
大数据项目之电商分析平台(2)
第三章 、程序框架解析3.1、模块分析3.1.1、commons模块1. conf 包代码清单 3-1 ConfigurationManager类/*** 配置工具类*/object ConfigurationManager {// 创建用于初始化配置生成器实例的参数对象private val params = new Parameters()// F...
第三章 、程序框架解析
3.1、模块分析
3.1.1、commons模块

1. conf 包
代码清单 3-1 ConfigurationManager类
/**
* 配置工具类
*/
object ConfigurationManager {
// 创建用于初始化配置生成器实例的参数对象
private val params = new Parameters()
// FileBasedConfigurationBuilder:产生一个传入的类的实例对象
// FileBasedConfiguration:融合 FileBased 与 Configuration 的接口
// PropertiesConfiguration:从一个或者多个文件读取配置的标准配置加载器
// configure():通过 params 实例初始化配置生成器
// 向 FileBasedConfigurationBuilder()中传入一个标准配置加载器类,生成一个加载器类的实例对象,然
后通过 params 参数对其初始化
private val builder = new FileBasedConfigurationBuilder[FileBasedConfiguration](classOf
[PropertiesConfiguration])
.configure(params.properties().setFileName("commerce.properties"))
// 通过 getConfiguration 获取配置对象
val config = builder.getConfiguration()
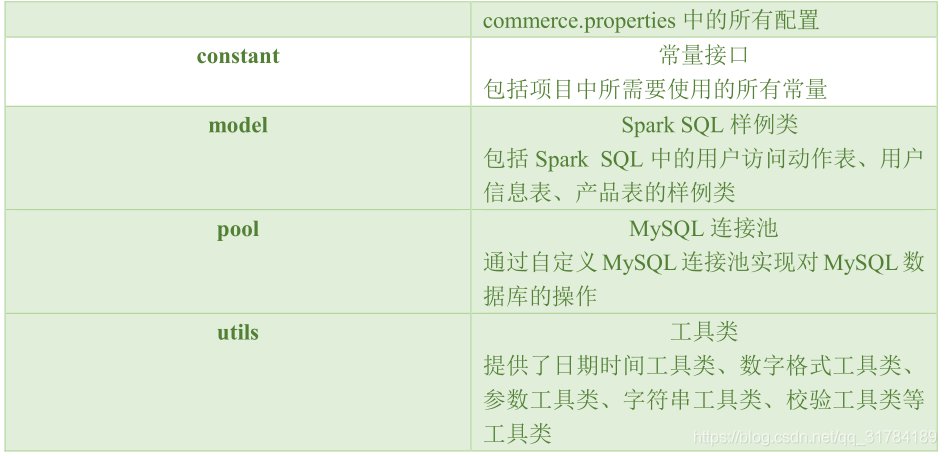
}2. constant 包
代码清单 3-2 Constants类
/**
* 常量接口
*/
object Constants {
/**
* 项目配置相关的常量
*/
val JDBC_DATASOURCE_SIZE = "jdbc.datasource.size"
val JDBC_URL = "jdbc.url"
val JDBC_USER = "jdbc.user"
val JDBC_PASSWORD = "jdbc.password"
val KAFKA_TOPICS = "kafka.topics"
/**
* Spark 作业相关的常量
*/
val SPARK_APP_NAME_SESSION = "UserVisitSessionAnalyzeSpark"
val SPARK_APP_NAME_PAGE = "PageOneStepConvertRateSpark"
val FIELD_SESSION_ID = "sessionid"
val FIELD_SEARCH_KEYWORDS = "searchKeywords"
val FIELD_CLICK_CATEGORY_IDS = "clickCategoryIds"
val FIELD_AGE = "age"
val FIELD_PROFESSIONAL = "professional"
val FIELD_CITY = "city"
val FIELD_SEX = "sex"
val FIELD_VISIT_LENGTH = "visitLength"
val FIELD_STEP_LENGTH = "stepLength"
val FIELD_START_TIME = "startTime"
val FIELD_CLICK_COUNT = "clickCount"
val FIELD_ORDER_COUNT = "orderCount"
val FIELD_PAY_COUNT = "payCount"
val FIELD_CATEGORY_ID = "categoryid"
val SESSION_COUNT = "session_count"
val TIME_PERIOD_1s_3s = "1s_3s"
val TIME_PERIOD_4s_6s = "4s_6s"
val TIME_PERIOD_7s_9s = "7s_9s"
val TIME_PERIOD_10s_30s = "10s_30s"
val TIME_PERIOD_30s_60s = "30s_60s"
val TIME_PERIOD_1m_3m = "1m_3m"
val TIME_PERIOD_3m_10m = "3m_10m"
val TIME_PERIOD_10m_30m = "10m_30m"
val TIME_PERIOD_30m = "30m"
val STEP_PERIOD_1_3 = "1_3"
val STEP_PERIOD_4_6 = "4_6"
val STEP_PERIOD_7_9 = "7_9"
val STEP_PERIOD_10_30 = "10_30"
val STEP_PERIOD_30_60 = "30_60"
val STEP_PERIOD_60 = "60"
/**
* 任务相关的常量
*/
val TASK_PARAMS = "task.params.json"
val PARAM_START_DATE = "startDate"
val PARAM_END_DATE = "endDate"
val PARAM_START_AGE = "startAge"
val PARAM_END_AGE = "endAge"
val PARAM_PROFESSIONALS = "professionals"
val PARAM_CITIES = "cities"
val PARAM_SEX = "sex"
val PARAM_KEYWORDS = "keywords"
val PARAM_CATEGORY_IDS = "categoryIds"
val PARAM_TARGET_PAGE_FLOW = "targetPageFlow"
}3. model 包
代码清单 3-3 DateModel类
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)
/**
* 用户信息表
*
* @param user_id 用户的 ID
* @param username 用户的名称
* @param name 用户的名字
* @param age 用户的年龄
* @param professional 用户的职业
* @param city 用户所在的城市
* @param sex 用户的性别
*/
case class UserInfo(user_id: Long,
username: String,
name: String,
age: Int,
professional: String,
city: String,
sex: String
)
/**
* 产品表
*
* @param product_id 商品的 ID
* @param product_name 商品的名称
* @param extend_info 商品额外的信息
*/
case class ProductInfo(product_id: Long,
product_name: String,
extend_info: String
)4. utils 包
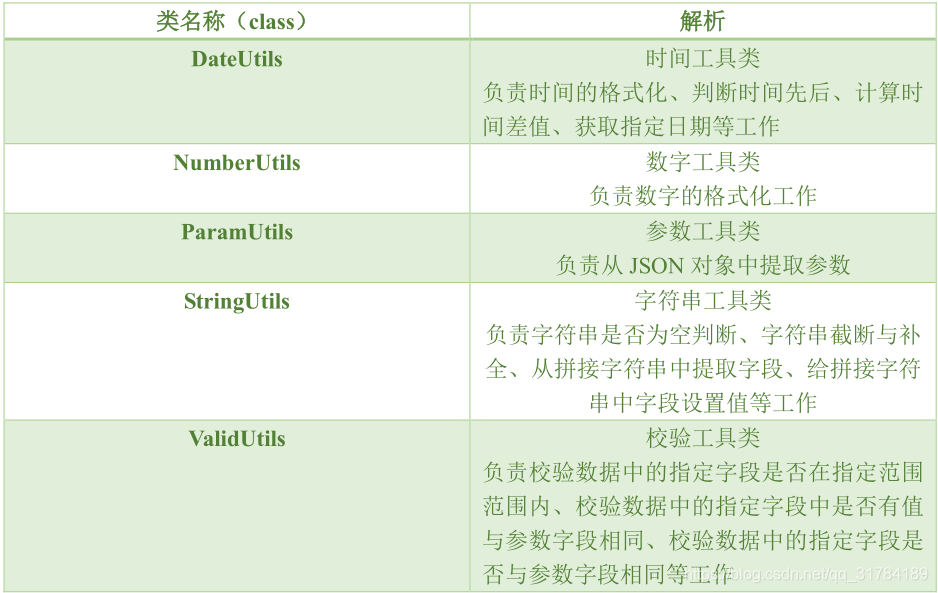
表 3-2 utils包
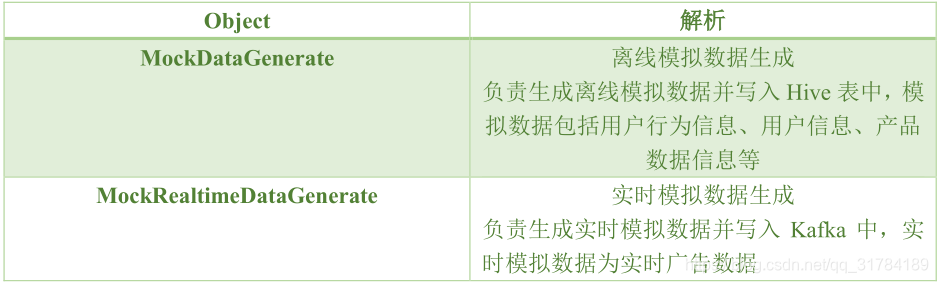
3.1.2 mock 模块
mock 模块负责产生模拟数据。
3.1.3 analyse 模块
analyse 模块是需求的具体实现模块,我们将会在下一章中进行详细解析。
第四章 需求分析
4.1 需求一 :Session 各范围 访问步长、访问时长 占比统计
4.1.1 需求
需求一要统计出符合筛选条件的 session 中,访问时长在 1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m 以上各个范围内的 session占比;访问步长在 1~3、4~6、7~9、10~30、30~60、60 以上各个范围内的 session占比,并将结果保存到 MySQL 数据库中。
在计算之前需要根据查询条件筛选 session,查询条件比如搜索过某些关键词的用户、访问时间在某个时间段内的用户、年龄在某个范围内的用户、职业在某个范围内的用户、所在某个城市的用户,发起的 session。找到对应的这些用户的 session,并进行统计,之所以需要有筛选主要是可以让使用者,对感兴趣的和关系的用户群体,进行后续各种复杂业务逻辑的统计和分析,那么拿到的结果数据,就是只是针对特殊用户群体的分析结果;而不是对所有用户进行分析的泛泛的分析结果。比如说,现在某个企业高层,就是想看到用户群体中,28~35 岁的,老师职业的群体,对应的一些统计和分析的结果数据,从而辅助高管进行公司战略上的决策制定。
session 访问时长,也就是说一个 session 对应的开始的 action,到结束的 action,之间的时间范围;还有,就是访问步长,指的是,一个 session 执行期间内,依次点击过多少个页面,比如说,一次 session,维持了 1 分钟,那么访问时长就是 1m,然后在这 1 分钟内,点击了 10 个页面,那么 session 的访问步长,就是 10.
比如说,符合第一步筛选出来的 session 的数量大概是有 1000 万个。那么里面,我们要计算出,访问时长在 1s~3s 内的session 的数量,并除以符合条件的总 session数量(比如 1000 万),比如是 100 万/1000 万,那么 1s~3s 内的 session 占比就是 10%。依次类推,这里说的统计,就是这个意思。
这个功能可以让人从全局的角度看到,符合某些条件的用户群体,使用我们的产品的一些习惯。比如大多数人,到底是会在产品中停留多长时间,大多数人,会在一次使用产品的过程中,访问多少个页面。那么对于使用者来说,有一个全局和清晰的认识。
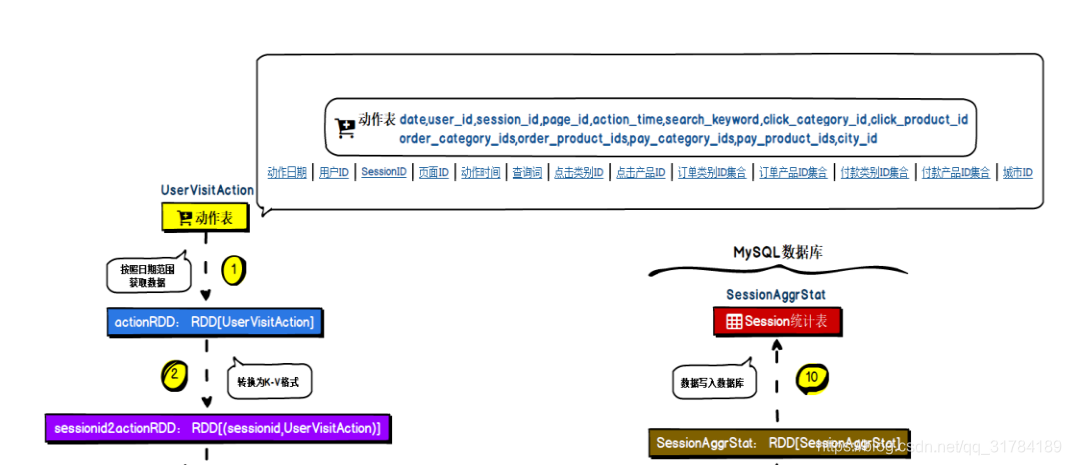
4.1.2、数据源解析

4.1.3 数据结构解析
1. UserVisitAction
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)2. AggrInfo
SessionID | 搜索关键字 | 点击品类 | 访问时长 | 访问步长|开始时间
Session_Id | Search_Keywords | Click_Category_Id | Visit_Length | Step_Length |
Start_Time|Age|Professional|Sex|City4.1.4 需求实现 流程
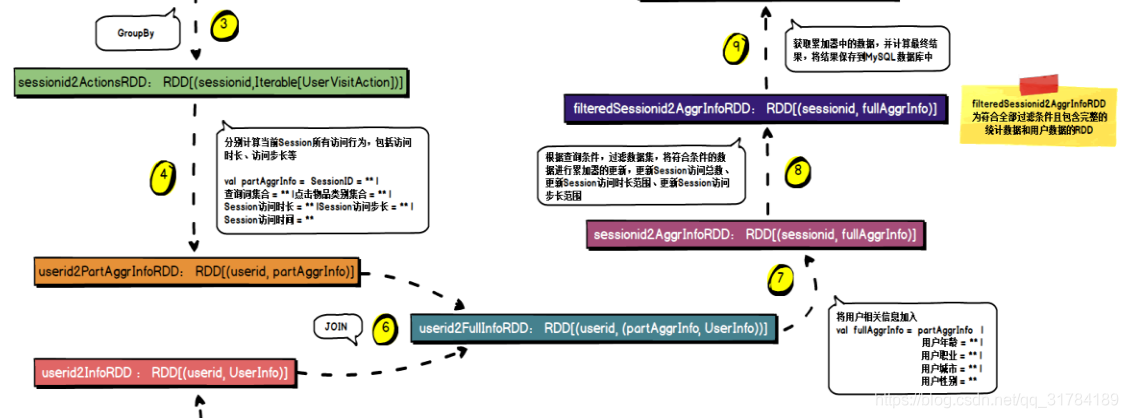

4.1.5、 MySQL 存储结构解析
-- ----------------------------
-- Table structure for `session_aggr_stat`
-- ----------------------------
DROP TABLE IF EXISTS `session_aggr_stat`;
CREATE TABLE `session_aggr_stat` (
`taskid` varchar(255) DEFAULT NULL,
`session_count` int(11) DEFAULT NULL,
`visit_length_1s_3s_ratio` double DEFAULT NULL,
`visit_length_4s_6s_ratio` double DEFAULT NULL,
`visit_length_7s_9s_ratio` double DEFAULT NULL,
`visit_length_10s_30s_ratio` double DEFAULT NULL,
`visit_length_30s_60s_ratio` double DEFAULT NULL,
`visit_length_1m_3m_ratio` double DEFAULT NULL,
`visit_length_3m_10m_ratio` double DEFAULT NULL,
`visit_length_10m_30m_ratio` double DEFAULT NULL,
`visit_length_30m_ratio` double DEFAULT NULL,
`step_length_1_3_ratio` double DEFAULT NULL,
`step_length_4_6_ratio` double DEFAULT NULL,
`step_length_7_9_ratio` double DEFAULT NULL,
`step_length_10_30_ratio` double DEFAULT NULL,
`step_length_30_60_ratio` double DEFAULT NULL,
`step_length_60_ratio` double DEFAULT NULL,
KEY `idx_task_id` (`taskid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.1.6 、代码解析
代码清单 4-1 需求一代码解析
/**
* 根据日期获取对象的用户行为数据
* @param spark
* @param taskParam
* @return
*/
def getActionRDDByDateRange(spark: SparkSession,
taskParam: JSONObject): RDD[UserVisitAction] = {
val startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
import spark.implicits._
spark.sql("select * from user_visit_action where date>='" + startDate + "' and date<='"
+ endDate + "'").as[UserVisitAction].rdd
}
/**
* 对 Session 数据进行聚合
* @param spark
* @param sessinoid2actionRDD
* @return
*/
def aggregateBySession(spark: SparkSession, sessinoid2actionRDD: RDD[(String,
UserVisitAction)]): RDD[(String, String)] = {
// 对行为数据按 session 粒度进行分组
val sessionid2ActionsRDD = sessinoid2actionRDD.groupByKey()
// 对 每 一 个 session 分 组 进 行 聚 合 , 将 session 中 所 有 的 搜 索 词 和 点 击 品 类 都 聚 合 起 来 ,
<userid,partAggrInfo(sessionid,searchKeywords,clickCategoryIds)>
val userid2PartAggrInfoRDD = sessionid2ActionsRDD.map { case (sessionid,
userVisitActions) =>
val searchKeywordsBuffer = new StringBuffer("")
val clickCategoryIdsBuffer = new StringBuffer("")
var userid = -1L
// session 的起始和结束时间
var startTime: Date = null
var endTime: Date = null
// session 的访问步长
var stepLength = 0
// 遍历 session 所有的访问行为
userVisitActions.foreach { userVisitAction =>
if (userid == -1L) {
userid = userVisitAction.user_id
}
val searchKeyword = userVisitAction.search_keyword
val clickCategoryId = userVisitAction.click_category_id
// 实际上这里要对数据说明一下
// 并不是每一行访问行为都有 searchKeyword 何 clickCategoryId 两个字段的
// 其实,只有搜索行为,是有 searchKeyword 字段的
// 只有点击品类的行为,是有 clickCategoryId 字段的
// 所以,任何一行行为数据,都不可能两个字段都有,所以数据是可能出现 null 值的
// 我们决定是否将搜索词或点击品类 id 拼接到字符串中去
// 首先要满足:不能是 null 值
// 其次,之前的字符串中还没有搜索词或者点击品类 id
if (StringUtils.isNotEmpty(searchKeyword)) {
if (!searchKeywordsBuffer.toString.contains(searchKeyword)) {
searchKeywordsBuffer.append(searchKeyword + ",")
}
}
if (clickCategoryId != null && clickCategoryId != -1L) {
if (!clickCategoryIdsBuffer.toString.contains(clickCategoryId.toString)) {
clickCategoryIdsBuffer.append(clickCategoryId + ",")
}
}
// 计算 session 开始和结束时间
val actionTime = DateUtils.parseTime(userVisitAction.action_time)
if (startTime == null) {
startTime = actionTime
}
if (endTime == null) {
endTime = actionTime
}
if (actionTime.before(startTime)) {
startTime = actionTime
}
if (actionTime.after(endTime)) {
endTime = actionTime
}
// 计算 session 访问步长
stepLength += 1
}
val searchKeywords = StringUtils.trimComma(searchKeywordsBuffer.toString)
val clickCategoryIds = StringUtils.trimComma(clickCategoryIdsBuffer.toString)
// 计算 session 访问时长(秒)
val visitLength = (endTime.getTime() - startTime.getTime()) / 1000
// 聚合数据,使用 key=value|key=value
val partAggrInfo = Constants.FIELD_SESSION_ID + "=" + sessionid + "|" +
var stepLength = 0
// 遍历 session 所有的访问行为
userVisitActions.foreach { userVisitAction =>
if (userid == -1L) {
userid = userVisitAction.user_id
}
val searchKeyword = userVisitAction.search_keyword
val clickCategoryId = userVisitAction.click_category_id
// 实际上这里要对数据说明一下
// 并不是每一行访问行为都有 searchKeyword 何 clickCategoryId 两个字段的
// 其实,只有搜索行为,是有 searchKeyword 字段的
// 只有点击品类的行为,是有 clickCategoryId 字段的
// 所以,任何一行行为数据,都不可能两个字段都有,所以数据是可能出现 null 值的
