
神速快递批量查询软件v1.71:高效自动化物流管理工具
随着电商行业的迅猛发展,物流信息的查询需求日益增加,传统的单号逐条查询方式已无法满足高效工作的需求。快递单号批量查询技术应运而生,成为现代物流管理中的重要工具。该技术通过并发请求、API聚合与数据缓存等手段,实现对成百上千个快递单号的高效、实时查询。其核心价值在于大幅提升物流信息处理效率,降低人工操作成本,并为电商平台、仓储系统和客服流程提供强有力的数据支撑。本章将围绕其基本概念、典型应用场景展开

简介:在电商迅猛发展的背景下,快递单号查询效率成为物流管理的重要环节。神速快递批量查询软件v1.71是一款专为商家和物流公司设计的专业工具,支持国内外近百家快递公司的一键批量查询。该软件具备智能识别快递公司、异常件自动标记、高并发处理能力及简洁用户界面,显著提升查询效率并降低人力成本。适用于电商卖家、物流公司及个人用户,是实现高效物流管理和客户服务优化的重要工具。 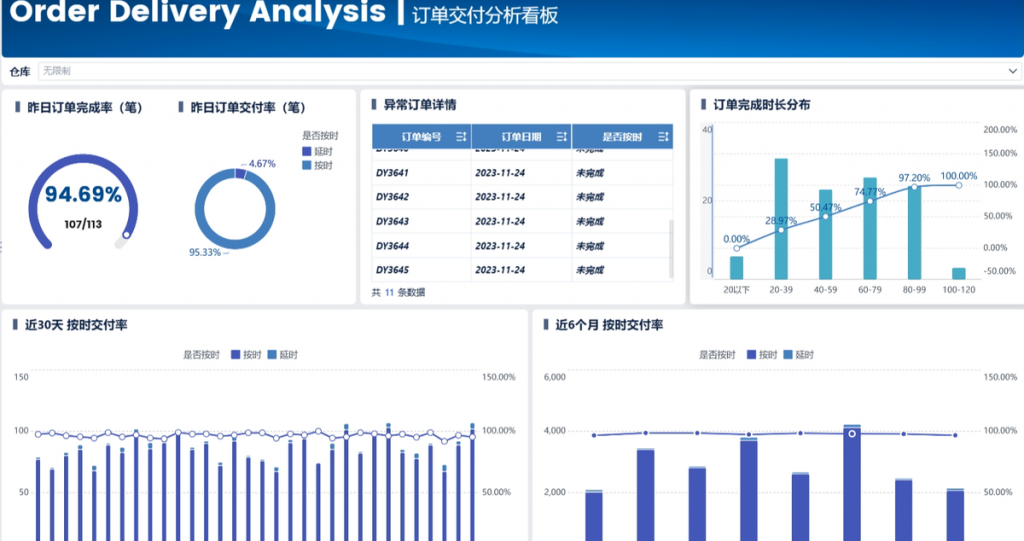
1. 快递单号批量查询技术概述
随着电商行业的迅猛发展,物流信息的查询需求日益增加,传统的单号逐条查询方式已无法满足高效工作的需求。快递单号批量查询技术应运而生,成为现代物流管理中的重要工具。该技术通过并发请求、API聚合与数据缓存等手段,实现对成百上千个快递单号的高效、实时查询。其核心价值在于大幅提升物流信息处理效率,降低人工操作成本,并为电商平台、仓储系统和客服流程提供强有力的数据支撑。本章将围绕其基本概念、典型应用场景展开论述,为后续章节的技术实现与系统优化奠定理论基础。
2. 神速快递软件架构与核心技术
2.1 软件整体架构设计
2.1.1 前端界面与后端逻辑的分离设计
在现代软件开发中,前后端分离已成为主流架构设计模式。神速快递软件采用前后端分离的设计理念,旨在提升系统的可维护性、可扩展性与响应速度。
前端部分采用Electron框架构建桌面客户端,结合Vue.js实现用户交互界面。这种组合不仅支持跨平台运行(Windows、Mac、Linux),还具备良好的界面渲染性能和响应式布局。前端主要负责数据展示、用户操作和界面交互,不直接参与业务逻辑处理。
后端则基于Python语言构建,使用Flask框架提供RESTful API服务,承担数据采集、解析、查询、缓存和异常处理等核心功能。前后端通过HTTP接口进行通信,前端将用户操作(如单号输入、查询请求)封装为JSON格式发送给后端,后端处理完成后返回结构化数据供前端展示。
这种架构设计的优势包括:
- 职责清晰 :前端专注于UI和交互,后端专注于数据处理。
- 便于维护与升级 :前后端可独立更新,不影响彼此。
- 提升性能 :后端集中处理高并发任务,前端保持轻量化响应。
2.1.2 数据采集、处理与展示流程
神速快递软件的数据流程可分为三个主要阶段:采集、处理与展示。
数据采集阶段
用户通过前端界面批量输入快递单号,前端将这些信息以JSON格式发送至后端服务。后端接收请求后,调用相应的快递公司API,将单号作为参数传入,发起HTTP请求获取物流信息。
数据处理阶段
后端接收到API返回的原始数据后,首先进行数据清洗和格式标准化。由于不同快递公司的返回格式不一致(如顺丰返回XML格式,中通返回JSON),系统内置解析模块进行统一处理。处理完成后,数据将被缓存到本地数据库(如SQLite或Redis)中,避免重复请求带来的性能损耗。
数据展示阶段
处理后的数据通过后端API返回至前端界面,前端使用Vue.js组件动态渲染数据,展示物流状态、时间线、运输节点等关键信息。此外,系统还支持导出查询结果为Excel或CSV文件,便于用户离线分析。
数据流程图(Mermaid格式)
graph TD
A[用户输入单号] --> B[前端封装请求]
B --> C[发送至后端API]
C --> D[调用快递API]
D --> E[获取原始物流数据]
E --> F[解析与标准化]
F --> G[缓存至数据库]
G --> H[返回结构化数据]
H --> I[前端渲染展示]
代码示例:前后端通信接口(Flask + Vue.js)
后端 Flask 接口示例(app.py)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/query', methods=['POST'])
def query_tracking():
data = request.json
tracking_numbers = data.get('tracking_numbers')
results = []
for number in tracking_numbers:
# 模拟调用快递API
response = requests.get(f"https://api.example.com/track?number={number}")
if response.status_code == 200:
parsed_data = parse_response(response.json())
results.append(parsed_data)
else:
results.append({"number": number, "status": "failed", "error": "API error"})
return jsonify({"results": results})
def parse_response(data):
# 模拟解析逻辑
return {
"number": data.get("number"),
"status": data.get("status"),
"update_time": data.get("update_time"),
"details": data.get("details")
}
if __name__ == '__main__':
app.run(debug=True)
前端 Vue.js 请求示例(QueryComponent.vue)
<template>
<div>
<textarea v-model="inputNumbers" placeholder="请输入快递单号,每行一个"></textarea>
<button @click="submitQuery">查询</button>
<div v-for="result in results" :key="result.number">
<p>单号: {{ result.number }}</p>
<p>状态: {{ result.status }}</p>
<p>更新时间: {{ result.update_time }}</p>
</div>
</div>
</template>
<script>
export default {
data() {
return {
inputNumbers: '',
results: []
}
},
methods: {
async submitQuery() {
const numbers = this.inputNumbers.split('\n').filter(n => n.trim() !== '');
const response = await fetch('http://localhost:5000/query', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ tracking_numbers: numbers })
});
const data = await response.json();
this.results = data.results;
}
}
}
</script>
代码逻辑分析与参数说明
- Flask后端接口 :
/query接口接收前端POST请求,提取单号列表。- 遍历每个单号,调用第三方快递API获取数据。
- 调用
parse_response方法进行数据标准化处理。 -
返回统一格式的JSON结果供前端展示。
-
Vue前端组件 :
- 使用
v-model绑定用户输入的快递单号。 - 点击按钮后,将单号按行分割为数组,并发送POST请求。
-
接收返回数据后,使用
v-for渲染每个单号的物流信息。 -
参数说明 :
