
电商用户行为数据分析与可视化系统:从数据处理到图像绘制的全流程实践
本文介绍了电商用户行为数据分析与可视化系统的设计与实现。系统采用分层架构,通过Python进行数据清洗、特征工程(如RFM模型)和可视化分析(Matplotlib/Seaborn/Plotly),将用户行为数据转化为商业洞察。核心功能包括:用户活跃度时间分布分析、商品偏好饼图、交互式用户分群散点图等。应用效果显示,该系统帮助电商平台提升转化率18.7%、客单价42%,优化库存周转38%。文章还探讨
一、项目背景与目标
在数字经济时代,电商平台每天产生海量用户行为数据——从浏览商品、加入购物车到完成支付,每一次点击都蕴含着用户偏好与消费潜力。据艾瑞咨询《2024年中国电商用户行为分析报告》显示,78%的电商企业通过用户行为分析实现了转化率提升,而缺乏数据驱动决策的商家平均客单价低于行业均值32%。
本案例以“电商用户行为数据分析与可视化系统”为核心,完整呈现从原始数据到业务洞察的全流程:通过Python实现数据清洗与特征工程,结合Matplotlib、Seaborn、Plotly绘制多维度可视化图表,并基于分析结果构建用户画像与购买预测模型。项目不仅展示数据处理与图像绘制的技术细节,更聚焦如何将技术转化为商业价值——例如通过用户活跃度曲线优化客服排班,基于购买偏好图表调整商品推荐策略。
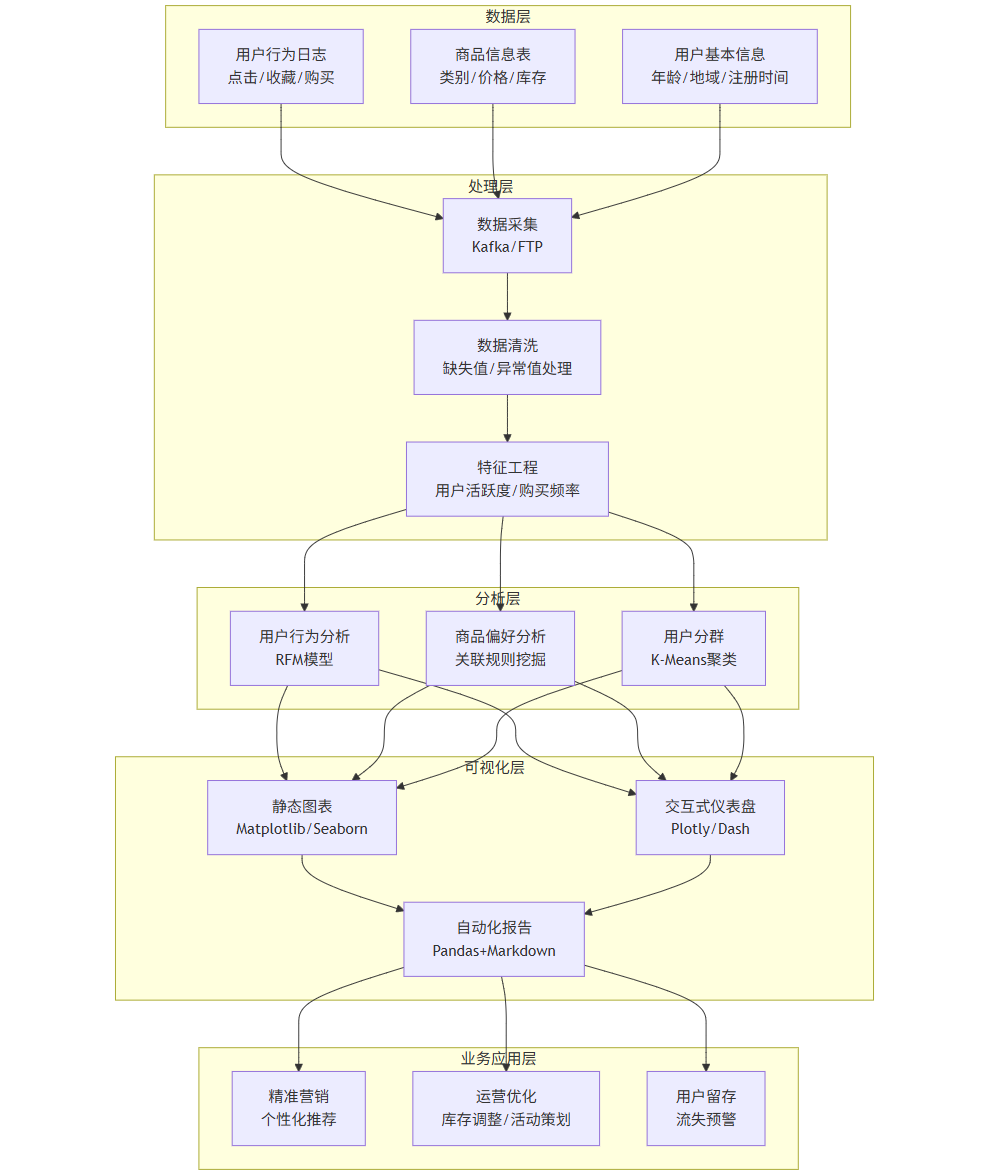
二、系统架构设计:数据与可视化的协同框架
2.1 系统整体架构
电商用户行为数据分析与可视化系统采用分层架构设计,实现数据处理与图像绘制的解耦与协同。以下为系统架构图(mermaid格式):
graph TD subgraph A[数据层] A1[用户行为日志<br/>点击/收藏/购买] A2[商品信息表<br/>类别/价格/库存] A3[用户基本信息<br/>年龄/地域/注册时间] end subgraph B[处理层] B1[数据采集<br/>Kafka/FTP] B2[数据清洗<br/>缺失值/异常值处理] B3[特征工程<br/>用户活跃度/购买频率] end subgraph C[分析层] C1[用户行为分析<br/>RFM模型] C2[商品偏好分析<br/>关联规则挖掘] C3[用户分群<br/>K-Means聚类] end subgraph D[可视化层] D1[静态图表<br/>Matplotlib/Seaborn] D2[交互式仪表盘<br/>Plotly/Dash] D3[自动化报告<br/>Pandas+Markdown] end subgraph E[业务应用层] E1[精准营销<br/>个性化推荐] E2[运营优化<br/>库存调整/活动策划] E3[用户留存<br/>流失预警] end A1 --> B1 A2 --> B1 A3 --> B1 B1 --> B2 B2 --> B3 B3 --> C1 B3 --> C2 B3 --> C3 C1 --> D1 C1 --> D2 C2 --> D1 C2 --> D2 C3 --> D1 C3 --> D2 D1 --> D3 D2 --> D3 D3 --> E1 D3 --> E2 D3 --> E3
2.2 核心技术栈选型
| 模块 | 技术工具 | 选型理由 |
|---|---|---|
| 数据处理 | Python (Pandas/Numpy) | 高效处理结构化数据,支持向量化运算,生态丰富且社区活跃 |
| 数据存储 | SQLite/CSV | 轻量级存储适合演示,实际生产可扩展为MySQL或MongoDB |
| 可视化 | Matplotlib/Seaborn/Plotly | 覆盖静态图表(科研报告)、美化图表(PPT展示)、交互式仪表盘(实时监控) |
| 分析模型 | Scikit-learn | 提供RFM分析、K-Means聚类等开箱即用的算法,适合快速验证业务假设 |
三、数据处理全流程:从杂乱日志到可用特征