// 我们决定是否将搜索词或点击品类 id 拼接到字符串中去
// 首先要满足:不能是 null 值
// 其次,之前的字符串中还没有搜索词或者点击品类 id
if (StringUtils.isNotEmpty(searchKeyword)) {
if (!searchKeywordsBuffer.toString.contains(searchKeyword)) {
searchKeywordsBuffer.append(searchKeyword + ",")
}
}
if (clickCategoryId != null && clickCategoryId != -1L) {
if (!clickCategoryIdsBuffer.toString.contains(clickCategoryId.toString)) {
clickCategoryIdsBuffer.append(clickCategoryId + ",")
}
}
// 计算 session 开始和结束时间
val actionTime = DateUtils.parseTime(userVisitAction.action_time)
if (startTime == null) {
startTime = actionTime
}
if (endTime == null) {
endTime = actionTime
}
if (actionTime.before(startTime)) {
startTime = actionTime
}
if (actionTime.after(endTime)) {
endTime = actionTime
}
// 计算 session 访问步长
stepLength += 1
}
val searchKeywords = StringUtils.trimComma(searchKeywordsBuffer.toString)
val clickCategoryIds = StringUtils.trimComma(clickCategoryIdsBuffer.toString)
// 计算 session 访问时长(秒)
val visitLength = (endTime.getTime() - startTime.getTime()) / 1000
// 聚合数据,使用 key=value|key=value
val partAggrInfo = Constants.FIELD_SESSION_ID + "=" + sessionid + "|" +
(if (sex != null) Constants.PARAM_SEX + "=" + sex + "|" else "") +
(if (keywords != null) Constants.PARAM_KEYWORDS + "=" + keywords + "|" else "") +
(if (categoryIds != null) Constants.PARAM_CATEGORY_IDS + "=" + categoryIds else "")
if (_parameter.endsWith("\\|")) {
_parameter = _parameter.substring(0, _parameter.length() - 1)
}
val parameter = _parameter
// 根据筛选参数进行过滤
val filteredSessionid2AggrInfoRDD = sessionid2AggrInfoRDD.filter { case (sessionid,
aggrInfo) =>
// 接着,依次按照筛选条件进行过滤
// 按照年龄范围进行过滤(startAge、endAge)
var success = true
if (!ValidUtils.between(aggrInfo, Constants.FIELD_AGE, parameter,
Constants.PARAM_START_AGE, Constants.PARAM_END_AGE))
success = false
// 按照职业范围进行过滤(professionals)
// 互联网,IT,软件
// 互联网
if (!ValidUtils.in(aggrInfo, Constants.FIELD_PROFESSIONAL, parameter,
Constants.PARAM_PROFESSIONALS))
success = false
// 按照城市范围进行过滤(cities)
// 北京,上海,广州,深圳
// 成都
if (!ValidUtils.in(aggrInfo, Constants.FIELD_CITY, parameter,
Constants.PARAM_CITIES))
success = false
// 按照性别进行过滤
// 男/女
// 男,女
if (!ValidUtils.equal(aggrInfo, Constants.FIELD_SEX, parameter, Constants.PARAM_SEX))
success = false
// 按照搜索词进行过滤
// 我们的 session 可能搜索了 火锅,蛋糕,烧烤
// 我们的筛选条件可能是 火锅,串串香,iphone 手机
// 那么,in 这个校验方法,主要判定 session 搜索的词中,有任何一个,与筛选条件中
// 任何一个搜索词相当,即通过
if (!ValidUtils.in(aggrInfo, Constants.FIELD_SEARCH_KEYWORDS, parameter,
Constants.PARAM_KEYWORDS))
success = false
// 按照点击品类 id 进行过滤
if (!ValidUtils.in(aggrInfo, Constants.FIELD_CLICK_CATEGORY_IDS, parameter,
Constants.PARAM_CATEGORY_IDS))
success = false
// 如果符合任务搜索需求
if (success) {
sessionAggrStatAccumulator.add(Constants.SESSION_COUNT);
// 计算访问时长范围
def calculateVisitLength(visitLength: Long) {
if (visitLength >= 1 && visitLength <= 3) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_1s_3s);
} else if (visitLength >= 4 && visitLength <= 6) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_4s_6s);
} else if (visitLength >= 7 && visitLength <= 9) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_7s_9s);
} else if (visitLength >= 10 && visitLength <= 30) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_10s_30s);
} else if (visitLength > 30 && visitLength <= 60) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_30s_60s);
} else if (visitLength > 60 && visitLength <= 180) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_1m_3m);
} else if (visitLength > 180 && visitLength <= 600) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_3m_10m);
} else if (visitLength > 600 && visitLength <= 1800) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_10m_30m);
} else if (visitLength > 1800) {
sessionAggrStatAccumulator.add(Constants.TIME_PERIOD_30m);
}
}
// 计算访问步长范围
def calculateStepLength(stepLength: Long) {
if (stepLength >= 1 && stepLength <= 3) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_1_3);
} else if (stepLength >= 4 && stepLength <= 6) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_4_6);
} else if (stepLength >= 7 && stepLength <= 9) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_7_9);
} else if (stepLength >= 10 && stepLength <= 30) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_10_30);
} else if (stepLength > 30 && stepLength <= 60) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_30_60);
} else if (stepLength > 60) {
sessionAggrStatAccumulator.add(Constants.STEP_PERIOD_60);
}
}
// 计算出 session 的访问时长和访问步长的范围,并进行相应的累加
val visitLength = StringUtils.getFieldFromConcatString(aggrInfo, "\\|",
Constants.FIELD_VISIT_LENGTH).toLong
val stepLength = StringUtils.getFieldFromConcatString(aggrInfo, "\\|",
Constants.FIELD_STEP_LENGTH).toLong
calculateVisitLength(visitLength)
calculateStepLength(stepLength)
}
success
}
filteredSessionid2AggrInfoRDD
}
/**
* 获取通过筛选条件的 session 的访问明细数据 RDD
*
* @param sessionid2aggrInfoRDD
* @param sessionid2actionRDD
* @return
*/
def getSessionid2detailRDD(sessionid2aggrInfoRDD: RDD[(String, String)],
sessionid2actionRDD: RDD[(String, UserVisitAction)]): RDD[(String, UserVisitAction)] = {
sessionid2aggrInfoRDD.join(sessionid2actionRDD).map(item => (item._1, item._2._2))
}
/**
* 计算各 session 范围占比,并写入 MySQL
* @param value
*/
def calculateAndPersistAggrStat(spark: SparkSession, value: mutable.HashMap[String, Int],
taskUUID: String) {
// 从 Accumulator 统计串中获取值
val session_count = value(Constants.SESSION_COUNT).toDouble
val visit_length_1s_3s = value.getOrElse(Constants.TIME_PERIOD_1s_3s, 0)
val visit_length_4s_6s = value.getOrElse(Constants.TIME_PERIOD_4s_6s, 0)
val visit_length_7s_9s = value.getOrElse(Constants.TIME_PERIOD_7s_9s, 0)
val visit_length_10s_30s = value.getOrElse(Constants.TIME_PERIOD_10s_30s, 0)
val visit_length_30s_60s = value.getOrElse(Constants.TIME_PERIOD_30s_60s, 0)
val visit_length_1m_3m = value.getOrElse(Constants.TIME_PERIOD_1m_3m, 0)
val visit_length_3m_10m = value.getOrElse(Constants.TIME_PERIOD_3m_10m, 0)
val visit_length_10m_30m = value.getOrElse(Constants.TIME_PERIOD_10m_30m, 0)
val visit_length_30m = value.getOrElse(Constants.TIME_PERIOD_30m, 0)
val step_length_1_3 = value.getOrElse(Constants.STEP_PERIOD_1_3, 0)
val step_length_4_6 = value.getOrElse(Constants.STEP_PERIOD_4_6, 0)
val step_length_7_9 = value.getOrElse(Constants.STEP_PERIOD_7_9, 0)
val step_length_10_30 = value.getOrElse(Constants.STEP_PERIOD_10_30, 0)
val step_length_30_60 = value.getOrElse(Constants.STEP_PERIOD_30_60, 0)
val step_length_60 = value.getOrElse(Constants.STEP_PERIOD_60, 0)
// 计算各个访问时长和访问步长的范围
val visit_length_1s_3s_ratio = NumberUtils.formatDouble(visit_length_1s_3s / session_count, 2)
val visit_length_4s_6s_ratio = NumberUtils.formatDouble(visit_length_4s_6s / session_count, 2)
val visit_length_7s_9s_ratio = NumberUtils.formatDouble(visit_length_7s_9s / session_count, 2)
val visit_length_10s_30s_ratio = NumberUtils.formatDouble(visit_length_10s_30s / session_count, 2)
val visit_length_30s_60s_ratio = NumberUtils.formatDouble(visit_length_30s_60s / session_count, 2)
val visit_length_1m_3m_ratio = NumberUtils.formatDouble(visit_length_1m_3m / session_count, 2)
val visit_length_3m_10m_ratio = NumberUtils.formatDouble(visit_length_3m_10m / session_count, 2)
val visit_length_10m_30m_ratio = NumberUtils.formatDouble(visit_length_10m_30m / session_count, 2)
val visit_length_30m_ratio = NumberUtils.formatDouble(visit_length_30m / session_count,2)
val step_length_1_3_ratio = NumberUtils.formatDouble(step_length_1_3 / session_count,2)
val step_length_4_6_ratio = NumberUtils.formatDouble(step_length_4_6 / session_count,2)
val step_length_7_9_ratio = NumberUtils.formatDouble(step_length_7_9 / session_count,2)
val step_length_10_30_ratio = NumberUtils.formatDouble(step_length_10_30 / session_count, 2)
val step_length_30_60_ratio = NumberUtils.formatDouble(step_length_30_60 / session_count, 2)
val step_length_60_ratio = NumberUtils.formatDouble(step_length_60 / session_count, 2)
// 将统计结果封装为 Domain 对象
val sessionAggrStat = SessionAggrStat(taskUUID,
session_count.toInt, visit_length_1s_3s_ratio, visit_length_4s_6s_ratio,
visit_length_7s_9s_ratio,
visit_length_10s_30s_ratio, visit_length_30s_60s_ratio, visit_length_1m_3m_ratio,
visit_length_3m_10m_ratio, visit_length_10m_30m_ratio, visit_length_30m_ratio,
step_length_1_3_ratio, step_length_4_6_ratio, step_length_7_9_ratio,
step_length_10_30_ratio, step_length_30_60_ratio, step_length_60_ratio)
import spark.implicits._
val sessionAggrStatRDD = spark.sparkContext.makeRDD(Array(sessionAggrStat))
sessionAggrStatRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "session_aggr_stat")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}代码清单 4-2 SessionAggrStat类
/**
* 聚合统计表
*
* @param taskid 当前计算批次的 ID
* @param session_count 所有 Session 的总和
* @param visit_length_1s_3s_ratio 1-3sSession 访问时长占比
* @param visit_length_4s_6s_ratio 4-6sSession 访问时长占比
* @param visit_length_7s_9s_ratio 7-9sSession 访问时长占比
* @param visit_length_10s_30s_ratio 10-30sSession 访问时长占比
* @param visit_length_30s_60s_ratio 30-60sSession 访问时长占比
* @param visit_length_1m_3m_ratio 1-3mSession 访问时长占比
