在node1,node2,node3节点/software/kafka_2.11-0.11.0.3路径中编写Kafka启动脚本“startKafka.sh”,内容如下:
nohup bin/kafka-server-start.sh config/server.properties > kafkalog.txt 2>&1 &
node1,node2,node3节点配置完成后修改“startKafka.sh”脚本执行权限:
chmod +x ./startKafka.sh
6.启动Kafka集群
在node1,node2,node3三台节点上分别执行/software/kafka/startKafka.sh脚本,启动Kafka:
[root@node1 kafka_2.11-0.11.0.3]# ./startKafka.sh
[root@node2 kafka_2.11-0.11.0.3]# ./startKafka.sh
[root@node3 kafka_2.11-0.11.0.3]# ./startKafka.sh
7.Kafka 命令测试
#创建topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic testtopic --partitions 3 --replication-factor 3
#console控制台向topic 中生产数据
./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic testtopic
#console控制台消费topic中的数据
./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
1.4.8搭建Redis
| 节点IP | 节点名称 | Redis服务 |
|---|---|---|
| 192.168.179.7 | node4 | client |
具体搭建步骤如下:
1.将redis安装包上传到node4节点,并解压
[root@node4 ~]# cd /software/
[root@node4 software]# tar -zxvf ./redis-2.8.18.tar.gz
2.node4安装需要的C插件
[root@node4 ~]# yum -y install gcc tcl
3.编译Redis
进入/software/redis-2.8.18目录中,编译redis。
[root@node4 ~]# cd /software/redis-2.8.18
[root@node4 redis-2.8.18]# make
4.创建安装目录安装Redis
#创建安装目录
[root@node4 ~]# mkdir -p /software/redis
#进入redis编译目录,安装redis
[root@node4 ~]# cd /software/redis-2.8.18
[root@node4 redis-2.8.18]# make PREFIX=/software/redis install
注意:现在就可以使用redis了,进入/software/redis/bin下,就可以执行redis命令。
5.将Redis加入环境变量,加入系统服务,设置开机启动
#将redis-server链接到/usr/local/bin/目录下,后期加入系统服务时避免报错
[root@node4 ~]# ln -sf /software/redis-2.8.18/src/redis-server /usr/local/bin/
#执行如下命令,配置redis Server,一直回车即可
[root@node4 ~]# cd /software/redis-2.8.18/utils/
[root@node4 utils]# ./install_server.sh
#执行完以上安装,在/etc/init.d下会修改redis_6379名称并加入系统服务
[root@node4 utils]# cd /etc/init.d/
[root@node4 init.d]# mv redis_6379 redisd
[root@node4 init.d]# chkconfig --add redisd
#检查加入系统状态,3,4,5为开,就是开机自动启动
[root@node4 init.d]# chkconfig --list

**6.配置Redis环境变量**
```bash
# 在node4节点上编辑profile文件,vim /etc/profile
export REDIS_HOME=/software/redis
export PATH=$PATH:$REDIS_HOME/bin
#使环境变量生效
source /etc/profile
7.启动|停止 Redis服务
后期每次开机启动都会自动启动Redis,也可以使用以下命令手动启动|停止redis
#启动redis
[root@node4 init.d]# service redisd start
#停止redis
[root@node4 init.d]# redis-cli shutdown
8)测试redis
#进入redis客户端
[root@node4 ~]# redis-cli
#切换1号库,并插入key
127.0.0.1:6379> select 1
127.0.0.1:6379[1]> hset rediskey zhagnsan 100
#查看所有key并获取key值
127.0.0.1:6379[1]> keys *
127.0.0.1:6379[1]> hgetall rediskey
#删除指定key
127.0.0.1:6379[1]> del 'rediskey'
1.4.9搭建Flink
这里选择Flink的版本为1.11.6,原因是1.11.6与Iceberg的整合比较稳定。Flink搭建节点分布如下:
以下是使用Markdown格式编写的表格,展示了Flink集群的节点IP、节点名称以及对应的Flink服务分布情况:
| 节点IP | 节点名称 | Flink服务 |
| --------------- | -------- | ----------------- |
| 192.168.179.4 | node1 | JobManager, TaskManager |
| 192.168.179.5 | node2 | TaskManager |
| 192.168.179.6 | node3 | TaskManager |
| 192.168.179.7 | node4 | client |
在这个表格中,Flink服务列列出了每个节点上运行的Flink组件。例如,node1运行了JobManager和TaskManager角色。
具体搭建步骤如下:
1.上传压缩包解压
将Flink的安装包上传到node1节点/software下并解压:
[root@node1 software]# tar -zxvf ./flink-1.11.6-bin-scala_2.11.tgz
2.修改配置文件
在node1节点上进入到Flink conf 目录下,配置flink-conf.yaml文件,内容如下:
#进入flink-conf.yaml目录
[root@node1 conf]# cd /software/flink-1.11.6/conf/
#vim编辑flink-conf.yaml文件,配置修改内容如下
jobmanager.rpc.address: node1
taskmanager.numberOfTaskSlots: 3
其中:taskmanager.numberOfTaskSlot参数默认值为1,修改成3。表示数每一个TaskManager上有3个Slot。
3.配置TaskManager节点
在node1节点上配置$FLINK_HOME/conf/workers文件,内容如下:
node1
node2
node3
4.分发安装包到node2,node3,node4节点
[root@node1 software]# scp -r ./flink-1.11.6 node2:/software/
[root@node1 software]# scp -r ./flink-1.11.6 node3:/software/
#注意,这里发送到node4,node4只是客户端
[root@node1 software]# scp -r ./flink-1.11.6 node4:/software/
5.启动Flink集群
#在node1节点中,启动Flink集群
[root@node1 ~]# cd /software/flink-1.11.6/bin/
[root@node1 bin]# ./start-cluster.sh
6.访问flink Webui
https://node1:8081,进入页面如下:
7.准备“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”包
在基于Yarn提交Flink任务时需要将Hadoop依赖包“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”放入flink各个节点的lib目录中(包括客户端)。
1.4.10搭建Flume
以下展示了Flume服务在指定节点上的分布情况:
| 节点IP | 节点名称 | Flume服务 |
| --------------- | -------- | -------- |
| 192.168.179.8 | node5 | flume |
在这个表格中,Flume服务列指明了在特定节点上运行的Flume组件。
Flume的搭建配置步骤如下:
1.首先将Flume上传到Mynode5节点/software/路径下,并解压,命令如下:
[root@ node5 software]# tar -zxvf ./apache-flume-1.9.0-bin.tar.gz
2.其次配置Flume的环境变量,配置命令如下:
#修改 /etc/profile文件,在最后追加写入如下内容,配置环境变量:
[root@node5 software]# vim /etc/profile
export FLUME_HOME=/software/apache-flume-1.9.0-bin
export PATH=$FLUME_HOME/bin:$PATH
#保存以上配置文件并使用source命令使配置文件生效
[root@node5 software]# source /etc/profile
经过以上两个步骤,Flume的搭建已经完成,至此,Flume的搭建完成,我们可以使用Flume进行数据采集。
1.4.11搭建maxwell
1.4.11.1开启MySQL binlog日志
本项目主要使用Maxwell来监控业务库MySQL中的数据到Kafka,Maxwell原理是通过同步MySQL binlog日志数据达到同步MySQL数据的目的。Maxwell不支持高可用搭建,但是支持断点还原,可以在执行失败时重新启动继续上次位置读取数据,此外安装Maxwell前需要开启MySQL binlog日志,步骤如下:
1.登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';

2.开启MySQL binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
# 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定义
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
# 选择 ROW 模式
binlog-format=ROW
3.重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';

1.4.11.2安装Maxwell
这里maxwell安装版本选择1.28.2,选择node3节点安装,安装maxwell步骤如下:
1.将下载好的安装包上传到node3并解压
[root@node3 ~]# cd /software/
[root@node3 software]# tar -zxvf ./maxwell-1.28.2.tar.gz
2.在MySQL中创建Maxwell的用户及赋权
Maxwell同步mysql数据到Kafka中需要将读取的binlog位置文件及位置信息等数据存入MySQL,所以这里创建maxwell数据库,及给maxwell用户赋权访问其他所有数据库。
mysql> CREATE database maxwell;
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
mysql> flush privileges;
3.修改配置“config.properties”文件
node3节点进入“/software/maxwell-1.28.2”,修改“config.properties.example”为“config.properties”并配置:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=test-topic
#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table
#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell
#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用
client_id=maxwell_first
注意:以上参数也可以在后期启动maxwell时指定参数方式来设置。
4.启动zookeeper及Kafka,创建对应test-topic
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic test-topic --partitions 3 --replication-factor 3
5.在Kafka中监控test-topic
[root@node2 bin]# cd /software/kafka_2.11-0.11/
[root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test-topic
6.启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties.
注意以上启动也可以编写脚本:
#startMaxwell.sh 脚本内容:
/software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 &
修改执行权限:
chmod +x ./start_maxwell.sh
注意:这里我们可以通过Maxwell将MySQL业务库中所有binlog变化数据监控到Kafka test-topic中,在此项目中我们将MySQL binlog数据监控到Kafka中然后通过Flink读取对应topic数据进行处理。
7.在mysql中创建库testdb,并创建表person插入数据
mysql> create database testdb;
mysql> use testdb;
mysql> create table person(id int,name varchar(255),age int);
mysql> insert into person values (1,'zs',18);
mysql> insert into person values (2,'ls',19);
mysql> insert into person values (3,'ww',20);
可以看到在监控的kafka test-topic中有对应的数据被同步到topic中:
8.全量同步mysql数据到kafka
这里以MySQL 表testdb.person为例将全量数据导入到Kafka中,可以通过配置Maxwell,使用Maxwell bootstrap功能全量将已经存在MySQL testdb.person表中的数据导入到Kafka,操作步骤如下:
#启动Maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties
#启动maxwell-bootstrap全量同步数据
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# ./maxwell-bootstrap --database testdb --table person --host node2 --user maxwell --password maxwell --client_id maxwell_first --where "id>0"
执行之后可以看到对应的Kafka test-topic中将表testdb.person中的数据全部导入一遍:
1.4.12搭建clickhouse
以下是展示了ClickHouse服务在指定节点上的分布情况:
这里clickhouse的版本选择21.9.4.35,clickhouse选择分布式安装,clickhouse节点分布如下:
| 节点IP | 节点名称 | ClickHouse服务 |
| --------------- | -------- | -------------- |
| 192.168.179.4 | node1 | clickhouse |
| 192.168.179.5 | node2 | clickhouse |
| 192.168.179.6 | node3 | clickhouse |
在这个表格中,ClickHouse服务列指明了在特定节点上运行的ClickHouse服务实例。
clickhouse详细安装步骤如下:
1.选择三台clickhouse节点,在每台节点上安装clickhouse需要的安装包
这里选择node1、node2,node3三台节点,上传安装包,分别在每台节点上执行如下命令安装clickhouse:
rpm -ivh ./clickhosue-common-static-21.9.4.35-2.x86_64.rpm
#注意在安装以下rpm包时,让输入密码,可以直接回车跳过
rpm -ivh ./clickhouse-server-21.9.4.35-2.noarch.rpm
rpm -ivh ./clickhouse-client-21.9.4.35-2.noarch.rpm
2.安装zookeeper集群并启动。
搭建clickhouse集群时,需要使用Zookeeper去实现集群副本之间的同步,所以这里需要zookeeper集群,zookeeper集群安装后可忽略此步骤。
3.配置外网可访问
在每台clickhouse节点中配置/etc/clickhouse-server/config.xml文件第164行<listen_host>,把以下对应配置注释去掉,如下:
<listen_host>::1</listen_host>
#注意每台节点监听的host名称配置当前节点host,需要强制保存wq!