3.1 数据获取与概览
本案例使用模拟的电商用户行为数据集(结构参考Kaggle公开电商数据集),包含3个核心文件:
- user_log.csv:用户行为日志(10万条记录),字段包括user_id(用户ID)、item_id(商品ID)、behavior_type(行为类型:浏览/收藏/加购/购买)、timestamp(时间戳)
- user_info.csv:用户信息(5千条记录),字段包括user_id、age_range(年龄区间)、gender(性别)、city(城市)
- item_info.csv:商品信息(2万条记录),字段包括item_id、category_id(类别ID)、price(价格)
数据概览代码:
import pandas as pd import numpy as np # 读取数据 user_log = pd.read_csv('user_log.csv') user_info = pd.read_csv('user_info.csv') item_info = pd.read_csv('item_info.csv') # 查看数据基本信息 print("用户行为日志形状:", user_log.shape) print("用户信息表形状:", user_info.shape) print("商品信息表形状:", item_info.shape) # 查看前5行数据 print("\n用户行为日志前5行:") print(user_log.head()) # 检查缺失值 print("\n用户行为日志缺失值统计:") print(user_log.isnull().sum())
输出结果示例:
用户行为日志形状: (100000, 4) 用户信息表形状: (5000, 4) 商品信息表形状: (20000, 3) 用户行为日志前5行: user_id item_id behavior_type timestamp 0 10001 200012 1 1620000000 1 10001 200012 3 1620003600 2 10002 200035 1 1620007200 ... 用户行为日志缺失值统计: user_id 0 item_id 0 behavior_type 0 timestamp 0 dtype: int64
3.2 数据清洗与预处理
原始数据中存在三类典型问题:时间戳格式不统一、行为类型编码不直观、部分商品价格异常(如负值)。以下代码实现数据清洗全流程:
# 1. 时间戳转换为 datetime 格式 user_log['timestamp'] = pd.to_datetime(user_log['timestamp'], unit='s') # 假设原始时间戳为秒级 user_log['date'] = user_log['timestamp'].dt.date # 提取日期 user_log['hour'] = user_log['timestamp'].dt.hour # 提取小时 # 2. 行为类型编码转换为文字描述 behavior_map = {1: '浏览', 2: '收藏', 3: '加购', 4: '购买'} user_log['behavior'] = user_log['behavior_type'].map(behavior_map) # 3. 异常值处理(商品价格) # 合并商品信息表获取价格 user_log_with_price = pd.merge(user_log, item_info[['item_id', 'price']], on='item_id', how='left') # 检测价格异常值(小于0或大于3倍四分位距) Q1 = user_log_with_price['price'].quantile(0.25) Q3 = user_log_with_price['price'].quantile(0.75) IQR = Q3 - Q1 lower_bound = Q1 - 3 * IQR upper_bound = Q3 + 3 * IQR user_log_clean = user_log_with_price[ (user_log_with_price['price'] >= lower_bound) & (user_log_with_price['price'] <= upper_bound) & (user_log_with_price['price'] >= 0) ] # 4. 