* @param visit_length_3m_10m_ratio 3-10mSession 访问时长占比
* @param visit_length_10m_30m_ratio 10-30mSession 访问时长占比
* @param visit_length_30m_ratio 30mSession 访问时长占比
* @param step_length_1_3_ratio 1-3 步长占比
* @param step_length_4_6_ratio 4-6 步长占比
* @param step_length_7_9_ratio 7-9 步长占比
* @param step_length_10_30_ratio 10-30 步长占比
* @param step_length_30_60_ratio 30-60 步长占比
* @param step_length_60_ratio 大于 60 步长占比
*/
case class SessionAggrStat(taskid: String,
session_count: Long,
visit_length_1s_3s_ratio: Double,
visit_length_4s_6s_ratio: Double,
visit_length_7s_9s_ratio: Double,
visit_length_10s_30s_ratio: Double,
visit_length_30s_60s_ratio: Double,
visit_length_1m_3m_ratio: Double,
visit_length_3m_10m_ratio: Double,
visit_length_10m_30m_ratio: Double,
visit_length_30m_ratio: Double,
step_length_1_3_ratio: Double,
step_length_4_6_ratio: Double,
step_length_7_9_ratio: Double,
step_length_10_30_ratio: Double,
step_length_30_60_ratio: Double,
step_length_60_ratio: Double
)4.2 需求 二 :Session 随机抽取
4.2.1 需求解析
在符合条件的 session 中,按照时间比例随机抽取 1000 个 session
这个按照时间比例是什么意思呢?随机抽取本身是很简单的,但是按照时间比例,就很复杂了。比如说,这一天总共有 1000 万的 session。那么我现在总共要从这 1000 万 session 中,随机抽取出来 1000 个 session。但是这个随机不是那么简单的。需要做到如下几点要求:首先,如果这一天的 12:00~13:00 的 session 数量是 100万,那么这个小时的 session 占比就是 1/10,那么这个小时中的 100 万的 session,我们就要抽取 1/10 * 1000 = 100 个。然后再从这个小时的 100 万 session 中,随机抽取出 100 个 session。以此类推,其他小时的抽取也是这样做。
这个功能的作用,是说,可以让使用者,能够对于符合条件的 session,按照时间比例均匀的随机采样出 1000 个 session,然后观察每个 session 具体的点击流/行为,比如先进入了首页、然后点击了食品品类、然后点击了雨润火腿肠商品、然后搜索了火腿肠罐头的关键词、接着对王中王火腿肠下了订单、最后对订单做了支付。
之所以要做到按时间比例随机采用抽取,就是要做到,观察样本的公平性。
抽取完毕之后,需要将 Session 的相关信息和详细信息保存到 MySQL 数据库中。
4.2.2、数据源解析
本需求的数据源来自于需求一中获取的的 Session 聚合数据(AggrInfo)和Session 用户访问数据(UserVisitAction)。
4.2.3 、数据结构解析
1. UserVisitAction
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)2. AggrInfo
SessionID | 搜索关键字 | 点击品类 | 访问时长 | 访问步长|开始时间
Session_Id | Search_Keywords | Click_Category_Id | Visit_Length | Step_Length | Start_Time4.2.4 、需求实现流程
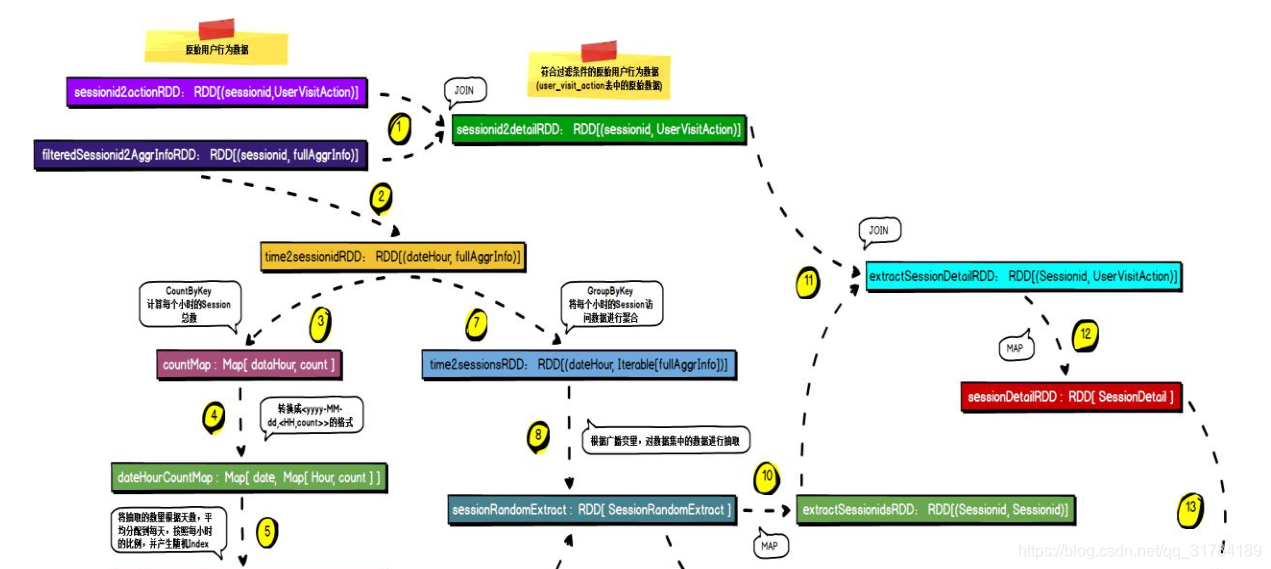

4.2.5 、MySQL存储结构解析
-- ----------------------------
-- Table structure for `session_detail`
-- ----------------------------
DROP TABLE IF EXISTS `session_detail`;
CREATE TABLE `session_detail` (
`taskid` varchar(255) DEFAULT NULL,
`userid` int(11) DEFAULT NULL,
`sessionid` varchar(255) DEFAULT NULL,
`pageid` int(11) DEFAULT NULL,
`actionTime` varchar(255) DEFAULT NULL,
`searchKeyword` varchar(255) DEFAULT NULL,
`clickCategoryId` int(11) DEFAULT NULL,
`clickProductId` int(11) DEFAULT NULL,
`orderCategoryIds` varchar(255) DEFAULT NULL,
`orderProductIds` varchar(255) DEFAULT NULL,
`payCategoryIds` varchar(255) DEFAULT NULL,
`payProductIds` varchar(255) DEFAULT NULL,
KEY `idx_task_id` (`taskid`),
KEY `idx_session_id` (`sessionid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for `session_random_extract`
-- ----------------------------
DROP TABLE IF EXISTS `session_random_extract`;
CREATE TABLE `session_random_extract` (
`taskid` varchar(255) DEFAULT NULL,
`sessionid` varchar(255) DEFAULT NULL,
`startTime` varchar(50) DEFAULT NULL,
`searchKeywords` varchar(255) DEFAULT NULL,
`clickCategoryIds` varchar(255) DEFAULT NULL,
KEY `idx_task_id` (`taskid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.2.6 、代码分析
代码清单 4-3 需求二代码解析
/**
* 业务需求二:随机抽取 session
* @param sessionid2AggrInfoRDD
*/
def randomExtractSession(spark: SparkSession, taskUUID: String, sessionid2AggrInfoRDD:
RDD[(String, String)], sessionid2actionRDD: RDD[(String, UserVisitAction)]) {
// 第一步,计算出每天每小时的 session 数量,获取<yyyy-MM-dd_HH,aggrInfo>格式的 RDD
val time2sessionidRDD = sessionid2AggrInfoRDD.map { case (sessionid, aggrInfo) =>
val startTime = StringUtils.getFieldFromConcatString(aggrInfo, "\\|", Constants.
FIELD_START_TIME)
// 将 key 改为 yyyy-MM-dd_HH 的形式(小时粒度)
val dateHour = DateUtils.getDateHour(startTime)
(dateHour, aggrInfo)
}
// 得到每天每小时的 session 数量
// countByKey()计算每个不同的 key 有多少个数据
// countMap<yyyy-MM-dd_HH, count>
val countMap = time2sessionidRDD.countByKey()
// 第 二 步 , 使 用 按 时 间 比 例 随 机 抽 取 算 法 , 计 算 出 每 天 每 小 时 要 抽 取 session 的 索 引 , 将
<yyyy-MM-dd_HH,count>格式的 map,转换成<yyyy-MM-dd,<HH,count>>的格式
// dateHourCountMap <yyyy-MM-dd,<HH,count>>
val dateHourCountMap = mutable.HashMap[String, mutable.HashMap[String, Long]]()
for ((dateHour, count) <- countMap) {
val date = dateHour.split("_")(0)
val hour = dateHour.split("_")(1)
// 通过模式匹配实现了 if 的功能
dateHourCountMap.get(date) match {
// 对应日期的数据不存在,则新增
case None => dateHourCountMap(date) = new mutable.HashMap[String, Long]();
dateHourCountMap(date) += (hour -> count)
// 对应日期的数据存在,则累加
// 如果有值,Some(hourCountMap)将值取到了 hourCountMap 中
case Some(hourCountMap) => hourCountMap += (hour -> count)
}
}
// 按时间比例随机抽取算法,总共要抽取 100 个 session,先按照天数,进行平分
// 获取每一天要抽取的数量
val extractNumberPerDay = 100 / dateHourCountMap.size
// dateHourExtractMap[天,[小时,index 列表]]
val dateHourExtractMap = mutable.HashMap[String, mutable.HashMap[String,
mutable.ListBuffer[Int]]]()
val random = new Random()
/**
* 根据每个小时应该抽取的数量,来产生随机值
* 遍历每个小时,填充 Map<date,<hour,(3,5,20,102)>>
* @param hourExtractMap 主要用来存放生成的随机值
* @param hourCountMap 每个小时的 session 总数
* @param sessionCount 当天所有的 seesion 总数
*/
def hourExtractMapFunc(hourExtractMap: mutable.HashMap[String,
mutable.ListBuffer[Int]], hourCountMap: mutable.HashMap[String, Long], sessionCount: Long)
{
for ((hour, count) <- hourCountMap) {
// 计算每个小时的 session 数量,占据当天总 session 数量的比例,直接乘以每天要抽取的数量
// 就可以计算出,当前小时需要抽取的 session 数量
var hourExtractNumber = ((count / sessionCount.toDouble) * extractNumberPerDay).toInt
if (hourExtractNumber > count) {
hourExtractNumber = count.toInt
}
// 仍然通过模式匹配实现有则追加,无则新建
hourExtractMap.get(hour) match {
case None => hourExtractMap(hour) = new mutable.ListBuffer[Int]();
// 根据数量随机生成下标
for (i <- 0 to hourExtractNumber) {
var extractIndex = random.nextInt(count.toInt);
// 一旦随机生成的 index 已经存在,重新获取,直到获取到之前没有的 index
while (hourExtractMap(hour).contains(extractIndex)) {
extractIndex = random.nextInt(count.toInt);
}
hourExtractMap(hour) += (extractIndex)
}
case Some(extractIndexList) =>
for (i <- 0 to hourExtractNumber) {
var extractIndex = random.nextInt(count.toInt);
// 一旦随机生成的 index 已经存在,重新获取,直到获取到之前没有的 index
while (hourExtractMap(hour).contains(extractIndex)) {
extractIndex = random.nextInt(count.toInt);
}
hourExtractMap(hour) += (extractIndex)
}
}
}
}
// session 随机抽取功能
for ((date, hourCountMap) <- dateHourCountMap) {
// 计算出这一天的 session 总数
val sessionCount = hourCountMap.values.sum
// dateHourExtractMap[天,[小时,小时列表]]
dateHourExtractMap.get(date) match {
case None => dateHourExtractMap(date) = new mutable.HashMap[String,
mutable.ListBuffer[Int]]();
// 更新 index
hourExtractMapFunc(dateHourExtractMap(date), hourCountMap, sessionCount)
case Some(hourExtractMap) => hourExtractMapFunc(hourExtractMap, hourCountMap,
sessionCount)
}
}
/* 至此,index 获取完毕 */
//将 Map 进行广播
val dateHourExtractMapBroadcast = spark.sparkContext.broadcast(dateHourExtractMap)
// time2sessionidRDD <yyyy-MM-dd_HH,aggrInfo>
// 执行 groupByKey 算子,得到<yyyy-MM-dd_HH,(session aggrInfo)>
val time2sessionsRDD = time2sessionidRDD.groupByKey()
// 第三步:遍历每天每小时的 session,然后根据随机索引进行抽取,我们用 flatMap 算子,遍历所有的
<dateHour,(session aggrInfo)>格式的数据
val sessionRandomExtract = time2sessionsRDD.flatMap { case (dateHour, items) =>
val date = dateHour.split("_")(0)
val hour = dateHour.split("_")(1)
// 从广播变量中提取出数据
val dateHourExtractMap = dateHourExtractMapBroadcast.value
// 获取指定天对应的指定小时的 indexList
// 当前小时需要的 index 集合
val extractIndexList = dateHourExtractMap.get(date).get(hour)
// index 是在外部进行维护
var index = 0
val sessionRandomExtractArray = new ArrayBuffer[SessionRandomExtract]()
// 开始遍历所有的 aggrInfo
for (sessionAggrInfo <- items) {
// 如果筛选 List 中包含当前的 index,则提取此 sessionAggrInfo 中的数据
if (extractIndexList.contains(index)) {
val sessionid = StringUtils.getFieldFromConcatString(sessionAggrInfo, "\\|",
Constants.FIELD_SESSION_ID)
val starttime = StringUtils.getFieldFromConcatString(sessionAggrInfo, "\\|",
Constants.FIELD_START_TIME)
val searchKeywords = StringUtils.getFieldFromConcatString(sessionAggrInfo, "\\|",
Constants.FIELD_SEARCH_KEYWORDS)
val clickCategoryIds = StringUtils.getFieldFromConcatString(sessionAggrInfo, "\\|",
Constants.FIELD_CLICK_CATEGORY_IDS)
sessionRandomExtractArray += SessionRandomExtract(taskUUID, sessionid, starttime,
searchKeywords, clickCategoryIds)
}
// index 自增
index += 1
}
sessionRandomExtractArray
}
/* 将抽取后的数据保存到 MySQL */
// 引入隐式转换,准备进行 RDD 向 Dataframe 的转换
import spark.implicits._
// 为了方便地将数据保存到 MySQL 数据库,将 RDD 数据转换为 Dataframe
sessionRandomExtract.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "session_random_extract")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
// 提取抽取出来的数据中的 sessionId
val extractSessionidsRDD = sessionRandomExtract.map(item => (item.sessionid,
item.sessionid))
// 第四步:获取抽取出来的 session 的明细数据
// 根据 sessionId 与详细数据进行聚合
val extractSessionDetailRDD = extractSessionidsRDD.join(sessionid2actionRDD)
// 对 extractSessionDetailRDD 中的数据进行聚合,提炼有价值的明细数据
val sessionDetailRDD = extractSessionDetailRDD.map { case (sid, (sessionid,
userVisitAction)) =>
SessionDetail(taskUUID, userVisitAction.user_id, userVisitAction.session_id,
userVisitAction.page_id, userVisitAction.action_time,