<listen_host>node1</listen_host>
4.在每台节点创建metrika.xml文件,写入以下内容
在node1、node2、node3节点上/etc/clickhouse-server/config.d路径下下配置metrika.xml文件,默认clickhouse会在/etc路径下查找metrika.xml文件,但是必须要求metrika.xml上级目录拥有者权限为clickhouse ,所以这里我们将metrika.xml创建在/etc/clickhouse-server/config.d路径下,config.d目录的拥有者权限为clickhouse。
在metrika.xml中我们配置后期使用的clickhouse集群中创建分布式表时使用3个分片,每个分片有1个副本,配置如下:
vim /etc/clickhouse-server/config.d/metrika.xml:
<yandex>
<remote_servers>
<clickhouse_cluster_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node3</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster_3shards_1replicas>
</remote_servers>
<zookeeper>
<node index="1">
<host>node3</host>
<port>2181</port>
</node>
<node index="2">
<host>node4</host>
<port>2181</port>
</node>
<node index="3">
<host>node5</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<shard>01</shard>
<replica>node1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
在ClickHouse分布式集群配置中,以下是对配置文件中各项配置项的解释:
-
remote_servers:
这是ClickHouse集群配置的标签,用于标识集群配置。新版本的ClickHouse不再要求以"clickhouse"作为前缀。 -
clickhouse_cluster_3shards_1replicas:
这是集群的名称,代表集群由3个分片组成,每个分片有1个副本。分片是存储数据的部分,副本是分片数据的备份。 -
shard:
分片是指集群中的一个数据存储单元。一个ClickHouse集群可以包含多个分片,每个分片可以存储一部分数据。分片对应于集群中的每个服务节点。 -
replica:
副本是分片数据的备份,用于提高数据的可用性。每个分片可以配置一个或多个副本。副本的数量取决于ClickHouse节点的总数。 -
internal_replication:
默认为false。如果设置为true,写操作将只写入一个副本,而其他副本的数据同步在后台自动完成。 -
zookeeper:
用于配置ZooKeeper集群信息,ZooKeeper用于ClickHouse副本之间的协调。 -
macros:
用于区分每个ClickHouse节点的宏配置。<shard>和<replica>是宏的标签,可以在创建副本表时动态使用。每台ClickHouse节点需要配置不同的宏名称。 -
networks:
配置允许访问的IP地址范围。"::/0"代表允许任意IP访问,包括IPv4和IPv6地址。如果需要允许外网访问,还需要在/etc/clickhouse-server/config.xml中进行相应配置。 -
clickhouse_compression:
这是MergeTree引擎表的数据压缩设置。min_part_size定义了数据部分的最小大小,min_part_size_ratio定义了数据部分大小与表大小的比率,method定义了数据压缩的格式。
请注意,为了实现数据压缩,需要在每台ClickHouse节点上配置metrika.xml文件,并修改每个节点的macros配置名称,以确保正确应用压缩设置。
#node2节点修改metrika.xml中的宏变量如下:
<macros>
<shard>02</replica>
<replica>node2</replica>
</macros>
#node3节点修改metrika.xml中的宏变量如下:
<macros>
<shard>03</replica>
<replica>node3</replica>
</macros>
这些配置项共同定义了ClickHouse集群的拓扑结构和行为,确保了数据的分布式存储、高可用性和可扩展性。在配置ClickHouse集群时,应根据实际业务需求和硬件资源来合理规划分片和副本的数量。
5.在每台节点上启动/查看/重启/停止clickhouse服务
首先启动zookeeper集群,然后分别在node1、node2、node3节点上启动clickhouse服务,这里每台节点和单节点启动一样。启动之后,clickhouse集群配置完成。
#每台节点启动Clickchouse服务
service clickhouse-server start
#每台节点查看clickhouse服务状态
service clickhouse-server status
#每台节点重启clickhouse服务
service clickhouse-server restart
#每台节点关闭Clikchouse服务
service clickhouse-server stop
6,检查集群配置是否完成
在node1、node2、node3任意一台节点进入clickhouse客户端,查询集群配置:
#选择三台clickhouse任意一台节点,进入客户端
clickhouse-client
#查询集群信息,看到下图所示即代表集群配置成功。
node1 :) select * from system.clusters;

#查询集群信息,也可以使用如下命令
node1 :) select cluster,host_name from system.clusters;

7.测试clickhouse
#在clickhouse node1节点创建mergeTree表 mt
create table mt(id UInt8,name String,age UInt8) engine = MergeTree() order by (id);
#向表 mt 中插入数据
insert into table mt values(1,'zs',18),(2,'ls',19),(3,'ww',20);
#查询表mt中的数据
select * from mt;
1.5项目数据种类与采集
实时数仓项目中的数据分为两类,一类是业务系统产生的业务数据,这部分数据存储在MySQL数据库中,另一类是实时用户日志行为数据,这部分数据是用户登录系统产生的日志数据。
针对MySQL日志数据我们采用maxwell全量或者增量实时采集到大数据平台中,针对用户日志数据,通过log4j日志将数据采集到目录中,再通过Flume实时同步到大数据平台,总体数据采集思路如下图所示:
针对MySQL业务数据和用户日志数据构建离线+实时湖仓一体数据分析平台,我们暂时划分为会员主题和商品主题。下面了解下主题各类表情况。
1.5.1MySQL业务数据
1.5.1.1配置MySQL支持UTF8编码
在node2节点上配“/etc/my.cnf”文件,在对应的标签下加入如下配置,更改mysql数据库编码格式为utf-8:
[mysqld]
character-set-server=utf8
[client]
default-character-set = utf8
修改完成之后重启mysql即可。
1.5.1.2MySQL数据表
MySQL业务数据存储在库“lakehousedb”中,此数据库中的业务数据表如下:
1.会员基本信息表 : mc_member_info
2.会员收货地址表 : mc_member_address
3.用户登录数据表 : mc_user_login
4.商品分类表 : pc_product_category
5.商品基本信息表 : pc_product
1.5.1.3MySQL业务数据采集
我们通过maxwell数据同步工具监控MySQL binlog日志将MySQL日志数据同步到Kafka topic “KAFKA-DB-BUSSINESS-DATA”中,详细步骤如下:
1.配置maxwell config.properties文件
进入node3“/software/maxwell-1.28.2”目录,配置config.properties文件,主要是配置监控mysql日志数据对应的Kafka topic,配置详细内容如下:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=KAFKA-DB-BUSSINESS-DATA
#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table
#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell
#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用
client_id=maxwell_first
2.启动kafka,创建Kafka topic,并监控Kafka topic
启动Zookeeper集群、Kafka 集群,创建topic“KAFKA-DB-BUSSINESS-DATA” topic:
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DB-BUSSINESS-DATA --partitions 3 --replication-factor 3
#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DB-BUSSINESS-DATA
3.启动maxwell
#在node3节点上启动maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin/
[root@node3 bin]# maxwell --config ../config.properties
4.在mysql中创建“lakehousedb”并导入数据
#进入mysql ,创建数据库lakehousedb
[root@node2 ~]# mysql -u root -p123456
mysql> create database lakehousedb;
打开“Navicat”工具,将资料中(*资料获取方式:待定)*的“lakehousedb.sql”文件导入到MySQL数据库“lakehousedb”中,我们可以看到在对应的kafka topic “KAFKA-DB-BUSSINESS-DATA”中会有数据被采集过来。
1.5.2用户日志数据
1.5.2.1用户日志数据
目前用户日志数据只有“会员浏览商品日志数据”,其详细信息如下:
接口地址:/collector/common/browselog
请求方式:post
请求数据类型:application/json
接口描述:用户登录系统后,会有当前登录时间信息及当前用户登录后浏览商品,跳转链接、浏览所获积分等信息
请求示例:
{
"logTime": 1646393162044,
"userId": "uid529497",
"userIp": "216.36.11.233",
"frontProductUrl": "https://fo0z7oZj/rInb/ui",
"browseProductUrl": "https://2/5Rx/SqqOUsK4",
"browseProductTpCode": "202",
"browseProductCode": "q6HCcpxd2I",
"obtainPoints": 14,
}
请求参数解释如下:
| 参数名称 | 参数说明 |
|----------------|------------------------------------------------|
| logTime | 浏览日志时间 |
| userId | 用户编号 |
| userIp | 浏览Ip地址 |
| frontProductUrl| 跳转前URL地址,有为null,有的不为null |
| browseProductUrl| 浏览商品URL |
| browseProductTpCode| 浏览商品二级分类 |
| browseProductCode| 浏览商品编号 |
| obtainPoints | 浏览商品所获积分 |
1.5.2.2用户日志数据采集
日志数据采集是通过log4j日志配置来将用户的日志数据集中获取,编写日志采集接口在项目“LogCollector”中来采集用户日志数据。(该项目也在资料中)
当用户浏览网站触发对应的接口时,日志采集接口根据配合的log4j将用户浏览信息写入对应的目录中,然后通过Flume监控对应的日志目录,将用户日志数据采集到Kafka topic “KAFKA-USER-LOG-DATA”中。
模拟用户浏览日志数据,将用户浏览日志数据采集到Kafka中,详细步骤如下:
骤如下:
1.将日志采集接口项目打包,上传到node5节点
将日志采集接口项目“LogCollector”项目配置成生产环境prod,打包,上传到node5节点目录/software下。
2.编写Flume 配置文件a.properties
将a.properties存放在node5节点/software目录下,文件配置内容如下:
#设置source名称
a.sources = r1
#设置channel的名称
a.channels = c1
#设置sink的名称
a.sinks = k1
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a.sources.r1.filegroups = f1
#第一组监控的是对应文件夹中的什么文件:.log文件
a.sources.r1.filegroups.f1 = /software/lakehouselogs/userbrowse/.*log
# The channel can be defined as follows.
#设置source的channel名称
a.sources.r1.channels = c1
a.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a.channels.c1.transcationCapacity=100
# Each sink's type must be defined
#设置Kafka接收器
a.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a.sinks.k1.brokerList=node1:9092,node2:9092,node3:9092
#设置Kafka的Topic
a.sinks.k1.topic=KAFKA-USER-LOG-DATA
#设置序列化方式
a.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a.sinks.k1.channel = c1
3.在Kafka中创建对应的topic并监控
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-USER-LOG-DATA --partitions 3 --replication-factor 3
#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-USER-LOG-DATA
4.启动日志采集接口
在node5节点上启动日志采集接口,启动命令如下:
[root@node5 ~]# cd /software/
[root@node5 software]# java -jar ./logcollector-0.0.1-SNAPSHOT.jar
启动之后,根据日志采集接口配置会在“/software/lakehouselogs/userbrowse”目录中汇集用户浏览商品日志数据。
5.启动Flume,监控用户日志数据到Kafka
在node5节点上启动Flume,监控用户浏览日志数据到Kafka “KAFKA-USER-LOG-DATA” topic。
[root@node5 ~]# cd /software/
[root@node5 software]# flume-ng agent --name a -f /software/a.properties -Dflume.root.logger=INFO,console
6.启动模拟用户浏览日志代码,向日志采集接口生产数据
在window本地启动“LakeHouseMockData”项目下的“RTMockUserLogData”代码,向日志采集接口中生产用户浏览商品日志数据。
启动代码后,我们会在Kafka “KAFKA-USER-LOG-DATA” topic 中看到监控到的用户日志数据。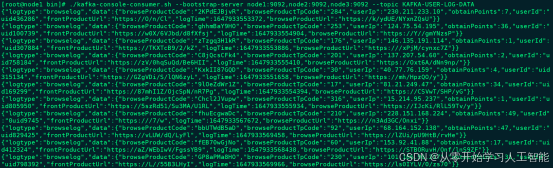
1.5.3错误事项解决
如果在向mysql中创建库及表时有如下错误:
[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
以上错误是由于MySQL sql_mode引起,对于group by聚合操作,如果在select中的列没有在group by中出现,那么这个SQL是不合法的。按照以下步骤来处理。
1.首先停止mysql,然后在mysql节点配置my.ini文件
[root@node2 ~]# service mysqld stop
打开/etc/my.cnf文件,在[mysqld]标签下配置如下内容:
[mysqld]
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
2.重启mysql即可解决
[root@node2 ~]# service mysqld start
1.6内网穿透工具-网云穿
一般开发完成接口部署后可以在本地使用localhost或者127.0.0.1来访问,在同一个局域网内的机器也可以通过访问局域网IP来实现接口访问,但是外网无法直接访问,我们需要使用腾讯云图来访问局域网内开发的接口,这就需要用到内网穿透工具,内网穿透工具可以让我们的局域网内部署的数据接口实现被外网访问。
目前内网穿透工具非常多,例如:花生壳、Net123、网云穿、Ngrok、闪库、AllProxy等。这里我们使用网云穿工具来实现内网穿透。
1.首先下载网云穿工具
下载地址:https://www.xiaomy.net/
点击免费版领取,注册并领取隧道。下载window版本,关闭window杀毒软件,然后解压安装包,点击“网云穿内网穿透.exe”运行登录即可。 
2.添加隧道
点击“添加隧道”,进入网页添加:

3.启动隧道,测试访问
登录客户端,启动隧道,并且启动本地SpringBoot项目,通过外网访问域名可以访问到内网接口。
1.7大屏可视化工具腾讯云图
大屏可视化工具有很多,例如:腾讯云图,帆软Finebi,阿里DataV,百度Sugar,思迈特SmartBi,免费的积木报表等工具。我们这里选择腾讯云图来实现数据可视化,网址:https://cloud.tencent.com/product/tcv,腾讯云图使用文档地址为:https://cloud.tencent.com/document/product/665
1.7.1腾讯云图介绍
腾讯云图(Tencent Cloud Visualization,简称TCV)是一款一站式数据可视化展示平台。该平台的设计目标是帮助用户快速通过可视化图表展示大量数据,实现低门槛、快速打造专业大屏数据展示。以下是腾讯云图的主要特点:
- 多种行业模板:腾讯云图为不同行业预设了多种模板,以极致展示数据的魅力。
- 拖拽式自由布局:用户可以直接将组件拖拽到画布上进行自由配置和布局,无需编码,全程图形化编辑。
- 支持多种数据来源:平台支持从静态数据、CSV文件、公网数据库、腾讯云数据库和API等多种数据源接入数据,并能实现数据的实时同步更新。
- 灵活投屏:基于Web页面渲染,可以灵活投屏至多种屏幕终端。
- 安全发布:支持公开发布,并提供密码验证和基于HMAC-SHA256 base64加密的Token验证,以保证项目安全。
- 云监控集成:集成了腾讯云的云服务器、云数据库等服务的云监控API,可以调取并实时展示云服务的监控数据。
腾讯云图的应用场景包括大数据展示、监控大屏和活动会场等,能够通过专业设计的样式、组件和模板,有效地展现商业价值和行业洞察。
1.7.2购买使用(目前应用已下线,可参考接入流程,使用其他可视化工具、也可以使用开源框架)
首先注册账号登录腾讯云,在腾讯云产品中选择“腾讯云图”,页面下方可以进行购买。也可以直接进入购买地址,http://yuntu.cloud.tencent.com/#/buy。购买时需要实名认证,目前1年个人试用版价格为19元。
腾讯云图使用如下:
1.登录腾讯云图,创建大屏
登录“https://console.cloud.tencent.com/tcv”腾讯云图,点击新建大屏:
2.创建“轮播表格”并配置
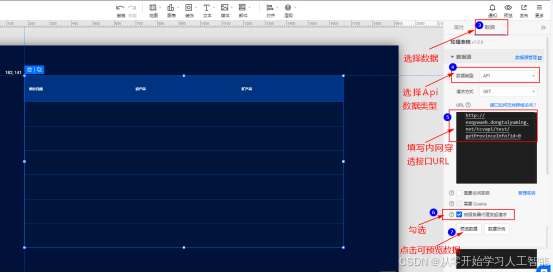
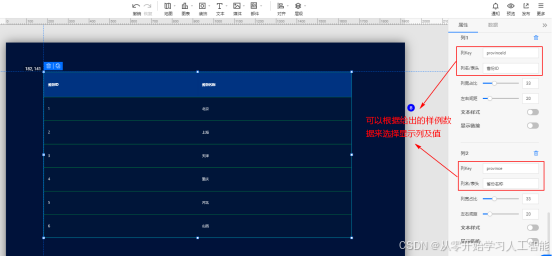
注意以上填写内网穿透接口地址时由于项目中没有配置安全访问,所以这里填写“http://exqywueb.dongtaiyuming.net//lakehouse/dataapi/getTestData”,http不要加s否则访问不到。
另外可以在“文本”中设置标题,在“装饰”中配置边跨及动画,达到更炫的效果。点击“预览”可以预览数据。
3.数据发布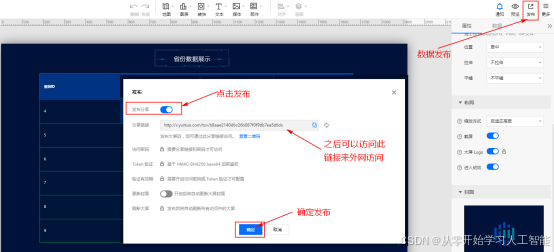
4.外网访问
浏览器输入:
“http://v.yuntus.com/tcv/b8aae2140d6c26b087f0f9db7ea5d6dc”地址,访问发布数据页。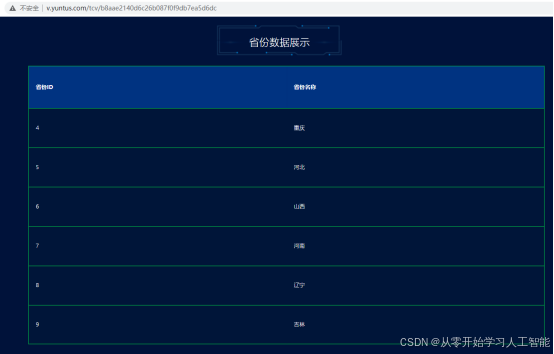
1.8实时业务:实时统计每个省份用户新增及pv、uv指标
1.8.1业务需求
利用网站实时登录会员数据和会员基本信息,我们能够实现对每个省份用户新增数量的实时统计,以及对每个省份实时用户的页面浏览量(PV)和独立访客数(UV)指标的动态监测。这些关键数据将通过一个直观的可视化大屏进行展示,以便于快速把握用户行为和市场动态。
1.8.2业务分层设计及流程图
本业务涉及的数据主要来源于三个关键业务表:用户登录数据表“mc_user_login”、会员基本信息表“mc_member_info”以及会员收货地址表“mc_member_address”。我们将这些业务数据采集至大数据平台,并采用数据湖技术Iceberg构建湖仓一体的数据仓库分层架构。在此架构中,“mc_user_login”表记录了用户的登录与登出信息,作为事实表在数据仓库中占据核心地位。而“mc_member_info”和“mc_member_address”两张表则提供了会员的基本信息数据,作为维度表为数据仓库提供丰富的描述性信息。
在湖仓分层的设计过程中,我们特别将维度数据存储于HBase,以利用其高效的随机读写能力;同时,将事实数据存储于 Iceberg数仓分层中,以实现高效的数据管理和分析。这样的设计既优化了数据存储结构,也提升了数据处理效率。
在前面的章节中,我们利用Maxwell实现了将MySQL业务库的数据实时同步至Kafka的“KAFKA-DB-BUSSINESS-DATA”主题。针对该主题中的数据,我们将采用Flink进行处理。Flink代码的主要任务包括:将所有业务库数据保留一份完整的副本存储至Iceberg的ODS层,同时对维度数据进行筛选后存储至Kafka,以便于后续的维度数据处理。此外,为了确保代码重启后能够从正确的位置继续消费数据,我们还将所有事实数据同样存储在Kafka中。这样的设计确保了数据的连续性和一致性。后续的数据处理层也将遵循这一逻辑进行操作。
湖仓分层设计如下图所示: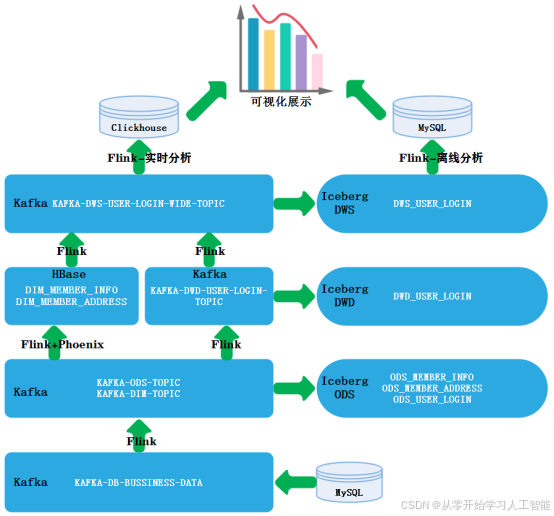
1.8.3业务实现
1.8.3.1编写写入ODS层业务代码
在湖仓一体架构中,ODS层主要负责存储原始的业务数据。针对“KAFKA-DB-BUSSINESS-DATA”主题中的数据,我们实现了以下两个核心功能:
- 原始数据存储:我们将从Kafka读取的MySQL业务数据完整地存储在Iceberg的ODS层中,这样做是为了满足项目可能出现的临时业务需求,确保数据的原始性和可用性。为了实现这一功能,我们首先需要在Hive中预先创建对应的Iceberg表,以便将数据写入。
- 数据分离存储:我们将事实数据和维度数据进行区分,并将它们分别存储在Kafka中对应的主题中。由于在“KAFKA-DB-BUSSINESS-DATA”主题中,binlog数据并未明确标记哪些是事实数据,哪些是维度数据,因此我们采用了一种巧妙的策略。我们在MySQL的配置表“lakehousedb.dim_tbl_config_info”中记录了维度表的信息,然后通过Flink获取这些信息并进行广播,与Kafka的实时数据流进行关联,从而有效地将事实数据和维度数据分开处理。
通过这种方式,我们不仅确保了数据的正确分类和存储,还提高了数据处理流程的灵活性和可维护性。
1.8.3.1.1编写写入ODS层业务代码
数据写入ODS层代码是“ProduceKafkaDBDataToODS.scala”。
这里我们 使用 scala 语言。
在湖仓一体的大数据项目中,Java和Scala混用的原因通常涉及以下几个方面:
- 历史与生态兼容性:
- Hadoop生态:Hadoop及其生态系统中的许多组件最初是用Java开发的,因此Java与这些系统的兼容性非常好。
- Spark生态:Apache Spark是一个新兴的大数据处理框架,它最初是用Scala编写的,Scala能够提供简洁的语法和丰富的库,这使得它在数据处理方面非常受欢迎。
- 语言特性:
- Scala的优势:Scala提供了简洁的语法、函数式编程特性、模式匹配等,这些特性使得编写数据处理和分析代码更加高效和简洁。
- Java的优势:Java具有稳定的性能、强大的生态系统、广泛的社区支持和良好的文档。
- 性能考量:
- 在某些情况下,Java的运行时性能可能比Scala更优越,尤其是在JVM优化方面。因此,对于性能要求极高的部分,可能会选择使用Java。
- 开发效率和可维护性:
- Scala的简洁性可以提高开发效率,尤其是在处理复杂的数据转换和业务逻辑时。
- Java的静态类型系统和严格的语法检查有助于维护大型项目和团队协作。
- 现有代码库和团队技能:
- 如果团队中已经存在大量的Java代码库,或者团队成员对Java更为熟悉,那么混用Java和Scala可以更好地利用现有资源和技术积累。
- 微服务架构:
- 在微服务架构中,不同的服务可能根据其特定需求选择最适合的语言。例如,数据处理和分析服务可能使用Scala,而其他服务可能使用Java。
总之,Java和Scala混用在大数据项目中是一种权衡的结果,旨在结合两种语言的优势,提高项目的开发效率、运行性能和可维护性。
- 在微服务架构中,不同的服务可能根据其特定需求选择最适合的语言。例如,数据处理和分析服务可能使用Scala,而其他服务可能使用Java。
业务主要代码逻辑实现如下:
object ProduceKafkaDBDataToODS {
private val mysqlUrl: String = ConfigUtil.MYSQL_URL
private val mysqlUser: String = ConfigUtil.MYSQL_USER
private val mysqlPassWord: String = ConfigUtil.MYSQL_PASSWORD
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
private val kafkaDimTopic: String = ConfigUtil.KAFKA_DIM_TOPIC
private val kafkaOdsTopic: String = ConfigUtil.KAFKA_ODS_TOPIC
private val kafkaDwdUserLogTopic: String = ConfigUtil.KAFKA_DWD_USERLOG_TOPIC
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
import org.apache.flink.streaming.api.scala._
env.enableCheckpointing(5000)
/**
* 1.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 2.创建 Kafka Connector,连接消费Kafka中数据
* 注意:1).关键字要使用 " 飘"符号引起来 2).对于json对象使用 map < String,String>来接收
*/
tblEnv.executeSql(
"""
|create table kafka_db_bussiness_tbl(
| database string,
| `table` string,
| type string,
| ts string,
| xid string,
| `commit` string,
| data map<string,string>
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DB-BUSSINESS-DATA',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='latest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.将不同的业务库数据存入各自的Iceberg表
*/
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_MEMBER_INFO
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['member_growth_score'] as member_growth_score,
| data['member_level'] as member_level,
| data['balance'] as balance,
| data['gmt_create'] as gmt_create,
| data['gmt_modified'] as gmt_modified
| from kafka_db_bussiness_tbl where `table` = 'mc_member_info'
""".stripMargin)
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_MEMBER_ADDRESS
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['province'] as province,
| data['city'] as city,
| data['area'] as area,
| data['address'] as address,
| data['log'] as log,
| data['lat'] as lat,
| data['phone_number'] as phone_number,
| data['consignee_name'] as consignee_name,
| data['gmt_create'] as gmt_create,
| data['gmt_modified'] as gmt_modified
| from kafka_db_bussiness_tbl where `table` = 'mc_member_address'
""".stripMargin)
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_USER_LOGIN
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['ip'] as ip,
| data['login_tm'] as login_tm,
| data['logout_tm'] as logout_tm
| from kafka_db_bussiness_tbl where `table` = 'mc_user_login'
""".stripMargin)
//4.读取 Kafka 中的数据,将维度数据另外存储到 Kafka 中
val kafkaTbl: Table = tblEnv.sqlQuery("select database,`table`,type,ts,xid,`commit`,data from kafka_db_bussiness_tbl")
//5.将kafkaTbl Table 转换成DStream 与MySql中的数据
val kafkaDS: DataStream[Row] = tblEnv.toAppendStream[Row](kafkaTbl)
//6.设置mapState,用于广播流
val mapStateDescriptor = new MapStateDescriptor[String,JSONObject]("mapStateDescriptor",classOf[String],classOf[JSONObject])
//7.从MySQL中获取配置信息,并广播
val bcConfigDs: BroadcastStream[JSONObject] = env.addSource(MySQLUtil.getMySQLData(mysqlUrl,mysqlUser,mysqlPassWord)).broadcast(mapStateDescriptor)
//8.设置维度数据侧输出流标记
val dimDataTag = new OutputTag[String]("dim_data")
//9.只监控mysql 数据库lakehousedb 中的数据,其他库binlog不监控,连接两个流进行处理
val factMainDs: DataStream[String] = kafkaDS.filter(row=>{"lakehousedb".equals(row.getField(0).toString)}).connect(bcConfigDs).process(new BroadcastProcessFunction[Row, JSONObject, String] {
override def processElement(row: Row, ctx: BroadcastProcessFunction[Row, JSONObject, String]#ReadOnlyContext, out: Collector[String]): Unit = {
//最后返回给Kafka 事实数据的json对象
val returnJsonObj = new JSONObject()
//获取广播状态
val robcs: ReadOnlyBroadcastState[String, JSONObject] = ctx.getBroadcastState(mapStateDescriptor)
//解析事件流数据
val nObject: JSONObject = CommonUtil.rowToJsonObj(row)
//获取当前时间流来自的库和表 ,样例数据如下
//lackhousedb,pc_product,insert,1646659263,21603,null,{gmt_create=1645493074001, category_id=220, product_name=黄金, product_id=npfSpLHB8U}
val dbName: String = nObject.getString("database")
val tableName: String = nObject.getString("table")
val key = dbName + ":" + tableName
if (robcs.contains(key)) {
//维度数据
val jsonValue: JSONObject = robcs.get(key)
//维度数据,将对应的 jsonValue中的信息设置到流事件中
nObject.put("tbl_name", jsonValue.getString("tbl_name"))
nObject.put("tbl_db", jsonValue.getString("tbl_db"))
nObject.put("pk_col", jsonValue.getString("pk_col"))
nObject.put("cols", jsonValue.getString("cols"))
nObject.put("phoenix_tbl_name", jsonValue.getString("phoenix_tbl_name"))
ctx.output(dimDataTag, nObject.toString)
}else{
//事实数据,加入iceberg 表名写入Kafka ODS-DB-TOPIC topic中
if("mc_user_login".equals(tableName)){
returnJsonObj.put("iceberg_ods_tbl_name","ODS_USER_LOGIN")
returnJsonObj.put("kafka_dwd_topic",kafkaDwdUserLogTopic)
returnJsonObj.put("data",nObject.toString)
}
out.collect(returnJsonObj.toJSONString)
}
}
override def processBroadcastElement(jsonObject: JSONObject, ctx: BroadcastProcessFunction[Row, JSONObject, String]#Context, out: Collector[String]): Unit = {
val tblDB: String = jsonObject.getString("tbl_db")
val tblName: String = jsonObject.getString("tbl_name")
//向状态中更新数据
val bcs: BroadcastState[String, JSONObject] = ctx.getBroadcastState(mapStateDescriptor)
bcs.put(tblDB + ":" + tblName, jsonObject)
println("广播数据流设置完成...")
}
})
//10.结果写入到Kafka - dim_data_topic topic中
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
factMainDs.addSink(new FlinkKafkaProducer[String](kafkaOdsTopic,new KafkaSerializationSchema[String] {
override def serialize(element: String, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte],Array[Byte]](kafkaOdsTopic,null,element.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))//暂时使用at_least_once语义,exactly_once语义有些bug问题
factMainDs.getSideOutput(dimDataTag).addSink(new FlinkKafkaProducer[String](kafkaDimTopic,new KafkaSerializationSchema[String] {
override def serialize(element: String, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte],Array[Byte]](kafkaDimTopic,null,element.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))//暂时使用at_least_once语义,exactly_once语义有些bug问题
env.execute()
}
}
1.8.3.1.2创建Iceberg-ODS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg表有“ODS_MEMBER_INFO”、“ODS_MEMBER_ADDRESS”、“ODS_USER_LOGIN”,创建语句如下:
#在Hive客户端执行以下建表语句
CREATE TABLE ODS_MEMBER_INFO (
id string,
user_id string,
member_growth_score string,
member_level string,
balance string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_MEMBER_ADDRESS (
id string,
user_id string,
province string,
city string,
area string,
address string,
log string,
lat string,
phone_number string,
consignee_name string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_ADDRESS/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
以上语句在Hive客户端执行完成之后,在HDFS中可以看到对应的Iceberg数据目录: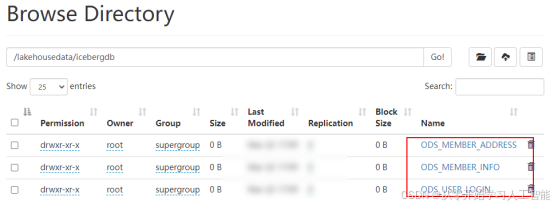
1.8,3.1.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-ODS-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-ODS-TOPIC --partitions 3 --replication-factor 3
#在Kafka 中创建 KAFKA-DIM-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DIM-TOPIC --partitions 3 --replication-factor 3
#监控以上两个topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-ODS-TOPIC
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DIM-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
3)执行代码,查看对应topic中的结果
以上代码执行后在,在对应的Kafka “KAFKA-DIM-TOPIC”和“KAFKA-ODS-TOPIC”中都有对应的数据。在Iceberg-ODS层中对应的表中也有数据。
1.8.3.2编写写入DIM层业务代码
编写代码读取Kafka “KAFKA-DIM-TOPIC” topic维度数据通过Phoenix写入到HBase中,我们可以通过topic中每条数据获取该条数据对应的phoenix表名及字段名动态创建phoenix表以及插入数据,这里所有在mysql“lakehousedb.dim_tbl_config_info”中配置的维度表都会动态的写入到HBase中。这里使用Flink处理对应topic数据时如果维度数据需要清洗还可以进行清洗。
1.8.3.2.1代码编写
读取Kafka 维度数据写入HBase代码为“DimDataToHBase.scala”,主要代码逻辑如下:
object DimDataToHBase {
private val consumeKafkaFromEarliest: Boolean = ConfigUtil.CONSUME_KAFKA_FORMEARLIEST
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
private val kafakDimTopic: String = ConfigUtil.KAFKA_DIM_TOPIC
private val phoenixURL: String = ConfigUtil.PHOENIX_URL
var ds: DataStream[String] = _
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//1.导入隐式转换
import org.apache.flink.streaming.api.scala._
//2.设置Kafka配置
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
props.setProperty("key.deserializer",classOf[StringDeserializer].getName)
props.setProperty("value.deserializer",classOf[StringDeserializer].getName)
props.setProperty("group.id","mygroup.id")
//3.从数据中获取Kafka DIM层 KAFKA-DIM-TOPIC 数据
/**
* 数据样例:
* {
* "gmt_create": "1646037374201",
* "commit": "true",
* "tbl_name": "mc_member_info",
* "type": "insert",
* "gmt_modified": "1646037374201",
* "member_level": "3",
* "database": "lakehousedb",
* "xid": "38450",
* "pk_col": "id",
* "balance": "10482",
* "user_id": "0uid9060",
* "phoenix_tbl_name": "DIM_MEMBER_INFO",
* "tbl_db": "lakehousedb",
* "member_points": "7568",
* "id": "10014",
* "cols": "user_id,member_growth_score,member_level,member_points,balance,gmt_create,gmt_modified",
* "table": "mc_member_info",
* "member_growth_score": "3028",
* "ts": "1646901373"
* }
*
*/
if(consumeKafkaFromEarliest){
ds = env.addSource(MyKafkaUtil.GetDataFromKafka(kafakDimTopic,props).setStartFromEarliest())
}else{
ds = env.addSource(MyKafkaUtil.GetDataFromKafka(kafakDimTopic,props))
}
ds.keyBy(line=>{
JSON.parseObject(line).getString("phoenix_tbl_name")
}).process(new KeyedProcessFunction[String,String,String] {
//设置状态,存储每个Phoenix表是否被创建
lazy private val valueState: ValueState[String] = getRuntimeContext.getState(new ValueStateDescriptor[String]("valueState",classOf[String]))
var conn: Connection = _
var pst: PreparedStatement = _
//在open方法中,设置连接Phoenix ,方便后期创建对应的phoenix表
override def open(parameters: Configuration): Unit = {
println("创建Phoenix 连接... ...")
