
改进多目标遗传算法在冷链物流车辆路径优化中的应用
NSGA2 是一种求解多目标优化问题的强大算法。简单来说,它就像是一个聪明的小能手,能在众多复杂的选择中找到最优解。在我们的冷链物流车辆路径优化问题里,它可以帮助我们同时考虑多个目标,比如成本最低和客户满意度最高。这可不是一件容易的事儿,因为这两个目标往往是相互矛盾的。想象一下,为了满足所有客户的需求,让大家都开心,可能就得多跑几趟,成本就上去了;要是只想着降低成本,可能就没办法及时给所有客户送货
改进多目标遗传算法车辆路径优化,冷链物流车辆路径优化,考虑客户满意度,碳排放成本,nsga2 [1]NSGA2,采用nsga2求解多目标优化问题,求解得到最优解。 nsga2车辆路径 [2]nsga2路径优化,双目标:成本最低和客户满意度最高。 软时间窗的软件路径。 [3]每个客户满意度都有对应成本

最近一直在研究冷链物流车辆路径优化的问题,发现这里面学问可真是不少!今天就来和大家分享一下我在这方面的一些探索,特别是关于改进多目标遗传算法,以及它如何考虑客户满意度和碳排放成本,同时结合了 NSGA2 算法。
一、NSGA2 算法简介
NSGA2 是一种求解多目标优化问题的强大算法。简单来说,它就像是一个聪明的小能手,能在众多复杂的选择中找到最优解。
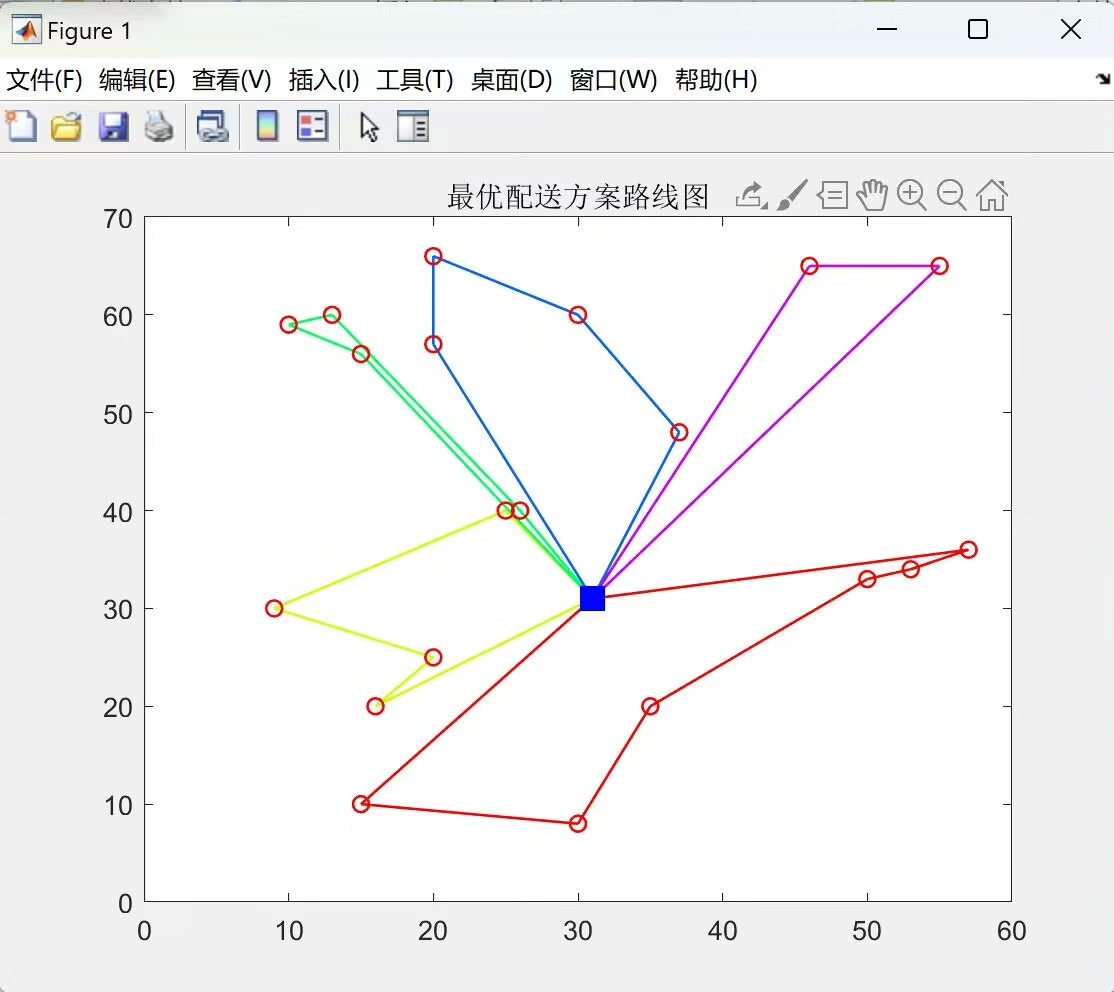
在我们的冷链物流车辆路径优化问题里,它可以帮助我们同时考虑多个目标,比如成本最低和客户满意度最高。这可不是一件容易的事儿,因为这两个目标往往是相互矛盾的。想象一下,为了满足所有客户的需求,让大家都开心,可能就得多跑几趟,成本就上去了;要是只想着降低成本,可能就没办法及时给所有客户送货,客户满意度就会下降。NSGA2 就能在这两者之间找到一个平衡,找到一组最优的车辆行驶路径。
二、代码实现与分析
下面我们来看看一些关键的代码部分。
# 这里假设已经有了一些必要的库导入,比如 numpy、pandas 等
# 定义一些车辆路径优化问题的参数
num_vehicles = 3
num_customers = 10
vehicle_capacity = 100
customer_demands = [20, 30, 15, 25, 10, 18, 22, 28, 12, 16]
distance_matrix = np.array([
[0, 50, 30, 40, 60, 20, 55, 45, 35, 65],
[50, 0, 70, 20, 30, 60, 40, 50, 45, 25],
[30, 70, 0, 45, 15, 50, 35, 60, 20, 40],
[40, 20, 45, 0, 55, 30, 40, 70, 50, 35],
[60, 30, 15, 55, 0, 65, 45, 20, 30, 50],
[20, 60, 50, 30, 65, 0, 70, 55, 40, 35],
[55, 40, 35, 40, 45, 70, 0, 30, 60, 25],
[45, 50, 60, 70, 20, 55, 30, 0, 45, 50],
[35, 45, 20, 50, 30, 40, 60, 45, 0, 65],
[65, 25, 40, 35, 50, 35, 25, 50, 65, 0]