userVisitAction.search_keyword,
userVisitAction.click_category_id, userVisitAction.click_product_id,
userVisitAction.order_category_ids,
userVisitAction.order_product_ids, userVisitAction.pay_category_ids,
userVisitAction.pay_product_ids)
}
// 将明细数据保存到 MySQL 中
sessionDetailRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "session_detail")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}代码清单 4-4 SessionRandomExtract类
/**
* Session 随机抽取表
*
* @param taskid 当前计算批次的 ID
* @param sessionid 抽取的 Session 的 ID
* @param startTime Session 的开始时间
* @param searchKeywords Session 的查询字段
* @param clickCategoryIds Session 点击的类别 id 集合
*/
case class SessionRandomExtract(taskid:String,
sessionid:String,
startTime:String,
searchKeywords:String,
clickCategoryIds:String)代码清单 4-5 SessionDetail类
/**
* Session 随机抽取详细表
*
* @param taskid 当前计算批次的 ID
* @param userid 用户的 ID
* @param sessionid Session 的 ID
* @param pageid 某个页面的 ID
* @param actionTime 点击行为的时间点
* @param searchKeyword 用户搜索的关键词
* @param clickCategoryId 某一个商品品类的 ID
* @param clickProductId 某一个商品的 ID
* @param orderCategoryIds 一次订单中所有品类的 ID 集合
* @param orderProductIds 一次订单中所有商品的 ID 集合
* @param payCategoryIds 一次支付中所有品类的 ID 集合
* @param payProductIds 一次支付中所有商品的 ID 集合
**/
case class SessionDetail(taskid:String,
userid:Long,
sessionid:String,
pageid:Long,
actionTime:String,
searchKeyword:String,
clickCategoryId:Long,
clickProductId:Long,
orderCategoryIds:String,
orderProductIds:String,
payCategoryIds:String,
payProductIds:String)4.3 、需求三:Top10 热门品类
4.3.1、需求分析
在符合条件的 session 中,获取点击、下单和支付数量排名前 10 的品类。
数据中的每个 session 可能都会对一些品类的商品进行点击、下单和支付等等行为,那么现在就需要获取这些 session 点击、下单和支付数量排名前 10 的最热门的
品类。也就是说,要计算出所有这些 session 对各个品类的点击、下单和支付的次数,然后按照这三个属性进行排序,获取前 10 个品类。
这个功能,很重要,就可以让我们明白,就是符合条件的用户,他最感兴趣的商品是什么种类。这个可以让公司里的人,清晰地了解到不同层次、不同类型的用户的心理和喜好。
计算完成之后,将数据保存到 MySQL 数据库中。
4.3.2 、数据源解析
本 需 求 的 数 据 源 来 自 于 需 求 一 中 获 取 的 Session 用 户 访 问 数 据(UserVisitAction)。
4.3.3 、数据结构解析
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)4.3.4 、需求实现流程
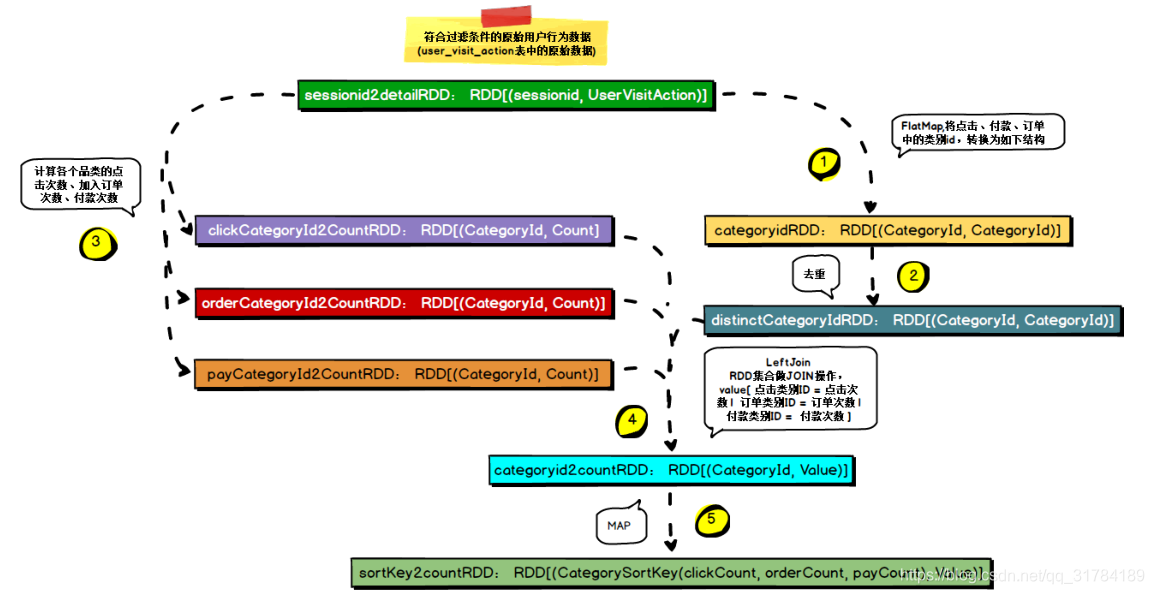
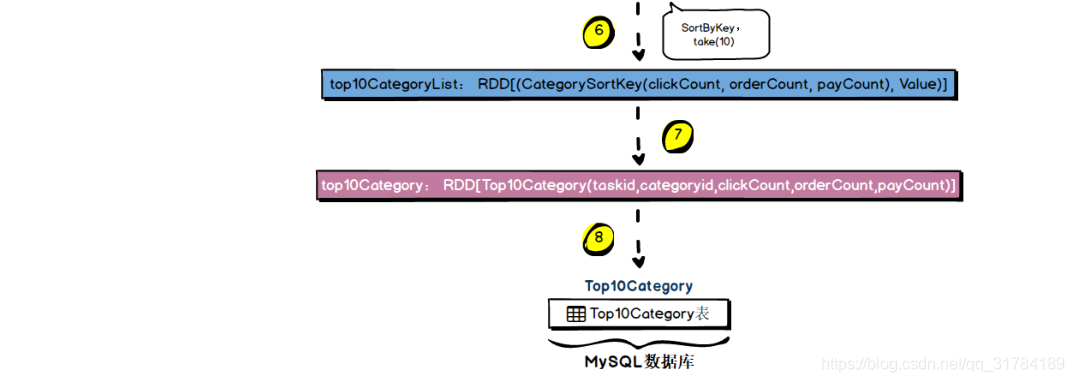
4.3.5、 MySQL 存储结构解析
-- ----------------------------
-- Table structure for `top10_category`
-- ----------------------------
DROP TABLE IF EXISTS `top10_category`;
CREATE TABLE `top10_category` (
`taskid` varchar(255) DEFAULT NULL,
`categoryid` int(11) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL,
`orderCount` int(11) DEFAULT NULL,
`payCount` int(11) DEFAULT NULL,
KEY `idx_task_id` (`taskid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.3.6 、代码解析
代码清单 4-6 需求三代码解析
/**
* 业务需求三:获取 top10 热门品类
* @param spark
* @param taskid
* @param sessionid2detailRDD
* @return
*/
def getTop10Category(spark: SparkSession, taskid: String, sessionid2detailRDD: RDD[(String,
UserVisitAction)]): Array[(CategorySortKey, String)] = {
// 第一步:获取每一个 Sessionid 点击过、下单过、支付过的数量
// 获取所有产生过点击、下单、支付中任意行为的商品类别
val categoryidRDD = sessionid2detailRDD.flatMap { case (sessionid, userVisitAction) =>
val list = ArrayBuffer[(Long, Long)]()
// 一个 session 中点击的商品 ID
if (userVisitAction.click_category_id != null) {
list += ((userVisitAction.click_category_id, userVisitAction.click_category_id))
}
// 一个 session 中下单的商品 ID 集合
if (userVisitAction.order_category_ids != null) {
for (orderCategoryId <- userVisitAction.order_category_ids.split(","))
list += ((orderCategoryId.toLong, orderCategoryId.toLong))
}
// 一个 session 中支付的商品 ID 集合
if (userVisitAction.pay_category_ids != null) {
for (payCategoryId <- userVisitAction.pay_category_ids.split(","))
list += ((payCategoryId.toLong, payCategoryId.toLong))
}
list
}
// 对重复的 categoryid 进行去重
// 得到了所有被点击、下单、支付的商品的品类
val distinctCategoryIdRDD = categoryidRDD.distinct
// 第二步:计算各品类的点击、下单和支付的次数
// 计算各个品类的点击次数
val clickCategoryId2CountRDD = getClickCategoryId2CountRDD(sessionid2detailRDD)
// 计算各个品类的下单次数
val orderCategoryId2CountRDD = getOrderCategoryId2CountRDD(sessionid2detailRDD)
// 计算各个品类的支付次数
val payCategoryId2CountRDD = getPayCategoryId2CountRDD(sessionid2detailRDD)
// 第三步:join 各品类与它的点击、下单和支付的次数
// distinctCategoryIdRDD 中是所有产生过点击、下单、支付行为的商品类别
// 通过 distinctCategoryIdRDD 与各个统计数据的 LeftJoin 保证数据的完整性
val categoryid2countRDD = joinCategoryAndData(distinctCategoryIdRDD,
clickCategoryId2CountRDD, orderCategoryId2CountRDD, payCategoryId2CountRDD);
// 第四步:自定义二次排序 key
/ 第五步:将数据映射成<CategorySortKey,info>格式的 RDD,然后进行二次排序(降序)
// 创建用于二次排序的联合 key —— (CategorySortKey(clickCount, orderCount, payCount), line)
// 按照:点击次数 -> 下单次数 -> 支付次数 这一顺序进行二次排序
val sortKey2countRDD = categoryid2countRDD.map { case (categoryid, line) =>
val clickCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_CLICK_COUNT).toLong
val orderCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_ORDER_COUNT).toLong
val payCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_PAY_COUNT).toLong
(CategorySortKey(clickCount, orderCount, payCount), line)
}
// 降序排序
val sortedCategoryCountRDD = sortKey2countRDD.sortByKey(false)
// 第六步:用 take(10)取出 top10 热门品类,并写入 MySQL
val top10CategoryList = sortedCategoryCountRDD.take(10)
val top10Category = top10CategoryList.map { case (categorySortKey, line) =>
val categoryid = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_CATEGORY_ID).toLong
val clickCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_CLICK_COUNT).toLong
val orderCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_ORDER_COUNT).toLong
val payCount = StringUtils.getFieldFromConcatString(line, "\\|",
Constants.FIELD_PAY_COUNT).toLong
Top10Category(taskid, categoryid, clickCount, orderCount, payCount)
}
// 将 Map 结构转化为 RDD
val top10CategoryRDD = spark.sparkContext.makeRDD(top10Category)
// 写入 MySQL 之前,将 RDD 转化为 Dataframe
import spark.implicits._
top10CategoryRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "top10_category")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
top10CategoryList
}
/**
* 连接品类 RDD 与数据 RDD
*
* @param categoryidRDD
* @param clickCategoryId2CountRDD
* @param orderCategoryId2CountRDD
* @param payCategoryId2CountRDD
* @return
*/
def joinCategoryAndData(categoryidRDD: RDD[(Long, Long)], clickCategoryId2CountRDD:
RDD[(Long, Long)], orderCategoryId2CountRDD: RDD[(Long, Long)], payCategoryId2CountRDD:
RDD[(Long, Long)]): RDD[(Long, String)] = {
// 将所有品类信息与点击次数信息结合【左连接】
val clickJoinRDD = categoryidRDD.leftOuterJoin(clickCategoryId2CountRDD).map { case
(categoryid, (cid, optionValue)) =>
val clickCount = if (optionValue.isDefined) optionValue.get else 0L
val value = Constants.FIELD_CATEGORY_ID + "=" + categoryid + "|" +
Constants.FIELD_CLICK_COUNT + "=" + clickCount
(categoryid, value)
}
// 将所有品类信息与订单次数信息结合【左连接】
val orderJoinRDD = clickJoinRDD.leftOuterJoin(orderCategoryId2CountRDD).map { case
(categoryid, (ovalue, optionValue)) =>
val orderCount = if (optionValue.isDefined) optionValue.get else 0L
val value = ovalue + "|" + Constants.FIELD_ORDER_COUNT + "=" + orderCount
(categoryid, value)
}
// 将所有品类信息与付款次数信息结合【左连接】
val payJoinRDD = orderJoinRDD.leftOuterJoin(payCategoryId2CountRDD).map { case
(categoryid, (ovalue, optionValue)) =>
val payCount = if (optionValue.isDefined) optionValue.get else 0L
val value = ovalue + "|" + Constants.FIELD_PAY_COUNT + "=" + payCount
(categoryid, value)
}
payJoinRDD
}
/**
* 获取各个品类的支付次数 RDD
*
* @param sessionid2detailRDD
* @return
*/
def getPayCategoryId2CountRDD(sessionid2detailRDD: RDD[(String, UserVisitAction)]):
RDD[(Long, Long)] = {
// 过滤支付数据
val payActionRDD = sessionid2detailRDD.filter { case (sessionid, userVisitAction) =>
userVisitAction.pay_category_ids != null }
// 获取每种类别的支付次数
val payCategoryIdRDD = payActionRDD.flatMap { case (sessionid, userVisitAction) =>
userVisitAction.pay_category_ids.split(",").map(item => (item.toLong, 1L)) }
// 计算各个品类的支付次数
payCategoryIdRDD.reduceByKey(_ + _)
}
/**
* 获取各品类的下单次数 RDD
*
* @param sessionid2detailRDD
* @return
*/
def getOrderCategoryId2CountRDD(sessionid2detailRDD: RDD[(String, UserVisitAction)]):
RDD[(Long, Long)] = {
// 过滤订单数据
val orderActionRDD = sessionid2detailRDD.filter { case (sessionid, userVisitAction) =>
userVisitAction.order_category_ids != null }
// 获取每种类别的下单次数
val orderCategoryIdRDD = orderActionRDD.flatMap { case (sessionid, userVisitAction) =>
userVisitAction.order_category_ids.split(",").map(item => (item.toLong, 1L)) }
// 计算各个品类的下单次数
orderCategoryIdRDD.reduceByKey(_ + _)
}
/**
* 获取各个品类的支付次数 RDD
*
* @param sessionid2detailRDD
* @return
*/
def getPayCategoryId2CountRDD(sessionid2detailRDD: RDD[(String, UserVisitAction)]):
RDD[(Long, Long)] = {
// 过滤支付数据
val payActionRDD = sessionid2detailRDD.filter { case (sessionid, userVisitAction) =>
userVisitAction.pay_category_ids != null }
// 获取每种类别的支付次数
val payCategoryIdRDD = payActionRDD.flatMap { case (sessionid, userVisitAction) =>
userVisitAction.pay_category_ids.split(",").map(item => (item.toLong, 1L)) }
// 计算各个品类的支付次数
payCategoryIdRDD.reduceByKey(_ + _)
}代码清单 4-7 CategorySortKey类
case class CategorySortKey(val clickCount: Long, val orderCount: Long, val payCount: Long)
extends Ordered[CategorySortKey] {
/** Result of comparing `this` with operand `that`.
*
* Implement this method to determine how instances of A will be sorted.