conn = DriverManager.getConnection(phoenixURL)
}
override def processElement(jsonStr: String, ctx: KeyedProcessFunction[String, String, String]#Context, out: Collector[String]): Unit = {
val nObject: JSONObject = JSON.parseObject(jsonStr)
//从json 对象中获取对应 hbase 表名、主键、列信息
val operateType: String = nObject.getString("type")
val phoenixTblName: String = nObject.getString("phoenix_tbl_name")
val pkCol: String = nObject.getString("pk_col")
val cols: String = nObject.getString("cols")
//判断操作类型,这里只会向HBase中存入增加、修改的数据,删除等其他操作不考虑
//operateType.equals("bootstrap-insert") 这种情况主要是使用maxwell 直接批量同步维度数据时,操作类型为bootstrap-insert
if(operateType.equals("insert")||operateType.equals("update")||operateType.equals("bootstrap-insert")){
//判断状态中是否有当前表状态,如果有说明已经被创建,没有就组织建表语句,通过phoenix创建维度表
if(valueState.value() ==null){
createPhoenixTable(phoenixTblName, pkCol, cols)
//更新状态
valueState.update(phoenixTblName)
}
//向phoenix表中插入数据,同时方法中涉及数据清洗
upsertIntoPhoenixTable(nObject, phoenixTblName, pkCol, cols)
/**
* 当有维度数据更新时,那么将Redis中维度表缓存删除
* Redis中 key 为:维度表-主键值
*/
if(operateType.equals("update")){
//获取当前更新数据中主键对应的值
val pkValue: String = nObject.getJSONObject("data").getString(pkCol)
//组织Redis中的key
val key = phoenixTblName+"-"+pkValue
//删除Redis中缓存的此key对应数据,没有此key也不会报错
MyRedisUtil.deleteKey(key)
}
out.collect("执行成功")
}
}
private def upsertIntoPhoenixTable(nObject: JSONObject, phoenixTblName: String, pkCol: String, cols: String): Unit = {
//获取向phoenix中插入数据所有列
val colsList: ListBuffer[String] = MyStringUtil.getAllCols(cols)
//获取主键对应的值
val pkValue: String = nObject.getString(pkCol)
//组织向表中插入数据的语句
//upsert into test values ('1','zs',18);
val upsertSQL = new StringBuffer(s"upsert into ${phoenixTblName} values ('${pkValue}'")
for (col <- colsList) {
val currentColValue: String = nObject.getString(col)
println("colsList = "+colsList.toString+" - current col = "+currentColValue)
//将列数据中的 “'”符号进行转义
upsertSQL.append(s",'${currentColValue.replace("'","\\'")}'")
}
upsertSQL.append(s")")
//向表中Phoenix中插入数据
println("phoenix 插入Sql = "+upsertSQL.toString)
pst = conn.prepareStatement(upsertSQL.toString)
pst.execute()
//这里如果想要批量提交,可以设置状态,当每个key 满足1000条时,commit一次,
// 另外定义定时器,每隔2分钟自动提交一次,防止有些数据没有达到2000条时没有存入Phoenix
conn.commit()
}
private def createPhoenixTable(phoenixTblName: String, pkCol: String, cols: String): Boolean = {
//获取所有列
val colsList: ListBuffer[String] = MyStringUtil.getAllCols(cols)
//组织phoenix建表语句,为了后期操作方便,这里建表语句所有列族指定为“cf",所有字段都为varchar
//create table xxx (id varchar primary key ,cf.name varchar,cf.age varchar);
val createSql = new StringBuffer(s"create table if not exists ${phoenixTblName} (${pkCol} varchar primary key,")
for (col <- colsList) {
createSql.append(s"cf.${col.replace("'","\\'")} varchar,")//处理数据中带 ' 的数据
}
//将最后一个逗号替换成“) column_encoded_bytes=0” ,最后这个参数是不让phoenix对数据进行16进制编码
createSql.replace(createSql.length() - 1, createSql.length(), ") column_encoded_bytes=0")
println(s"拼接Phoenix SQL 为 = ${createSql}")
//执行sql
pst = conn.prepareStatement(createSql.toString)
pst.execute()
}
//关闭连接
override def close(): Unit = {
pst.close()
conn.close()
}
}).print()
env.execute()
}
}
1.8.3.2.2代码测试
执行代码之前首先需要启动HDFS、HBase,代码中设置读取Kafka数据从头开始读取,然后执行代码,代码执行完成后可以进入phoenix中查看对应的结果:
# 在node4节点上启动phoenix
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
[root@node4 bin]# ./sqlline.py
1.8.3.3编写写入DWD层业务代码
DWD层数据主要存储干净的明细数据,这里针对ODS层“KAFKA-ODS-TOPIC”数据编写代码进行清洗写入对应的Kafka topic和Iceberg-DWD层中。代码功能中有以下几点重要方面:
针对Kafka ODS层中的数据进行清洗,写入Iceberg-DWD层中。
将数据除了写入Iceberg-DWD层中之外,还要写入Kafka中方便后续处理得到DWS层数据。
1.8.3.3.1代码编写
编写处理Kafka ODS层数据写入Iceberg-DWD层数据时,由于在Kafka “KAFKA-ODS-TOPIC”topic中每条数据都已经有对应写入kafka的topic信息,所以这里我们只需要读取“KAFKA-ODS-TOPIC”topic中的数据写入到Iceberg-DWD层中,另外动态获取每条数据写入Kafka topic信息将每条数据写入到对应的topic即可。
具体代码参照“ProduceODSDataToDWD.scala”,大体代码逻辑如下:
case class DwdInfo (iceberg_ods_tbl_name:String,kafka_dwd_topic:String,browse_product_code:String,browse_product_tpcode:String,user_ip:String,obtain_points:String,user_id1:String,user_id2:String, front_product_url:String, log_time:String, browse_product_url:String ,id:String,ip:String, login_tm:String,logout_tm:String)
object ProduceODSDataToDWD {
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 2.创建 Kafka Connector,连接消费Kafka ods中数据
*/
tblEnv.executeSql(
"""
|create table kafka_ods_tbl(
| iceberg_ods_tbl_name string,
| kafka_dwd_topic string,
| data string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-ODS-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='latest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
val odsTbl :Table = tblEnv.sqlQuery(
"""
| select iceberg_ods_tbl_name,data,kafka_dwd_topic from kafka_ods_tbl
""".stripMargin)
val odsDS: DataStream[Row] = tblEnv.toAppendStream[Row](odsTbl)
//3.设置Sink 到Kafka 数据输出到侧输出流标记
val kafkaDataTag = new OutputTag[JSONObject]("kafka_data")
/**
* 4.表准换成对应的DataStream数据处理,清洗ODS 中的数据,存入Iceberg
* {
* "iceberg_ods_tbl_name": "ODS_BROWSELOG",
* "data": "{\"browseProductCode\":\"yyRAteviDb\",\"browseProductTpCode\":\"120\",\"userIp\":\"117.233.5.190\",\"obtainPoints\":\"24\",
* \"userId\":\"uid464936\",\"frontProductUrl\":\"https://1P//2RQbHFS2\",\"logTime\":\"1647065858856\",\"browseProductUrl\":\"https://RXm/iOUxR/Tliu9TE0\"}",
* "kafka_dwd_topic": "KAFKA-DWD-BROWSE-LOG-TOPIC"
* }
*
* {
* "iceberg_ods_tbl_name": "ODS_USER_LOGIN",
* "data": "{\"database\":\"lakehousedb\",\"xid\":\"14942\",\"user_id\":\"uid283876\",\"ip\":\"215.148.233.254\",\"commit\":\"true\",
* \"id\":\"10052\",\"type\":\"insert\",\"logout_tm\":\"1647066506140\",\"table\":\"mc_user_login\",\"ts\":\"1647066504\",\"login_tm\":\"1647051931534\"}",
* "kafka_dwd_topic": "KAFKA-DWD-USER-LOGIN-TOPIC"
* }
*
* 这里将数据转换成DataStream后再转换成表写入Iceberg
*
*/
//对数据只是时间进行清洗,转换成DwdInfo 类型DataStream 返回,先过滤一些数据为null的
val dwdDS: DataStream[DwdInfo] = odsDS.filter(row=>{row.getField(0)!=null && row.getField(1)!=null &&row.getField(2)!=null })
.process(new ProcessFunction[Row,DwdInfo]() {
override def processElement(row: Row, context: ProcessFunction[Row, DwdInfo]#Context, collector: Collector[DwdInfo]): Unit = {
val iceberg_ods_tbl_name: String = row.getField(0).toString
val data: String = row.getField(1).toString
val kafka_dwd_topic: String = row.getField(2).toString
val jsonObj: JSONObject = JSON.parseObject(data)
//清洗日期数据
jsonObj.put("logTime",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("logTime")))
jsonObj.put("login_tm",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("login_tm")))
jsonObj.put("logout_tm",DateUtil.getDateYYYYMMDDHHMMSS(jsonObj.getString("logout_tm")))
//解析json 嵌套数据
val browse_product_code: String = jsonObj.getString("browseProductCode")
val browse_product_tpcode: String = jsonObj.getString("browseProductTpCode")
val user_ip: String = jsonObj.getString("userIp")
val obtain_points: String = jsonObj.getString("obtainPoints")
val user_id1: String = jsonObj.getString("user_id")
val user_id2: String = jsonObj.getString("userId")
val front_product_url: String = jsonObj.getString("frontProductUrl")
val log_time: String = jsonObj.getString("logTime")
val browse_product_url: String = jsonObj.getString("browseProductUrl")
val id: String = jsonObj.getString("id")
val ip: String = jsonObj.getString("ip")
val login_tm: String = jsonObj.getString("login_tm")
val logout_tm: String = jsonObj.getString("logout_tm")
//往各类数据 data json 对象中加入sink dwd topic 的信息
jsonObj.put("kafka_dwd_topic",kafka_dwd_topic)
context.output(kafkaDataTag,jsonObj)
collector.collect(DwdInfo(iceberg_ods_tbl_name, kafka_dwd_topic, browse_product_code, browse_product_tpcode, user_ip, obtain_points,
user_id1,user_id2, front_product_url, log_time, browse_product_url, id, ip, login_tm, logout_tm))
}
})
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
/**
* 6.将以上数据写入到Kafka 各自DWD 层topic中,这里不再使用SQL方式,而是直接使用DataStream代码方式 Sink 到各自的DWD层代码中
*/
dwdDS.getSideOutput(kafkaDataTag).addSink(new FlinkKafkaProducer[JSONObject]("KAFKA-DWD-DEFAULT-TOPIC",new KafkaSerializationSchema[JSONObject] {
override def serialize(jsonObj: JSONObject, aLong: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
val sinkDwdTopic: String = jsonObj.getString("kafka_dwd_topic")
new ProducerRecord[Array[Byte], Array[Byte]](sinkDwdTopic,null,jsonObj.toString.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))
env.execute()
}
}
1.8.3.3.2创建Iceberg-DWD层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg-DWD表有“DWD_USER_LOGIN”,创建语句如下:
CREATE TABLE DWD_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
1.8.3.3.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWD-USER-LOGIN-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-USER-LOGIN-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWD-USER-LOGIN-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
3)执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWD-USER-LOGIN-TOPIC” topic中都有对应的数据。在Iceberg-DWD层中对应的表中也有数据。
Kafka中结果如下: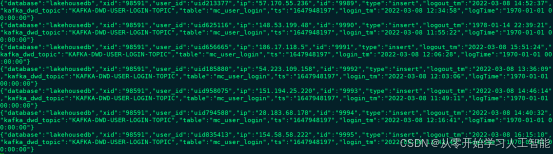
Iceberg-DWD层表”DWD_USER_LOGIN”中的数据如下: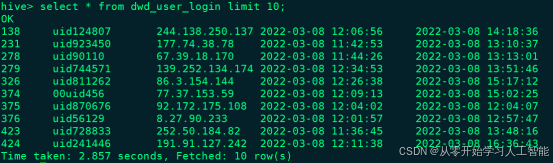
1.8.3.4编写写入DWS层业务代码
"在本业务场景中,DWS层专门设计用于存储经过整合的大宽表数据。我们主要关注Kafka主题’KAFKA-DWD-USER-LOGIN-TOPIC’中的用户登录事件,通过与HBase中存储的’DIM_MEMBER_INFO’用户基本信息和’DIM_MEMBER_ADDRESS’用户地址信息维度表进行关联,构建出用户主题的大宽表。
为了提高数据处理的效率,Flink在处理来自Kafka的用户登录数据时,采用了Redis作为缓存层,以加速与HBase中维度数据的关联过程。完成用户主题宽表的构建后,我们将其数据持久化存储到Iceberg-DWS层。同时,为了支持后续的实时统计分析,我们还将宽表数据的输出结果发送到Kafka,确保数据流的连续性和实时性。"
1.8.3.4.1代码编写
具体代码参照“ProduceUserLogInToDWS.scala”,大体代码逻辑如下:
object ProduceUserLogInToDWS {
private val hbaseDimMemberInfoTbl: String = ConfigUtil.HBASE_DIM_MEMBER_INFO
private val hbaseDimMemberAddressInfoTbl: String = ConfigUtil.HBASE_DIM_MEMBER_ADDRESS_INFO
private val kafkaDwsUserLoginWideTopic: String = ConfigUtil.KAFKA_DWS_USER_LOGIN_WIDE_TOPIC
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 3.创建 Kafka Connector,连接消费Kafka dwd中数据
* {
* "database": "lakehousedb",
* "xid": "35632",
* "user_id": "uid141138",
* "ip": "28.217.141.249",
* "commit": "true",
* "id": "10093",
* "type": "insert",
* "logout_tm": "年-月-日 时:分:秒",
* "kafka_dwd_topic": "KAFKA-DWD-USER-LOGIN-TOPIC",
* "table": "mc_user_login",
* "ts": "1647074110",
* "login_tm": "年-月-日 时:分:秒"
* }
*/
tblEnv.executeSql(
"""
|create table kafka_dwd_user_login_tbl (
| id string,
| user_id string,
| ip string,
| login_tm string,
| logout_tm string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DWD-USER-LOGIN-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='latest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
val userLogInTbl:Table = tblEnv.sqlQuery(
"""
| select user_id,ip,login_tm,logout_tm from kafka_dwd_user_login_tbl
""".stripMargin)
//4.将Row 类型数据转换成对象类型操作
val userLogInDS: DataStream[UserLogin] = tblEnv.toAppendStream[Row](userLogInTbl).map(row=>{
val userId: String = row.getField(0).toString
val ip: String = row.getField(1).toString
val loginTm: String = row.getField(2).toString
val logoutTm: String = row.getField(3).toString
UserLogin(userId,ip,loginTm,logoutTm)
})
//5.设置Sink 到Kafka 数据输出到侧输出流标记
val kafkaDataTag = new OutputTag[JSONObject]("kafka_data")
//6.连接phoenix 库查询HBase数据组织宽表
val wideUserLoginDS: DataStream[UserLoginWideInfo] = userLogInDS.process(processFunction = new ProcessFunction[UserLogin, UserLoginWideInfo]() {
var conn: Connection = _
var pst: PreparedStatement = _
var rs: ResultSet = _
//创建Phoenix 连接
override def open(parameters: Configuration): Unit = {
//连接Phoenix
println(s"连接Phoenix ... ...")