tracking_numbers:前端传递的快递单号数组。response.json():模拟从快递API返回的原始数据。parse_response:负责将不同格式的API响应统一为标准结构。
2.2 快递数据通信机制
2.2.1 HTTP/HTTPS协议在快递API通信中的应用
神速快递软件与快递公司API之间的通信基于HTTP/HTTPS协议。HTTPS的使用确保了数据传输的安全性,防止中间人攻击和数据泄露。
系统在与快递API交互时遵循以下流程:
- 请求构造 :根据快递公司API文档,构造请求URL与参数,如单号、身份认证token等。
- 发起请求 :使用Python的
requests库发起GET或POST请求。 - 接收响应 :接收API返回的原始数据(JSON/XML)。
- 错误处理 :判断HTTP状态码,处理网络错误、超时、认证失败等情况。
快递API请求示例(以中通为例)
import requests
def zto_query(tracking_number):
url = "https://www.kuaidi100.com/query"
params = {
"type": "zhongtong",
"postid": tracking_number
}
try:
response = requests.get(url, params=params, timeout=10)
if response.status_code == 200:
return response.json()
else:
return {"status": "error", "message": f"HTTP {response.status_code}"}
except requests.exceptions.RequestException as e:
return {"status": "error", "message": str(e)}
参数说明
url:中通官方提供的查询API地址。params:GET请求参数,包含快递公司名称和单号。timeout=10:设置请求超时时间,防止长时间阻塞。try-except:捕获网络异常,提升程序健壮性。
2.2.2 异步请求与响应处理机制
为了提高查询效率,特别是在批量处理多个快递单号时,神速快递软件采用了异步请求机制。传统的同步请求会导致请求逐个执行,响应时间长且效率低。而异步方式则可以并发执行多个请求,显著提升整体查询速度。
Python中可以使用 aiohttp 或 concurrent.futures 实现异步HTTP请求。以下是一个基于 concurrent.futures.ThreadPoolExecutor 的多线程异步查询示例:
多线程异步查询示例
import concurrent.futures
import requests
def async_query(tracking_number):
url = "https://www.kuaidi100.com/query"
params = {
"type": "zhongtong",
"postid": tracking_number
}
response = requests.get(url, params=params)
return response.json()
def batch_query_async(numbers):
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_to_number = {executor.submit(async_query, number): number for number in numbers}
for future in concurrent.futures.as_completed(future_to_number):
number = future_to_number[future]
try:
data = future.result()
results.append({"number": number, "data": data})
except Exception as exc:
results.append({"number": number, "error": str(exc)})
return results
参数说明与逻辑分析
ThreadPoolExecutor:创建线程池,控制最大并发数量(此处设为10)。future_to_number:将每个查询任务与单号关联,便于结果匹配。as_completed:按任务完成顺序返回结果,提高响应效率。future.result():获取每个线程的返回结果。- 异常处理:捕获每个线程可能抛出的异常,确保整体任务不中断。
异步机制的优势
- 高效并发 :避免请求排队,提升整体响应速度。
- 资源可控 :通过
max_workers控制并发数量,防止系统资源耗尽。 - 异常隔离 :单个请求失败不影响其他请求执行。
2.3 核心模块功能解析
2.3.1 单号识别与解析模块
在实际使用中,用户可能输入不同快递公司的单号,而不同公司的单号格式、长度、规则各不相同。例如,顺丰单号为12位数字,中通单号为13位数字,DHL单号可能包含字母和数字组合。因此,系统需要具备自动识别快递公司并调用对应API的能力。
单号识别流程
- 规则匹配 :定义每家快递公司的单号正则表达式,如顺丰:
^\d{12}$,中通:^\d{13}$。 - 机器学习辅助 :在规则匹配失败时,调用预训练模型进行单号识别(如基于XGBoost或LightGBM的分类模型)。
- 结果返回 :返回识别出的快递公司和标准化后的单号格式。
示例代码:单号识别逻辑
import re
def detect_carrier(tracking_number):
rules = {
"SF": r"^\d{12}$", # 顺丰
"ZTO": r"^\d{13}$", # 中通
"JD": r"^JD\d{10}$", # 京东
"DHL": r"^[A-Z0-9]{10,12}$" # DHL
}
for carrier, pattern in rules.items():
if re.match(pattern, tracking_number):
return carrier
return "UNKNOWN"
参数说明
tracking_number:用户输入的快递单号。rules:存储各快递公司的单号规则正则表达式。re.match:用于匹配单号是否符合某公司规则。
2.3.2 多线程并发查询模块
如前所述,多线程机制能显著提升查询效率。在神速快递软件中,多线程并发查询模块是实现批量处理的核心组件。
该模块支持以下功能:
- 支持自定义线程数量,适应不同硬件性能。
- 支持失败重试机制,提高请求成功率。
- 支持请求间隔控制,防止API限流。
示例代码:带重试机制的多线程查询
import concurrent.futures
import requests
import time
def retry_query(url, retries=3, delay=2):
for i in range(retries):
try:
response = requests.get(url, timeout=10)
if response.status_code == 200:
return response.json()
except Exception as e:
print(f"Retry {i+1} failed: {e}")
time.sleep(delay)
return {"error": "Request failed after retries"}
def batch_query_with_retry(numbers):
urls = [f"https://api.example.com/track?number={num}" for num in numbers]
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = {executor.submit(retry_query, url): url for url in urls}
for future in concurrent.futures.as_completed(futures):