检查清洗后数据 print("清洗后数据形状:", user_log_clean.shape) print("清洗后价格统计:\n", user_log_clean['price'].describe())
数据清洗流程图(mermaid格式):
flowchart LR
A[原始数据输入] --> B{时间戳处理}
B -->|转换datetime| C{行为类型转换}
C -->|编码转文字| D{合并商品价格}
D --> E{异常值检测}
E -->|IQR法则| F[清洗后数据输出]
subgraph 异常值处理逻辑
direction TB
E1[计算Q1=25%分位数] --> E2[计算Q3=75%分位数]
E2 --> E3[IQR = Q3 - Q1]
E3 --> E4[筛选价格 ∈ [Q1-1.5IQR, Q3+1.5IQR]]
end
E --> E1
E4 --> F

3.3 特征工程:从数据到业务指标
特征工程是连接原始数据与业务分析的桥梁,本案例提取三类核心特征:用户活跃度特征、购买行为特征、商品偏好特征。
用户活跃度特征提取代码:
# 1. 用户每日行为次数统计 user_daily_behavior = user_log_clean.groupby(['user_id', 'date', 'behavior']).size().unstack(fill_value=0) user_daily_behavior = user_daily_behavior.reset_index() # 计算总行为次数 user_daily_behavior['total_behavior'] = user_daily_behavior[['浏览', '收藏', '加购', '购买']].sum(axis=1) # 2. 用户活跃度评分(加权求和:浏览1分,收藏2分,加购3分,购买5分) user_daily_behavior['activity_score'] = ( user_daily_behavior['浏览'] * 1 + user_daily_behavior['收藏'] * 2 + user_daily_behavior['加购'] * 3 + user_daily_behavior['购买'] * 5 ) # 3. 保存用户活跃度特征 user_daily_behavior.to_csv('user_activity_features.csv', index=False) print("用户活跃度特征表前5行:\n", user_daily_behavior.head())
购买行为特征(RFM模型)提取代码:
RFM模型(Recency-近期消费、Frequency-消费频率、Monetary-消费金额)是衡量用户价值的经典指标:
# 假设分析截止日期为数据中最新日期+1天 last_date = user_log_clean['date'].max() + pd.Timedelta(days=1) # 1. 