*
* Returns `x` where:
*
* - `x < 0` when `this < that`
*
* - `x == 0` when `this == that`
*
* - `x > 0` when `this > that`
*
*/
override def compare(that: CategorySortKey): Int = {
if (this.clickCount - that.clickCount != 0) {
return (this.clickCount - that.clickCount).toInt
} else if (this.orderCount - that.orderCount != 0) {
return (this.orderCount - that.orderCount).toInt
} else if (this.payCount - that.payCount != 0) {
return (this.payCount - that.payCount).toInt
}
0
}
}代码清单 4-8 Top10Category类
/**
* 品类 Top10 表
* @param taskid
* @param categoryid
* @param clickCount
* @param orderCount
* @param payCount
*/
case class Top10Category(taskid:String,
categoryid:Long,
clickCount:Long,
orderCount:Long,
payCount:Long)4.4 、需求四:Top10 热门品类 Top10 活跃 Session 统计
4.4.1 、需求解析
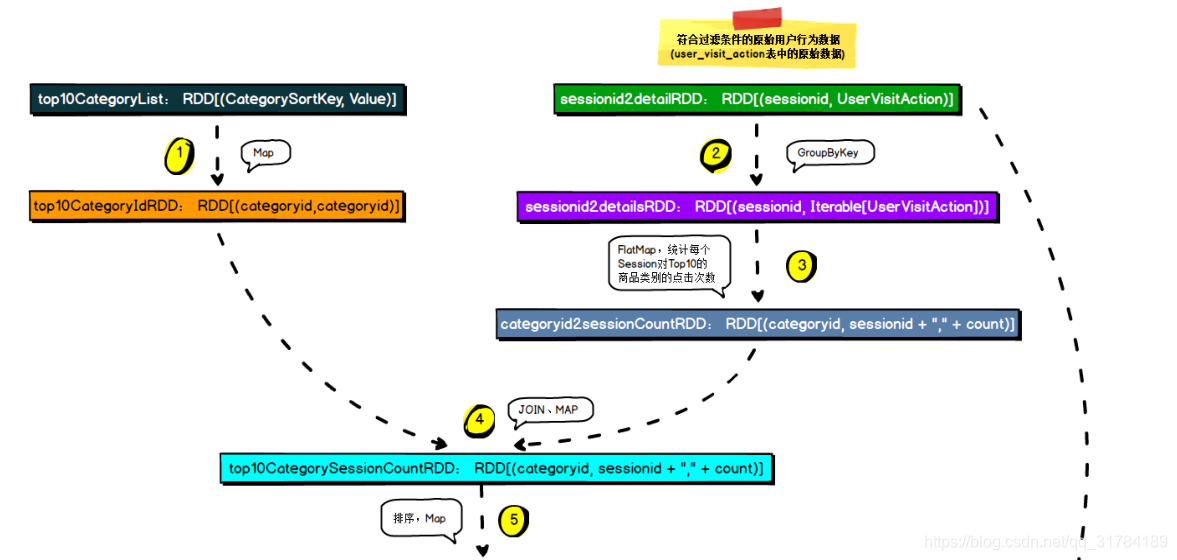
对于排名前 10 的品类,分别获取其点击次数排名前 10 的 session。
这个就是说,对于 top10 的品类,每一个都要获取对它点击次数排名前 10 的session。
这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的 session 的行为。
计算完成之后,将数据保存到 MySQL 数据库中。
4.4.2、数据源解析
本 需 求 的 数 据 源 来 自 于 需 求 一 中 获 取 的 Session 用 户 访 问 数 据(UserVisitAction)。
4.4.3、数据结构解析
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)4.4.4 、需求实现流程
4.4.5、MySQL 存储结构解析
-- ----------------------------
-- Table structure for `top10_session`
-- ----------------------------
DROP TABLE IF EXISTS `top10_session`;
CREATE TABLE `top10_session` (
`taskid` varchar(255) DEFAULT NULL,
`categoryid` int(11) DEFAULT NULL,
`sessionid` varchar(255) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL,
KEY `idx_task_id` (`taskid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.4.6、代码解析
代码清单 4-9 需求四代码解析
/**
* 业务功能四:获取 top10 热门品类的活跃 session
*
* @param taskid
*/
def getTop10Session(spark: SparkSession, taskid: String, top10CategoryList:
Array[(CategorySortKey, String)], sessionid2ActionRDD: RDD[(String, UserVisitAction)]) {
// 第一步:将 top10 热门品类的 id,生成一份 RDD
// 获得所有需要求的 category 集合
val top10CategoryIdRDD = spark.sparkContext.makeRDD(top10CategoryList.map { case
(categorySortKey, line) =>
val categoryid = StringUtils.getFieldFromConcatString(line, "\\|", Constants.FIELD_
CATEGORY_ID).toLong;
(categoryid, categoryid)
})
// 第二步:计算 top10 品类被各 session 点击的次数
// sessionid2ActionRDD 是符合过滤(职业、年龄等)条件的完整数据
// sessionid2detailRDD ( sessionId, userAction )
val sessionid2ActionsRDD = sessionid2ActionRDD.groupByKey()
// 获取每个品类被每一个 Session 点击的次数
val categoryid2sessionCountRDD = sessionid2ActionsRDD.flatMap { case (sessionid,
userVisitActions) =>
val categoryCountMap = new mutable.HashMap[Long, Long]()
// userVisitActions 中聚合了一个 session 的所有用户行为数据
// 遍历 userVisitActions 是提取 session 中的每一个用户行为,并对每一个用户行为中的点击事件进行计
数
for (userVisitAction <- userVisitActions) {
// 如果 categoryCountMap 中尚不存在此点击品类,则新增品类
if (!categoryCountMap.contains(userVisitAction.click_category_id))
categoryCountMap.put(userVisitAction.click_category_id, 0)
// 如果 categoryCountMap 中已经存在此点击品类,则进行累加
if (userVisitAction.click_category_id != null && userVisitAction.click_category_id !=
-1L) {
categoryCountMap.update(userVisitAction.click_category_id,
categoryCountMap(userVisitAction.click_category_id) + 1)
}
}
// 对 categoryCountMap 中的数据进行格式转化
for ((categoryid, count) <- categoryCountMap)
yield (categoryid, sessionid + "," + count)
}
// 通过 top10 热门品类 top10CategoryIdRDD 与完整品类点击统计 categoryid2sessionCountRDD 进行
join,仅获取热门品类的数据信息
// 获取到 to10 热门品类,被各个 session 点击的次数【将数据集缩小】
val top10CategorySessionCountRDD =
top10CategoryIdRDD.join(categoryid2sessionCountRDD).map { case (cid, (ccid, value)) =>
(cid, value) }
// 第三步:分组取 TopN 算法实现,获取每个品类的 top10 活跃用户
// 先按照品类分组
val top10CategorySessionCountsRDD = top10CategorySessionCountRDD.groupByKey()
// 将每一个品类的所有点击排序,取前十个,并转换为对象
val top10SessionObjectRDD = top10CategorySessionCountsRDD.flatMap { case (categoryid,
clicks) =>
// 先排序,然后取前 10
val top10Sessions = clicks.toList.sortWith(_.split(",")(1) > _.split(",")(1)).take(10)
// 重新整理数据
top10Sessions.map { case line =>
val sessionid = line.split(",")(0)
val count = line.split(",")(1).toLong
Top10Session(taskid, categoryid, sessionid, count)
}
}
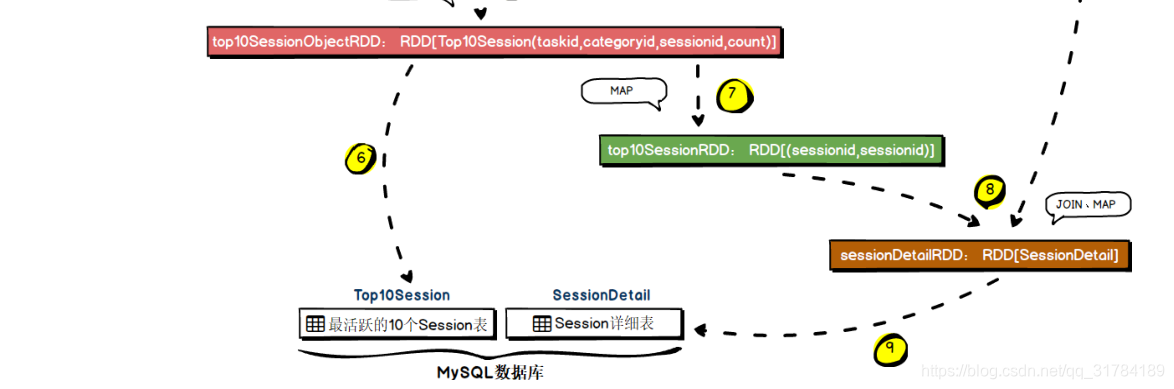
// 将结果以追加方式写入到 MySQL 中
import spark.implicits._
top10SessionObjectRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "top10_session")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
val top10SessionRDD = top10SessionObjectRDD.map(item => (item.sessionid,
item.sessionid))
// 第四步:获取 top10 活跃 session 的明细数据
val sessionDetailRDD = top10SessionRDD.join(sessionid2ActionRDD).map { case (sid,
(sessionid, userVisitAction)) =>
SessionDetail(taskid, userVisitAction.user_id, userVisitAction.session_id,
userVisitAction.page_id, userVisitAction.action_time,
userVisitAction.search_keyword,
userVisitAction.click_category_id, userVisitAction.click_product_id,
userVisitAction.order_category_ids,
userVisitAction.order_product_ids, userVisitAction.pay_category_ids,
userVisitAction.pay_product_ids)
}
// 将活跃 Session 的明细数据,写入到 MySQL
sessionDetailRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "session_detail")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}代码清单 4-10 Top10Session类
/**
* Top10 Session
* @param taskid
* @param categoryid
* @param sessionid
* @param clickCount
*/
case class Top10Session(taskid:String,
categoryid:Long,
sessionid:String,
clickCount:Long)4.5 、需求五:页面转化率统计
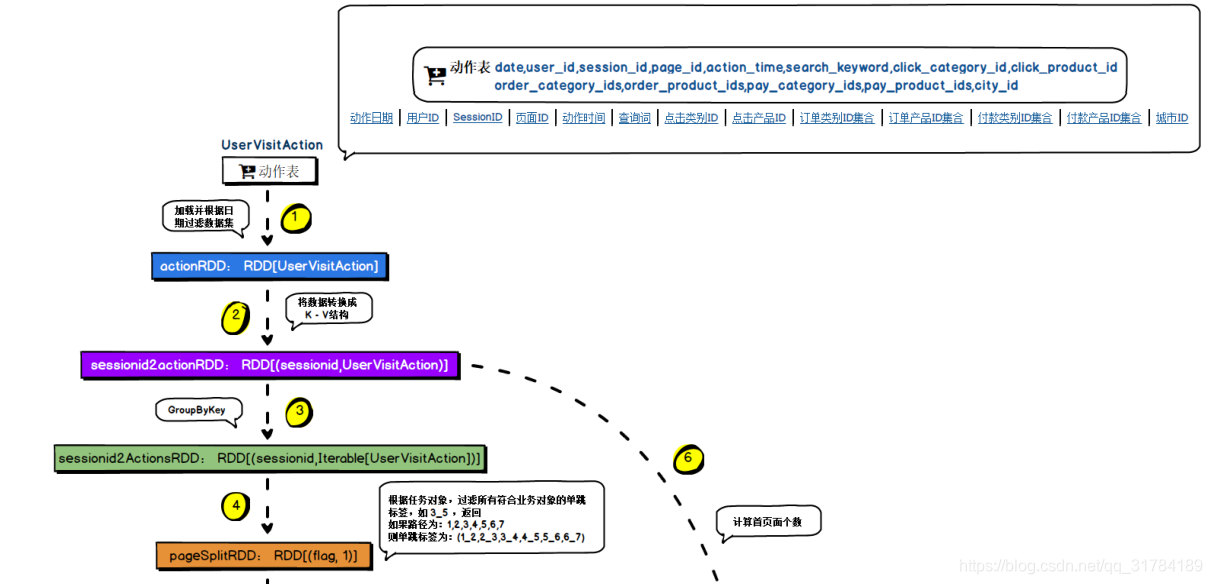
4.5.1 、需求解析
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率,比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率,我们记为 C;那么页面 5-7 的转化率怎么求呢?先需要求出符合条件的 Session 中访问页面 5 又紧接着访问了页面 7 的次数为 D,那么 D/B即为 5-7 的单跳转化率。
产品经理,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。数据分析师,可以此数据做更深一步的计算和分析。
企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。

在该模块中,需要根据查询对象中设置的 Session过滤条件,先将对应得 Session过滤出来,然后根据查询对象中设置的页面路径,计算页面单跳转化率,比如查询的页面路径为:3、5、7、8,那么就要计算 3-5、5-7、7-8 的页面单跳转化率。需要注意的一点是,页面的访问时有先后的。
4.5.2 、数据源解析

4.5.3 、数据结构解析
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的 ID
* @param session_id Session 的 ID
* @param page_id 某个页面的 ID
* @param action_time 点击行为的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的 ID
* @param click_product_id 某一个商品的 ID
* @param order_category_ids 一次订单中所有品类的 ID 集合
* @param order_product_ids 一次订单中所有商品的 ID 集合
* @param pay_category_ids 一次支付中所有品类的 ID 集合
* @param pay_product_ids 一次支付中所有商品的 ID 集合
* @param city_id 城市 ID
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long
)4.5.4 、需求实现流程
4.5.5、 MySQL 存储结构解析
-- ----------------------------
-- Table structure for `page_split_convert_rate`
-- ----------------------------
DROP TABLE IF EXISTS `page_split_convert_rate`;
CREATE TABLE `page_split_convert_rate` (
`taskid` varchar(255) DEFAULT NULL,
`convertRate` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.5.6 、代码解析
代码清单 4-11 需求五代码解析
/**
* 页面单跳转化率模块 spark 作业
*
* 页面转化率的求解思路是通过 UserAction 表获取一个 session 的所有 UserAction,根据时间顺序排序后获
取全部 PageId
* 然后将PageId组合成PageFlow,即1,2,3,4,5的形式(按照时间顺序排列),之后,组合为1_2, 2_3, 3_4, ...
的形式
* 然后筛选出出现在 targetFlow 中的所有 A_B
*
* 对每个 A_B 进行数量统计,然后统计 startPage 的 PV,之后根据 targetFlow 的 A_B 顺序,计算每一层的转
化率
*
*/
object PageOneStepConvertRate {
def main(args: Array[String]): Unit = {
// 获取统计任务参数【为了方便,直接从配置文件中获取,企业中会从一个调度平台获取】
val jsonStr = ConfigurationManager.config.getString(Constants.TASK_PARAMS)
val taskParam = JSONObject.fromObject(jsonStr)
// 任务的执行 ID,用户唯一标示运行后的结果,用在 MySQL 数据库中
val taskUUID = UUID.randomUUID().toString
// 构建 Spark 上下文
val sparkConf = new SparkConf().setAppName("SessionAnalyzer").setMaster("local[*]")
// 创建 Spark 客户端
val spark =
SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val sc = spark.sparkContext
// 查询指定日期范围内的用户访问行为数据
val actionRDD = this.getActionRDDByDateRange(spark, taskParam)
// 将用户行为信息转换为 K-V 结构
val sessionid2actionRDD = actionRDD.map(item => (item.session_id, item))
// 将数据进行内存缓存
sessionid2actionRDD.persist(StorageLevel.MEMORY_ONLY)
// 对<sessionid,访问行为> RDD,做一次 groupByKey 操作,生成页面切片
val sessionid2actionsRDD = sessionid2actionRDD.groupByKey()
// 最核心的一步,每个 session 的单跳页面切片的生成,以及页面流的匹配,算法
val pageSplitRDD = generateAndMatchPageSplit(sc, sessionid2actionsRDD, taskParam)
// 返回:(1_2, 1),(3_4, 1), ..., (100_101, 1)
// 统计每个跳转切片的总个数
// pageSplitPvMap:(1_2, 102320), (3_4, 90021), ..., (100_101, 45789)
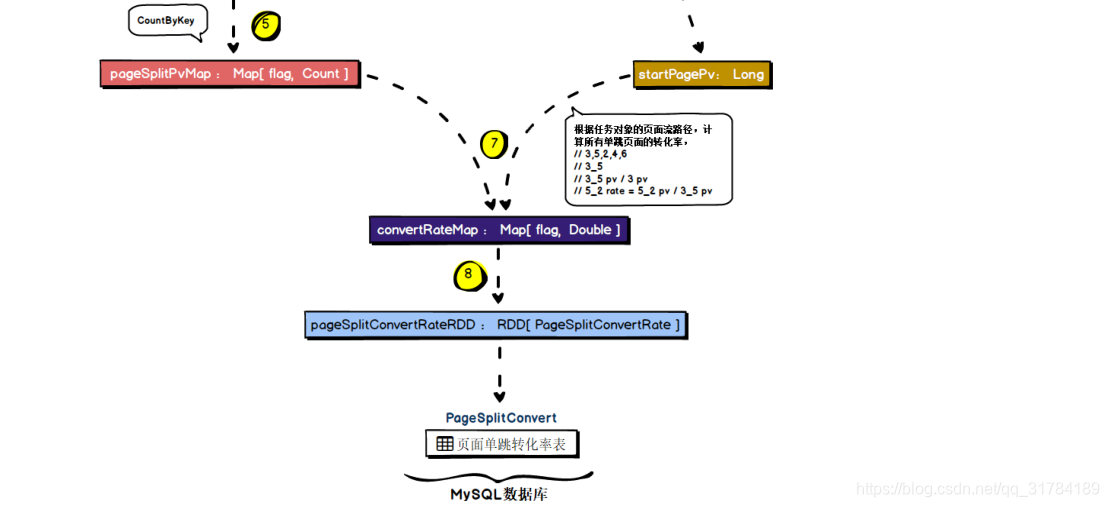
val pageSplitPvMap = pageSplitRDD.countByKey
// 使用者指定的页面流是 3,2,5,8,6
// 咱们现在拿到的这个 pageSplitPvMap,3->2,2->5,5->8,8->6
// 首先计算首页 PV 的数量
val startPagePv = getStartPagePv(taskParam, sessionid2actionsRDD)
// 计算目标页面流的各个页面切片的转化率
val convertRateMap = computePageSplitConvertRate(taskParam, pageSplitPvMap,
startPagePv)
// 持久化页面切片转化率
persistConvertRate(spark, taskUUID, convertRateMap)
spark.close()
}
/**
* 持久化转化率
* @param convertRateMap
*/
def persistConvertRate(spark:SparkSession, taskid:String,
convertRateMap:collection.Map[String, Double]) {
val convertRate = convertRateMap.map(item => item._1 + "=" + item._2).mkString("|")
val pageSplitConvertRateRDD =
spark.sparkContext.makeRDD(Array(PageSplitConvertRate(taskid,convertRate)))
import spark.implicits._
pageSplitConvertRateRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "page_split_convert_rate")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password",
ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}
/**
* 计算页面切片转化率
* @param pageSplitPvMap 页面切片 pv
* @param startPagePv 起始页面 pv
* @return
*/
def computePageSplitConvertRate(taskParam:JSONObject,
pageSplitPvMap:collection.Map[String, Long], startPagePv:Long):collection.Map[String,
Double] = {
val convertRateMap = new mutable.HashMap[String, Double]()
//1,2,3,4,5,6,7
val targetPageFlow = ParamUtils.getParam(taskParam, Constants.PARAM_TARGET_PAGE_FLOW)
val targetPages = targetPageFlow.split(",").toList
//(1_2,2_3,3_4,4_5,5_6,6_7)
val targetPagePairs = targetPages.slice(0,
targetPages.length-1).zip(targetPages.tail).map(item => item._1 + "_" + item._2)
// lastPageSplitPv:存储最新一次的页面 PV 数量
var lastPageSplitPv = startPagePv.toDouble
// 3,5,2,4,6
// 3_5
// 3_5 pv / 3 pv
// 5_2 rate = 5_2 pv / 3_5 pv
// 通过 for 循环,获取目标页面流中的各个页面切片(pv)
for(targetPage <- targetPagePairs){
// 先获取 pageSplitPvMap 中记录的当前 targetPage 的数量
val targetPageSplitPv = pageSplitPvMap.get(targetPage).get.toDouble
println((targetPageSplitPv, lastPageSplitPv))
// 用当前 targetPage 的数量除以上一次 lastPageSplit 的数量,得到转化率
val convertRate = NumberUtils.formatDouble(targetPageSplitPv / lastPageSplitPv, 2)
// 对 targetPage 和转化率进行存储
convertRateMap.put(targetPage, convertRate)
// 将本次的 targetPage 作为下一次的 lastPageSplitPv
lastPageSplitPv = targetPageSplitPv
}
convertRateMap
}
/**
* 获取页面流中初始页面的 pv
* @param taskParam
* @param sessionid2actionsRDD
* @return
*/
def getStartPagePv(taskParam:JSONObject, sessionid2actionsRDD:RDD[(String,
Iterable[UserVisitAction])]) :Long = {
// 获取配置文件中的 targetPageFlow
val targetPageFlow = ParamUtils.getParam(taskParam, Constants.PARAM_TARGET_PAGE_FLOW)
// 获取起始页面 ID
val startPageId = targetPageFlow.split(",")(0).toLong
// sessionid2actionsRDD 是聚合后的用户行为数据
// userVisitAction 中记录的是在一个页面中的用户行为数据
val startPageRDD = sessionid2actionsRDD.flatMap{ case (sessionid, userVisitActions) =>
// 过滤出所有 PageId 为 startPageId 的用户行为数据
userVisitActions.filter(_.page_id == startPageId).map(_.page_id)
}
// 对 PageId 等于 startPageId 的用户行为数据进行技术
startPageRDD.count()
}
/**
* 页面切片生成与匹配算法
* 注意,一开始我们只有 UserAciton 信息,通过将 UserAction 按照时间进行排序,然后提取 PageId,再进
行连接,可以得到 PageFlow
* @param sc
* @param sessionid2actionsRDD
* @param taskParam
* @return
*/
def generateAndMatchPageSplit(sc:SparkContext, sessionid2actionsRDD:RDD[(String,
Iterable[UserVisitAction])], taskParam:JSONObject ):RDD[(String, Int)] = {
/* 对目标 PageFlow 进行解析 */
//1,2,3,4,5,6,7
val targetPageFlow = ParamUtils.getParam(taskParam, Constants.PARAM_TARGET_PAGE_FLOW)
//将字符串转换成为了 List[String]
val targetPages = targetPageFlow.split(",").toList
//targetPages.slice(0, targetPages.length-1) :[1,2,3,4,5,6]
//targetPages.tail :[2,3,4,5,6,7]
//targetPages.slice(0, targetPages.length-1).zip(targetPages.tail) :
(1,2)(2,3)(3,4)(4,5)(5,6)(6,7)
//map(item => item._1 + "_" + item._2):(1_2,2_3,3_4,4_5,5_6,6_7)
val targetPagePairs = targetPages.slice(0,
targetPages.length-1).zip(targetPages.tail).map(item => item._1 + "_" + item._2)
//将结果转换为广播变量
//targetPagePairs 类型为 List[String]
val targetPageFlowBroadcast = sc.broadcast(targetPagePairs)
/* 对所有 PageFlow 进行解析 */
// 对全部数据进行处理
sessionid2actionsRDD.flatMap{ case (sessionid, userVisitActions) =>
// 获取使用者指定的页面流
// 使用者指定的页面流,1,2,3,4,5,6,7
// 1->2 的转化率是多少?2->3 的转化率是多少?