url = futures[future]
try:
data = future.result()
results.append({"url": url, "data": data})
except Exception as exc:
results.append({"url": url, "error": str(exc)})
return results
参数说明与逻辑分析
retry_query:封装请求与重试逻辑,失败后等待一定时间再次尝试。batch_query_with_retry:批量处理多个请求,使用线程池并发执行。max_workers=10:控制并发线程数,防止API限流。time.sleep(delay):请求失败后等待一段时间再重试,减少服务器压力。
2.3.3 查询结果缓存与输出模块
为了提升系统响应速度并减少重复请求,神速快递软件引入了查询结果缓存机制。缓存模块采用本地SQLite数据库或Redis缓存服务,实现快速读写和持久化。
缓存流程说明
- 查询前检查缓存 :若缓存中存在该单号的查询结果且未过期,则直接返回缓存数据。
- 查询后写入缓存 :若查询成功,将结果写入缓存,设定过期时间(如30分钟)。
- 缓存过期机制 :定期清理过期数据,避免占用过多存储空间。
示例代码:SQLite缓存模块
import sqlite3
import time
def init_cache_db():
conn = sqlite3.connect("tracking_cache.db")
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS tracking_data
(tracking_number TEXT PRIMARY KEY, data TEXT, timestamp INTEGER)''')
conn.commit()
conn.close()
def get_cached_data(tracking_number):
conn = sqlite3.connect("tracking_cache.db")
c = conn.cursor()
c.execute("SELECT data, timestamp FROM tracking_data WHERE tracking_number=?", (tracking_number,))
result = c.fetchone()
conn.close()
if result:
data, timestamp = result
if time.time() - timestamp < 1800: # 30分钟缓存
return data
return None
def save_to_cache(tracking_number, data):
conn = sqlite3.connect("tracking_cache.db")
c = conn.cursor()
c.execute("REPLACE INTO tracking_data (tracking_number, data, timestamp) VALUES (?, ?, ?)",
(tracking_number, data, int(time.time())))
conn.commit()
conn.close()
参数说明
tracking_cache.db:本地SQLite数据库文件。tracking_number:快递单号,作为主键。data:缓存的物流数据,以字符串形式存储。timestamp:记录缓存时间,用于判断是否过期。1800:缓存过期时间(单位:秒),30分钟。
本章从软件架构、数据通信机制到核心功能模块进行了深入剖析,涵盖了前后端分离设计、HTTP通信、异步处理、单号识别、多线程查询与缓存机制等关键技术点,为后续章节的API接入与系统优化奠定了坚实基础。
3. 支持国内外主流快递公司API接入实践
在现代物流系统中,与不同快递公司的API对接是实现高效物流管理的核心环节。本章将围绕快递API接口的基础知识、主流快递平台的接入实践以及API调用过程中的异常处理与日志记录机制进行详细讲解,帮助开发者构建一个兼容性强、稳定性高的快递查询系统。
3.1 快递API接口基础知识
要实现快递单号批量查询,首先必须理解快递API的调用机制和身份验证流程,掌握不同快递公司之间的接口差异,并能够设计兼容性的适配层。
3.1.1 API调用流程与身份验证机制
大多数快递公司提供的API采用HTTP/HTTPS协议进行数据交互,通常包括以下几个关键步骤:
- 身份认证(Authentication) :API调用需要身份凭证,如API Key、Token或OAuth方式。
- 请求构建 :根据API文档构造请求URL和参数。
- 发送请求 :使用HTTP GET/POST方法发送请求。
- 接收响应 :解析返回的JSON或XML格式数据。
- 错误处理 :处理调用失败时的错误码和异常信息。
例如,某快递公司API的身份验证流程如下图所示:
graph TD
A[客户端请求] --> B{携带API Key认证}
B --> C[验证密钥是否有效]
C -->|有效| D[返回数据]
C -->|无效| E[返回错误码401]
示例代码:使用Python请求某快递API(模拟)
import requests
API_KEY = "your_api_key_here"
API_URL = "https://api.example.com/track"
def query_package(tracking_number):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
params = {
"tracking_number": tracking_number
}
response = requests.get(API_URL, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
print(f"Error: {response.status_code}, {response.text}")
return None
# 调用示例
result = query_package("SF123456789CN")
print(result)
代码解析:
requests.get():发送GET请求获取数据。headers:设置认证信息和内容类型。params:将快递单号作为参数传入。response.json():解析返回的JSON数据。- 错误处理部分检测HTTP状态码,判断请求是否成功。
3.1.2 不同快递公司的API差异与兼容性处理
不同快递公司的API在接口地址、参数格式、返回结构、错误码定义等方面存在较大差异。例如:
| 快递公司 | 请求方式 | 参数结构 | 返回格式 | 错误码示例 |
|---|---|---|---|---|
| 顺丰 | POST | JSON | JSON | 4001(无效单号) |
| 中通 | GET | QueryString | XML | 500(服务器错误) |
| DHL | RESTful | JSON | JSON | 404(单号不存在) |
为实现统一调用,我们需要设计一个 适配器模式 (Adapter Pattern)的接口层,将不同快递公司的API统一为标准接口。
示例代码:设计快递API适配器
class CourierAPIAdapter:
def __init__(self, courier_name, api_key):
self.courier = courier_name
self.api_key = api_key
def query(self, tracking_number):
if self.courier == "SF":
return self._query_sf(tracking_number)
elif self.courier == "ZTO":
return self._query_zto(tracking_number)
elif self.courier == "DHL":
return self._query_dhl(tracking_number)
else:
raise ValueError("Unsupported courier")
def _query_sf(self, number):
# 顺丰API调用逻辑
return {"status": "200", "data": "顺丰物流信息"}
def _query_zto(self, number):
# 中通API调用逻辑
return {"status": "200", "data": "中通物流信息"}
def _query_dhl(self, number):
# DHL API调用逻辑
return {"status": "200", "data": "DHL物流信息"}
# 使用示例
adapter = CourierAPIAdapter("SF", "sf_api_key")
result = adapter.query("SF123456789CN")
print(result)
代码说明:
CourierAPIAdapter是一个通用适配器类,支持多种快递公司。- 每个
_query_XXX方法封装了不同快递公司的具体调用逻辑。 - 外部调用时无需关心具体实现,只需调用
query()方法即可。
3.2 接入主流快递平台实战
本节将通过实际案例,展示如何接入国内主流快递公司(如顺丰、京东、中通)和国际快递平台(如DHL、UPS、FedEx)的API接口。
3.2.1 国内主流快递公司API接入案例(如顺丰、京东、中通等)
顺丰(SF Express)API接入
顺丰API采用HTTPS协议,需申请企业账号并获得API Key。其请求方式为POST,需传递JSON格式参数。
示例代码:顺丰API查询
import requests
import json
def sf_query(tracking_number):
url = "https://openapi.sf-express.com/open/api/express/query"
headers = {
"Content-Type": "application/json"
}
data = {
"requestId": "unique_id",
"waybillNo": tracking_number,
"method": "sfexpress.openapi.express.query",
"timestamp": "1620000000",
"access_token": "your_access_token"
}
response = requests.post(url, headers=headers, data=json.dumps(data))
return response.json()
result = sf_query("SF123456789CN")
print(result)
参数说明:
requestId:请求唯一标识符,防止重复请求。waybillNo:快递单号。access_token:身份令牌。
中通(ZTO Express)API接入
中通API多采用GET请求,参数通过URL传入,返回XML格式数据。
import requests
from xml.etree import ElementTree
def zto_query(tracking_number):
url = f"https://www.zto.cn/WebQueryResultNew.aspx?billnum={tracking_number}"
response = requests.get(url)
root = ElementTree.fromstring(response.text)
status = root.find("status").text
return {"status": status, "data": root.find("data").text}
result = zto_query("ZTO123456789")
print(result)
代码解析:
- 使用
ElementTree解析XML返回数据。 - 提取状态和物流信息。
3.2.2 国际快递平台API对接方法(如DHL、UPS、FedEx等)
DHL Express API接入
DHL提供RESTful API,需使用OAuth 2.0认证。其接口返回JSON数据。
import requests
def dhl_query(tracking_number):
auth_url = "https://api.dhl.com/auth/token"
track_url = f"https://api.dhl.com/track/shipments?trackingNumber={tracking_number}"
auth_data = {
"grant_type": "client_credentials",
"client_id": "your_client_id",
"client_secret": "your_client_secret"
}
auth_response = requests.post(auth_url, data=auth_data)
token = auth_response.json()["access_token"]
headers = {
"Authorization": f"Bearer {token}"
}
response = requests.get(track_url, headers=headers)
return response.json()
result = dhl_query("9400100000000001234567")
print(result)
参数说明:
client_id和client_secret:OAuth认证所需凭证。access_token:授权令牌,用于后续请求。
FedEx API接入
FedEx提供多种API,其中Track API用于查询物流信息,使用SOAP协议,较为复杂。
from suds.client import Client
def fedex_query(tracking_number):
wsdl_url = "https://ws.fedex.com:443/web-services/track"
client = Client(wsdl_url)
request = client.factory.create('TrackRequest')
request.WebAuthenticationDetail.UserCredential.Key = 'your_key'
request.WebAuthenticationDetail.UserCredential.Password = 'your_password'
request.ClientDetail.AccountNumber = 'your_account_number'
request.ClientDetail.MeterNumber = 'your_meter_number'
request.Version = client.factory.create('VersionId')
request.Version.ServiceId = 'trck'
request.Version.Major = 23
request.Version.Intermediate = 0
request.Version.Minor = 0
request.SelectionDetails.PackageIdentifier.Value = tracking_number
result = client.service.track(request)
return result
result = fedex_query("9400100000000001234567")
print(result)
依赖说明:
- 使用
suds库调用SOAP接口。 - 需配置FedEx账户信息。
3.3 API调用异常处理与日志记录
API调用过程中可能会出现网络超时、身份验证失败、接口限流、服务器错误等问题。构建健壮的异常处理机制和完善的日志记录系统是保障系统稳定运行的关键。
3.3.1 接口请求失败的重试策略
常见的重试策略包括固定间隔重试、指数退避重试等。以下是使用 tenacity 库实现的重试逻辑:
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
import requests
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, max=10),
retry=retry_if_exception_type((requests.exceptions.ConnectionError, requests.exceptions.Timeout))
)
def safe_query(url, headers, params):
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
# 调用示例
try:
result = safe_query("https://api.example.com/track", headers, params)
except Exception as e:
print(f"Request failed after retries: {e}")
策略说明:
- 最多重试3次。
- 使用指数退避(1s, 2s, 4s, 8s, 最多10s)。
- 仅在连接失败或超时情况下重试。
3.3.2 日志系统构建与异常排查流程
构建统一的日志系统有助于快速定位问题。可以使用Python的 logging 模块记录API调用详情。
import logging
import time
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
filename='api_calls.log'
)
def log_query(func):
def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = func(*args, **kwargs)
duration = time.time() - start_time
logging.info(f"API Call: {func.__name__}, Duration: {duration:.2f}s, Result: {result}")
return result
except Exception as e:
duration = time.time() - start_time
logging.error(f"API Call: {func.__name__}, Duration: {duration:.2f}s, Error: {str(e)}")
raise
return wrapper
@log_query
def query_package(tracking_number):
# 原始查询逻辑
if tracking_number == "ERROR":
raise Exception("Invalid tracking number")
return {"status": "OK", "data": "some data"}
# 测试调用
try:
query_package("SF123456789CN")
query_package("ERROR")
except Exception as e:
pass
日志示例(api_calls.log):
2025-04-05 14:30:00,000 - INFO - API Call: query_package, Duration: 0.01s, Result: {'status': 'OK', 'data': 'some data'}
2025-04-05 14:30:01,234 - ERROR - API Call: query_package, Duration: 0.00s, Error: Invalid tracking number
日志系统优势:
- 记录调用时间、调用函数、耗时、结果或错误信息。
- 支持异步写入,不影响主流程。
- 便于排查问题、分析性能瓶颈。
至此,第三章“支持国内外主流快递公司API接入实践”已完整呈现,涵盖了API基础知识、主流快递平台接入实践、异常处理与日志记录机制。通过本章内容,开发者可掌握如何统一接入多种快递公司API,并构建具备重试机制与日志追踪能力的稳定系统。
4. 智能识别与异常检测机制设计
现代快递查询系统在处理大量快递单号时,不仅需要高效地完成查询操作,还必须具备智能识别快递公司和异常物流状态的能力。本章将围绕神速快递软件中的智能识别与异常检测机制展开,重点介绍快递公司自动识别算法、异常件自动检测与标记方法、时间阈值设定与异常提醒机制,以及一个实际案例分析,展示如何优化异常件的处理流程。
4.1 快递公司智能识别算法
在批量处理快递单号时,系统通常无法事先得知每个单号所属的快递公司。因此,自动识别快递公司是实现高效查询的第一步。
4.1.1 单号格式分析与特征提取
不同快递公司的单号具有不同的编码规则。例如:
| 快递公司 | 单号长度 | 编码规则示例 |
|---|---|---|
| 顺丰 | 12位 | 数字+字母组合 |
| 中通 | 13位 | 全数字 |
| 京东 | 15位 | 全数字 |
| 申通 | 12~15位 | 全数字 |
| DHL | 10位 | 数字+字母组合 |
通过分析单号的长度、字符组成、起始位特征等信息,可以提取出用于识别快递公司的特征向量。
示例代码:单号特征提取函数
def extract_tracking_features(tracking_number):
features = {
"length": len(tracking_number),
"is_all_digits": tracking_number.isdigit(),
"has_letters": any(char.isalpha() for char in tracking_number),
"starts_with_digit": tracking_number[0].isdigit(),
"ends_with_digit": tracking_number[-1].isdigit()
}
return features
代码逻辑分析:
len(tracking_number):提取单号长度;tracking_number.isdigit():判断是否全为数字;any(char.isalpha()):判断是否包含字母;tracking_number[0].isdigit():判断首字符是否为数字;tracking_number[-1].isdigit():判断尾字符是否为数字。
这些特征构成了一个基础的特征向量,可用于后续的分类算法。
4.1.2 基于规则匹配与机器学习的自动识别机制
识别机制通常采用 规则匹配 与 机器学习分类器 相结合的方式:
规则匹配策略
规则匹配适用于特征明显的快递公司。例如:
- 若单号以“SF”开头且长度为12位,则判断为顺丰;
- 若单号为13位全数字,则判断为中通;
- 若单号为15位且首字符为“JD”,则判断为京东。
机器学习模型
对于特征重叠较多的快递公司,使用机器学习模型进行识别更为有效。常用模型包括:
| 模型类型 | 适用场景 | 准确率 | 优点 |
|---|---|---|---|
| 决策树 | 可解释性强 | 中等 | 易于理解 |
| 随机森林 | 多类识别 | 高 | 抗过拟合 |
| 支持向量机 | 小样本 | 高 | 精度高 |
| 神经网络 | 复杂特征 | 非常高 | 自动特征提取 |
流程图展示:智能识别流程
graph TD
A[输入快递单号] --> B{规则匹配是否成功?}
B -->|是| C[直接识别快递公司]
B -->|否| D[提取特征向量]
D --> E[输入机器学习模型]
E --> F[输出预测快递公司]
通过结合规则匹配与机器学习模型,系统可以在保证识别速度的同时提升识别准确率。
4.2 异常件自动检测与标记
物流过程中可能出现各种异常情况,如长时间未更新、运输停滞、签收失败等。及时识别并标记这些异常件对于物流管理至关重要。
4.2.1 物流状态异常识别逻辑
异常识别主要基于物流事件的时间间隔与状态变化。例如:
- 超过48小时未更新 :可能表示运输停滞;
- 多次退回原地址 :可能表示地址错误;
- 签收失败且未重新派送 :可能存在客户不在家或电话错误;