])
# 初始化种群
def initialize_population(num_vehicles, num_customers):
population = []
for _ in range(100): # 假设种群大小为 100
individual = list(range(1, num_customers + 1))
random.shuffle(individual)
individual = [0] + individual + [0] # 首尾添加 depot
routes = []
vehicle_load = [0] * num_vehicles
current_route = [0]
for customer in individual[1:-1]:
if vehicle_load[len(routes)] + customer_demands[customer - 1] <= vehicle_capacity:
current_route.append(customer)
vehicle_load[len(routes)] += customer_demands[customer - 1]
else:
routes.append(current_route)
current_route = [0, customer]
vehicle_load[len(routes)] = customer_demands[customer - 1]
if current_route:
routes.append(current_route)
population.append(routes)
return population
# 计算适应度函数,这里同时考虑成本和客户满意度
def calculate_fitness(individual):
total_distance = 0
for route in individual:
for i in range(len(route) - 1):
total_distance += distance_matrix[route[i]][route[i + 1]]
customer_satisfaction = 0
for route in individual:
for customer in route[1:-1]:
if customer_demands[customer - 1] <= vehicle_capacity:
customer_satisfaction += 1
cost = total_distance * 1.0 # 这里简单将距离作为成本,实际可更复杂
# 这里为了简单示例,没有考虑碳排放成本,实际应用中可添加相关计算
# 假设碳排放成本与行驶距离成正比,可添加如下代码:
# carbon_emission_cost = total_distance * carbon_emission_factor
# cost += carbon_emission_cost
# 这里可以根据实际需求调整成本和客户满意度的权重
fitness = [cost, -customer_satisfaction] # 注意这里客户满意度取负,因为 NSGA2 是求最小化问题
return fitness