conn = DriverManager.getConnection(ConfigUtil.PHOENIX_URL)
}
override def processElement(userLogin: UserLogin, context: ProcessFunction[UserLogin, UserLoginWideInfo]#Context, collector: Collector[UserLoginWideInfo]): Unit = {
//最终返回的json 对象
val jsonObj = new JSONObject()
jsonObj.put("user_id", userLogin.user_id)
jsonObj.put("ip", userLogin.ip)
jsonObj.put("login_tm", userLogin.login_tm)
jsonObj.put("logout_tm", userLogin.logout_tm)
//根据 用户user_id 从Redis缓存中读取 DIM_MEMBER_INFO - 用户基本信息表
val memberInfoRedisCacheInfo: String = MyRedisUtil.getInfoFromRedisCache(hbaseDimMemberInfoTbl, userLogin.user_id)
//根据 用户user_id 从Redis缓存中读取 DIM_MEMBER_ADDRESS - 用户收货地址表
val memberAddressInfo: String = MyRedisUtil.getInfoFromRedisCache(hbaseDimMemberAddressInfoTbl, userLogin.user_id)
if (MyStringUtil.isEmpty(memberInfoRedisCacheInfo)) {
//说明缓存中没有数据,从phoenix中查询
println("连接Phoenix查询 DIM_MEMBER_INFO - 用户基本信息表 维度数据")
val sql = s"select user_id,member_growth_score,member_level,member_points,balance,gmt_create,gmt_modified from DIM_MEMBER_INFO where user_id = '${userLogin.user_id}'"
println("phoenix 执行SQL 如下: "+sql)
pst = conn.prepareStatement(sql)
rs = pst.executeQuery()
//准备 向Redis 中写入 DIM_MEMBER_INFO - 用户基本信息表 的json对象
val dimMemberInfoRedisJsonObj = new JSONObject()
while (rs.next()) {
dimMemberInfoRedisJsonObj.put("member_growth_score", rs.getString("member_growth_score"))
dimMemberInfoRedisJsonObj.put("member_level", rs.getString("member_level"))
dimMemberInfoRedisJsonObj.put("member_points", rs.getString("member_points"))
dimMemberInfoRedisJsonObj.put("balance", rs.getString("balance"))
dimMemberInfoRedisJsonObj.put("gmt_create", rs.getString("gmt_create"))
dimMemberInfoRedisJsonObj.put("gmt_modified", rs.getString("gmt_modified"))
//将用户信息存入Redis缓存,向Redis中设置数据缓存
MyRedisUtil.setRedisDimCache(hbaseDimMemberInfoTbl, userLogin.user_id, dimMemberInfoRedisJsonObj.toString)
//将json 加入到总返回结果的Json中
CommonUtil.AddAttributeToJson(jsonObj, dimMemberInfoRedisJsonObj)
}
} else {
//从redis 中获取 json 信息设置在最终结果中
println("DIM_MEMBER_INFO - 用户基本信息表 从Redis中获取到缓存处理")
CommonUtil.AddAttributeToJson(jsonObj, JSON.parseObject(memberInfoRedisCacheInfo))
}
if (MyStringUtil.isEmpty(memberAddressInfo)) {
//说明缓存中没有数据,从phoenix中查询
println("连接Phoenix查询 DIM_MEMBER_INFO - 用户基本信息表 维度数据")
val sql = s"select province,city,area,address,lon,lat,phone_number,consignee_name from DIM_MEMBER_ADDRESS where user_id = '${userLogin.user_id}'"
pst = conn.prepareStatement(sql)
rs = pst.executeQuery()
//准备 向Redis 中写入 DIM_MEMBER_ADDRESS - 用户收货地址表 的json对象
val dimMemberAddressInfoRedisJsonObj = new JSONObject()
while (rs.next()) {
dimMemberAddressInfoRedisJsonObj.put("province", rs.getString("province"))
dimMemberAddressInfoRedisJsonObj.put("city", rs.getString("city"))
dimMemberAddressInfoRedisJsonObj.put("area", rs.getString("area"))
dimMemberAddressInfoRedisJsonObj.put("address", rs.getString("address"))
dimMemberAddressInfoRedisJsonObj.put("phone_number", rs.getString("phone_number"))
dimMemberAddressInfoRedisJsonObj.put("consignee_name", rs.getString("consignee_name"))
//将用户信息存入Redis缓存,向Redis中设置数据缓存
MyRedisUtil.setRedisDimCache(hbaseDimMemberAddressInfoTbl, userLogin.user_id, dimMemberAddressInfoRedisJsonObj.toString)
//将json 加入到总返回结果的Json中
CommonUtil.AddAttributeToJson(jsonObj, dimMemberAddressInfoRedisJsonObj)
}
} else {
//从redis 中获取 json 信息设置在最终结果中
println("DIM_MEMBER_INFO - 用户基本信息表 从Redis中获取到缓存处理")
CommonUtil.AddAttributeToJson(jsonObj, JSON.parseObject(memberAddressInfo))
}
//准备向Kafka 中存储的数据json 对象
context.output(kafkaDataTag,jsonObj)
//最终返回 jsonObj,此时jsonObj包含了所有json 信息
/**
* {
* "gmt_create": "1645019077772",
* "area": "迎泽区",
* "address": "山西省太原市迎泽区郝庄镇忽塌沟龙城森林公园",
* "city": "太原市",
* "ip": "114.179.78.99",
* "consignee_name": "凤玫维",
* "gmt_modified": "1645019077772",
* "member_level": "2",
* "balance": "79755",
* "province": "山西省",
* "user_id": "uid886111",
* "member_points": "5063",
* "phone_number": "15868964061",
* "logout_tm": "2022-03-08 12:42:18",
* "member_growth_score": "5012",
* "login_tm": "2022-03-08 12:13:56"
* }
*/
collector.collect(UserLoginWideInfo(jsonObj.getString("user_id"),jsonObj.getString("ip"),jsonObj.getString("gmt_create"),
jsonObj.getString("login_tm"),jsonObj.getString("logout_tm"),jsonObj.getString("member_level"),jsonObj.getString("province"),
jsonObj.getString("city"),jsonObj.getString("area"),jsonObj.getString("address"),jsonObj.getString("member_points"),
jsonObj.getString("balance"),jsonObj.getString("member_growth_score")))
}
override def close(): Unit = {
rs.close()
pst.close()
conn.close()
}
})
/**
* 7.将清洗完的数据存入Iceberg 表中
* 将宽表转换成表存储在 iceberg - DWS 层 DWS_USER_LOGIN ,
*/
val table: Table = tblEnv.fromDataStream(wideUserLoginDS)
tblEnv.executeSql(
s"""
|insert into hadoop_iceberg.icebergdb.DWS_USER_LOGIN
|select
| user_id,
| ip,
| gmt_create,
| login_tm,
| logout_tm,
| member_level,
| province,
| city,
| area,
| address,
| member_points,
| balance,
| member_growth_score
| from ${table}
""".stripMargin)
//8.同时将结果存储在Kafka KAFKA-DWS-USER-LOGIN-TOPIC topic中
/**
* 将以上数据写入到Kafka 各自DWD 层topic中,这里不再使用SQL方式,而是直接使用DataStream代码方式 Sink 到各自的DWD层代码中
*/
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
wideUserLoginDS.getSideOutput(kafkaDataTag).addSink(new FlinkKafkaProducer[JSONObject](kafkaDwsUserLoginWideTopic,new KafkaSerializationSchema[JSONObject] {
override def serialize(jsonObj: JSONObject, timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte], Array[Byte]](kafkaDwsUserLoginWideTopic,null,jsonObj.toString.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))
env.execute()
}
}
1.8.3.4.2创建Iceberg-DWS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg-DWS表有“DWS_USER_LOGIN”,创建语句如下:
CREATE TABLE DWS_USER_LOGIN (
user_id string,
ip string,
gmt_create string,
login_tm string,
logout_tm string,
member_level string,
province string,
city string,
area string,
address string,
member_points string,
balance string,
member_growth_score string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWS_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
1.8.3.4.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWS-USER-LOGIN-WIDE-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWS-USER-LOGIN-WIDE-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWS-USER-LOGIN-WIDE-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
3)执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWS-USER-LOGIN-WIDE-TOPIC” topic中都有对应的数据。在Iceberg-DWS层中对应的表中也有数据。
Kafka中结果如下: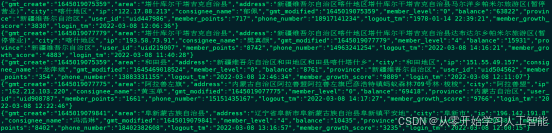
Iceberg-DWD层表”DWS_USER_LOGIN”中的数据如下: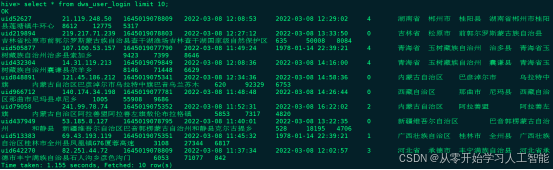
1.8.3.5编写写入DM层业务代码
DM层主要是报表数据,针对实时业务将DM层设置在Clickhouse中,在此业务中DM层主要存储的是通过Flink读取Kafka “KAFKA-DWS-USER-LOGIN-WIDE-TOPIC” topic中的数据进行分析的结果,实时写入到Clickhouse中。
1.8.3.5.1代码编写
具体代码参照“ProcessUserLoginInfoToDM.scala”,大体代码逻辑如下:
object ProcessUserLoginInfoToDM {
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.创建 Kafka Connector,连接消费Kafka dwd中数据
* {
* "gmt_create": "1645019077786",
* "area": "淮阴区",
* "address": "江苏省淮安市淮阴区渔沟镇淮西村",
* "city": "淮安市",
* "ip": "141.252.65.108",
* "consignee_name": "苗优奇",
* "gmt_modified": "1645019077786",
* "member_level": "2",
* "balance": "58444",
* "province": "江苏省",
* "user_id": "uid534024",
* "member_points": "5700",
* "phone_number": "17866060116",
* "logout_tm": "2022-03-08 12:31:12",
* "member_growth_score": "9832",
* "login_tm": "2022-03-08 11:48:09"
* }
*/
tblEnv.executeSql(
"""
|create table kafka_dws_user_login_wide_tbl (
| user_id string,
| ip string,
| gmt_create string,
| login_tm string,
| logout_tm string,
| member_level string,
| province string,
| city string,
| area string,
| address string,
| member_points string,
| member_growth_score string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DWS-USER-LOGIN-WIDE-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.实时统计每个省份新增你会员数量及每个省份pv,uv
* now() == current_timestamp 返回时间戳 timestamp 格式日期:2022-03-15T06:20:51.788
*/
val dwsTbl:Table = tblEnv.sqlQuery(
"""
| select province,city,user_id,login_tm,gmt_create from kafka_dws_user_login_wide_tbl
""".stripMargin)
//4.将Row 类型数据转换成对象类型操作
val dwsDS: DataStream[UserLoginWideInfo] = tblEnv.toAppendStream[Row](dwsTbl)
.filter(row=>{row.getField(0)!=null})
.map(row => {
val province: String = row.getField(0).toString
val city: String = row.getField(1).toString
val user_id: String = row.getField(2).toString
val login_tm: String = row.getField(3).toString
val gmt_create: String = row.getField(4).toString
UserLoginWideInfo(user_id, null, DateUtil.getDateYYYYMMDDHHMMSS(gmt_create), login_tm, null, null, province, city, null, null, null, null, null)
})
/**
* 5.将以上结果写入到Clickhouse表 dm_user_login_info 表中
* create table dm_user_login_info(
* dt String,
* province String,
* city String,
* user_id String,
* login_tm String,
* gmt_create String
* ) engine = MergeTree() order by dt;
*/
//准备向ClickHouse中插入数据的sql
val insertIntoCkSql = "insert into dm_user_login_info (dt,province,city,user_id,login_tm,gmt_create) values (?,?,?,?,?,?)"