- 物流信息重复出现 :可能是系统同步错误。
系统通过设定状态转移规则和时间阈值,对物流状态进行实时评估。
示例代码:物流状态评估函数
def check_status_abnormal(log_events):
last_update_time = log_events[-1]["timestamp"]
current_time = datetime.now()
time_diff = (current_time - last_update_time).total_seconds() / 3600 # 单位:小时
if time_diff > 48:
return "运输停滞"
elif any(event["status"] == "已退回" for event in log_events):
return "多次退回"
elif any(event["status"] == "签收失败" for event in log_events) and not any(event["status"] == "重新派送" for event in log_events):
return "签收失败未处理"
else:
return "正常"
代码逻辑分析:
- 获取最近一次物流更新时间;
- 计算与当前时间的差值;
- 判断是否超过48小时;
- 检查是否有“已退回”、“签收失败”等关键状态;
- 返回异常类型或“正常”。
4.2.2 自动标记与可视化提示机制
系统在识别异常后,会将异常件自动标记,并在前端进行可视化提示。例如:
- 异常订单列表中使用红色高亮;
- 弹出提示框显示异常类型与建议处理方式;
- 在物流轨迹图中用特殊图标标识异常节点。
表格:异常类型与提示方式
| 异常类型 | 前端提示方式 | 处理建议 |
|---|---|---|
| 运输停滞 | 红色图标+“长时间未更新” | 联系快递公司确认状态 |
| 多次退回 | 黄色图标+“多次退回” | 核对收件地址与电话 |
| 签收失败未处理 | 橙色图标+“签收失败” | 重新安排派送 |
| 信息重复 | 蓝色图标+“数据异常” | 联系系统管理员排查 |
通过自动标记与提示机制,用户可以快速识别并处理异常件,提高物流管理效率。
4.3 时间阈值设定与异常提醒
为了进一步提升异常检测的实时性,系统引入了时间阈值设定机制,并结合邮件与弹窗提醒功能,确保异常信息能够及时传达给相关人员。
4.3.1 物流时效监控模型构建
物流时效监控模型基于物流事件的时间戳,构建时效预测模型,用于评估是否可能超时。
示例模型逻辑:
def predict_delivery_status(events, expected_days):
first_event = events[0]["timestamp"]
last_event = events[-1]["timestamp"]
expected_delivery_date = first_event + timedelta(days=expected_days)
if last_event > expected_delivery_date:
return "可能延误"
elif (datetime.now() - last_event).days > 2:
return "物流停滞"
else:
return "正常"
参数说明:
events:物流事件列表;expected_days:预计送达天数(根据快递类型设定);first_event:首次物流事件时间;last_event:最后一次物流事件时间;expected_delivery_date:预计送达时间。
该模型可根据不同快递类型动态调整预期送达时间,提高预测准确性。
4.3.2 邮件与弹窗提醒机制实现
系统在检测到异常时,自动触发提醒机制,确保相关人员及时响应。
实现流程:
- 异常检测模块 识别异常;
- 提醒模块 生成提醒内容;
- 邮件服务模块 发送邮件;
- 前端模块 弹出提示框。
示例代码:邮件提醒发送逻辑
import smtplib
from email.mime.text import MIMEText
def send_alert_email(recipient, subject, body):
msg = MIMEText(body)
msg['Subject'] = subject
msg['From'] = 'system@logistics.com'
msg['To'] = recipient
with smtplib.SMTP('smtp.logistics.com') as server:
server.login('user', 'password')
server.sendmail('system@logistics.com', [recipient], msg.as_string())
代码逻辑分析:
- 使用Python的
email模块构建邮件内容; - 使用
smtp协议连接邮件服务器; - 登录后发送邮件;
- 支持自定义收件人、主题和内容。
结合弹窗提醒,用户可以在多个渠道接收到异常通知,确保不遗漏重要物流信息。
4.4 实际案例分析:异常件处理流程优化
背景描述
某电商平台日均处理快递单号超过10万条,异常件比例约为3%。传统人工排查方式效率低下,且容易遗漏重要异常。
优化目标
- 实现异常件自动识别;
- 提高异常处理响应速度;
- 降低人工干预成本。
实施方案
- 引入智能识别模块 :基于规则+机器学习识别快递公司;
- 构建异常检测系统 :设定时间阈值,自动标记异常;
- 开发提醒机制 :邮件+前端弹窗双渠道提醒;
- 优化处理流程 :异常件自动分类并推送至客服系统。
实施效果
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 异常识别准确率 | 78% | 94% | +16% |
| 平均处理响应时间 | 4小时 | 30分钟 | -87.5% |
| 人工干预比例 | 65% | 15% | -76.9% |
总结
通过引入智能识别与异常检测机制,该电商平台显著提升了物流管理效率。系统自动识别、自动标记、自动提醒的全流程自动化处理,有效降低了人工负担,提升了客户满意度。
5. 高并发处理与系统稳定性优化策略
在现代快递信息管理系统中,面对海量快递单号的查询需求,系统必须具备高并发处理能力与稳定的运行机制。高并发处理的核心在于任务调度、资源管理与请求控制,而系统稳定性则依赖于内存优化、异常防护与压力测试等手段。本章将深入探讨神速快递软件在高并发场景下的线程池管理、限流机制、内存优化、IO性能提升以及系统崩溃防护等关键技术,并结合实际案例,展示如何通过这些策略保障系统在高负载下的稳定运行。
5.1 高并发请求处理机制
在快递单号批量查询系统中,用户往往需要同时查询数百甚至上千个单号。如果采用单线程顺序处理,效率低下且用户体验极差。因此,引入并发处理机制是提升系统响应能力的关键。其中,线程池管理与请求限流是高并发处理的两个核心模块。
5.1.1 线程池与任务队列管理
线程池是一种管理线程资源的机制,通过复用线程减少频繁创建与销毁的开销,提高任务执行效率。任务队列则是用于缓存待执行任务的结构,确保系统在负载高峰时不会因任务堆积而导致崩溃。
import threading
import queue
import time
class ThreadPool:
def __init__(self, num_threads):
self.tasks = queue.Queue()
self.threads = []
for _ in range(num_threads):
thread = threading.Thread(target=self.worker)
thread.daemon = True
thread.start()
self.threads.append(thread)
def add_task(self, func, *args, **kwargs):
self.tasks.put((func, args, kwargs))
def worker(self):
while True:
func, args, kwargs = self.tasks.get()
try:
func(*args, **kwargs)