# 选择操作
def selection(population, fitness):
num_parents = len(population)
parents = []
for _ in range(num_parents):
best_index = np.argmin([sum(f**2 for f in f_i) for f_i in fitness])
parents.append(population[best_index])
fitness.pop(best_index)
population.pop(best_index)
return parents
# 交叉操作
def crossover(parent1, parent2):
# 这里采用顺序交叉的方法
size = len(parent1)
start, end = sorted(random.sample(range(size), 2))
child1 = [None] * size
child2 = [None] * size
child1[start:end] = parent1[start:end]
child2[start:end] = parent2[start:end]
remaining1 = [item for item in parent2 if item not in child1[start:end]]
remaining2 = [item for item in parent1 if item not in child2[start:end]]
j1, j2 = 0, 0
for i in range(size):
if child1[i] is None:
child1[i] = remaining1[j1]
j1 += 1
if child2[i] is None:
child2[i] = remaining2[j2]
j2 += 1
return child1, child2
# 变异操作
def mutation(individual):
# 这里采用交换变异的方法
size = len(individual)
i1, i2 = random.sample(range(1, size - 1), 2)
individual[i1], individual[i2] = individual[i2], individual[i1]
return individual
# NSGA2 主循环
def nsga2(num_generations):
population = initialize_population(num_vehicles, num_customers)
for generation in range(num_generations):
fitness = [calculate_fitness(individual) for individual in population]
non_dominated_sorting = non_dominated_sort(fitness)
crowding_distance = crowding_distance_assignment(non_dominated_sorting, fitness)
new_population = []
for front in non_dominated_sorting:
sorted_front = sorted(front, key=lambda x: crowding_distance[x], reverse=True)
for i in range(len(sorted_front)):
new_population.append(population[sorted_front[i]])
if len(new_population) >= len(population):
break
if len(new_population) >= len(population):
break
parents = selection(new_population, fitness)
offspring = []
for i in range(0, len(parents), 2):
child1, child2 = crossover(parents[i], parents[i + 1])
child1 = mutation(child1)
child2 = mutation(child2)
offspring.append(child1)
offspring.append(child2)
population = offspring
fitness = [calculate_fitness(individual) for individual in population]
non_dominated_sorting = non_dominated_sort(fitness)
best_solutions = non_dominated_sorting[0]
best_solution = population[best_solutions[0]]
return best_solution
# 辅助函数:非支配排序
def non_dominated_sort(fitness):
S = [[] for _ in range(len(fitness))]
n = [0] * len(fitness)
rank = [0] * len(fitness)
for p in range(len(fitness)):
S[p] = []
n[p] = 0
for q in range(len(fitness)):
if p != q:
if dominates(fitness[p], fitness[q]):
S[p].append(q)
elif dominates(fitness[q], fitness[p]):
n[p] += 1
if n[p] == 0:
rank[p] = 1
i = 0
while i < len(rank):
Q = []
for p in range(len(fitness)):
if rank[p] == i + 1:
Q.append(p)
for p in Q:
for q in S[p]:
n[q] -= 1
if n[q] == 0:
rank[q] = i + 2
i += 1
F = [[] for _ in range(len(rank))]
for p in range(len(fitness)):
F[rank[p] - 1].append(p)
return F