val ckSink: SinkFunction[UserLoginWideInfo] = MyClickHouseUtil.clickhouseSink[UserLoginWideInfo](insertIntoCkSql, new JdbcStatementBuilder[UserLoginWideInfo] {
override def accept(ps: PreparedStatement, userLoginWideInfo: UserLoginWideInfo): Unit = {
ps.setString(1, DateUtil.getCurrentDateYYYYMMDD())
ps.setString(2, userLoginWideInfo.province)
ps.setString(3, userLoginWideInfo.city)
ps.setString(4, userLoginWideInfo.user_id)
ps.setString(5, userLoginWideInfo.login_tm)
ps.setString(6, userLoginWideInfo.gmt_create)
}
})
//6.针对数据加入sink
dwsDS.addSink(ckSink)
env.execute()
}
}
1.8.3.5.2创建Clickhouse-DM层表
代码在执行之前需要在Clickhouse中创建对应的DM层用户登录信息表dm_user_login_info,clickhouse建表语句如下:
#node1节点启动clickhouse
[root@node1 bin]# service clickhouse-server start
#node1节点进入clickhouse
[root@node1 bin]# clickhouse-client -m
#node1节点创建clickhouse-DM层表
create table dm_user_login_info(
dt String,
province String,
city String,
user_id String,
login_tm String,
gmt_create String
) engine = MergeTree() order by dt;
1.8.3.5.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
2)执行代码,查看对应结果
以上代码执行后在,在Clickhouse-DM层中表“dm_user_login_info”中查看对应数据结果如下: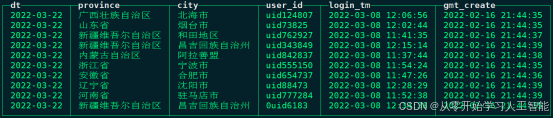
1.8.4数据发布接口
"在Flink处理完毕后,我们将实时结果数据写入Clickhouse-DM层。为了便于数据使用方调用和可视化这些数据,我们开发了一个名为’LakeHouseDataPublish’的SpringBoot项目,专门用于数据发布。该项目提供了灵活的数据源支持,包括MySQL和Clickhouse。其中,MySQL数据源用于展示离线数据,而Clickhouse数据源则专门用于展示DM层的实时数据结果。
对于此业务,我们提供了一个特定的接口:‘localhost:8989/lakehouse/dataapi/getUserLoginInfos’。启动’LakeHouseDataPublish’项目后,用户可以通过在浏览器中访问上述接口,直接查询并获取所需的数据结果。"

1.8.5数据可视化
首先启动内网穿透工具映射本地数据发布接口,打开腾讯云图https://console.cloud.tencent.com/tcv,新建大屏,添加接口及对应数据,设计组织以下大屏结果:
1.8.6实时任务执行流程
目前暂时将项目在本地执行,执行顺序如下:
1)准备环境
这里默认HDFS、Hive、HBase、Kafka环境已经准备,启动maxwell组件监控mysql业务库数据:
#在Kafka中创建好对应的kafka topic(已创建的topic,可忽略,避免重复创建)
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DB-BUSSINESS-DATA --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-ODS-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DIM-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-USER-LOGIN-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWS-USER-LOGIN-WIDE-TOPIC --partitions 3 --replication-factor 3
#启动maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties
#在Hive中创建好需要的Iceberg各层的表
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
CREATE TABLE ODS_MEMBER_INFO (
id string,
user_id string,
member_growth_score string,
member_level string,
balance string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_MEMBER_ADDRESS (
id string,
user_id string,
province string,
city string,
area string,
address string,
log string,
lat string,
phone_number string,
consignee_name string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_ADDRESS/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE DWD_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE DWS_USER_LOGIN (
user_id string,
ip string,
gmt_create string,
login_tm string,
logout_tm string,
member_level string,
province string,
city string,
area string,
address string,
member_points string,
balance string,
member_growth_score string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWS_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
#启动Clickhouse
[root@node1 ~]# service clickhouse-server start
#在Clickhouse中创建好对应表
create table dm_user_login_info(
dt String,
province String,
city String,
user_id String,
login_tm String,
gmt_create String
) engine = MergeTree() order by dt;
2)启动Flink代码
依次启动如下Flink代码:”ProduceKafkaDBDataToODS.scala”、“DimDataToHBase.scala”、“ProduceKafkaODSDataToDWD.scala”、“ProduceUserLogInToDWS.scala”、“ProcessUserLoginInfoToDM.scala”代码。各个代码中Kafka Connector属性“scan.startup.mode”设置为“latest-offset”,从最新位置消费数据。
注意:代码执行时可以设置使用内存参数:-Xmx300m -Xms300m
3)启动数据采集接口代码
启动项目“LakeHouseDataPublish”发布数据。
4)启动模拟数据代码
启动项目“LakeHouseMockData”中模拟向数据库中生产数据代码“RTMockDBData.java”。
启动类打包成 jar 后 配置启动路径:
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>xx.xx.xx</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
在 xx.xx.xx中替换指定的 启动类。
1.9实时业务:实时统计商品及一级种类、二级种类访问排行
1.9.1业务需求
用户登录系统后会浏览商品,浏览日志通过日志采集接口采集到Kafka “KAFKA-USER-LOG-DATA”topic中,每个用户浏览商品的日志信息中都有浏览的商品编号以及当前商品所属的二级分类信息,我们需要根据用户在网站上浏览的日志信息实时统计出商品浏览排行、商品一级种类、二级种类访问排行,并在大屏展示,展示效果如下:
1.9.2业务分层设计及流程图
在本次业务中,我们处理的数据分为两大类。第一类数据来源于MySQL业务库,包括商品分类表“pc_product_category”和商品基本信息表“pc_product”。这些业务表数据将被采集至大数据平台,并利用数据湖技术Iceberg构建湖仓一体的数据仓库分层架构。在数仓中,这两张表充当维度数据的角色。在湖仓分层的设计阶段,我们决定将维度数据存储于HBase,以利用其高效的随机读写能力,而将事实数据存储在Iceberg数仓分层中。对于维度数据的处理,我们已经编写了通用的代码“DimDataToHBase.scala”。只需在MySQL配置表“lakehousedb.dim_tbl_config_info”中正确配置对应的维度表信息,即可通过Maxwell实现MySQL中维度数据的增量或全量分流,并将其导入到Kafka的维度主题“KAFKA-DIM-TOPIC”中。随后,这些维度数据将通过我们编写的通用处理代码写入HBase。
第二类数据是用户浏览商品的日志数据,这部分数据已在1.5章节中通过日志采集接口被采集至Kafka主题“KAFKA-USER-LOG-DATA”。针对这个主题中的数据,我们将采用Flink进行处理。Flink代码的主要任务是保留业务库中所有数据的完整副本,并将其存储在Iceberg的ODS层中。同时,对于维度数据,我们将进行筛选并存储在Kafka中,以便于后续的维度数据处理。为了确保代码重启后能够从正确的位置继续消费数据,我们同样将所有事实数据存储在Kafka中。后续的数据处理层也将遵循这一逻辑进行操作。这样的设计既保证了数据的连续性,也提高了处理流程的健壮性。
本实时业务湖仓分层设计如下图所示: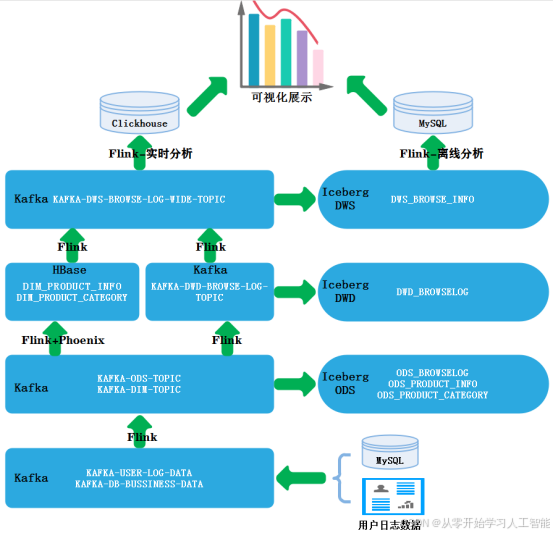
1.9.3业务实现
1.9.3编写写入ODS层业务代码
由于本业务涉及到MySQL业务数据和用户日志数据,两类数据是分别采集存储在不同的Kafka Topic中的,所以这里写入ODS层代码由两个代码组成。
1.9.3.1.1代码编写
处理MySQL业务库binlog数据的代码复用第一个业务代码只需要在”ProduceKafkaDBDataToODS.scala” 代码中写入存入Icebeg-ODS层表的代码即可,“ProduceKafkaDBDataToODS.scala”代码文件中加入代码如下:
```scala
//向Iceberg ods 层 ODS_PRODUCT_CATEGORY 表插入数据
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_PRODUCT_CATEGORY
|select
| data['id'] as id ,
| data['p_id'] as p_id,
| data['name'] as name,
| data['pic_url'] as pic_url,
| data['gmt_create'] as gmt_create
| from kafka_db_bussiness_tbl where `table` = 'pc_product_category'
""".stripMargin)
//向Iceberg ods 层 ODS_PRODUCT_INFO 表插入数据
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_PRODUCT_INFO
|select
| data['product_id'] as product_id ,
| data['category_id'] as category_id,
| data['product_name'] as product_name,
| data['gmt_create'] as gmt_create
| from kafka_db_bussiness_tbl where `table` = 'pc_product'
""".stripMargin)
处理用户日志的代码需要自己编写,代码中的业务逻辑主要是读取存储用户浏览日志数据topic “KAFKA-USER-LOG-DATA”中的数据,通过Flink代码处理将不同类型用户日志处理成json类型数据,将该json结果后续除了存储在Iceberg-ODS层对应的表之外还要将数据存储在Kafka topic “KAFKA-ODS-TOPIC” 中方便后续的业务处理。具体代码参照“ProduceKafkaLogDataToODS.scala”,主要代码逻辑如下:
```scala
object ProduceKafkaLogDataToODS {
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
private val kafkaOdsTopic: String = ConfigUtil.KAFKA_ODS_TOPIC
private val kafkaDwdBrowseLogTopic: String = ConfigUtil.KAFKA_DWD_BROWSELOG_TOPIC
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 1.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* {
* "logtype": "browselog",
* "data": {
* "browseProductCode": "eSHd1sFat9",
* "browseProductTpCode": "242",
* "userIp": "251.100.236.37",
* "obtainPoints": 32,
* "userId": "uid208600",
* "frontProductUrl": "https://f/dcjp/nVnE",
* "logTime": 1646980514321,
* "browseProductUrl": "https://kI/DXSNBeP/"
* }
* }
*/
/**
* 2.创建 Kafka Connector,连接消费Kafka中数据
* 注意:1).关键字要使用 " 飘"符号引起来 2).对于json对象使用 map < String,String>来接收
*/
tblEnv.executeSql(
"""
|create table kafka_log_data_tbl(
| logtype string,
| data map<string,string>
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-USER-LOG-DATA',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.将不同的业务库数据存入各自的Iceberg表
*/
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_BROWSELOG
|select
| data['logTime'] as log_time ,
| data['userId'] as user_id,
| data['userIp'] as user_ip,
| data['frontProductUrl'] as front_product_url,
| data['browseProductUrl'] as browse_product_url,
| data['browseProductTpCode'] as browse_product_tpcode,
| data['browseProductCode'] as browse_product_code,
| data['obtainPoints'] as obtain_points
| from kafka_log_data_tbl where `logtype` = 'browselog'
""".stripMargin)
//4.将用户所有日志数据组装成Json数据存入 kafka topic ODS-TOPIC 中
//读取 Kafka 中的数据,将维度数据另外存储到 Kafka 中
val kafkaLogTbl: Table = tblEnv.sqlQuery("select logtype,data from kafka_log_data_tbl")
//将 kafkaLogTbl Table 转换成 DataStream 数据
val userLogDS: DataStream[Row] = tblEnv.toAppendStream[Row](kafkaLogTbl)
//将 userLogDS 数据转换成JSON 数据写出到 kafka topic ODS-TOPIC
val odsSinkDS: DataStream[String] = userLogDS.map(row => {
//最后返回给Kafka 日志数据的json对象
val returnJsonObj = new JSONObject()
val logType: String = row.getField(0).toString
val data: String = row.getField(1).toString
val nObject = new JSONObject()
val arr: Array[String] = data.stripPrefix("{").stripSuffix("}").split(",")
for (elem <- arr) {
//有些数据 “data”中属性没有值,就没有“=”
if (elem.contains("=") && elem.split("=").length == 2) {
val split: Array[String] = elem.split("=")
nObject.put(split(0).trim, split(1).trim)
} else {
nObject.put(elem.stripSuffix("=").trim, "")
}
}
if ("browselog".equals(logType)) {
returnJsonObj.put("iceberg_ods_tbl_name", "ODS_BROWSELOG")
returnJsonObj.put("kafka_dwd_topic",kafkaDwdBrowseLogTopic)
returnJsonObj.put("data",nObject.toString)
} else {
//其他日志,这里目前没有
}
returnJsonObj.toJSONString
})
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
odsSinkDS.addSink(new FlinkKafkaProducer[String](kafkaOdsTopic,new KafkaSerializationSchema[String] {
override def serialize(element: String, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte],Array[Byte]](kafkaOdsTopic,null,element.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))
env.execute()
}
}
1.9.3.1.2创建Iceberg-ODS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg表有“ODS_PRODUCT_CATEGORY”、“ODS_PRODUCT_INFO”,创建语句如下:
CREATE TABLE ODS_PRODUCT_CATEGORY (
id string,
p_id string,
name string,
pic_url string,
gmt_create string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_PRODUCT_CATEGORY/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_PRODUCT_INFO (
product_id string,
category_id string,
product_name string,
gmt_create string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_PRODUCT_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_BROWSELOG (
log_time string,
user_id string,
user_ip string,
front_product_url string,
browse_product_url string,
browse_product_tpcode string,
browse_product_code string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_BROWSELOG/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
以上语句在Hive客户端执行完成之后,在HDFS中可以看到对应的Iceberg数据目录:
1.9.3.1.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-USER-LOG-DATA topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-USER-LOG-DATA --partitions 3 --replication-factor 3
#在Kafka 中创建 KAFKA-ODS-TOPIC topic(第一个业务已创建可忽略)
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-ODS-TOPIC --partitions 3 --replication-factor 3
#在Kafka 中创建 KAFKA-DIM-TOPIC topic(第一个业务已创建可忽略)
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DIM-TOPIC --partitions 3 --replication-factor 3
#监控以上两个topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-ODS-TOPIC
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DIM-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
针对用户日志数据可以启动代码“RTMockUserLogData.java”,实时向日志采集接口写入数据。
3)启动日志采集接口,启动Flume监控
如果上个步骤中设置从“earliest-offset”消费kafka数据,可以暂时不启动日志采集接口和Flume
#在node5节点上启动日志采集接口
[root@node5 ~]# cd /software/
[root@node5 software]# java -jar logcollector-0.0.1-SNAPSHOT.jar
#在node5节点上启动Flume
[root@node5 software]# flume-ng agent --name a -f /software/a.properties -Dflume.root.logger=INFO,console
4)执行代码,查看对应topic中的结果
以上代码执行后在,在对应的Kafka “KAFKA-DIM-TOPIC”和“KAFKA-ODS-TOPIC”中都有对应的数据。在Iceberg-ODS层中对应的表中也有数据。
5)执行模拟生产用户日志代码,查看对应topic中的结果
执行模拟产生用户日志数据代码:RTMockUserLogData.java,观察对应的Kafak “KAFKA-ODS-TOPIC”中有实时数据被采集。
1.9.3.2编写写入DIM层业务代码
1.9.3.2.1代码编写
DIM层业务代码与第一个业务处理Kafka topic “KAFKA-DIM-TOPIC” 数据到HBase代码完全一直,所以这里直接复用第一个业务中的DIM层业务代码“DimDataToHBase.scala”即可。
1.9.3.2.1.2代码测试
执行代码“DimDataToHBase.scala”之前首先需要启动HDFS、HBase,代码中设置读取Kafka数据从头开始读取,然后执行代码,代码执行完成后可以进入phoenix中查看对应的结果:
# 在node4节点上启动phoenix
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
[root@node4 bin]# ./sqlline.py
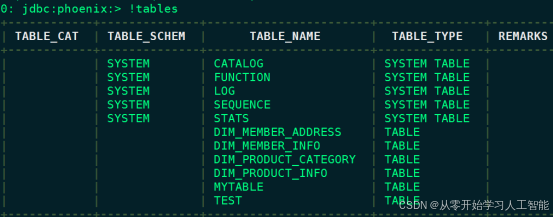
1.9.3.3编写写入DWD层业务代码
1.9.3.3.1代码编写
Flink读取Kafka topic “KAFKA-ODS-TOPIC” 数据写入Iceberg-DWD层也是复用第一个业务代码,这里只需要在代码中加入写入Iceberg-DWD层代码即可,代码如下:
//插入 iceberg - dwd 层 会员浏览商品日志信息 :DWD_BROWSELOG
tblEnv.executeSql(
s"""
|insert into hadoop_iceberg.icebergdb.DWD_BROWSELOG
|select
| log_time,
| user_id2,
| user_ip,
| front_product_url,
| browse_product_url,
| browse_product_tpcode,
| browse_product_code,
| obtain_points
| from ${table} where iceberg_ods_tbl_name = 'ODS_BROWSELOG'
""".stripMargin)
另外,在Flink处理此topic中每条数据时都有获取对应写入后续Kafka topic信息,本业务对应的每条用户日志数据写入的kafka topic为“KAFKA-DWD-BROWSE-LOG-TOPIC”,所以代码可以复用。
1.9.3.3.2创建Iceberg-DWD层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg-DWD表有“DWD_BROWSELOG”,创建语句如下:
CREATE TABLE DWD_BROWSELOG (
log_time string,
user_id string,
user_ip string,
front_product_url string,
browse_product_url string,
browse_product_tpcode string,
browse_product_code string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_BROWSELOG/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
1.9.3.3.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWD-BROWSE-LOG-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-BROWSE-LOG-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWD-BROWSE-LOG-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动向日志采集接口模拟生产日志代码“RTMockUserLogData.java”,需要启动日志采集接口及Flume。
3)执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWD-BROWSE-LOG-TOPIC” topic中都有对应的数据。在Iceberg-DWD层中对应的表中也有数据。
Kafka中结果如下:
Iceberg-DWD层表”DWD_BROWSELOG”中的数据如下:
1.9.3.4 编写写入DWS层业务代码
"DWS层专门用于存储综合了多维度信息的大宽表数据。在本业务场景中,我们专注于处理来自Kafka主题’KAFKA-DWD-BROWSE-LOG-TOPIC’的用户浏览商品日志数据,并将其与HBase中的’ODS_PRODUCT_CATEGORY’商品分类表和’ODS_PRODUCT_INFO’商品信息表进行关联,以构建出浏览商品行为的主题大宽表。
为了提升数据处理的效率,我们在Flink处理流程中集成了Redis作为缓存层,这显著加快了用户浏览数据与HBase维度数据的关联速度。完成宽表构建后,我们将数据同步至Iceberg-DWS层,同时,为了支持后续的实时统计和分析需求,我们也把宽表数据的输出结果发布到Kafka,确保了数据流的连续性和实时性。
1.9.3.4.1代码编写
具体代码参照“ProduceBrowseLogToDWS.scala”,大体代码逻辑如下:
object ProduceBrowseLogToDWS {
private val hbaseDimProductCategoryTbl: String = ConfigUtil.HBASE_DIM_PRODUCT_CATEGORY
private val hbaseDimProductInfoTbl: String = ConfigUtil.HBASE_DIM_PRODUCT_INFO
private val kafkaDwsBrowseLogWideTopic: String = ConfigUtil.KAFKA_DWS_BROWSE_LOG_WIDE_TOPIC
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 1.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 2.创建 Kafka Connector,连接消费Kafka dwd中数据
* {
* "browseProductCode": "BviQsxHtxC",
* "browseProductTpCode": "282",
* "userIp": "5.189.85.33",
* "obtainPoints": "38",
* "userId": "uid250775",
* "frontProductUrl": "https:///swdOX/ruh",
* "kafka_dwd_topic": "KAFKA-DWD-BROWSE-LOG-TOPIC",
* "logTime": "1647067452241",
* "browseProductUrl": "https:///57/zB4oF"
* }
*/
tblEnv.executeSql(
"""
|create table kafka_dwd_browse_log_tbl (
| logTime string,
| userId string,
| userIp string,
| frontProductUrl string,
| browseProductUrl string,
| browseProductTpCode string,
| browseProductCode string,
| obtainPoints string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DWD-BROWSE-LOG-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
val browseLogTbl:Table = tblEnv.sqlQuery(
"""
| select logTime,userId,userIp,frontProductUrl,browseProductUrl,browseProductTpCode,browseProductCode,obtainPoints from kafka_dwd_browse_log_tbl
""".stripMargin)
//3.将Row 类型数据转换成对象类型操作,方便与维度数据进行关联
val browseLogDS: DataStream[BrowseLog] = tblEnv.toAppendStream[Row](browseLogTbl).map(row=>{
val logTime: String = row.getField(0).toString//浏览日志时间
val userId: String = row.getField(1).toString//用户编号
val userIp: String = row.getField(2).toString//浏览IP地址
val frontProductUrl: String = row.getField(3).toString//跳转前URL地址,有为null,有的不为null
val browseProductUrl: String = row.getField(4).toString//浏览商品URL
val browseProductTpCode: String = row.getField(5).toString//浏览商品二级分类
val browseProductCode: String = row.getField(6).toString//浏览商品编号
val obtainPointsstring: String = row.getField(7).toString//浏览商品所获积分
BrowseLog(logTime,userId,userIp,frontProductUrl,browseProductUrl,browseProductTpCode,browseProductCode,obtainPointsstring)
})
//4.设置Sink 到Kafka 数据输出到侧输出流标记
val kafkaDataTag = new OutputTag[JSONObject]("kafka_data")
//5.连接phoenix 库查询HBase数据组织Browse宽表
val browseLogWideInfoDS: DataStream[BrowseLogWideInfo] = browseLogDS.process(new ProcessFunction[BrowseLog,BrowseLogWideInfo] {
var conn: Connection = _
var pst: PreparedStatement = _
var rs: ResultSet = _
//创建Phoenix 连接
override def open(parameters: Configuration): Unit = {
//连接Phoenix
println(s"连接Phoenix ... ...")