// 这里,我们拿到的 session 的访问行为,默认情况下是乱序的
// 比如说,正常情况下,我们希望拿到的数据,是按照时间顺序排序的
// 但是问题是,默认是不排序的
// 所以,我们第一件事情,对 session 的访问行为数据按照时间进行排序
// 举例,反例
// 比如,3->5->4->10->7
// 3->4->5->7->10
// userVisitActions 是 Iterable[UserAction],toList.sortWith 将 Iterable 中的所有
UserAction 按照时间进行排序
// 按照时间排序
val sortedUVAs = userVisitActions.toList.sortWith((uva1, uva2) =>
DateUtils.parseTime(uva1.action_time).getTime() <
DateUtils.parseTime(uva2.action_time).getTime())
// 提取所有 UserAction 中的 PageId 信息
val soredPages = sortedUVAs.map(item => if(item.page_id != null) item.page_id)
//【注意】页面的 PageFlow 是将 session 的所有 UserAction 按照时间顺序排序后提取 PageId,再将
PageId 进行连接得到的
// 按照已经排好的顺序对 PageId 信息进行整合,生成所有页面切片:(1_2,2_3,3_4,4_5,5_6,6_7)
val sessionPagePairs = soredPages.slice(0,
soredPages.length-1).zip(soredPages.tail).map(item => item._1 + "_" + item._2)
/* 由此,得到了当前 session 的 PageFlow */
// 只要是当前 session 的 PageFlow 有一个切片与 targetPageFlow 中任一切片重合,那么就保留下来
// 目标:(1_2,2_3,3_4,4_5,5_6,6_7) 当前:(1_2,2_5,5_6,6_7,7_8)
// 最后保留:(1_2,5_6,6_7)
// 输出:(1_2, 1) (5_6, 1) (6_7, 1)
sessionPagePairs.filter(targetPageFlowBroadcast.value.contains(_)).map((_,1))
}
}
def getActionRDDByDateRange(spark:SparkSession, taskParam:JSONObject):
RDD[UserVisitAction] = {
val startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
import spark.implicits._
spark.sql("select * from user_visit_action where date>='" + startDate + "' and date<='"
+ endDate + "'")
.as[UserVisitAction].rdd
}
}4.6、需求六:各区域 Top3 商品统计
4.6.1 、需求分析
根据用户指定的日期查询条件范围,统计各个区域下的最热门【点击】的 top3商品,区域信息、各个城市的信息在项目中用固定值进行配置,因为不怎么变动。
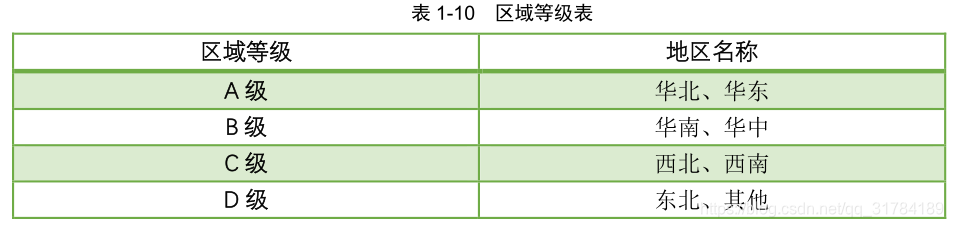
1. 查询 task,获取日期范围,通过 Spark SQL,查询 user_visit_action 表中的指定日期范围内的数据,过滤出,商品点击行为,click_product_id is not null;click_product_id != 'NULL';
click_product_id != 'null';city_id,click_product_id。
2. 使用 Spark SQL 从 MySQL 中查询出来城市信息(city_id、city_name、area),用户访问行为
数据要跟城市信息进行 join,city_id、city_name、area、product_id,RDD,转换成 DataFrame,
注册成一个临时表。
3. Spark SQL 内置函数(case when),对 area 打标记(华东大区,A 级,华中大区,B 级,东北
大区,C 级,西北大区,D 级),area_level。
4. 计算出来每个区域下每个商品的点击次数,group by area, product_id;保留每个区域的城市名
称列表;自定义 UDAF,group_concat_distinct()函数,聚合出来一个 city_names 字段,area、
product_id、city_names、click_count。
5. join 商品明细表,hive(product_id、product_name、extend_info),extend_info是 json 类
型,自定义 UDF,get_json_object()函数,取出其中的product_status 字段,if()函数(Spark
SQL 内置函数),判断,0 自营,1 第三方;(area、product_id、city_names、click_count、
product_name、product_status)。
6. 开窗函数,根据 area 来聚合,获取每个 area 下,click_count 排名前 3 的 product信息 ;
area、 area_level、 product_id、 city_names、 click_count、product_name、product_status
7. 结果写入 MySQL 表中。4.6.2 数据源解析

4.6.3、数据结构分析
Array((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"), (3L, "广州", "华南"),(4L, "三亚", "华南"), (5L, "武汉", "华中"), (6L, "长沙", "华中"), (7L, "西安", "西北"), (8L,"成都", "西南"), (9L, "哈尔滨", "东北"))4.6.4、需求实现流程
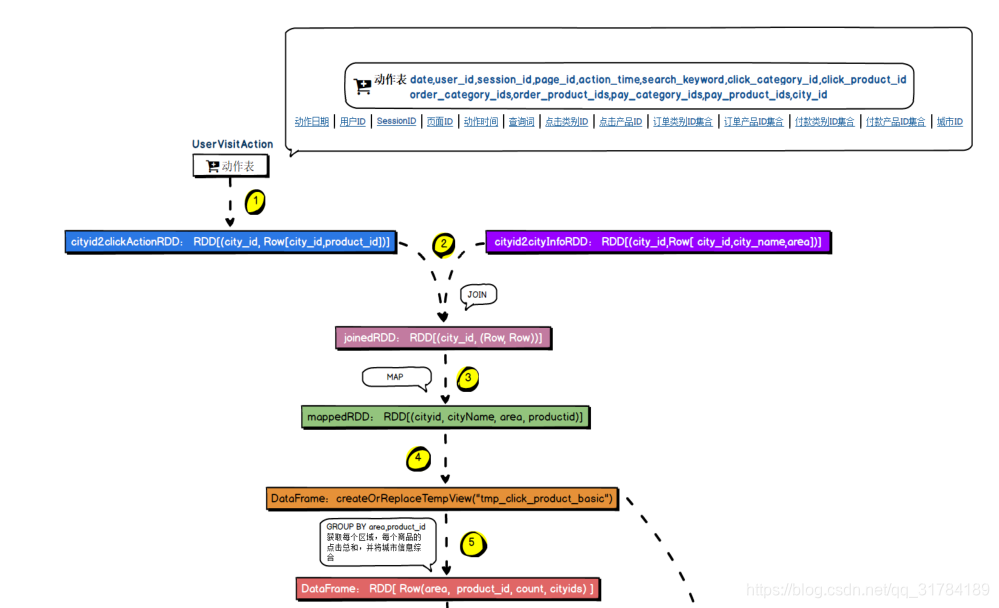
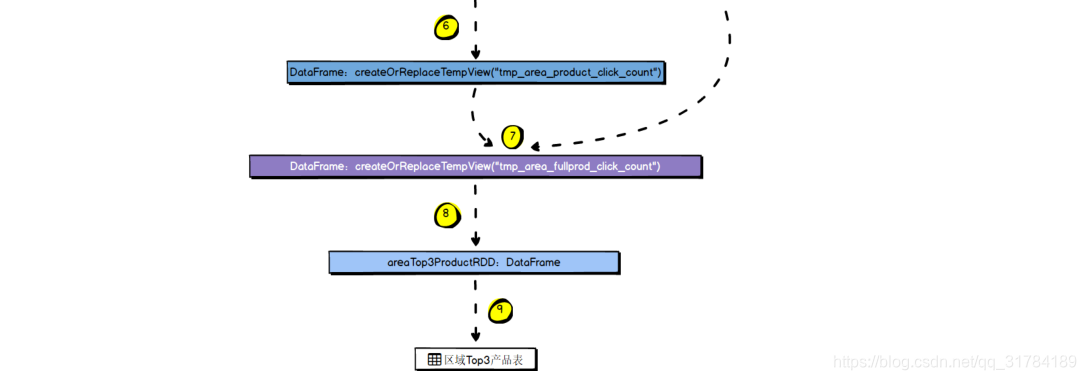
4.6.5 、MySQL 存储结构解析
-- ----------------------------
-- Table structure for `area_top3_product`
-- ----------------------------
DROP TABLE IF EXISTS `area_top3_product`;
CREATE TABLE `area_top3_product` (
`taskid` varchar(255) DEFAULT NULL,
`area` varchar(255) DEFAULT NULL,
`areaLevel` varchar(255) DEFAULT NULL,
`productid` int(11) DEFAULT NULL,
`cityInfos` varchar(255) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL,
`productName` varchar(255) DEFAULT NULL,
`productStatus` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.6.6 、代码解析
代码清单 4-12 需求六代码解析
/**
* 区域 Top3 商品统计
*/
object AreaTop3ProductApp {
def main(args: Array[String]): Unit = {
// 获取统计任务参数【为了方便,直接从配置文件中获取,企业中会从一个调度平台获取】
val jsonStr = ConfigurationManager.config.getString(Constants.TASK_PARAMS)
val taskParam = JSONObject.fromObject(jsonStr)
// 任务的执行 ID,用户唯一标示运行后的结果,用在 MySQL 数据库中
val taskUUID = UUID.randomUUID().toString
// 构建 Spark 上下文
val sparkConf = new SparkConf().setAppName("SessionAnalyzer").setMaster("local[*]")
// 创建 Spark 客户端
val spark =
SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val sc = spark.sparkContext
// 注册自定义函数
spark.udf.register("concat_long_string", (v1: Long, v2: String, split: String) =>
v1.toString + split + v2)
spark.udf.register("get_json_object", (json: String, field: String) => {
val jsonObject = JSONObject.fromObject(json);
jsonObject.getString(field)
})
spark.udf.register("group_concat_distinct", new GroupConcatDistinctUDAF())
// 获取任务日期参数
val startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
// 查询用户指定日期范围内的点击行为数据(city_id,在哪个城市发生的点击行为)
val cityid2clickActionRDD = getcityid2ClickActionRDDByDate(spark, startDate, endDate)
// 查询城市信息
// 使用(city_id , 城市信息)
val cityid2cityInfoRDD = getcityid2CityInfoRDD(spark)
// 生成点击商品基础信息临时表
// 将点击行为 cityid2clickActionRDD 和城市信息 cityid2cityInfoRDD 进行 Join 关联
// tmp_click_product_basic
generateTempClickProductBasicTable(spark, cityid2clickActionRDD, cityid2cityInfoRDD)
// 生成各区域各商品点击次数的临时表
// 对 tmp_click_product_basic 表中的数据进行 count 聚合统计,得到点击次数
// tmp_area_product_click_count
generateTempAreaPrdocutClickCountTable(spark)
// 生成包含完整商品信息的各区域各商品点击次数的临时表
// 关联tmp_area_product_click_count表与product_info表,在tmp_area_product_click_count
基础上引入商品的详细信息
generateTempAreaFullProductClickCountTable(spark)
// 需求一:使用开窗函数获取各个区域内点击次数排名前 3 的热门商品
val areaTop3ProductRDD = getAreaTop3ProductRDD(taskUUID, spark)
// 将数据转换为 DF,并保存到 MySQL 数据库
import spark.implicits._
val areaTop3ProductDF = areaTop3ProductRDD.rdd.map(row =>
AreaTop3Product(taskUUID, row.getAs[String]("area"),
row.getAs[String]("area_level"), row.getAs[Long]("product_id"),
row.getAs[String]("city_infos"), row.getAs[Long]("click_count"),
row.getAs[String]("product_name"), row.getAs[String]("product_status"))
).toDS
areaTop3ProductDF.write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "area_top3_product")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password",
ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
spark.close()
}
/**
* 需求一:获取各区域 top3 热门商品
* 使用开窗函数先进行一个子查询,按照 area 进行分组,给每个分组内的数据,按照点击次数降序排序,打上一
个组内的行号
* 接着在外层查询中,过滤出各个组内的行号排名前 3 的数据
*
* @return
*/
def getAreaTop3ProductRDD(taskid: String, spark: SparkSession): DataFrame = {
// 华北、华东、华南、华中、西北、西南、东北
// A 级:华北、华东
// B 级:华南、华中
// C 级:西北、西南
// D 级:东北
// case when
// 根据多个条件,不同的条件对应不同的值
// case when then ... when then ... else ... end
val sql = "SELECT " +
"area," +
"CASE " +
"WHEN area='China North' OR area='China East' THEN 'A Level' " +
"WHEN area='China South' OR area='China Middle' THEN 'B Level' " +
"WHEN area='West North' OR area='West South' THEN 'C Level' " +
"ELSE 'D Level' " +
"END area_level," +
"product_id," +
"city_infos," +
"click_count," +
"product_name," +
"product_status " +
"FROM (" +
"SELECT " +
"area," +
"product_id," +
"click_count," +
"city_infos," +
"product_name," +
"product_status," +
"row_number() OVER (PARTITION BY area ORDER BY click_count DESC) rank " +
"FROM tmp_area_fullprod_click_count " +
") t " +
"WHERE rank<=3"
spark.sql(sql)
}
/**
* 生成区域商品点击次数临时表(包含了商品的完整信息)
* @param spark
*/
def generateTempAreaFullProductClickCountTable(spark: SparkSession) {
// 将之前得到的各区域各商品点击次数表,product_id
// 去关联商品信息表,product_id,product_name 和 product_status
// product_status 要特殊处理,0,1,分别代表了自营和第三方的商品,放在了一个 json 串里面
// get_json_object()函数,可以从 json 串中获取指定的字段的值
// if()函数,判断,如果 product_status 是 0,那么就是自营商品;如果是 1,那么就是第三方商品
// area, product_id, click_count, city_infos, product_name, product_status
// 你拿到到了某个区域 top3 热门的商品,那么其实这个商品是自营的,还是第三方的,其实是很重要的一件事
// 技术点:内置 if 函数的使用
val sql = "SELECT " +
"tapcc.area," +
"tapcc.product_id," +
"tapcc.click_count," +
"tapcc.city_infos," +
"pi.product_name," +
"if(get_json_object(pi.extend_info,'product_status')='0','Self','Third Party')
product_status " +
"FROM tmp_area_product_click_count tapcc " +
"JOIN product_info pi ON tapcc.product_id=pi.product_id "
val df = spark.sql(sql)
df.createOrReplaceTempView("tmp_area_fullprod_click_count")
}
/**
* 生成各区域各商品点击次数临时表
* @param spark
*/