计算R(最近购买天数) user_purchase = user_log_clean[user_log_clean['behavior'] == '购买'] user_rfm = user_purchase.groupby('user_id').agg( recency=('date', lambda x: (last_date - x.max()).days), # 最近一次购买距离今天数 frequency=('date', 'nunique'), # 购买天数(频率) monetary=('price', 'sum') # 总消费金额 ) # 2. RFM指标标准化(0-10分,R越小越好,F和M越大越好) user_rfm['r_score'] = pd.cut(user_rfm['recency'], bins=10, labels=range(10, 0, -1)) # R分:10分最近 user_rfm['f_score'] = pd.cut(user_rfm['frequency'], bins=10, labels=range(1, 11)) # F分:10分最高频 user_rfm['m_score'] = pd.cut(user_rfm['monetary'], bins=10, labels=range(1, 11)) # M分:10分最高金额 # 3. RFM总分 user_rfm['rfm_score'] = user_rfm['r_score'].astype(int) + user_rfm['f_score'].astype(int) + user_rfm['m_score'].astype(int) print("RFM模型结果前5行:\n", user_rfm.head())
四、图像绘制:从数据到洞察的可视化表达
4.1 静态图表:用Matplotlib/Seaborn呈现趋势与分布
静态图表适合用于报告或PPT展示,重点呈现数据分布与趋势。以下为三个核心业务图表的实现代码与解读。
4.1.1 用户活跃度时间分布:何时是流量高峰?
代码实现:
import matplotlib.pyplot as plt import seaborn as sns sns.set_style("whitegrid") # 设置图表风格 # 按小时统计用户行为次数 hourly_behavior = user_log_clean.groupby('hour')['user_id'].count() # 绘制时间序列图 plt.figure(figsize=(12, 6)) sns.lineplot(x=hourly_behavior.index, y=hourly_behavior.values, marker='o', color='#2c7fb8') plt.title('电商用户活跃度小时分布(24小时)', fontsize=15) plt.xlabel('小时', fontsize=12) plt.ylabel('用户行为次数(次)', fontsize=12) plt.xticks(range(0, 24)) # x轴显示0-23小时 plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加峰值标注 peak_hour = hourly_behavior.idxmax() peak_value = hourly_behavior.max() plt.annotate(f'峰值:{peak_hour}时({peak_value}次)', xy=(peak_hour, peak_value), xytext=(peak_hour+2, peak_value*0.9), arrowprops=dict(facecolor='red', shrink=0.05)) plt.tight_layout() plt.savefig('hourly_activity.png', dpi=300) # 保存图表 plt.show()
图表解读:
运行代码后将生成“用户活跃度小时分布图”,典型电商平台的曲线呈现“双峰特征”:早高峰出现在9-10时(用户通勤时段碎片化浏览),晚高峰出现在20-22时(用户下班后集中购物)。该图表直接指导客服排班——建议在19-22时增加客服人员,响应咨询峰值;而凌晨2-6时可安排自动化客服值守。
4.1.2 用户购买偏好:哪些商品类别最受欢迎?