conn = DriverManager.getConnection(ConfigUtil.PHOENIX_URL)
}
override def processElement(browseLog: BrowseLog, context: ProcessFunction[BrowseLog, BrowseLogWideInfo]#Context, collector: Collector[BrowseLogWideInfo]): Unit ={
//最终返回的json 对象
val jsonObj = new JSONObject()
jsonObj.put("log_time", browseLog.logTime)
jsonObj.put("user_id", browseLog.userId)
jsonObj.put("user_ip", browseLog.userIp)
jsonObj.put("front_product_url", browseLog.frontProductUrl)
jsonObj.put("browse_product_url", browseLog.browseProductUrl)
jsonObj.put("browse_product_tpcode", browseLog.browseProductTpCode) //商品类型id
jsonObj.put("browse_product_code", browseLog.browseProductCode)//商品id
jsonObj.put("obtain_points", browseLog.obtainPoints)
//根据浏览商品类型id : browse_product_tpcode 从Redis缓存中读取 DIM_PRODUCT_CATEGORY - 商品类别表
val productCategoryRedisCacheInfo: String = MyRedisUtil.getInfoFromRedisCache(hbaseDimProductCategoryTbl, browseLog.browseProductTpCode)
//根据浏览商品id : browse_product_code 从Redis缓存中读取 DIM_PRODUCT_INFO - 商品基本信息表
val productInfoRedisCacheInfo: String = MyRedisUtil.getInfoFromRedisCache(hbaseDimProductInfoTbl, browseLog.browseProductCode)
//商品种类数据如果 Redis 缓存中没有则读取phoenix获取,有则直接从缓存中获取
if (MyStringUtil.isEmpty(productCategoryRedisCacheInfo)) {
//说明缓存中没有数据,从phoenix中查询
println("连接Phoenix查询 DIM_PRODUCT_CATEGORY - 商品类别表 维度数据")
val sql =
s"""
|SELECT
| b.id as first_category_id,
| b.name AS first_category_name,
| a.id as second_category_id,
| a.name AS second_category_name
|FROM DIM_PRODUCT_CATEGORY a JOIN DIM_PRODUCT_CATEGORY b ON a.p_id = b.id where a.id = '${browseLog.browseProductTpCode}'
""".stripMargin
println("phoenix 执行SQL 如下: "+sql)
pst = conn.prepareStatement(sql)
rs = pst.executeQuery()
//准备 向Redis 中写入 DIM_PRODUCT_CATEGORY - 商品类别表 的json对象
val dimProductCategroyRedisJsonObj = new JSONObject()
while (rs.next()) {
dimProductCategroyRedisJsonObj.put("first_category_id", rs.getString("first_category_id"))
dimProductCategroyRedisJsonObj.put("first_category_name", rs.getString("first_category_name"))
dimProductCategroyRedisJsonObj.put("second_category_id", rs.getString("second_category_id"))
dimProductCategroyRedisJsonObj.put("second_category_name", rs.getString("second_category_name"))
//将商品种类信息存入Redis缓存,向Redis中设置数据缓存
MyRedisUtil.setRedisDimCache(hbaseDimProductCategoryTbl, browseLog.browseProductTpCode, dimProductCategroyRedisJsonObj.toString)
//将json 加入到总返回结果的Json中
CommonUtil.AddAttributeToJson(jsonObj, dimProductCategroyRedisJsonObj)
}
}else{
//Redis中查询到了数据,从redis 中获取 json 信息设置在最终结果中
println("DIM_PRODUCT_CATEGORY - 商品类别表 从Redis中获取到缓存处理")
CommonUtil.AddAttributeToJson(jsonObj, JSON.parseObject(productCategoryRedisCacheInfo))
}
//商品信息数据如果 Redis 缓存中没有则读取phoenix获取,有则直接从缓存中获取
if (MyStringUtil.isEmpty(productInfoRedisCacheInfo)) {
//说明缓存中没有数据,从phoenix中查询
println("连接Phoenix查询 DIM_PRODUCT_INFO - 商品基本信息表 维度数据")
val sql =
s"""
|SELECT
| product_id,
| product_name
|FROM DIM_PRODUCT_INFO where product_id = '${browseLog.browseProductCode}'
""".stripMargin
println("phoenix 执行SQL 如下: "+sql)
pst = conn.prepareStatement(sql)
rs = pst.executeQuery()
//准备 向Redis 中写入 DIM_PRODUCT_INFO - 商品基本信息表 的json对象
val dimProductInfoRedisJsonObj = new JSONObject()
while (rs.next()) {
dimProductInfoRedisJsonObj.put("product_id", rs.getString("product_id"))
dimProductInfoRedisJsonObj.put("product_name", rs.getString("product_name"))
//将商品种类信息存入Redis缓存,向Redis中设置数据缓存
MyRedisUtil.setRedisDimCache(hbaseDimProductInfoTbl, browseLog.browseProductCode, dimProductInfoRedisJsonObj.toString)
//将json 加入到总返回结果的Json中
CommonUtil.AddAttributeToJson(jsonObj, dimProductInfoRedisJsonObj)
}
}else{
//Redis中查询到了数据,从redis 中获取 json 信息设置在最终结果中
println("DIM_PRODUCT_INFO - 商品基本信息表 从Redis中获取到缓存处理")
CommonUtil.AddAttributeToJson(jsonObj, JSON.parseObject(productInfoRedisCacheInfo))
}
//准备向Kafka 中存储的数据json 对象
context.output(kafkaDataTag,jsonObj)
//最终返回 jsonObj,此时jsonObj包含了所有json 信息
/**
* {
* "first_category_id": "30",
* "user_ip": "195.134.35.113",
* "obtain_points": "0",
* "product_name": "扭扭车",
* "log_time": "2022-03-17 16:22:09",
* "browse_product_tpcode": "30000",
* "front_product_url": "https://0BZ/7N/qVIap",
* "first_category_name": "玩具乐器",
* "user_id": "uid786601",
* "browse_product_code": "xA4cfipkdl",
* "product_id": "xA4cfipkdl",
* "second_category_id": "30000",
* "browse_product_url": "https://DU6S2wiT/n/l3E",
* "second_category_name": "童车童床"
* }
*/
collector.collect(BrowseLogWideInfo(jsonObj.getString("log_time").split(" ")(0),jsonObj.getString("user_id"),jsonObj.getString("user_ip"),
jsonObj.getString("product_name"),jsonObj.getString("front_product_url"),jsonObj.getString("browse_product_url"),jsonObj.getString("first_category_name"),
jsonObj.getString("second_category_name"),jsonObj.getString("obtain_points")))
}
override def close(): Unit = {
rs.close()
pst.close()
conn.close()
}
})
/**
* 6.将清洗完的数据存入Iceberg 表中
* 将宽表转换成表存储在 iceberg - DWS 层 DWS_BROWSE_INFO ,
*/
val table: Table = tblEnv.fromDataStream(browseLogWideInfoDS)
tblEnv.executeSql(
s"""
|insert into hadoop_iceberg.icebergdb.DWS_BROWSE_INFO
|select
| log_time,
| user_id,
| user_ip,
| product_name,
| front_product_url,
| browse_product_url,
| first_category_name,
| second_category_name,
| obtain_points
| from ${table}
""".stripMargin)
//7.同时将结果存储在Kafka KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC topic中
/**
* 将以上数据写入到Kafka 各自DWD 层topic中,这里不再使用SQL方式,而是直接使用DataStream代码方式 Sink 到各自的DWD层代码中
*/
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
browseLogWideInfoDS.getSideOutput(kafkaDataTag).addSink(new FlinkKafkaProducer[JSONObject](kafkaDwsBrowseLogWideTopic,new KafkaSerializationSchema[JSONObject] {
override def serialize(jsonObj: JSONObject, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord[Array[Byte], Array[Byte]](kafkaDwsBrowseLogWideTopic,null,jsonObj.toString.getBytes())
}
},props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))
env.execute()
}
}
1.9.3.4.2创建Iceberg-DWS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1)在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
2)创建Iceberg表
这里创建Iceberg-DWS表有“DWS_BROWSE_INFO”,创建语句如下:
CREATE TABLE DWS_BROWSE_INFO (
log_time string,
user_id string,
user_ip string,
product_name string,
front_product_url string,
browse_product_url string,
first_category_name string,
second_category_name string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWS_BROWSE_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
1.9.3.4.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC
2)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动向日志采集接口模拟生产日志代码“RTMockUserLogData.java”,需要启动日志采集接口及Flume。
3)执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC” topic中都有对应的数据。在Iceberg-DWS层中对应的表中也有数据。
Kafka中结果如下:
Iceberg-DWD层表”DWS_BROWSE_INFO”中的数据如下:
1.9.3.5编写写入DM层业务代码
DM层主要是报表数据,针对实时业务将DM层设置在Clickhouse中,在此业务中DM层主要存储的是通过Flink读取Kafka “KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC” topic中的数据进行设置窗口分析,每隔10s设置滚动窗口统计该窗口内访问商品及商品一级、二级分类分析结果,实时写入到Clickhouse中。
1.9.3.5.1代码编写
具体代码参照“ProcessBrowseLogInfoToDM.scala”,大体代码逻辑如下:
object ProcessBrowseLogInfoToDM {
def main(args: Array[String]): Unit = {
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.创建 Kafka Connector,连接消费Kafka dwd中数据
*
*/
tblEnv.executeSql(
"""
|create table kafka_dws_user_login_wide_tbl (
| user_id string,
| product_name string,
| first_category_name string,
| second_category_name string,
| obtain_points string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.实时统计每个用户最近10s浏览的商品次数和商品一级、二级种类次数,存入到Clickhouse
*/
val dwsTbl:Table = tblEnv.sqlQuery(
"""
| select user_id,product_name,first_category_name,second_category_name from kafka_dws_user_login_wide_tbl
""".stripMargin)
//4.将Row 类型数据转换成对象类型操作
val browseDS: DataStream[BrowseLogWideInfo] = tblEnv.toAppendStream[Row](dwsTbl)
.map(row => {
val user_id: String = row.getField(0).toString
val product_name: String = row.getField(1).toString
val first_category_name: String = row.getField(2).toString
val second_category_name: String = row.getField(3).toString
BrowseLogWideInfo(null, user_id, null, product_name, null, null, first_category_name, second_category_name, null)
})
val dwsDS: DataStream[ProductVisitInfo] = browseDS.keyBy(info => {
info.first_category_name + "-" + info.second_category_name + "-" + info.product_name
})
.timeWindow(Time.seconds(10))
.process(new ProcessWindowFunction[BrowseLogWideInfo, ProductVisitInfo, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[BrowseLogWideInfo], out: Collector[ProductVisitInfo]): Unit = {
val currentDt: String = DateUtil.getDateYYYYMMDD(context.window.getStart.toString)
val startTime: String = DateUtil.getDateYYYYMMDDHHMMSS(context.window.getStart.toString)
val endTime: String = DateUtil.getDateYYYYMMDDHHMMSS(context.window.getEnd.toString)
val arr: Array[String] = key.split("-")
val firstCatName: String = arr(0)
val secondCatName: String = arr(1)
val productName: String = arr(2)
val cnt: Int = elements.toList.size
out.collect(ProductVisitInfo(currentDt, startTime, endTime, firstCatName, secondCatName, productName, cnt))
}
})
/**
* 5.将以上结果写入到Clickhouse表 dm_product_visit_info 表中
* create table dm_product_visit_info(
* current_dt String,
* window_start String,
* window_end String,
* first_cat String,
* second_cat String,
* product String,
* product_cnt UInt32
* ) engine = MergeTree() order by current_dt
*
*/
//准备向ClickHouse中插入数据的sql
val insertIntoCkSql = "insert into dm_product_visit_info (current_dt,window_start,window_end,first_cat,second_cat,product,product_cnt) values (?,?,?,?,?,?,?)"