def generateTempAreaPrdocutClickCountTable(spark: SparkSession) {
// 按照 area 和 product_id 两个字段进行分组
// 计算出各区域各商品的点击次数
// 可以获取到每个 area 下的每个 product_id 的城市信息拼接起来的串
val sql = "SELECT " +
"area," +
"product_id," +
"count(*) click_count, " +
"group_concat_distinct(concat_long_string(city_id,city_name,':')) city_infos " +
"FROM tmp_click_product_basic " +
"GROUP BY area,product_id "
val df = spark.sql(sql)
// 各区域各商品的点击次数(以及额外的城市列表),再次将查询出来的数据注册为一个临时表
df.createOrReplaceTempView("tmp_area_product_click_count")
}
/**
* 生成点击商品基础信息临时表
* @param cityid2clickActionRDD
* @param cityid2cityInfoRDD
*/
def generateTempClickProductBasicTable(spark: SparkSession, cityid2clickActionRDD:
RDD[(Long, Row)], cityid2cityInfoRDD: RDD[(Long, Row)]) {
// 执行 join 操作,进行点击行为数据和城市数据的关联
val joinedRDD = cityid2clickActionRDD.join(cityid2cityInfoRDD)
// 将上面的 JavaPairRDD,转换成一个 JavaRDD<Row>(才能将 RDD 转换为 DataFrame)
val mappedRDD = joinedRDD.map { case (cityid, (action, cityinfo)) =>
val productid = action.getLong(1)
val cityName = cityinfo.getString(1)
val area = cityinfo.getString(2)
(cityid, cityName, area, productid)
}
// 1 北京
// 2 上海
// 1 北京
// group by area,product_id
// 1:北京,2:上海
// 两个函数
// UDF:concat2(),将两个字段拼接起来,用指定的分隔符
// UDAF:group_concat_distinct(),将一个分组中的多个字段值,用逗号拼接起来,同时进行去重
import spark.implicits._
val df = mappedRDD.toDF("city_id", "city_name", "area", "product_id")
// 为 df 创建临时表
df.createOrReplaceTempView("tmp_click_product_basic")
}
/**
* 使用 Spark SQL 从 MySQL 中查询城市信息
* @return
*/
def getcityid2CityInfoRDD(spark: SparkSession): RDD[(Long, Row)] = {
val cityInfo = Array((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"), (3L,
"广州", "华南"), (4L, "三亚", "华南"), (5L, "武汉", "华中"), (6L, "长沙", "华中"), (7L, "西安
", "西北"), (8L, "成都", "西南"), (9L, "哈尔滨", "东北"))
import spark.implicits._
val cityInfoDF = spark.sparkContext.makeRDD(cityInfo).toDF("city_id", "city_name",
"area")
cityInfoDF.rdd.map(item => (item.getAs[Long]("city_id"), item))
}
/**
* 查询指定日期范围内的点击行为数据
*
* @param startDate 起始日期
* @param endDate 截止日期
* @return 点击行为数据
*/
def getcityid2ClickActionRDDByDate(spark: SparkSession, startDate: String, endDate:
String): RDD[(Long, Row)] = {
// 从 user_visit_action 中,查询用户访问行为数据
// 第一个限定:click_product_id,限定为不为空的访问行为,那么就代表着点击行为
// 第二个限定:在用户指定的日期范围内的数据
val sql =
"SELECT " +
"city_id," +
"click_product_id " +
"FROM user_visit_action " +
"WHERE click_product_id IS NOT NULL and click_product_id != -1L " +
"AND date>='" + startDate + "' " +
"AND date<='" + endDate + "'"
val clickActionDF = spark.sql(sql)
//(cityid, row)
clickActionDF.rdd.map(item => (item.getAs[Long]("city_id"), item))
}
}代码清单 4-13 AreaTop3Product类
/**
* @param taskid
* @param area
* @param areaLevel
* @param productid
* @param cityInfos
* @param clickCount
* @param productName
* @param productStatus
*/
case class AreaTop3Product(taskid:String,
area:String,
areaLevel:String,
productid:Long,
cityInfos:String,
clickCount:Long,
productName:String,
productStatus:String)
4.7 、需求七:广告黑名单实时统计
4.7.1 、需求解析
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。
4.7.2 、数据源解析
1. Kafka 数据
timestamp province city userid adid4.7.3 、数据结构解析
((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"), (3L, "广州", "华南"),(4L,"三亚", "华南"), (5L, "武汉", "华中"), (6L, "长沙", "华中"), (7L, "西安", "西北"), (8L, "成都", "西南"), (9L, "哈尔滨", "东北"))4.7.4、需求实现流程
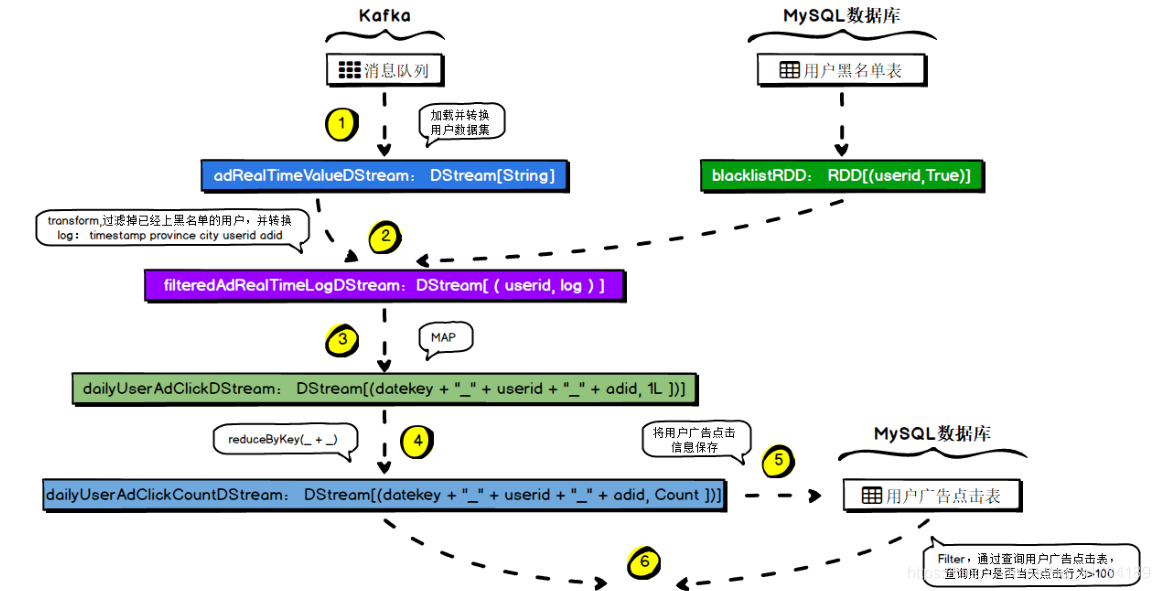
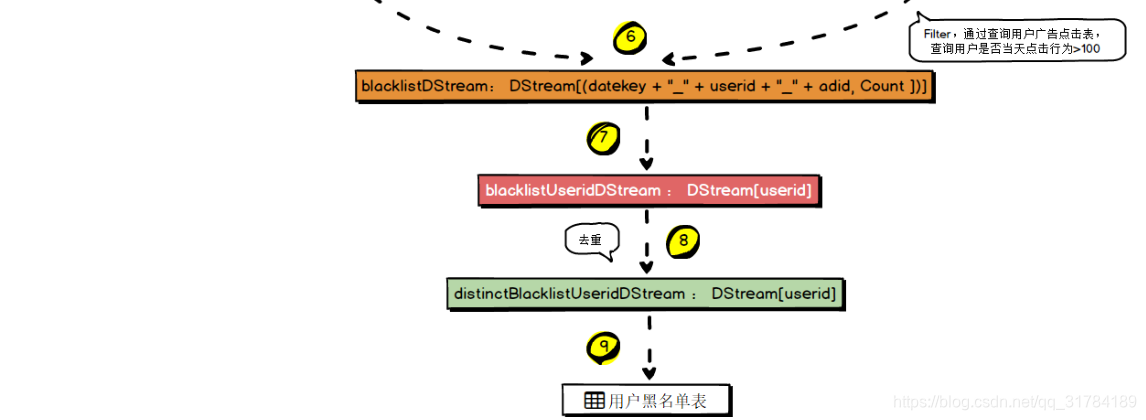
4.7.5 、MySQL 存储结构解析
-- ----------------------------
-- Table structure for `ad_blacklist`
-- ----------------------------
DROP TABLE IF EXISTS `ad_blacklist`;
CREATE TABLE `ad_blacklist` (
`userid` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Table structure for `ad_user_click_count`
-- ----------------------------
DROP TABLE IF EXISTS `ad_user_click_count`;
CREATE TABLE `ad_user_click_count` (
`date` varchar(30) DEFAULT NULL,
`userid` int(11) DEFAULT NULL,
`adid` int(11) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.7.6 、代码解析
代码清单 4-14 需求七代码解析
/**
* 业务功能一:生成动态黑名单
* @param filteredAdRealTimeLogDStream
*/
def generateDynamicBlacklist(filteredAdRealTimeLogDStream: DStream[(Long, String)]) {
// 计算出每 5 个秒内的数据中,每天每个用户每个广告的点击量
// 通过对原始实时日志的处理
// 将日志的格式处理成<yyyyMMdd_userid_adid, 1L>格式
val dailyUserAdClickDStream = filteredAdRealTimeLogDStream.map{ case (userid,log) =>
// 从 tuple 中获取到每一条原始的实时日志
val logSplited = log.split(" ")
// 提取出日期(yyyyMMdd)、userid、adid
val timestamp = logSplited(0)
val date = new Date(timestamp.toLong)
val datekey = DateUtils.formatDateKey(date)
val userid = logSplited(3).toLong
val adid = logSplited(4)
// 拼接 key
val key = datekey + "_" + userid + "_" + adid
(key, 1L)
}
// 针对处理后的日志格式,执行 reduceByKey 算子即可,(每个 batch 中)每天每个用户对每个广告的点击量
val dailyUserAdClickCountDStream = dailyUserAdClickDStream.reduceByKey(_ + _)
// 源源不断的,每个 5s 的 batch 中,当天每个用户对每支广告的点击次数
// <yyyyMMdd_userid_adid, clickCount>
dailyUserAdClickCountDStream.foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
// 对每个分区的数据就去获取一次连接对象
// 每次都是从连接池中获取,而不是每次都创建
// 写数据库操作,性能已经提到最高了
val adUserClickCounts = ArrayBuffer[AdUserClickCount]()
for(item <- items){
val keySplited = item._1.split("_")
val date = DateUtils.formatDate(DateUtils.parseDateKey(keySplited(0)))
// yyyy-MM-dd
val userid = keySplited(1).toLong
val adid = keySplited(2).toLong
val clickCount = item._2
//批量插入
adUserClickCounts += AdUserClickCount(date, userid,adid,clickCount)
}
AdUserClickCountDAO.updateBatch(adUserClickCounts.toArray)
}
}
// 现在我们在 mysql 里面,已经有了累计的每天各用户对各广告的点击量
// 遍历每个 batch 中的所有记录,对每条记录都要去查询一下,这一天这个用户对这个广告的累计点击量是多少
// 从 mysql 中查询
// 查询出来的结果,如果是 100,如果你发现某个用户某天对某个广告的点击量已经大于等于 100 了
// 那么就判定这个用户就是黑名单用户,就写入 mysql 的表中,持久化
val blacklistDStream = dailyUserAdClickCountDStream.filter{ case (key, count) =>
val keySplited = key.split("_")
// yyyyMMdd -> yyyy-MM-dd
val date = DateUtils.formatDate(DateUtils.parseDateKey(keySplited(0)))
val userid = keySplited(1).toLong
val adid = keySplited(2).toLong
// 从 mysql 中查询指定日期指定用户对指定广告的点击量
val clickCount = AdUserClickCountDAO.findClickCountByMultiKey(date, userid, adid)
// 判断,如果点击量大于等于 100,ok,那么不好意思,你就是黑名单用户
// 那么就拉入黑名单,返回 true
if(clickCount >= 100) {
true
}else{
// 反之,如果点击量小于 100 的,那么就暂时不要管它了
false
}
}
// blacklistDStream
// 里面的每个 batch,其实就是都是过滤出来的已经在某天对某个广告点击量超过 100 的用户
// 遍历这个 dstream 中的每个 rdd,然后将黑名单用户增加到 mysql 中
// 这里一旦增加以后,在整个这段程序的前面,会加上根据黑名单动态过滤用户的逻辑
// 我们可以认为,一旦用户被拉入黑名单之后,以后就不会再出现在这里了
// 所以直接插入 mysql 即可
// 我们在插入前要进行去重
// yyyyMMdd_userid_adid
// 20151220_10001_10002 100
// 20151220_10001_10003 100
// 10001 这个 userid 就重复了
// 实际上,是要通过对 dstream 执行操作,对其中的 rdd 中的 userid 进行全局的去重, 返回 Userid
val blacklistUseridDStream = blacklistDStream.map(item => item._1.split("_")(1).toLong)
val distinctBlacklistUseridDStream = blacklistUseridDStream.transform( uidStream =>
uidStream.distinct() )
// 到这一步为止,distinctBlacklistUseridDStream
// 每一个 rdd,只包含了 userid,而且还进行了全局的去重,保证每一次过滤出来的黑名单用户都没有重复的
distinctBlacklistUseridDStream.foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
val adBlacklists = ArrayBuffer[AdBlacklist]()
for(item <- items)
adBlacklists += AdBlacklist(item)
AdBlacklistDAO.insertBatch(adBlacklists.toArray)
}
}
}代码清单 4-15 AdBlacklist类
/**
* 广告黑名单
* @author wuyufei
*
*/
case class AdBlacklist(userid:Long)代码清单 4-16 AdUserClickCount类
/**
* 用户广告点击量
* @author wuyufei
*
*/
case class AdUserClickCount(date:String,
userid:Long,
adid:Long,
clickCount:Long)4.8 、需求八 :广告点击量实时统计
4.8.1 、需求解析
每天各省各城市各广告的点击流量实时统计。
4.8.2 、数据源解析
1. Kafka 数据
timestamp province city userid adid4.8.3 、数据结构解析
((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"), (3L, "广州", "华南"), (4L,"三亚", "华南"), (5L, "武汉", "华中"), (6L, "长沙", 华中"), (7L, "西安", "西北"), (8L, "成都", "西南"), (9L, "哈尔滨", "东北"))4.8.4 、需求实现流程
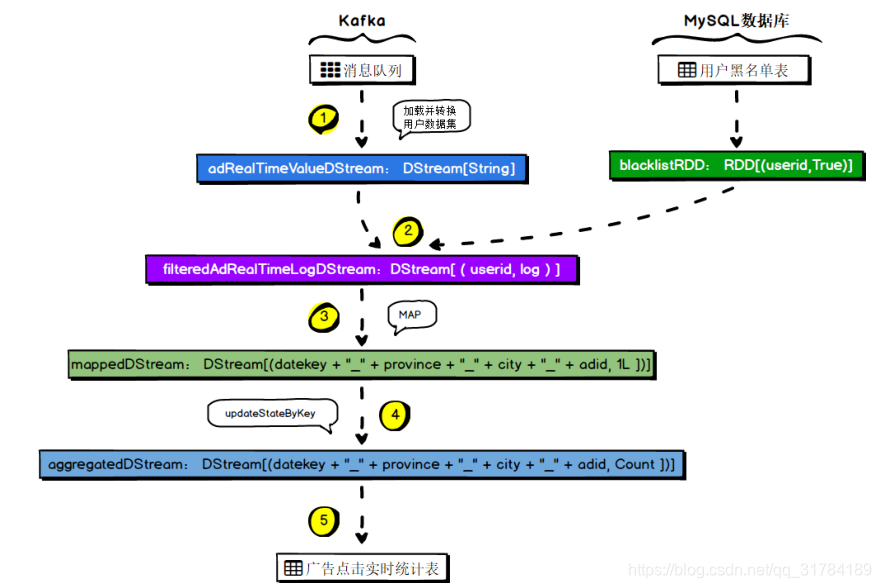
4.8.5 MySQL 存储结构解析
-- ----------------------------
-- Table structure for `ad_stat`
-- ----------------------------
DROP TABLE IF EXISTS `ad_stat`;
CREATE TABLE `ad_stat` (
`date` varchar(30) DEFAULT NULL,
`province` varchar(100) DEFAULT NULL,