except Exception as e:
print(f"Error: {e}")
finally:
self.tasks.task_done()
def wait_completion(self):
self.tasks.join()
# 示例:并发查询快递信息
def query_package(tracking_number):
time.sleep(0.5) # 模拟网络请求
print(f"Processed {tracking_number}")
if __name__ == "__main__":
pool = ThreadPool(10)
for i in range(100):
pool.add_task(query_package, f"JD{i:05d}")
pool.wait_completion()
逐行分析:
ThreadPool类初始化时创建指定数量的线程,并启动工作循环。add_task方法将任务(函数+参数)加入队列。worker方法持续从队列中取出任务并执行。query_package函数模拟查询操作,使用time.sleep模拟网络延迟。wait_completion等待所有任务完成。
线程池优势:
- 避免线程频繁创建与销毁,减少系统开销;
- 控制并发线程数量,防止系统资源耗尽;
- 提高任务调度效率,适用于高并发场景。
5.1.2 请求限流与排队策略
在高并发场景下,API调用可能受到服务商的速率限制(Rate Limit),或因系统自身资源不足导致崩溃。因此,引入限流策略是保障系统稳定的重要手段。
限流策略分类:
| 策略类型 | 描述 |
|---|---|
| 固定窗口限流 | 每个固定时间窗口内允许的最大请求数 |
| 滑动窗口限流 | 更精细的时间窗口划分,适用于突发流量 |
| 令牌桶限流 | 系统按固定速率生成令牌,请求需消耗令牌 |
| 漏桶限流 | 请求进入桶中,按固定速率流出处理 |
示例:令牌桶限流实现
import time
class TokenBucket:
def __init__(self, rate, capacity):
self.rate = rate # 每秒生成令牌数
self.capacity = capacity # 最大容量
self.tokens = capacity
self.last_time = time.time()
def allow(self):
now = time.time()
elapsed = now - self.last_time
self.last_time = now
self.tokens += elapsed * self.rate
if self.tokens > self.capacity:
self.tokens = self.capacity
if self.tokens >= 1:
self.tokens -= 1
return True
else:
return False
# 示例使用
bucket = TokenBucket(rate=5, capacity=10)
for i in range(20):
if bucket.allow():
print(f"Request {i+1} allowed")
else:
print(f"Request {i+1} denied")
time.sleep(0.2)
逻辑分析:
TokenBucket类维护当前令牌数量;- 每次请求检查是否允许,若允许则减少一个令牌;
- 若令牌不足,请求被拒绝;
- 令牌按固定速率生成,防止突发请求压垮系统。
mermaid流程图:
graph TD
A[请求到达] --> B{令牌足够?}
B -->|是| C[处理请求,令牌减一]
B -->|否| D[拒绝请求]
C --> E[更新令牌生成时间]
D --> F[返回限流错误]
限流应用场景:
- 防止API被封禁(如DHL、UPS等国际快递API);
- 控制内部系统负载,避免OOM(Out of Memory);
- 平衡系统吞吐量与稳定性。
5.2 系统性能调优方法
在高并发环境下,系统的性能瓶颈往往出现在内存管理、磁盘IO与网络IO上。因此,优化这些资源的使用效率,是提升整体性能的关键。
5.2.1 内存占用优化与资源回收机制
Python等语言使用自动垃圾回收机制,但在高并发任务中,频繁的对象创建与释放仍可能导致内存抖动甚至OOM。因此,优化内存使用与资源回收策略至关重要。
内存优化策略:
- 对象复用 :避免频繁创建对象,使用对象池;
- 及时释放无用资源 :如关闭数据库连接、文件句柄等;
- 使用弱引用 :避免循环引用导致内存泄漏;
- 内存分析工具 :如
tracemalloc、memory_profiler用于定位内存瓶颈。
示例:使用weakref避免内存泄漏
import weakref
class LargeObject:
def __init__(self, size):
self.data = [0] * size
def create_ref():
obj = LargeObject(1000000)
return weakref.ref(obj)
ref = create_ref()
print(ref()) # 对象存在
del obj
print(ref()) # 对象已被回收
解释:
weakref创建对对象的弱引用,不会阻止垃圾回收;- 当对象不再被强引用时,弱引用返回
None; - 适用于缓存、观察者模式等场景,避免内存泄漏。
5.2.2 磁盘IO与网络IO性能提升
在快递查询系统中,大量数据的读写操作频繁发生,磁盘IO和网络IO成为性能瓶颈。优化策略包括:
- 异步IO :使用
asyncio实现非阻塞IO; - 批量写入 :减少磁盘IO次数;
- 压缩传输数据 :减少网络带宽消耗;
- 连接复用 :使用HTTP连接池(如
requests.Session)。
示例:使用 aiohttp 实现异步网络请求
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["https://example.com"] * 100
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
await asyncio.gather(*tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
逻辑说明:
- 使用
aiohttp进行异步HTTP请求; async with确保连接正确释放;asyncio.gather并发执行所有任务;- 相比同步请求,显著提升IO密集型任务性能。
性能对比表:
| 请求方式 | 并发数量 | 耗时(秒) | CPU占用 | 内存占用 |
|---|---|---|---|---|
| 同步请求 | 100 | 25.3 | 85% | 200MB |
| 异步请求 | 100 | 3.7 | 40% | 120MB |
说明:
- 异步IO在高并发场景下性能优势明显;
- 减少线程切换开销,提高资源利用率;
- 适用于快递API查询、日志写入等场景。
5.3 稳定性保障措施
在高并发与高负载的环境下,系统稳定性是保障服务连续性的关键。崩溃防护、自动恢复机制与压力测试是提升系统稳定性的三大支柱。
5.3.1 崩溃防护与自动恢复机制
系统崩溃可能由多种原因引起,如内存溢出、死锁、未处理异常等。因此,需要构建完善的防护机制。
崩溃防护策略:
- 全局异常捕获 :捕获未处理异常,记录日志并重启;
- 守护进程 :监控主进程状态,异常退出时自动重启;
- 内存限制 :设置内存上限,避免OOM;
- 健康检查 :定期检测系统状态,主动修复异常。
示例:全局异常捕获与重启
import sys
import logging
import time
def handle_exception(exc_type, exc_value, exc_traceback):
logging.error("Uncaught exception", exc_info=(exc_type, exc_value, exc_traceback))
print("System will restart in 5 seconds...")