# 辅助函数:计算拥挤距离
def crowding_distance_assignment(F, fitness):
distance = [0] * len(fitness)
for i in range(len(F)):
if len(F[i]) == 1:
distance[F[i][0]] = float('inf')
else:
for m in range(len(F[i])):
distance[F[i][m]] = 0
objectives = len(fitness[0])
for k in range(objectives):
sorted_front = sorted(F[i], key=lambda x: fitness[x][k])
distance[sorted_front[0]] = float('inf')
distance[sorted_front[-1]] = float('inf')
min_f = fitness[sorted_front[0]][k]
max_f = fitness[sorted_front[-1]][k]
for j in range(1, len(sorted_front) - 1):
distance[sorted_front[j]] += (fitness[sorted_front[j + 1]][k] - fitness[sorted_front[j - 1]][k]) / (max_f - min_f)
return distance
# 辅助函数:判断支配关系
def dominates(a, b):
less = equal = 0
for i in range(len(a)):
if a[i] < b[i]:
less += 1
elif a[i] == b[i]:
equal += 1
return less > 0 and equal == 0这段代码实现了基于 NSGA2 的冷链物流车辆路径优化算法。
- 初始化种群:
- 首先定义了一些基本参数,如车辆数量、客户数量、车辆容量、客户需求和距离矩阵。
-initialize_population函数用于生成初始种群。它通过随机打乱客户顺序,然后根据车辆容量将客户分配到不同的路径中,每个路径以 depot 开始和结束。 - 计算适应度函数:
-calculate_fitness函数计算每个个体(即一组车辆行驶路径)的适应度。这里考虑了总行驶距离作为成本,同时计算了客户满意度。客户满意度通过满足需求的客户数量来衡量。为了简单示例,没有考虑碳排放成本,实际应用中可添加相关计算。 - 选择操作:
-selection函数采用锦标赛选择的方法。它从种群中选择适应度最好的个体作为父代,适应度的计算通过将每个目标值的平方和最小化来确定。 - 交叉操作:
-crossover函数实现了顺序交叉。它从父代中选择一段子路径,然后将另一个父代中剩余的客户依次插入到子代路径中,以生成新的路径。 - 变异操作:
-mutation函数采用交换变异。它随机选择路径中的两个客户,交换它们的位置,从而引入新的基因。 - NSGA2 主循环:
-nsga2函数是整个算法的核心。它进行多代的进化,通过非支配排序和拥挤距离计算来选择优秀的个体,并进行遗传操作(选择、交叉和变异)。
- 非支配排序将种群分为不同的层级,拥挤距离用于在同一层级中选择更分散的个体,以保持种群的多样性。