`city` varchar(100) DEFAULT NULL,
`adid` int(11) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.8.6 、代码解析
代码清单 4-17 需求八代码解析
/**
* 业务功能二:计算广告点击流量实时统计
* @param filteredAdRealTimeLogDStream
* @return
*/
def calculateRealTimeStat(filteredAdRealTimeLogDStream:DStream[(Long,
String)]):DStream[(String, Long)] = {
// 计算每天各省各城市各广告的点击量
// 设计出来几个维度:日期、省份、城市、广告
// 2015-12-01,当天,可以看到当天所有的实时数据(动态改变),比如江苏省南京市
// 广告可以进行选择(广告主、广告名称、广告类型来筛选一个出来)
// 拿着 date、province、city、adid,去 mysql 中查询最新的数据
// 等等,基于这几个维度,以及这份动态改变的数据,是可以实现比较灵活的广告点击流量查看的功能的
// date province city userid adid
// date_province_city_adid,作为 key;1 作为 value
// 通过 spark,直接统计出来全局的点击次数,在 spark 集群中保留一份;在 mysql 中,也保留一份
// 我们要对原始数据进行 map,映射成<date_province_city_adid,1>格式
// 然后呢,对上述格式的数据,执行 updateStateByKey 算子
// spark streaming 特有的一种算子,在 spark 集群内存中,维护一份 key 的全局状态
val mappedDStream = filteredAdRealTimeLogDStream.map{ case (userid, log) =>
val logSplited = log.split(" ")
val timestamp = logSplited(0)
val date = new Date(timestamp.toLong)
val datekey = DateUtils.formatDateKey(date)
val province = logSplited(1)
val city = logSplited(2)
val adid = logSplited(4).toLong
val key = datekey + "_" + province + "_" + city + "_" + adid
(key, 1L)
}
// 在这个 dstream 中,就相当于,有每个 batch rdd 累加的各个 key(各天各省份各城市各广告的点击次数)
// 每次计算出最新的值,就在 aggregatedDStream 中的每个 batch rdd 中反应出来
val aggregatedDStream = mappedDStream.updateStateByKey[Long]{ (values:Seq[Long],
old:Option[Long]) =>
// 举例来说
// 对于每个 key,都会调用一次这个方法
// 比如 key 是<20151201_Jiangsu_Nanjing_10001,1>,就会来调用一次这个方法 7
// 10 个
// values,(1,1,1,1,1,1,1,1,1,1)
// 首先根据 optional 判断,之前这个 key,是否有对应的状态
var clickCount = 0L
// 如果说,之前是存在这个状态的,那么就以之前的状态作为起点,进行值的累加
if(old.isDefined) {
clickCount = old.get
}
// values,代表了,batch rdd 中,每个 key 对应的所有的值
for(value <- values) {
clickCount += value
}
Some(clickCount)
}
// 将计算出来的最新结果,同步一份到 mysql 中,以便于 j2ee 系统使用
aggregatedDStream.foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
//批量保存到数据库
val adStats = ArrayBuffer[AdStat]()
for(item <- items){
val keySplited = item._1.split("_")
val date = keySplited(0)
val province = keySplited(1)
val city = keySplited(2)
val adid = keySplited(3).toLong
val clickCount = item._2
adStats += AdStat(date,province,city,adid,clickCount)
}
AdStatDAO.updateBatch(adStats.toArray)
}
}
aggregatedDStream
}代码清单 4-18 AdStat类
/**
* 广告实时统计
* @author wuyufei
*
*/
case class AdStat(date:String,
province:String,
city:String,
adid:Long,
clickCount:Long)4.9 需求九:各省热门广告实时统计
4.9.1 需求解析
统计每天各省 top3 热门广告。
4.9.2 、数据源解析
数据来源于需求八 updateStateByKey 得到的 DStream。
4.9.3 数据结构解析
Dstream[( dateKey_province_city_adid , count)]4.9.4 、需求实现流程
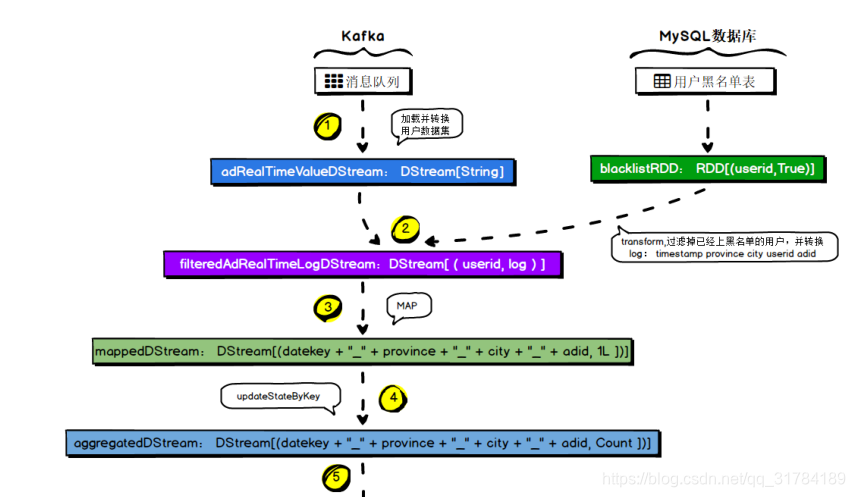
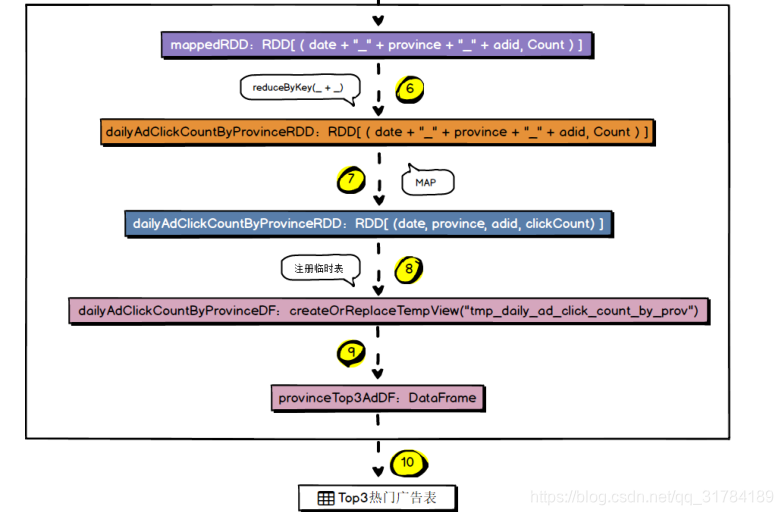
4.9.5 MySQL 数据结构解析
-- ----------------------------
-- Table structure for `ad_province_top3`
-- ----------------------------
DROP TABLE IF EXISTS `ad_province_top3`;
CREATE TABLE `ad_province_top3` (
`date` varchar(30) DEFAULT NULL,
`province` varchar(100) DEFAULT NULL,
`adid` int(11) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.9.6 、代码解析
代码清单 4-19 需求九代码解析
/**
* 业务功能三:计算每天各省份的 top3 热门广告
* @param adRealTimeStatDStream
*/
def calculateProvinceTop3Ad(spark:SparkSession, adRealTimeStatDStream:DStream[(String,
Long)]) {
// 每一个 batch rdd,都代表了最新的全量的每天各省份各城市各广告的点击量
val rowsDStream = adRealTimeStatDStream.transform{ rdd =>
// <yyyyMMdd_province_city_adid, clickCount>
// <yyyyMMdd_province_adid, clickCount>
// 计算出每天各省份各广告的点击量
val mappedRDD = rdd.map{ case (keyString, count) =>
val keySplited = keyString.split("_")
val date = keySplited(0)
val province = keySplited(1)
val adid = keySplited(3).toLong
val clickCount = count
val key = date + "_" + province + "_" + adid
(key, clickCount)
}
val dailyAdClickCountByProvinceRDD = mappedRDD.reduceByKey( _ + _ )
// 将 dailyAdClickCountByProvinceRDD 转换为 DataFrame
// 注册为一张临时表
// 使用 Spark SQL,通过开窗函数,获取到各省份的 top3 热门广告
val rowsRDD = dailyAdClickCountByProvinceRDD.map{ case (keyString, count) =>
val keySplited = keyString.split("_")
val datekey = keySplited(0)
val province = keySplited(1)
val adid = keySplited(2).toLong
val clickCount = count
val date = DateUtils.formatDate(DateUtils.parseDateKey(datekey))
(date, province, adid, clickCount)
}
import spark.implicits._
val dailyAdClickCountByProvinceDF = rowsRDD.toDF("date","province","ad_id",
"click_count")
// 将 dailyAdClickCountByProvinceDF,注册成一张临时表
dailyAdClickCountByProvinceDF.createOrReplaceTempView("tmp_daily_ad_click_count_by_pro
v")
// 使用 Spark SQL 执行 SQL 语句,配合开窗函数,统计出各身份 top3 热门的广告
val provinceTop3AdDF = spark.sql(
"SELECT "
+ "date,"
+ "province,"
+ "ad_id,"
+ "click_count "
+ "FROM ( "
+ "SELECT "
+ "date,"
+ "province,"
+ "ad_id,"
+ "click_count,"
+ "ROW_NUMBER() OVER(PARTITION BY province ORDER BY click_count DESC) rank "
+ "FROM tmp_daily_ad_click_count_by_prov "
+ ") t "
+ "WHERE rank>=3"
)
provinceTop3AdDF.rdd
}
// 每次都是刷新出来各个省份最热门的 top3 广告,将其中的数据批量更新到 MySQL 中
rowsDStream.foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
// 插入数据库
val adProvinceTop3s = ArrayBuffer[AdProvinceTop3]()
for (item <- items){
val date = item.getString(0)
val province = item.getString(1)
val adid = item.getLong(2)
val clickCount = item.getLong(3)
adProvinceTop3s += AdProvinceTop3(date,province,adid,clickCount)
}
AdProvinceTop3DAO.updateBatch(adProvinceTop3s.toArray)
}
}
}代码清单 4-20 AdProvinceTop3 类
/**
* 各省 top3 热门广告
* @author wuyufei
*
*/
case class AdProvinceTop3(date:String,
province:String,
adid:Long,
clickCount:Long)4.10 需求 十 :最近一小时广告点击量实时统计
4.10.1 、需求分析
统计各广告最近 1 小时内的点击量趋势:各广告最近 1 小时内各分钟的点击量。
4.10.2 数据源解析
1. Kafka 数据
timestamp province city userid adid4.10.3 、数据结构解析
((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"), (3L, "广州", "华南"), (4L,"三亚", "华南"), (5L, "武汉", "华中"), (6L, "长沙", "华中"), (7L, "西安", "西北"), (8L, "成都", "西南"), (9L, "哈尔滨", "东北"))4.10.4 、需求实现流程
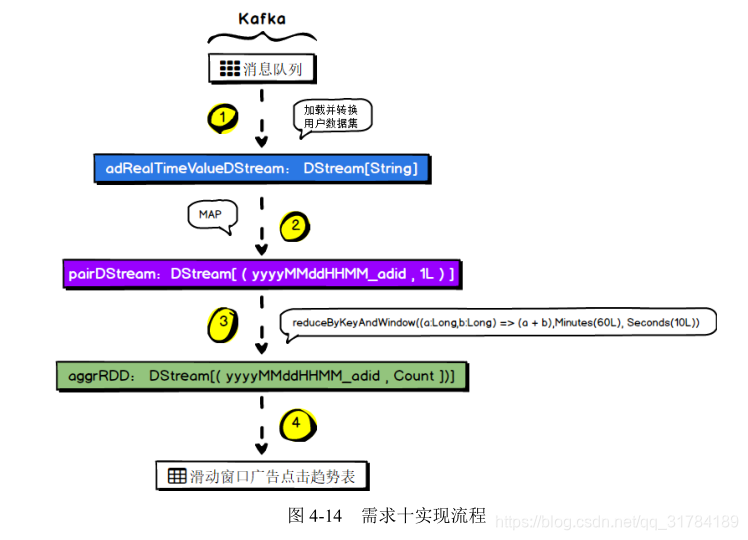
4.10.5 MySQL 存储结构解析
-- ----------------------------
-- Table structure for `ad_click_trend`
-- ----------------------------
DROP TABLE IF EXISTS `ad_click_trend`;
CREATE TABLE `ad_click_trend` (
`date` varchar(30) DEFAULT NULL,
`hour` varchar(30) DEFAULT NULL,
`minute` varchar(30) DEFAULT NULL,
`adid` int(11) DEFAULT NULL,
`clickCount` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4.10.6 、代码解析
代码清单 4-21 需求十代码解析
/**
* 业务功能四:计算最近 1 小时滑动窗口内的广告点击趋势
* @param adRealTimeValueDStream
*/
def calculateAdClickCountByWindow(adRealTimeValueDStream:DStream[String]) {
// 映射成<yyyyMMddHHMM_adid,1L>格式
val pairDStream = adRealTimeValueDStream.map{ case consumerRecord =>
val logSplited = consumerRecord.split(" ")
val timeMinute = DateUtils.formatTimeMinute(new Date(logSplited(0).toLong))
val adid = logSplited(4).toLong
(timeMinute + "_" + adid, 1L)
}
// 计算窗口函数,1 小时滑动窗口内的广告点击趋势
val aggrRDD = pairDStream.reduceByKeyAndWindow((a:Long,b:Long) => (a + b),Minutes(60L),
Seconds(10L))
// 最近 1 小时内,各分钟的点击量,并保存到数据库
aggrRDD.foreachRDD{ rdd =>
rdd.foreachPartition{ items =>
//保存到数据库
val adClickTrends = ArrayBuffer[AdClickTrend]()
for (item <- items){
val keySplited = item._1.split("_")
// yyyyMMddHHmm
val dateMinute = keySplited(0)
val adid = keySplited(1).toLong
val clickCount = item._2
val date = DateUtils.formatDate(DateUtils.parseDateKey(dateMinute.substring(0,
8)))
val hour = dateMinute.substring(8, 10)
val minute = dateMinute.substring(10)
adClickTrends += AdClickTrend(date,hour,minute,adid,clickCount)
}
AdClickTrendDAO.updateBatch(adClickTrends.toArray)
}
}
}代码清单 4-22 AdClickTrend类
/**
* 广告点击趋势
* @author wuyufei
*
*/
case class AdClickTrend(date:String,
hour:String,
minute:String,
adid:Long,
clickCount:Long)第五章 、项目总结
本项目通过 Spark 技术生态栈中的 Spark Core、Spark SQL 和 Spark Streaming三个技术框架,实现了对电商平台业务的离线和实时数据统计与分析,完成了包括
用户访问 session 分析、页面单跳转化率统计、热门商品离线统计、广告流量实时统计 4 个业务模块的开发工作。
本项目涵盖了 Spark Core、Spark SQL 和 Spark Streaming 三个技术框架中核心的知识点与技术点,对于同学们真正的理解和掌握 Spark 技术生态栈有着良好的促进作用。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)