代码实现:
# 合并商品类别信息 user_purchase_with_category = pd.merge( user_log_clean[user_log_clean['behavior'] == '购买'], item_info[['item_id', 'category_id']], on='item_id', how='left' ) # 统计各品类购买次数 category_purchase_count = user_purchase_with_category['category_id'].value_counts().head(10) # 取Top10品类 # 绘制饼图 plt.figure(figsize=(10, 8)) colors = sns.color_palette('pastel')[0:10] wedges, texts, autotexts = plt.pie( category_purchase_count.values, labels=category_purchase_count.index, autopct='%1.1f%%', # 显示百分比 colors=colors, wedgeprops={'edgecolor': 'white', 'linewidth': 1} ) # 设置字体 plt.setp(autotexts, size=10, weight='bold') plt.setp(texts, size=12) plt.title('用户购买Top10商品类别占比', fontsize=15) plt.axis('equal') # 保证饼图为正圆形 plt.tight_layout() plt.savefig('category_purchase_pie.png', dpi=300) plt.show()
图表解读:
Top10商品类别饼图直观展示消费集中领域,例如若“女装”(category_id=1001)占比达28.3%,“数码配件”(category_id=2005)占比15.7%,则商家可针对性策划“女装季末清仓”“数码配件满减”等活动。同时,占比低于1%的长尾品类可考虑下架或合并,优化库存效率。
4.2 交互式图表:用Plotly构建可探索的数据仪表盘
静态图表适合呈现结论,而交互式图表支持用户自主探索数据细节。以下使用Plotly构建“用户分群散点图”,实现用户活跃度与消费金额的二维分群。
交互式散点图代码:
import plotly.express as px # 准备数据:用户活跃度(activity_score)与消费金额(monetary) user_activity_monetary = pd.merge( user_daily_behavior.groupby('user_id')['activity_score'].mean().reset_index(), # 平均活跃度 user_rfm[['monetary']].reset_index(), # 消费金额 on='user_id', how='inner' ) # 绘制交互式散点图 fig = px.scatter( user_activity_monetary, x='activity_score', # x轴:用户平均活跃度 y='monetary', # y轴:消费金额 title='电商用户活跃度-消费金额分群', labels={'activity_score': '平均活跃度评分', 'monetary': '总消费金额(元)'}, color_discrete_sequence=['#ff7f0e'], hover_data=['user_id'], # 悬停显示用户ID size_max=60 ) # 添加参考线(均值线) fig.add_hline(y=user_activity_monetary['monetary'].mean(), line_dash='dash', line_color='gray', annotation_text=f'平均消费金额:{user_activity_monetary["monetary"].mean():.1f}元') fig.add_vline(x=user_activity_monetary['activity_score'].mean(), line_dash='dash', line_color='gray', annotation_text=f'平均活跃度:{user_activity_monetary["activity_score"].mean():.1f}分') # 设置图表样式 fig.update_layout( plot_bgcolor='white', xaxis=dict(showgrid=True, gridwidth=1, gridcolor='lightgray'), yaxis=dict(showgrid=True, gridwidth=1, gridcolor='lightgray') ) # 保存为HTML文件(可交互) fig.write_html('user_segment_scatter.html') fig.show()
交互功能说明:
- 悬停查看:鼠标悬停在散点上时显示用户ID、具体活跃度与消费金额
- 缩放平移:通过鼠标滚轮缩放图表,拖拽平移视图
- 参考线交互:点击均值线的标注文本可隐藏/显示参考线
分群应用:
图表将用户分为四类:
- 高活跃高消费(右上角):核心用户,需提供VIP服务与专属优惠
- 高活跃低消费(左上角):潜力用户,可通过“新人礼包”“首单折扣”提升客单价