val ckSink: SinkFunction[ProductVisitInfo] = MyClickHouseUtil.clickhouseSink[ProductVisitInfo](insertIntoCkSql,new JdbcStatementBuilder[ProductVisitInfo] {
override def accept(pst: PreparedStatement, productVisitInfo: ProductVisitInfo): Unit = {
pst.setString(1,productVisitInfo.currentDt)
pst.setString(2,productVisitInfo.windowStart)
pst.setString(3,productVisitInfo.windowEnd)
pst.setString(4,productVisitInfo.firstCat)
pst.setString(5,productVisitInfo.secondCat)
pst.setString(6,productVisitInfo.product)
pst.setLong(7,productVisitInfo.productCnt)
}
})
//针对数据加入sink
dwsDS.addSink(ckSink)
env.execute()
}
}
1.9.3.5.2创建Clickhouse-DM层表
代码在执行之前需要在Clickhouse中创建对应的DM层商品浏览信息表dm_product_visit_info,clickhouse建表语句如下:
#node1节点启动clickhouse
[root@node1 bin]# service clickhouse-server start
#node1节点进入clickhouse
[root@node1 bin]# clickhouse-client -m
#node1节点创建clickhouse-DM层表
create table dm_product_visit_info(
current_dt String,
window_start String,
window_end String,
first_cat String,
second_cat String,
product String,
product_cnt UInt32
) engine = MergeTree() order by current_dt;
1.9.3.5.3代码测试
以上代码编写完成后,代码执行测试步骤如下:
1)将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动向日志采集接口模拟生产日志代码“RTMockUserLogData.java”,需要启动日志采集接口及Flume。
2)执行代码,查看对应结果
以上代码执行后在,在Clickhouse-DM层中表“dm_product_visit_info”中查看对应数据结果如下:
1.9.4数据发布接口
"完成Flink实时数据处理后,我们将结果数据写入Clickhouse-DM层。为了便于数据使用方快速调用和可视化这些数据,我们开发了一个名为’LakeHouseDataPublish’的SpringBoot项目,作为数据发布接口。此接口项目支持两种数据源:MySQL和Clickhouse。其中,MySQL数据源用于展示离线数据,而Clickhouse数据源则专注于提供DM层的实时结果数据。
我们为这项业务提供了几个关键的实时数据接口,包括:
- 实时获取商品一级种类访问热度排行的接口,可通过访问 ‘http://localhost:8989/lakehouse/dataapi/getFirstCatVisitInfos’ 来获取。
- 实时获取商品二级种类访问热度排行的接口,可通过访问 ‘http://localhost:8989/lakehouse/dataapi/getSecondCatVisitInfos’ 来获取。
- 实时获取商品访问热度排行的接口,可通过访问 ‘http://localhost:8989/lakehouse/dataapi/getProductVisitInfos’ 来获取。
启动’LakeHouseDataPublish’项目后,用户只需在浏览器中输入上述接口URL,即可查询并获取相应的数据结果,实现数据的即时可视化分析。"
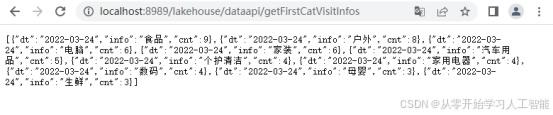


1.9.5数据可视化
首先启动内网穿透工具映射本地数据发布接口,打开腾讯云图https://console.cloud.tencent.com/tcv,新建大屏,添加接口及对应数据,设计组织以下大屏结果:
1.9.6实时任务执行流程
目前暂时将项目在本地执行,执行顺序如下:
1)准备环境
这里默认HDFS、Hive、HBase、Kafka环境已经准备,启动maxwell组件监控mysql业务库数据:
#在Kafka中创建好对应的kafka topic(已创建的topic,可忽略,避免重复创建)
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-USER-LOG-DATA --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DB-BUSSINESS-DATA --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-ODS-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DIM-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-BROWSE-LOG-TOPIC --partitions 3 --replication-factor 3
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC --partitions 3 --replication-factor 3
#启动maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin
[root@node3 bin]# maxwell --config ../config.properties
#在Hive中创建好需要的Iceberg各层的表
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
CREATE TABLE ODS_PRODUCT_CATEGORY (
id string,
p_id string,
name string,
pic_url string,
gmt_create string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_PRODUCT_CATEGORY/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_PRODUCT_INFO (
product_id string,
category_id string,
product_name string,
gmt_create string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_PRODUCT_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_BROWSELOG (
log_time string,
user_id string,
user_ip string,
front_product_url string,
browse_product_url string,
browse_product_tpcode string,
browse_product_code string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_BROWSELOG/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE DWD_BROWSELOG (
log_time string,
user_id string,
user_ip string,
front_product_url string,
browse_product_url string,
browse_product_tpcode string,
browse_product_code string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_BROWSELOG/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE DWS_BROWSE_INFO (
log_time string,
user_id string,
user_ip string,
product_name string,
front_product_url string,
browse_product_url string,
first_category_name string,
second_category_name string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWS_BROWSE_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
#启动Clickhouse
[root@node1 ~]# service clickhouse-server start
#在Clickhouse中创建好对应表
create table dm_product_visit_info(
current_dt String,
window_start String,
window_end String,
first_cat String,
second_cat String,
product String,
product_cnt UInt32
) engine = MergeTree() order by current_dt;
2)启动Flink代码
依次启动如下Flink代码:”ProduceKafkaDBDataToODS.scala”、“ProduceKafkaLogDataToODS.scala”、“DimDataToHBase.scala”、“ProduceKafkaODSDataToDWD.scala”、“ProduceBrowseLogToDWS.scala”、“ProcessBrowseLogInfoToDM.scala”代码。各个代码中Kafka Connector属性“scan.startup.mode”设置为“latest-offset”,从最新位置消费数据。
注意:代码执行时可以设置使用内存参数:-Xmx500m -Xms500m
3)启动数据采集接口代码
启动项目“LakeHouseDataPublish”发布数据。
4)启动模拟数据代码
启动项目“LakeHouseMockData”中模拟向数据库中生产数据代码“RTMockDBData.java”,此代码中只需要向MySQL生产用户登录数据即可。
启动项目“LakeHouseMockData”中向日志采集接口生产日志的代码“RTMockUserLogData.java”。
这里如果想和第一个业务一起运行还需要将第一个业务“ProduceUserLogInToDWS.scala”、“ProcessUserLoginInfoToDM.scala”两个代码。
1.10离线业务:统计每天用户商品浏览所获积分
1.10.1业务需求
使用Iceberg构建湖仓一体架构进行数据仓库分层,通过Flink操作各层数据同步到Iceberg中做到的离线与实时数据一致,当项目中有一些离线临时性的需求时,我们可以基于Iceberg各层编写SQL进行数据查询,针对Iceberg DWS层中的数据我们可以编写SQL进行离线数据指标分析。
当前离线业务根据Iceberg-DWS层中商品浏览宽表数据“DWS_BROWSE_INFO”进行查询每天每个用户商品浏览所获积分信息。
1.10.2业务流程图
这里通过Flink代码读取Iceberg-DWS层宽表数据,编写SQL进行指标分析,将分析结果存储在MySQL中,此业务流程图如下所示: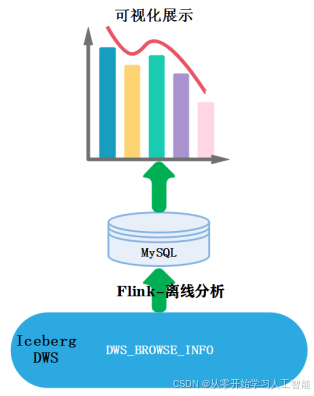
1.10.3业务实现
1.10.3.1代码编写
此业务代码详细如下:
```scala
object UserPointsAnls {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
import org.apache.flink.api.scala._
//1.创建Catalog
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
//2.使用当前Catalog
tblEnv.useCatalog("hadoop_iceberg")
//3.使用数据库
tblEnv.useDatabase("icebergdb")
val userPointTbl :Table = tblEnv.sqlQuery(
"""
| select log_time as dt,user_id,product_name,sum(cast(obtain_points as int)) as total_points from DWS_BROWSE_INFO
| group by log_time,user_id,product_name
""".stripMargin)
val userPointDS: DataStream[(Boolean, Row)] = tblEnv.toRetractStream[Row](userPointTbl)
/**
* 4.需要在MySQL resultdb 中创建表 user_points
* create database resultdb;
* create table user_points (log_time varchar(255),user_id varchar(255),product_name varchar(255),total_points bigint);
*/
val jdbcOutput: JdbcOutputFormat = JdbcOutputFormat.buildJdbcOutputFormat().setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://node2:3306/resultdb?user=root&password=123456")
.setQuery("insert into user_points values (?,?,?,?)")
.finish()
userPointDS.map(_._2).writeUsingOutputFormat(jdbcOutput)
env.execute()
}
}
#### 1.10.3.2代码执行
代码执行之前,我们需要登录MySQL创建库“resultdb”以及表user_points:
```scala
#在node2节点上执行如下命令
[root@node2 ~]# mysql -u root -p123456
mysql> create database resultdb;
mysql> use resultdb;
mysql> create table user_points(log_time varchar(255),user_id varchar(255),product_name varchar(255),total_points bigint);
创建完成之后,可以直接执行以上代码,代码执行完成之后,在mysql表“resultdb.user_points”中可以查看对应的结果: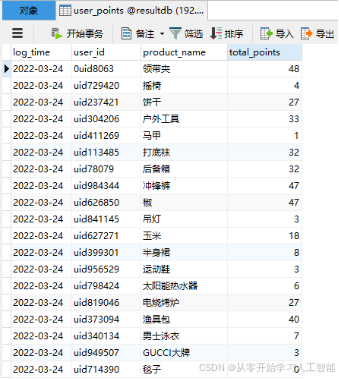
1.10.4数据发布接口
此离线业务对应的接口在数据发布接口项目“LakeHouseDataPublish”,对应的数据发布接口为:”localhost:8989/lakehouse/dataapi/getUserPoints”,启动数据发布接口,查询结果如下: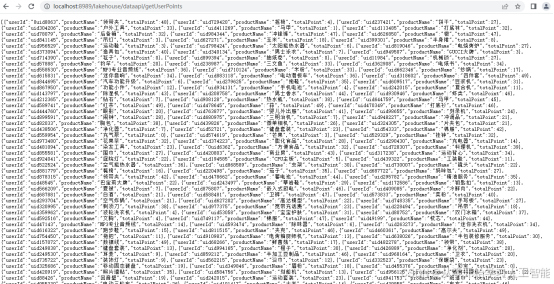
1.10.5数据可视化
首先启动内网穿透工具映射本地数据发布接口,打开腾讯云图https://console.cloud.tencent.com/tcv,新建大屏,添加接口及对应数据,设计组织以下大屏结果: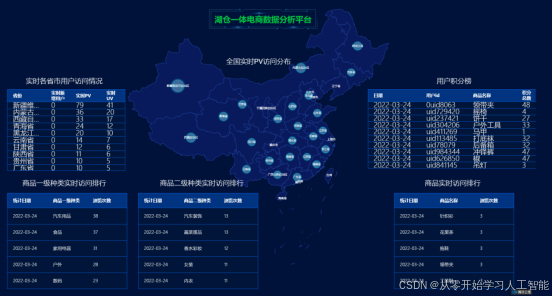
1.11合并Iceberg小文件
Iceberg表每次commit都会生成一个parquet数据文件,有可能一张Iceberg表对应的数据文件非常多,那么我们通过Java Api 方式对Iceberg表可以进行数据文件合并,数据文件合并之后,会生成新的Snapshot且原有Snap快照数据并不会被删除,如果要删除对应的数据文件需要通过“Expire Snapshots来实现”。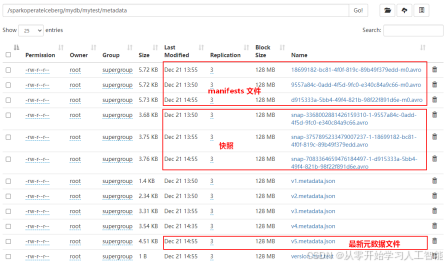
我们可以通过Java Api 删除历史快照Snap-*.avro,可以通过指定时间戳,当前时间戳之前的所有快照都会被删除,如果指定时间比最后一个快照时间还大,会保留最新快照数据。
在删除快照时,数据data目录中过期的数据parquet文件也会被删除(例如:快照回滚后不再需要的文件),到底哪些parquet文件数据被删除决定于最后的“snap-xx.avro”中对应的manifest list数据对应的parquet数据。随着不断删除snapshot,在Iceberg表不再有manifest文件对应的parquet文件也会被删除。
每次Commit生成对应的Snapshot之外,还会有一份元数据文件“vX-metadata.json”文件产生,我们可以在创建Iceberg表时执行对应的属性决定Iceberg表保留几个元数据文件,属性如下:
以下是根据您提供的属性描述创建的表格:
| Property | Description |
|---|---|
| write.metadata.delete-after-commit.enabled | 指定每次表提交后是否删除旧的元数据文件。 |
| write.metadata.previous-versions-max | 指定要保留的旧的元数据文件的数量。 |
例如,在Spark中创建表 test ,指定以上两个属性,建表语句如下:
CREATE TABLE ${CataLog名称}.${库名}.${表名} (
id bigint,
name string
) using iceberg
PARTITIONED BY (
loc string
) TBLPROPERTIES (
'write.metadata.delete-after-commit.enabled'= true,
'write.metadata.previous-versions-max' = 3
)
此项目中我们可以定期执行如下代码来删除Iceberg中过多的快照文件和数据文件,代码如下:
object CombinSnapAndRemoveOldSnap {
def main(args: Array[String]): Unit = {
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/lakehousedata")
/**
* 1.准备Iceberg表
*/
val table1: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_BROWSELOG"))
val table2: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_MEMBER_ADDRESS"))
val table3: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_MEMBER_INFO"))
val table4: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_PRODUCT_CATEGORY"))
val table5: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_PRODUCT_INFO"))
val table6: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_USER_LOGIN"))
val table7: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWD_BROWSELOG"))
val table8: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWD_USER_LOGIN"))
val table9: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWS_BROWSE_INFO"))
val table10: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWS_USER_LOGIN"))
/**
* 2.合并小文件数据,Iceberg合并小文件时并不会删除被合并的文件,Compact是将小文件合并成大文件并创建新的Snapshot。
* 如果要删除文件需要通过Expire Snapshots来实现,targetSizeInBytes 指定合并后的每个文件大小
*/
Actions.forTable(table1).rewriteDataFiles().execute()
Actions.forTable(table2).rewriteDataFiles().execute()
Actions.forTable(table3).rewriteDataFiles().execute()
Actions.forTable(table4).rewriteDataFiles().execute()
Actions.forTable(table5).rewriteDataFiles().execute()
Actions.forTable(table6).rewriteDataFiles().execute()
Actions.forTable(table7).rewriteDataFiles().execute()
Actions.forTable(table8).rewriteDataFiles().execute()
Actions.forTable(table9).rewriteDataFiles().execute()
Actions.forTable(table10).rewriteDataFiles().execute()
/**
* 3.删除历史快照,历史快照是通过ExpireSnapshot来实现的,设置需要删除多久的历史快照 snap-*.avro文件
*/
table1.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table2.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table3.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table4.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table5.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table6.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table7.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table8.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table9.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table10.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
}
}

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)