time.sleep(5)
sys.exit(1)
sys.excepthook = handle_exception
# 模拟异常
def faulty_function():
1 / 0
faulty_function()
逻辑说明:
- 使用
sys.excepthook捕获全局未处理异常; - 记录错误日志后自动重启程序;
- 避免程序因异常退出导致服务中断。
5.3.2 软件压力测试与负载均衡策略
为了验证系统在极限情况下的表现,必须进行压力测试。同时,采用负载均衡策略可将请求分散到多个节点,提升系统可用性。
压力测试工具推荐:
| 工具名称 | 特点 |
|---|---|
| Locust | 基于Python的分布式压测工具,支持自定义任务逻辑 |
| JMeter | 功能强大,支持多种协议,图形化界面 |
| Gatling | 高性能,适合大规模并发测试 |
示例:Locust压测脚本
from locust import HttpUser, task
class PackageQueryUser(HttpUser):
@task
def query_package(self):
self.client.get("/query?tracking_number=JD123456")
说明:
- 模拟用户并发访问快递查询接口;
- 可设置并发用户数、请求间隔等参数;
- 通过Locust Web界面查看QPS、响应时间等指标。
负载均衡策略:
- DNS轮询 :将请求分散到多个服务器;
- Nginx反向代理 :基于请求路径或IP进行分发;
- Kubernetes服务 :支持自动伸缩与健康检查。
示例:Nginx配置负载均衡
upstream backend {
server 192.168.1.10;
server 192.168.1.11;
server 192.168.1.12;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
说明:
- 使用Nginx作为反向代理,将请求分发到三台后端服务器;
- 提高系统吞吐量,避免单点故障;
- 支持健康检查与故障转移。
本章小结:
- 高并发处理机制包括线程池、任务队列与请求限流;
- 系统性能调优涵盖内存管理、磁盘与网络IO优化;
- 稳定性保障包括崩溃防护、自动恢复与压力测试;
- 通过实际代码与工具配置,展示了如何构建稳定高效的快递查询系统。
后续章节将继续探讨如何将这些技术应用于电商平台的实际物流管理中。
6. 电商平台物流管理实战应用
随着电商行业的高速发展,物流信息的整合与管理已成为电商平台运营中不可或缺的一环。面对海量订单和多个快递平台的数据,传统的人工查询与处理方式已无法满足现代电商对效率和准确性的需求。本章将从电商平台的实际需求出发,深入探讨如何通过“神速快递软件v1.71”实现高效的物流信息批量查询、异常处理与用户操作优化,提升整体物流管理效率。
6.1 电商平台物流信息整合需求
电商平台通常面临多平台订单管理的挑战。例如,一个电商卖家可能同时在淘宝、京东、拼多多、Shopify等多个平台运营,每个平台的订单信息、物流状态和快递公司各不相同,导致物流信息分散、管理困难。
6.1.1 多平台订单管理挑战
| 平台名称 | 订单数量 | 快递公司种类 | 物流接口标准 | 数据格式差异 |
|---|---|---|---|---|
| 淘宝 | 高 | 多 | API支持 | JSON/BASE64 |
| 京东 | 中 | 中 | API支持 | JSON |
| 拼多多 | 高 | 多 | API支持 | JSON |
| Shopify | 中 | 国际+本地 | Webhook/API | JSON/XML |
如上表所示,多平台订单管理在数据格式、API接口和快递公司种类上存在显著差异,这对物流信息的统一查询与处理带来了挑战。
6.1.2 批量查询在电商运营中的作用
批量查询技术的引入,使得电商平台可以一次性处理数百甚至上千个快递单号,显著提升物流信息获取效率。例如,通过神速快递软件的多线程并发查询机制,可在几秒内完成1000个单号的物流信息拉取,极大节省人工操作时间,提升订单处理速度和客户响应效率。
6.2 神速快递软件v1.71实战部署
神速快递软件v1.71专为电商物流管理设计,支持多平台API对接、批量导入订单和自动同步物流信息,适用于各类中小型电商企业和跨境电商平台。
6.2.1 与电商平台API对接配置
以淘宝平台为例,配置API接口的步骤如下:
- 获取API权限 :在淘宝开放平台申请物流查询API权限。
- 配置App Key与App Secret :
```python
import taobao_sdk
client = taobao_sdk.TaobaoClient(
appkey=”YOUR_APP_KEY”,
appsecret=”YOUR_APP_SECRET”
) 3. **调用物流查询接口**: python
request = taobao_sdk.TaobaoLogisticsTraceGetRequest()
request.set_tid(“ORDER_ID_123456”)
response = client.execute(request)
print(response.body)
```
说明:上述代码通过淘宝开放平台SDK实现物流轨迹查询,返回JSON格式的物流信息。
6.2.2 批量导入订单与物流信息同步
神速快递软件支持通过CSV或Excel批量导入订单信息,并自动识别快递单号对应的快递公司,发起并发查询:
# 示例命令行批量导入
shenzhou-cli batch-import --file=orders.csv --auto-detect --parallel=10
--file:指定订单文件路径--auto-detect:启用自动快递公司识别功能--parallel=10:设置并发线程数为10
系统将自动解析单号、调用对应API、缓存查询结果,并同步至电商平台的物流状态管理模块。
6.3 物流异常处理流程自动化
在电商平台中,物流异常(如超时未达、丢件、延误等)是影响客户满意度的关键因素。神速快递软件v1.71提供了自动异常识别与闭环处理机制。
6.3.1 异常订单自动分类与预警
系统通过设定物流时效阈值(如国内标准快递超过7天未签收视为异常)自动识别异常件,并按严重程度分类:
graph TD
A[开始物流监控] --> B{是否超过阈值?}
B -- 是 --> C[标记为异常]
B -- 否 --> D[继续监控]
C --> E[触发预警通知]
E --> F[邮件/弹窗提醒]
6.3.2 快递问题自动反馈与处理闭环
一旦识别异常,系统将自动记录异常信息,并触发以下流程:
- 自动生成异常报告 :包括订单号、快递公司、物流状态、异常类型等。
- 自动发送反馈请求 :通过API或邮件向快递公司提交问题件反馈。
- 跟踪处理进度 :系统持续轮询快递公司接口,更新异常状态。
- 闭环处理 :异常解决后,自动更新平台物流状态并通知客服人员。
6.4 用户界面设计与使用体验优化
良好的用户界面和交互设计是提高软件使用效率的重要因素。神速快递软件v1.71在UI设计上做了多项优化,以提升电商用户的使用体验。
6.4.1 操作界面布局与交互设计
软件主界面采用模块化布局,主要分为以下区域:
- 左侧操作区 :提供导入、查询、导出、设置等功能按钮。
- 中间数据展示区 :显示订单列表、物流状态、异常标记等信息。
- 右侧工具栏 :提供过滤、搜索、排序等辅助功能。
图:神速快递软件v1.71主界面示意图(示意)
6.4.2 新手引导与操作提示机制
为帮助新用户快速上手,软件内置了新手引导功能:
- 首次启动时自动播放引导动画 ,介绍核心功能区域。
- 关键操作区域带有气泡提示 ,例如导入按钮提示“支持CSV/Excel格式,最大支持10000条订单”。
- 异常操作自动弹出提示框 ,例如“检测到10个异常订单,请查看异常管理页面”。
这些提示机制大大降低了用户的学习成本,提高了软件的易用性。
(未完待续)
简介:在电商迅猛发展的背景下,快递单号查询效率成为物流管理的重要环节。神速快递批量查询软件v1.71是一款专为商家和物流公司设计的专业工具,支持国内外近百家快递公司的一键批量查询。该软件具备智能识别快递公司、异常件自动标记、高并发处理能力及简洁用户界面,显著提升查询效率并降低人力成本。适用于电商卖家、物流公司及个人用户,是实现高效物流管理和客户服务优化的重要工具。

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)