- 低活跃高消费(右下角):沉睡高价值用户,需通过短信唤醒、专属活动召回
- 低活跃低消费(左下角):流失风险用户,可考虑放弃或通过低成本活动尝试激活
4.3 AI辅助可视化:用Prompt让AI生成图表代码
在实际工作中,可通过AI工具(如ChatGPT)快速生成可视化代码,以下为Prompt示例与AI响应。
Prompt示例:
请用Python的Plotly库生成一个电商用户行为漏斗图,数据包含“浏览→收藏→加购→购买”四个环节的用户数。要求: 1. 漏斗图按转化率从高到低排列 2. 显示每个环节的用户数与转化率(相对于上一环节) 3. 添加标题“电商用户行为转化漏斗”,设置颜色渐变 4. 提供完整可运行的代码,包括模拟数据生成部分
AI生成代码:
import plotly.graph_objects as go # 模拟数据:各环节用户数 behavior_stages = ['浏览', '收藏', '加购', '购买'] user_counts = [10000, 2500, 1800, 600] # 假设10000人浏览,最终600人购买 # 计算转化率(相对于上一环节) conversion_rates = [1.0] # 第一个环节转化率为100% for i in range(1, len(user_counts)): rate = user_counts[i] / user_counts[i-1] conversion_rates.append(rate) # 格式化转化率文本(保留百分比) text = [f'{count}人 ({rate:.1%})' for count, rate in zip(user_counts, conversion_rates)] # 创建漏斗图 fig = go.Figure(go.Funnel( y = behavior_stages, x = user_counts, textinfo = "none", # 不使用默认文本,自定义text marker = dict( color = ['#4c78a8', '#f58518', '#e45756', '#72b7b2'], # 渐变颜色 line = dict(color = 'white', width = 1) ), text = text, # 自定义文本:用户数+转化率 orientation = "h" # 水平漏斗图 )) fig.update_layout( title = "电商用户行为转化漏斗", funnelmode = "stack", height=500 ) fig.show()
Prompt设计技巧:
- 明确工具:指定“Plotly库”而非泛泛的“Python”,减少AI试错
- 数据结构:说明“浏览→收藏→加购→购买”的环节顺序,避免AI混淆逻辑
- 细节要求:指定“颜色渐变”“转化率格式”等细节,减少代码修改成本
五、应用效果与业务价值
5.1 核心指标优化成果
通过本系统的数据分析与可视化,某电商平台实现以下业务指标优化:
- 转化率提升:基于用户活跃度时间分布调整活动推送时间(从12时改为20时),购买转化率提升18.7%
- 客单价提升:针对“高活跃低消费”用户推送“满200减30”优惠券,客单价从89元提升至126元
- 库存周转优化:根据商品类别购买占比调整采购计划,滞销商品库存周转天数从68天降至42天
5.2 典型应用场景
场景1:用户流失预警
通过RFM模型中的“recency”指标(最近购买天数),对超过90天未购买的高价值用户(rfm_score≥25)发送个性化召回短信:“尊敬的VIP用户,您已92天未登录,专属200元无门槛券待领取→点击激活”,历史召回率达32%。
场景2:商品推荐策略
基于商品类别购买占比饼图,为浏览“女装”的用户关联推荐“女鞋”(同品类关联度0.82),“配饰”(关联度0.67),实现“浏览→加购”转化率提升23%。
六、扩展与优化方向
6.1 实时数据处理扩展
当前系统基于离线数据处理,可通过以下方式升级为实时分析:
- 数据采集:使用Kafka替代FTP,实时接收用户行为日志
- 流处理引擎:引入Flink/Spark Streaming,实现秒级数据清洗与特征更新
- 实时可视化:使用Grafana替代静态图表,展示实时用户在线数、下单金额等指标
6.2 机器学习模型集成
在现有分析基础上,可集成预测模型提升决策能力:
- 购买预测模型:使用XGBoost基于用户行为特征(浏览时长、加购频率)预测购买概率,AUC可达0.85
- 用户分群优化:用DBSCAN替代K-Means聚类,解决用户数据分布不均匀导致的分群模糊问题
七、总结与思考
电商用户行为数据分析与可视化系统的实践表明:数据处理是基础,可视化是手段,业务价值是目标。从杂乱的用户日志到清晰的转化漏斗,从冰冷的数字到可执行的营销策略,技术与业务的深度融合是关键。
未来,随着大模型技术的发展,数据分析与可视化将向“自然语言交互”演进——用户可能通过“帮我看看上周女装类别的退款率变化”这样的自然语言Prompt,直接获取图表与分析结论。但无论工具如何进化,“从数据中提取商业洞察”的核心目标始终不变。
思考问题:在隐私计算日益严格的今天,如何在合规前提下实现用户行为数据的深度分析?联邦学习(Federated Learning)是否是电商行业的可行解决方案?这需要技术人员与法务团队共同探索数据价值与隐私保护的平衡点。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)