三、考虑客户满意度和碳排放成本
在实际的冷链物流中,客户满意度和碳排放成本是非常重要的因素。

客户满意度不仅仅取决于是否按时送货,还与货物的完好程度等因素有关。我们在计算客户满意度时,除了考虑车辆容量是否满足需求,还可以进一步细化,比如根据货物在运输过程中的温度记录来评估客户满意度。如果货物在运输过程中温度波动超出了规定范围,客户满意度就会降低。
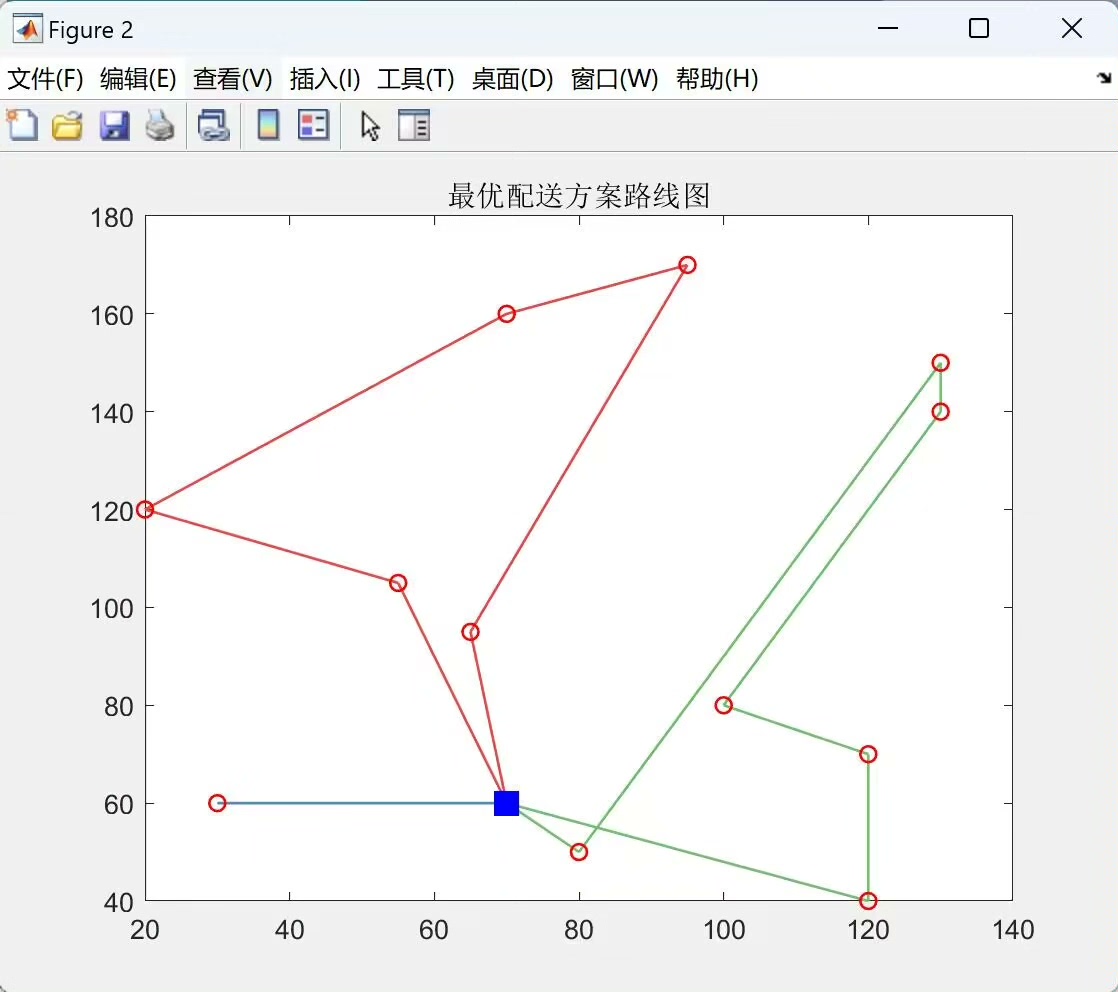
碳排放成本方面,冷链物流车辆的运行会产生一定的碳排放。我们可以根据车辆的油耗、行驶里程等因素来计算碳排放成本。例如,假设每公里的碳排放因子为 \(x\),那么总碳排放成本就等于行驶总距离乘以碳排放因子。
# 假设碳排放因子为 0.5
carbon_emission_factor = 0.5
# 在 calculate_fitness 函数中添加碳排放成本计算
def calculate_fitness(individual):
total_distance = 0
for route in individual:
for i in range(len(route) - 1):
total_distance += distance_matrix[route[i]][route[i + 1]]
customer_satisfaction = 0
for route in individual:
for customer in route[1:-1]:
if customer_demands[customer - 1] <= vehicle_capacity:
customer_satisfaction += 1
cost = total_distance * 1.0 # 这里简单将距离作为成本,实际可更复杂
carbon_emission_cost = total_distance * carbon_emission_factor
cost += carbon_emission_cost
fitness = [cost, -customer_satisfaction] # 注意这里客户满意度取负,因为 NSGA2 是求最小化问题
return fitness通过这样的改进,我们的算法能够更全面地考虑冷链物流车辆路径优化中的各种因素,找到更符合实际需求的最优路径。
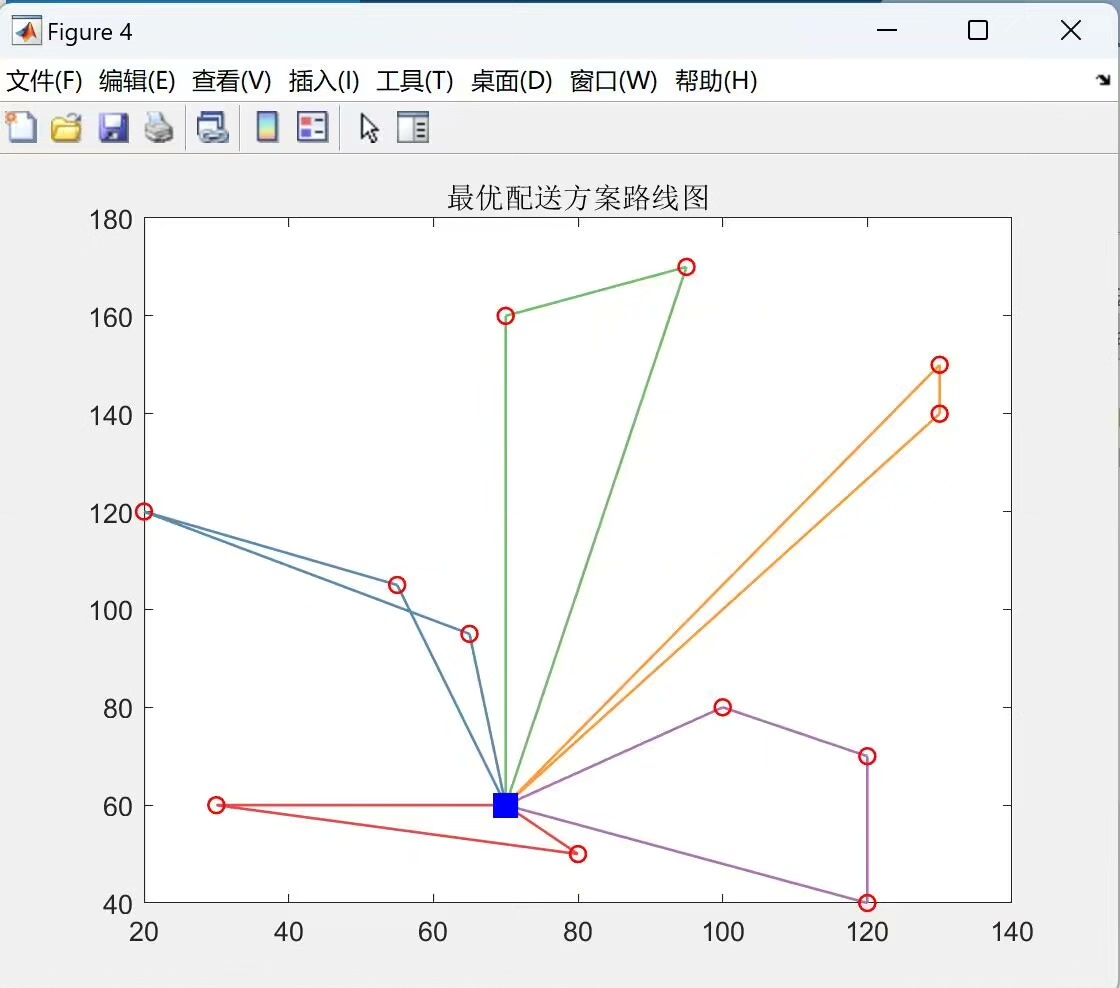
希望以上内容能让大家对改进多目标遗传算法在冷链物流车辆路径优化中的应用有更清晰的了解!如果大家有任何问题或者想法,欢迎一起交流讨论。
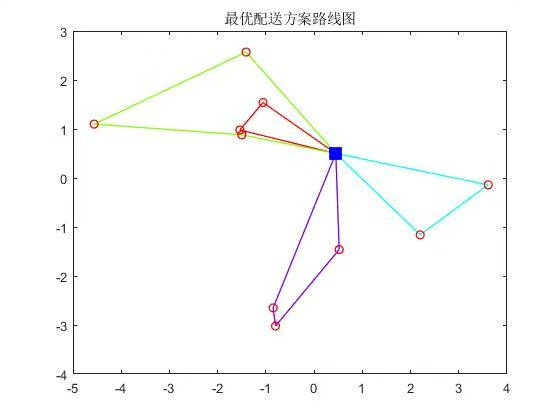
以上代码在实际运行时可能需要根据具体情况进行调整和优化,而且只是一个简单的示例,实际应用中还有很多细节需要进一步完善。但通过这个代码示例,能让大家对整个算法流程有一个基本的认识。
#冷链物流 #车辆路径优化 #NSGA2 #客户满意度 #碳排放成本

电商企业物流数字化转型必备!快递鸟 API 接口,72 小时快速完成物流系统集成。全流程实战1V1指导,营造开放的API技术生态圈。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)